简介
本文分享一个我前几个月实现的一个智能聊天系统小项目,包含了java后端,微信小程序端,web页面端三个子工程。
代码已经全部开源,地址放在了文末。
最近一年,chatGPT的火爆程度,已经不需要我再多说了,但是依旧有很多人想用却用不上,原因大家也都很清楚,因为需要科学上网才可以访问,并且注册也需要绑定海外的银行卡。那么这就给了很多人赚钱的机会,于是很多套壳类网站层出不穷,只需要简单写一下代码,部署到海外的服务器上,就可以进行访问了,并且可以实现和chatgpt官网一样的效果。然后再通过充值会员,或者购买次数,来赚钱。
当然,我这个项目也是很久之前就已经实现了,但是并不是为了赚钱,当时的想法是,第一是为了练习编程技术,作为程序员,遇到新鲜的事物,总是会想着尝试一番。第二是为了方便自己,因为自己平时学习或者办公中,也会经常使用chatgpt,但是公司网络又不允许我使用官网,那么不如自己来套壳一个,然后再提供前端页面进行交互,不就可以了吗。
后来,因为网页版对于手机使用非常不方便,于是就又开发出一个微信小程序,可以随时随地使用了,对我的工作和学习帮助还是挺大的,遇到问题就可以直接询问chatGPT了,而且我预设置了多种角色,精心调试了prompt,来实现特定场景或特定领域的问答机器人。
现在,我决定将这些所有的东西全部开源,毫无保留,大家可以使用代码进行学习或者部署使用,微信小程序端就不建议大家发布了,现在微信是不允许对接chatGPT的,大概率会审核不通过。我是因为发布的早,并且没有做过宣传,只是自己和身边人使用,访问量非常小。
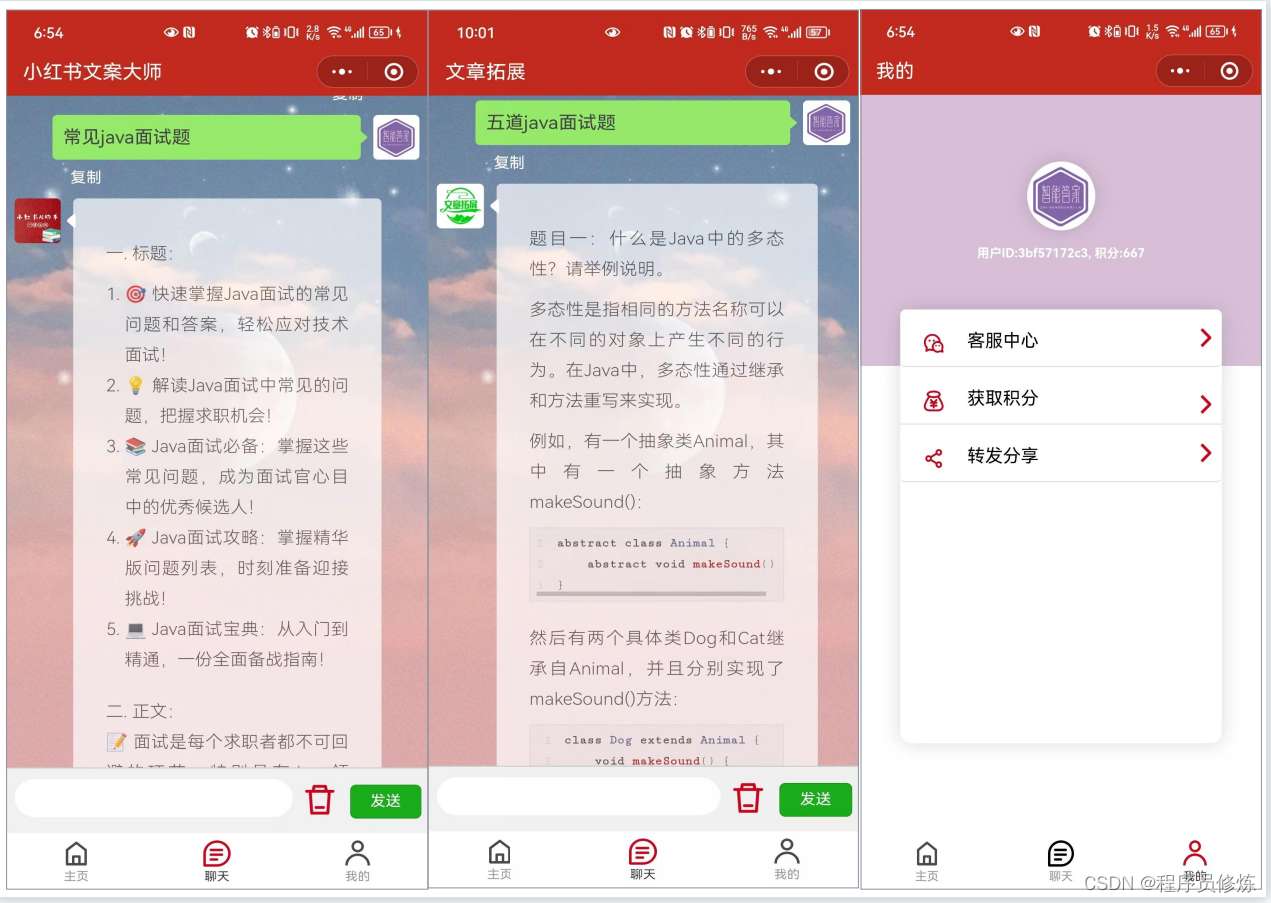
效果图展示
先来看下效果图吧,这样才能更加直观的展示。vue实现的网页端和微信小程序端,整体功能是一样的,只是布局有一点小的差异。
网页端
可以根据类别进行划分,每个类别下有多种角色

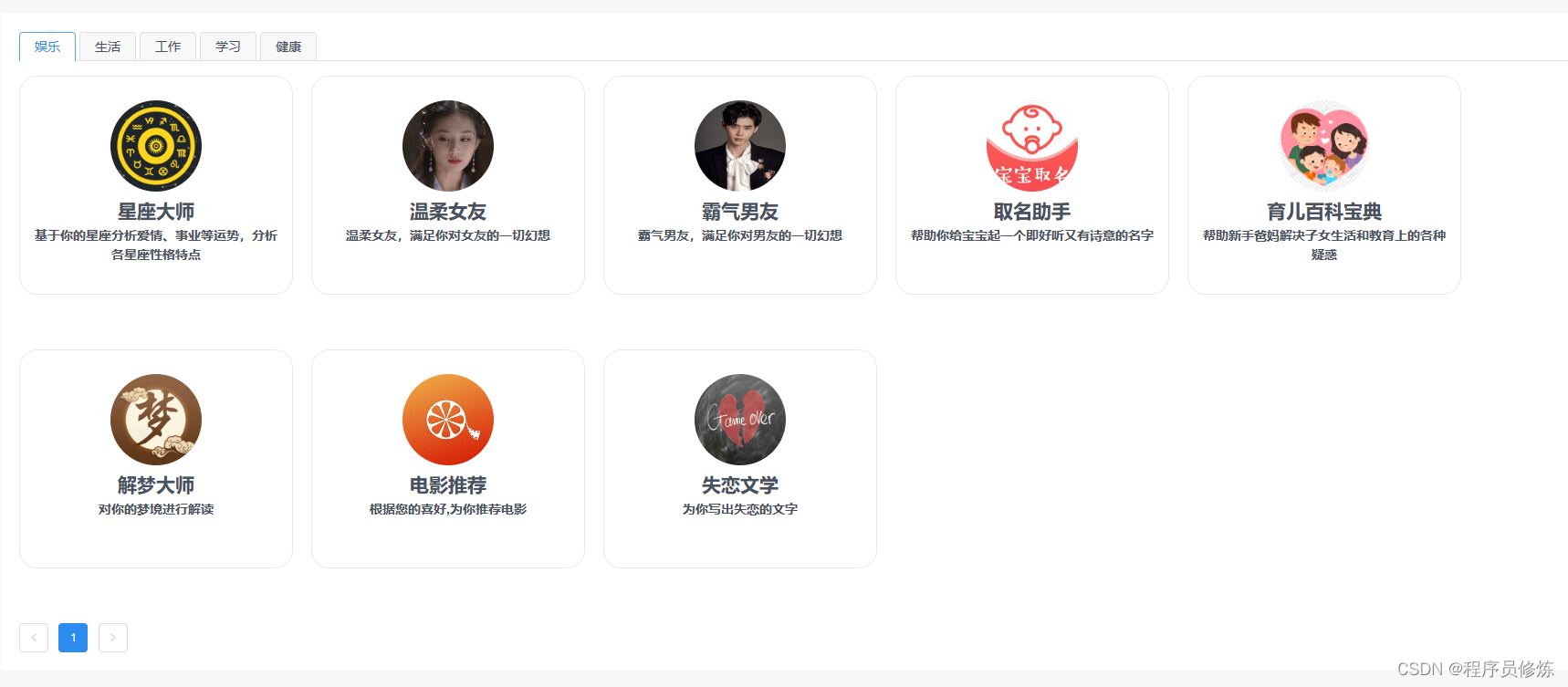
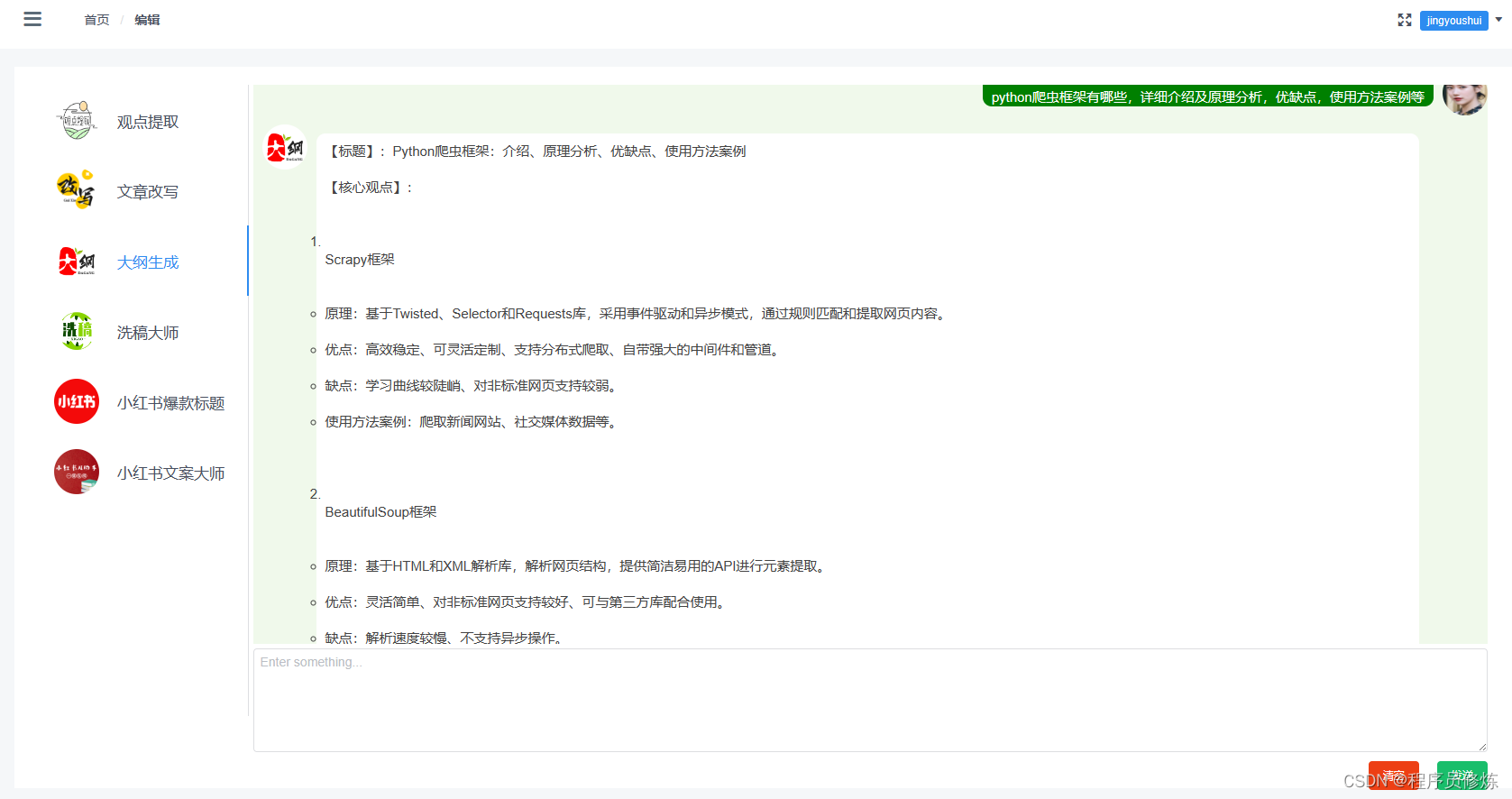
聊天页面,类似微信聊天一样,左侧是联系人列表,右边是对话框,下方是输入框。对话框中,自己的输入在右边显示,chatGPT的输出在左边显示。支持markdown格式转换。
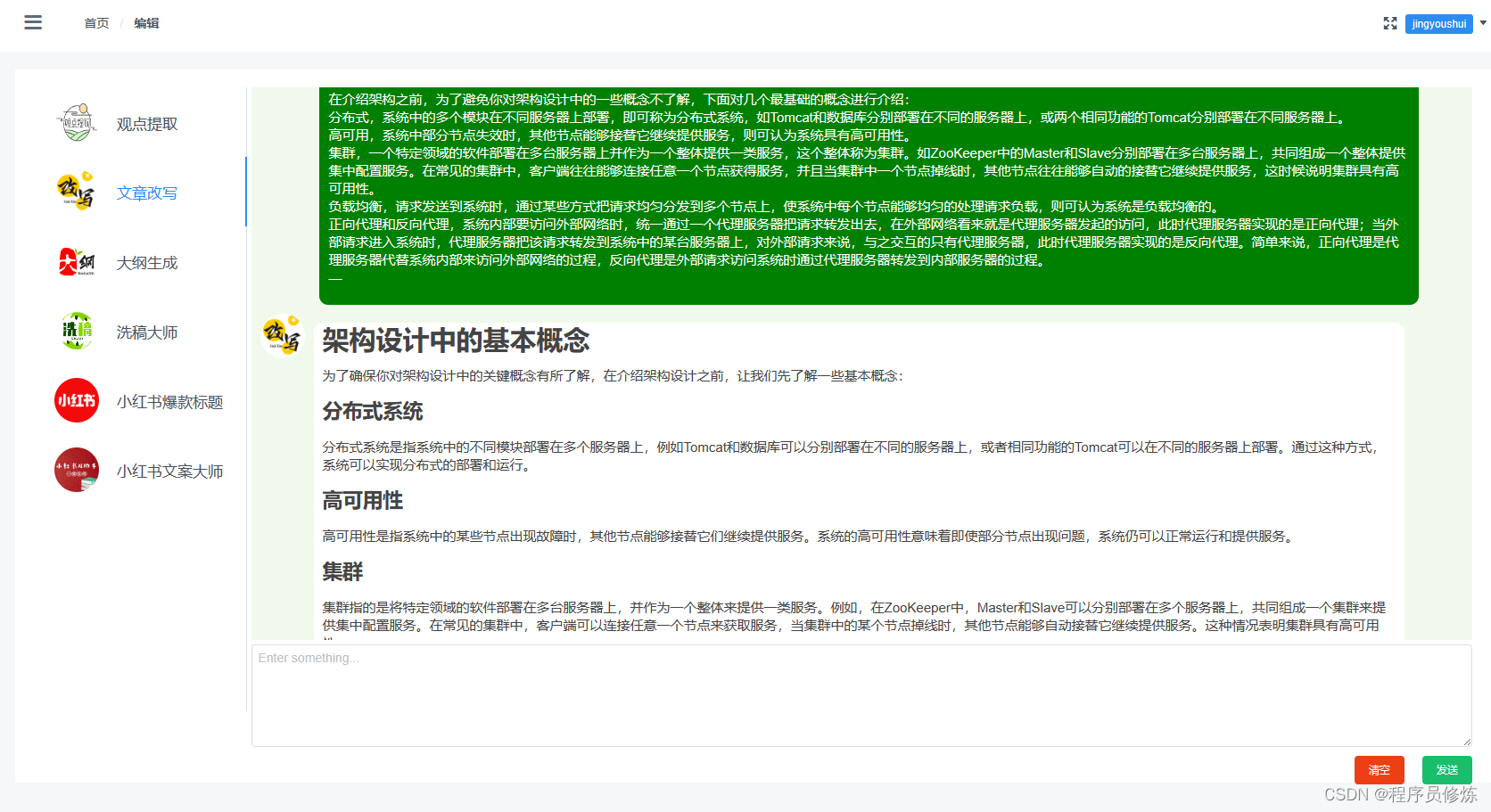
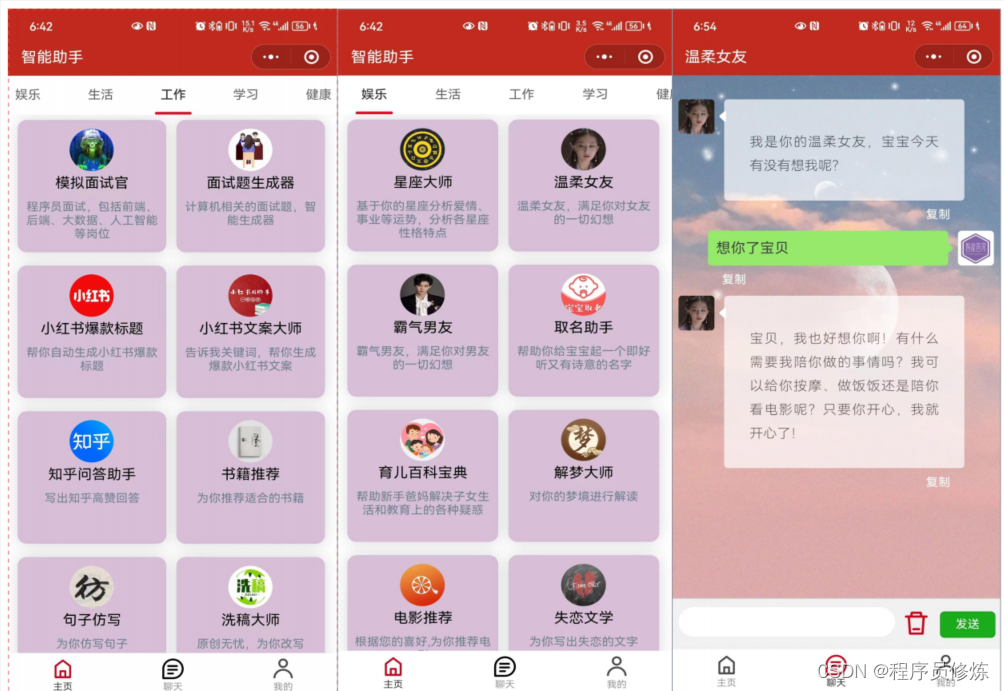
微信小程序端
类似的布局,同样的功能,支持积分扣减
后端项目介绍
后端是使用spring boot进行搭建的, 同时会使用到mysql, mybaits,spring data jpa, redis等组件。
为什么使用spring boot,因为自己是一名java程序员,当然对python和go也略知一二,只是对性能要求没有那么高,并且自己根据熟悉,所以选择了java语言,而Spring Boot是一个开源的Java开发框架,它简化了Java应用程序的开发和部署过程。相比于传统的Java开发,Spring Boot具有以下优点:
