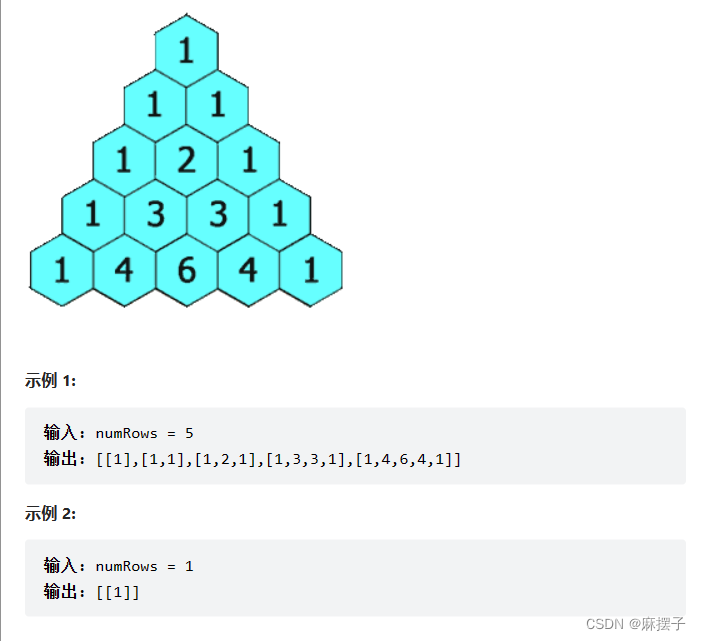
Redis五大基本数据结构
String,Hash,List,Set,ZSet
String
String是Redis最基本的数据结构,用来设置KV键值对,redis有16个数据库,可直接在当前数据库中set添加String的KV对。
使用场景
- KV对,记录学生ID和姓名。<ID, NAME>
- 对象的JSON存储
可以把对象的json存为String的KV对。
比如以学生学号为KEY,以json为VAL;
SET myjson "{\"name\":\"John\", \"age\": 30, \"city\":\"New York\"}"
GET myjson
=========== Output ===========
"{\"name\":\"John\", \"age\": 30, \"city\":\"New York\"}"
- 实现分布式锁:
多线程使用Redis时,如果产生资源竞争的情况,比如同时去修改某个资源,可以通过setnx或setex来做线程间同步,以及通过控制某个线程占有资源的时间避免死锁。
setnx:该函数设置KV对时,如果K已经存在,则能设置,若创建失败说明已经存在了。当分布式场景抢占资源时,线程1先来先创建KEY,如果线程2创建不成功,则线程1等待。因为Redis是单线程的,是线程安全的。线程1访问完临界资源后再删除KEY。线程2就可以创建KEY了。
setex:可以设置KEY的存活时间,避免线程一直占有资源不做释放而引发死锁。
psetex:单位是毫秒的设置过期时间的方法。
- 计数器
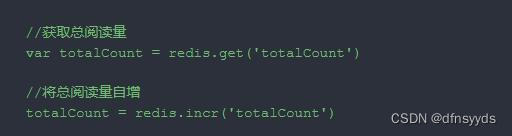
微博热门帖子的文章阅读人数。每当用户点进去,就执行一次INCR命令。对某个值做加1操作。
INCR的使案例:
(下面的‘article:1234’看起来奇怪,其实整体是个key)
1> 设置key:编号为1234的文章初始化阅读量为1 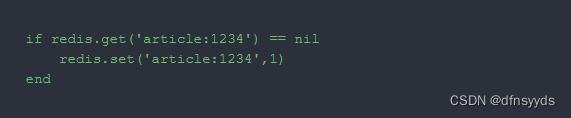
2> 每当有用户访问,就用INCR增加1

3> 当前文章阅读数量+1,总阅读量也+1(有场景不需要)
·incr相关操作
incr:表示+1
incrbyfloat:+n
decr:value-1。
decrby:val-n。
incrbyfloat:val做加减法均可
- 分布式系统全局序列号
mysql自增id已经到最大值, 无法满足分库分表下的id自增,需要独立的数据库中级来分配id。redis的incr命令可以实现id、序列号的生成。
用户多的场景下,不要每次取1个id,在redis中自增1000次,把序列号放入本地内存,当1000个id用完后,再去redis取,可以有效降低redis压力。
Hash
Redis中常用Hash存对象,每个hash像是一个对象的表中存了多组KV对,KV对代表成员变量和值。
Hset key field value
Hget key
使用场景:
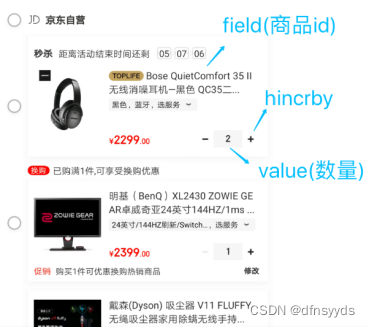
- 电商购物车:
一个用户只有一个购物车。用户1001的购物车可设对象键值为:‘cart:1001’。
商品ID和添加数可记录为成员变量和值。
1)以用户id为key === cart:1001
2)商品id为field === 10088
3)商品数量为value === 1
购物车操作:
1)添加商品 hset cart:1001 10088 1
2)增加数量 hincrby cart:1001 10088 1
3)商品总数 hlen cart:1001
4)删除商品 hdel cart:1001 10088
5)获取购物车所有商品 hgetall cart:1001
优点:
- 方便管理,寻找方便,这样有数据之间是有逻辑关系的
- 比string更节省空间,一个对象类型有很多KV,如果都用KV存储,就很费内存空间,内存空间很重要,是节点数。一个hash表的key,可以关联很多。
缺点:
- 不如String灵活,过期功能不能在字段,只能在哈希表上,hash的key上,也就是hash表名。
