文章目录
- 26 Sigmoid Belief Network
- 26.1 背景介绍
- 26.2 通过log-likelihood推断SBN的后验
- 26.3 醒眠算法——Wake Sleep Algorithm
26 Sigmoid Belief Network
26.1 背景介绍
什么是Sigmoid Belief Network?Belief Network等同于Bayesian Network,表示有向图模型。sigmoid指sigmoid函数,具体表示为 σ ( x ) = 1 1 + e x p { − x } \sigma(x) = \frac{1}{1 + exp{\lbrace -x \rbrace}} σ(x)=1+exp{−x}1。
具体举一个Sigmoid Belief Network的例子:
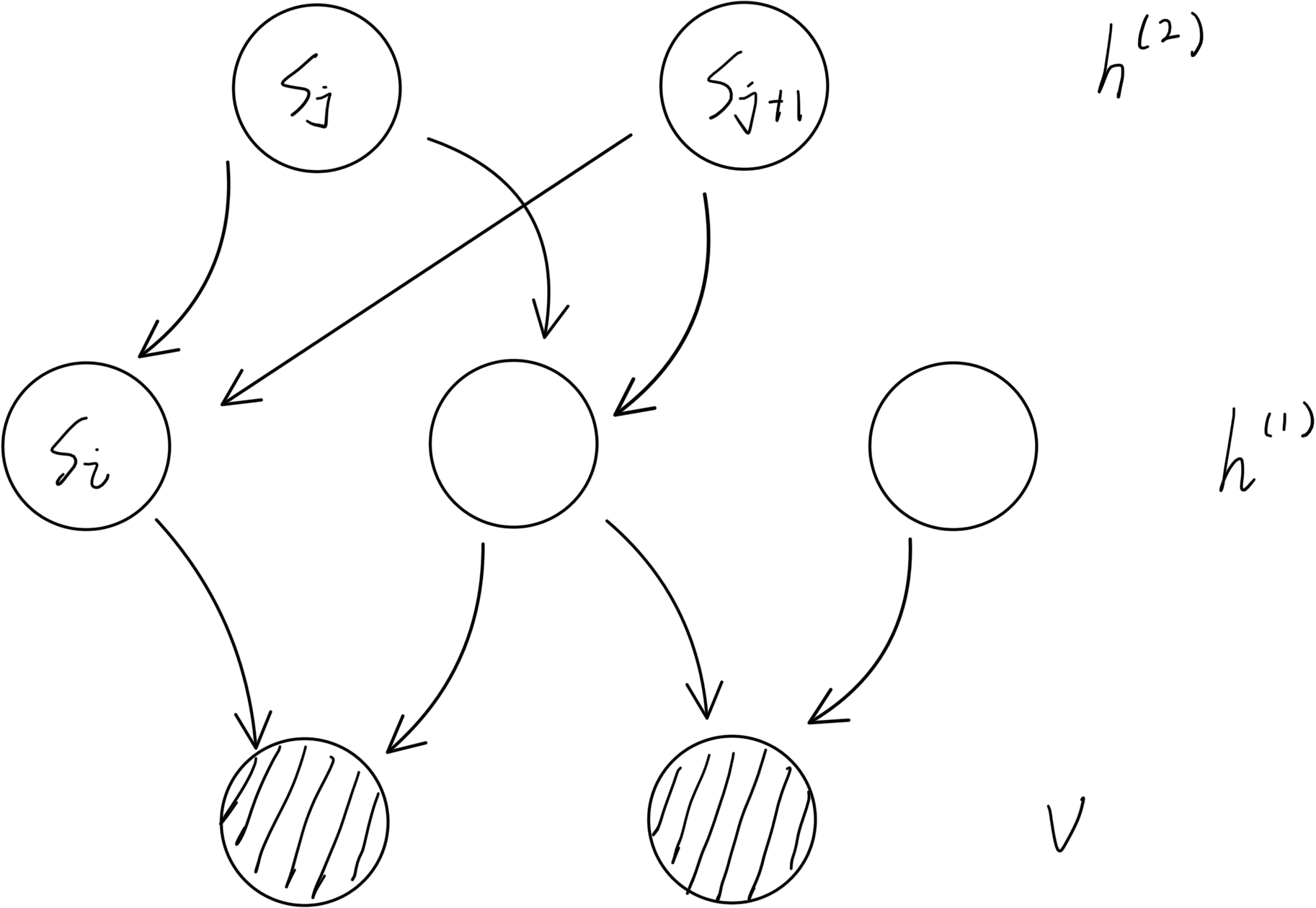
一个Sigmoid Belief Network如上图所示,由一个数据层与多个隐藏层组成,每层之间都没有直接的连接关系。
我们可以通过sigmoid函数从根节点将每个节点的概率分布进行求解,例如我们求解
S
i
S_i
Si节点的概率分布,因为我们一般将节点的值设置为0/1变量,所以可以写作:
{
P
(
S
i
=
1
∣
S
j
:
j
<
i
)
=
σ
(
∑
j
<
i
w
j
i
S
j
)
P
(
S
i
=
0
∣
S
j
:
j
<
i
)
=
1
−
P
(
S
i
=
1
)
=
σ
(
−
∑
j
<
i
w
j
i
S
j
)
\begin{cases} P(S_i = 1| S_j: j<i) = \sigma( \sum_{j<i} w_{ji} S_j ) \\ P(S_i = 0| S_j: j<i) = 1 - P(S_i = 1) = \sigma( - \sum_{j<i} w_{ji} S_j ) \end{cases}
{P(Si=1∣Sj:j<i)=σ(∑j<iwjiSj)P(Si=0∣Sj:j<i)=1−P(Si=1)=σ(−∑j<iwjiSj)
我们也可以将其表达为一个整式:
{
P
(
S
i
∣
S
j
:
j
<
i
)
=
σ
(
S
i
∗
∑
j
<
i
w
j
i
S
j
)
S
i
∗
=
2
S
i
−
1
\begin{cases} P(S_i| S_j: j<i) = \sigma( S_i^* \sum_{j<i} w_{ji} S_j ) \\ S_i^* = 2 S_i - 1 \end{cases}