1.简化配置:Spring Boot提供了自动配置的功能,可以根据项目的依赖自动配置各种组件,无需手动编写大量的XML配置文件,大大提高了开发效率。
2.内嵌服务器:Spring Boot内置了常用的服务器,如Tomcat、Jetty等,可以直接将应用程序打包为可执行的Jar包或War包,简化了部署和运行的过程。
3.良好的扩展性:Spring Boot基于Spring框架,可以与其他Spring生态系统的组件无缝集成,如Spring Data、Spring Security等,拓展了开发的能力。
搭建Spring Boot项目环境非常简单,只需要几个步骤:
1.在IDE中创建一个新的Spring Boot项目,可以选择使用Spring Initializr或者直接创建一个空的Maven或Gradle项目。
2.在项目的依赖管理文件(如pom.xml)中,添加Spring Boot的启动器依赖,例如:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
3.编写Spring Boot应用程序的入口类,例如:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
4.在入口类中,可以添加一些配置和组件,例如定义数据源、配置日志等。
至此,一个简单的Spring Boot项目就搭建完成了。接下来,我们将介绍如何集成OpenAI接口实现ChatGPT功能。
为了实现ChatGPT功能,我们需要先了解OpenAI接口的相关信息。OpenAI是一个人工智能技术公司,提供了各种自然语言处理的API,其中包括了ChatGPT功能。ChatGPT是一个强大的对话生成模型,可以根据输入的对话历史生成下一句话。
要使用OpenAI接口,我们需要进行以下步骤:
1.注册OpenAI账号并获取API密钥:在OpenAI官网注册一个账号,并获取API密钥,用于进行API请求。
2.集成OpenAI接口到Spring Boot项目:添加OpenAI的API依赖到项目中,我这里使用的是另外一个开源项目chatgpt-java,例如:
<dependency>
<groupId>com.unfbx</groupId>
<artifactId>chatgpt-java</artifactId>
<version>1.0.12</version>
</dependency>
3.使用webSocket。
WebSocket是一种在客户端和服务器之间实现双向通信的协议,通过该协议可以在服务端主动向客户端推送数据,实现实时的双向通信。与传统的HTTP请求-响应模式不同,WebSocket的连接一旦建立,客户端和服务器可以持久性地保持连接,双方可以随时发送和接收消息,达到实时通信的效果。这种实时通信对于聊天应用、实时数据展示和协同编辑等场景非常有用。
(1)添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
(2)建立连接,这里需要参数用户id
@OnOpen