- 在redis集群架构下不适合大规模使用,因为hash的KV对太多,都存在1个节点上,hash节点的压力会比其他节点压力大,使得redis集群压力分配不均衡。一台存10万个hash节点的机器,负载远比存10万个string的机器压力大。
List
有序列表,类似队列或栈,取决于你使用lpush还是rpush。
函数操作
lpush:插入,不存list就创建
lpop:
lpop:
rpop:
场景
- 阻塞队列
阻塞队列有两个特性: 线程安全和阻塞(队列空时,出队就会阻塞,队列满,入队会阻塞)。
而redis中的list相当于阻塞队列。它能保证线程安全,通过单线程模型来支持的。阻塞则只支持“队列为空”的情况,不考虑“队列满”。虽然有上限,但上限比较大。
实现:
1>如果list中存在元素,redis的blpop和brpop和lpop、rpop效果相同,当list为空,blpop和brpop会产生阻塞,一直阻塞到队列不空为止。
2> 阻塞时间可以设置,不一定是一直等待,等太久没有就走
3>阻塞期间,redis服务器还可以处理其它请求(特殊设定)。
-
消息队列
消息队列相当于在阻塞队列上加了“消息类型”,先进先出再增加上按照指定类型做。 -
排行榜:分页查询的应用
mybatis面试中常问的一个问题。redis的list中Lrange可以设定获取哪些范围到的值,效率很高。 -
公众号文章关注列表
当小明关注了多个订阅号,当订阅号更新后,通过LPUSH把内容发送到小明的信息list中。
如果是小明想获取大V的信息时,用LRANGE从不同订阅号队列中读取指定个数个信息。
(一个主题场景下,包含着多个同类型的内容数据可以使用list结构) -
微博大V粉丝列表
redis的list可存量非常大42亿。
Set
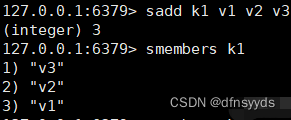
无序的去重集合。
sadd key:
srem key:
可以跟很多个值
场景
1>用户画像:极短字符串。因为随机存取效率高于list。
推荐系统中的应用,给某个用户贴一系列标签,而且方便寻找与其它集合的交集、差集等,寻找近邻用户和近邻商品,所以存set集合是很好的选择。
2>统计UV:
UV(访客数):set本身是去重,把日志中的唯一列存入Set中,天然的去重后查看set集合数即UV。
PV(页面访问量):页面访问
3>关注的人也关注了他
集合的差集。
4> 一切集合运算的场景
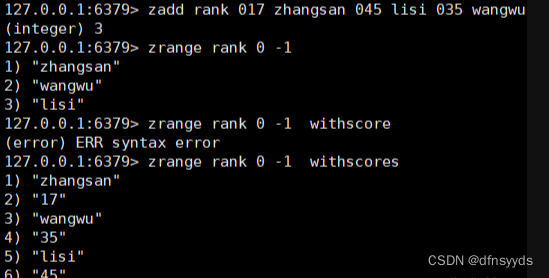
Zset:底层是跳表
有序的去重集合,排序是基于每个元素有值的,需要设定key和排序的数值。
zadd
zget
zrem
场景
1> 微博热搜:
zset可以统计PV,也就是页面访问次数,而页面访问次数排序后,就是热搜。
需要集合中元素带顺序,就是热搜中的TOK问题。
2 最高热度:
当日前10、月度前10等系列同类型寻找最高热度的排序数据。
redis还有特殊数据结构:
1 geospatial:推算地理位置
2 hyperloglog:基数统计(找1个或多个集合里面总共的不重复的元素)
2.8.9中更新了,有算法可以用来做:网页UV,多少用户访问。
传统方式的做法:用set(无序集合)存用户id,如果保存大量用户,有的ID比如分布式ID比较大,用户量太大,消耗了大量内存存用户ID,目的是为了计数,不是存用户ID。优点:占用的内存是固定的。
通过han p log log需要12KB内存,但是有0.81%错误率,就能统计出页面UV。
PFCOUNT
3 bitmap:记录大场景下的每个个体的状态
直接统计用户是否在线,或者是否活跃,打卡未打卡。95MB就能存1E个位数据,能看到1E的用户谁在线。
而C++ for循环1E次,只需要1秒。所以效率非常高。
4 redis中的布隆过滤器:
是redis中的一种数据结构,它将MySQL数据库中所有可能存在的数据都缓存到布隆过滤器中。当攻击者访问不存在的数据时迅速返回避免请求打到数据库上导致数据库宕机问题。
Bloom Filter 是一种空间效率很高的随机数据结构,底层利用了位图。布隆过滤器能确定一定不存在,但是不能保证真实存在,利用哈希,给每个位置做记录。但不同的值可能影响,所以位图要开大一点,多用几个哈希函数。



](https://img-blog.csdnimg.cn/9a639a1eac2f440bb6146b5d5c4a065b.png#pic_center)