public void onOpen(Session session, @PathParam("uid") String uid) {
log.info("websocket open,uid:{}", uid);
this.session = session;
this.uid = uid;
webSocketSet.add(this);
SESSIONS.add(session);
if (chatWebSocketMap.containsKey(uid)) {
chatWebSocketMap.remove(uid);
chatWebSocketMap.put(uid, this);
} else {
chatWebSocketMap.put(uid, this);
addOnlineCount();
}
log.info("websocket onOpen, userId:{}, online count:{}", this.uid, getOnlineCount());
}
(3)接收前端消息,并调用openAI。
因为websocket只能有定义一个字符串进行前后端交互,所以如果我们需要传递多个参数的话,需要将其转换为json字符串传递进来,并在接受后进行解析。如下所示,我们需要将roleId传递进来,roleId代表是和哪一个角色进行对话,这个在后面会用到,messages列表,里面存放了历史对话记录,这里传递进来是为了保持上下文进行通信,创建一个EventSourceListener,并把session传入进去,最后ChatCompletion 就是与openAI交互的结构体。
@OnMessage
public void onMessage(String message) {
log.info("onMessage, userId:{} ", this.uid);
JSONObject jsonObject = JSONUtil.parseObj(message);
Integer roleId = jsonObject.getInt("roleId");
String messageString = jsonObject.getStr("message");
List<Message> messages = new ArrayList<>();
messages = JSONUtil.toList(messageString, Message.class);
//接受参数
OpenAIWebSocketEventSourceListener eventSourceListener = new OpenAIWebSocketEventSourceListener(this.session);
ChatCompletion chatCompletion = buildChatCompletion(roleId, messages);
openAiStreamClient.streamChatCompletion(chatCompletion, eventSourceListener);
}
(4)组装报文。
我们可以将每一种角色的prompt,使用到的模型,最大token等参数,保存到数据库中,根据roleId进行获取,然后组装成ChatCompletion。其中,message结构体中,包含了role和content,role分为三种,分别是system,user,assistant。其中system是系统指定的,里面可以存放你的prompt,用来告诉chatGPT,它现在要扮演什么角色,要怎么输出内容,都可以在system指令中进行指定。user为用户输入的文本。assistant为chatGPT的回答的文本。model中可以指定自己使用的模型,可以使用gpt-3.5-turbo,gpt-4-32k等,根据自己实际情况进行选择。
private ChatCompletion buildChatCompletion(int id, List<Message> messages) {
ChatCompletion chatCompletion;
Role role = roleService.getRoleById(id);
if (role != null) {
Message roleMessage = Message.builder().content(role.getRoleMessage())
.role(Message.Role.SYSTEM).build();
messages.add(0, roleMessage);
chatCompletion = ChatCompletion.builder()
.temperature(role.getTemperature())
.model(role.getModel())
.maxTokens(role.getMaxTokens())
.topP(role.getTopP())
.presencePenalty(role.getPresencePenalty())
.frequencyPenalty(role.getFrequencyPenalty())
.messages(messages)
.stream(true)
.user(this.uid)
.build();
} else {
chatCompletion = ChatCompletion.builder()
.messages(messages)
.stream(true)
.user(this.uid)
.build();
}
return chatCompletion;
}
(5)发送请求到openAI
public void streamChatCompletion(ChatCompletion chatCompletion, EventSourceListener eventSourceListener) {
if (Objects.isNull(eventSourceListener)) {
log.error("参数异常:EventSourceListener不能为空,可以参考:com.unfbx.chatgpt.sse.ConsoleEventSourceListener");
throw new BaseException(CommonError.PARAM_ERROR);
} else {
if (!chatCompletion.isStream()) {
chatCompletion.setStream(true);
}
try {
EventSource.Factory factory = EventSources.createFactory(this.okHttpClient);
ObjectMapper mapper = new ObjectMapper();
String requestBody = mapper.writeValueAsString(chatCompletion);
Request request = (new Request.Builder()).url(this.apiHost + "v1/chat/completions").post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), requestBody)).build();
factory.newEventSource(request, eventSourceListener);
} catch (JsonProcessingException var8) {
log.error("请求参数解析异常:{}", var8);
var8.printStackTrace();
} catch (Exception var9) {
log.error("请求参数解析异常:{}", var9);
var9.printStackTrace();
}
}
}
上面代码中,通过okHttpClient创建了一个EventSource.Factory对象,然后创建了一个ObjectMapper对象,用于将数据转换为JSON格式。使用ObjectMapper将completion对象转换为JSON字符串,存储在requestBody变量中,使用ObjectMapper将completion对象转换为JSON字符串,存储在requestBody变量中,最后通过已创建的EventSource.Factory对象调用newEventSource方法,传入创建的Request对象和eventSourceListener参数。这样就创建了一个EventSource对象,并开始监听事件。简单来说,这段代码的作用是创建一个EventSource对象,并发送一个POST请求。
现在有两项技术需要解释一下,分别是okHttpClient和EventSource。
okHttpClient
okHttpClient是一个开源的Java HTTP客户端库,由Square公司开发。它提供了一个简单易用的接口,用于发送HTTP请求并处理响应。
特点:
-
支持同步和异步请求:okHttpClient可以发送同步和异步的HTTP请求。同步请求会阻塞当前线程,直到接收到服务器的响应;异步请求则使用回调函数来处理响应。
-
连接池管理:okHttpClient使用连接池来管理和复用HTTP连接,从而降低网络请求的延迟。它支持并发请求和多线程环境下的高效连接复用。
-
支持HTTP/2和SPDY协议:okHttpClient支持最新的HTTP/2和SPDY协议,可以提供更快的传输速度和更低的网络延迟。
-
支持拦截器:okHttpClient提供了拦截器机制,可以在请求和响应的不同阶段进行自定义操作,例如添加请求头、日志记录等。
-
支持重试和重定向:okHttpClient可以自动处理请求的失败、重试和重定向,减少开发者处理这些场景的工作量。
-
可扩展性和灵活性:okHttpClient通过插件系统提供了很高的可扩展性,并且可以根据实际需求进行各种配置,如超时设置、缓存策略等。
总的来说,okHttpClient是一个功能强大、易于使用和高效的Java HTTP客户端库,用于发送HTTP请求并处理响应,适用于各种网络场景和需求。
EventSource
EventSource是HTML5中定义的一种客户端API,也被称为服务器发送事件(Server-Sent Events)。它提供了一种在客户端与服务器之间实现单向通信的机制。以下是EventSource的作用和详细解释:
作用:
-
实时数据推送:EventSource可以与服务器建立长连接,通过服务器推送数据,实现实时更新,而无需客户端主动请求。
-
可靠性:EventSource会自动恢复与服务器连接,即使网络连接中断或重新连接。
-
简化开发:相比于WebSocket,EventSource更为简单易用,不需要进行握手等繁琐的操作。
工作原理:
-
客户端通过创建EventSource对象,并指定服务器端的URL来与服务器进行连接。
-
服务器向客户端发送事件流(event stream),可以包含不同类型的事件(event),每个事件都包含一个事件类型(event type)和事件数据(event data)。
-
客户端通过监听EventSource对象的相关事件来获取服务器发来的数据,如onmessage事件用于接收消息,onerror事件用于处理连接错误,等等。
优点:
-
对于服务器推送数据的场景非常适用,特别是在实时性要求较高且数据量较小的情况下。
-
内部自动处理了连接状态、网络中断等问题,减轻了开发者的负担。
-
不需要考虑跨域问题,因为EventSource默认支持跨域访问。
需要注意的是,EventSource与WebSocket的区别在于数据传输方式。WebSocket提供了双向通信的能力,并支持客户端和服务器端之间的全双工通信,而EventSource只支持服务器向客户端的单向数据推送。
我们这里后端代码调用openAI使用的是EventSource,前端和后端通信用的是WebSocket,其实都可以使用EventSource。
(6)监听openAI响应
我们通过EventSourceListener监听
public void onEvent(EventSource eventSource, String id, String type, String data) {
if (data.equals("[DONE]")) {
log.info("OpenAI返回数据结束了");
session.getBasicRemote().sendText("[DONE]");
return;
}
ObjectMapper mapper = new ObjectMapper();
ChatCompletionResponse completionResponse = mapper.readValue(data, ChatCompletionResponse.class);
String delta = mapper.writeValueAsString(completionResponse.getChoices().get(0).getDelta());
session.getBasicRemote().sendText(delta);
}
session对象代表了客户端与服务器之间的一个会话连接。它是WebSocket中的一个核心对象,用于进行数据交互。session.getBasicRemote()方法返回RemoteEndpoint.Basic对象,通过该对象可以向客户端发送消息。
sendText()方法是RemoteEndpoint.Basic对象的一个方法,用于发送文本消息到客户端。delta是要发送的文本消息内容。这句代码的作用是将delta文本消息发送给客户端,实现服务器向客户端的实时消息推送功能,这样,之前和后端建立好WebSocket连接的前端,就可以接收到来自chatGPT的响应了。
数据库结构
主要涉及到3张表,分别为role_type,role_desc和role。其中,role_type表是存放角色分类的,如娱乐、生活、工作、学习、健康等。
建表语句如下:
CREATE TABLE `role_type` (
`id` varchar(64) NOT NULL COMMENT '主键',
`role_type_name` varchar(256) NOT NULL COMMENT '类别名称',
`sort_num` decimal(10,2) NOT NULL DEFAULT '1.00' COMMENT '排序序号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='角色类别表';
role_desc表是角色描述信息表,其中包含了角色名称,简介,图片等内容,主要是用于角色列表展示的。
建表语句如下:
CREATE TABLE `role_desc` (
`id` varchar(10) NOT NULL COMMENT '主键',
`title` varchar(512) NOT NULL COMMENT '标题',
`description` text COMMENT '内容',
`chat` text COMMENT '聊天内容',
`image` varchar(128) NOT NULL COMMENT '图片',
`role_id` int DEFAULT NULL COMMENT 'roleId',
`sort_num` decimal(10,2) NOT NULL DEFAULT '1.00' COMMENT '排序序号',
`post_status` smallint DEFAULT '0' COMMENT '上线状态',
`create_date` datetime DEFAULT NULL COMMENT '创建时间',
`update_date` datetime DEFAULT NULL COMMENT '更新时间',
`role_type_id` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `type_index` (`role_type_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='角色描述表';

role表,是角色参数表,用于保存角色的prompt和调用openAI的一些核心参数,如模型,最大token等
建表语句如下:
CREATE TABLE `role` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '唯一标识,自动递增',
`role_name` varchar(255) DEFAULT NULL,
`role_message` text,
`model` varchar(255) NOT NULL DEFAULT 'gpt-3.5-turbo',
`create_time` datetime NOT NULL,
`temperature` double NOT NULL DEFAULT '0.2',
`max_tokens` int NOT NULL DEFAULT '2048',
`top_p` double NOT NULL DEFAULT '1',
`presence_penalty` double NOT NULL DEFAULT '0',
`frequency_penalty` double NOT NULL DEFAULT '0',
`n` int NOT NULL DEFAULT '1',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb3;

总结
本次分享,只分享了后端代码,前端和小程序端,下次继续分享。如果你想继续了解的话,可以关注我的公众号【程序员修炼】。
最后,代码获取方式,关注公众号,发送"ChatGPTService"获取后端代码,发送"ChatGPTWeChat"获取小程序代码,发送"ChatGPTWeb"获取前端代码。
另外,有任何问题,可加我微信【cxyxl66】进行咨询,来者不拒。



![考核:QTableWidget开发[折叠/展开单元格QTableWidgetItem]](https://img-blog.csdnimg.cn/9ce1011df8cd48ec84ea81c5c824c0b5.png)