{P(Si∣Sj:j<i)=σ(Si∗∑j<iwjiSj)Si∗=2Si−1
即使我们这样可以获得样本,但是我们发现其实后验还是求不出来的,以为隐藏层之间并非相互独立,关系非常的麻烦。
26.2 通过log-likelihood推断SBN的后验
首先根据上文我们可以得到两个条件:
{
P
(
S
i
∣
S
j
:
j
<
i
)
=
σ
(
S
i
∗
∑
j
<
i
w
j
i
S
j
)
P
(
S
)
=
∏
i
=
1
∣
S
∣
P
(
S
i
∣
S
j
:
j
<
i
)
=
P
(
V
,
H
)
\begin{cases} P(S_i| S_j: j<i) = \sigma( S_i^* \sum_{j<i} w_{ji} S_j ) \\ P(S) = \prod_{i=1}^{|S|} P(S_i| S_j: j<i) = P(V, H) \end{cases}
{P(Si∣Sj:j<i)=σ(Si∗∑j<iwjiSj)P(S)=∏i=1∣S∣P(Si∣Sj:j<i)=P(V,H)
这两个条件分别表示我们的条件概率与联合概率,通过这两个公式我们就可以对log-likelihood进行如下变换:
l
o
g
−
l
i
k
e
l
i
h
o
o
d
=
1
N
∑
v
∈
V
log
P
(
v
)
∇
w
j
i
log
P
(
v
)
=
1
P
(
v
)
∇
w
j
i
P
(
v
)
=
P
(
H
∣
v
)
P
(
H
,
v
)
∇
w
j
i
∑
H
P
(
v
,
H
)
=
∑
H
P
(
H
∣
v
)
P
(
H
,
v
)
∇
w
j
i
P
(
v
,
H
)
=
∑
S
P
(
S
∣
v
)
1
P
(
S
)
∇
w
j
i
P
(
S
)
=
∑
S
P
(
S
∣
v
)
∇
w
j
i
∏
k
=
1
∣
S
∣
P
(
S
k
∣
S
j
:
j
<
k
)
∏
k
=
1
∣
S
∣
P
(
S
k
∣
S
j
:
j
<
k
)
\begin{align} log-likelihood &= \frac{1}{N} \sum_{v \in V} \log P(v) \\ \nabla_{w_{ji}} \log P(v) &= \frac{1}{P(v)} \nabla_{w_{ji}} P(v) \\ &= \frac{P(H|v)}{P(H, v)} \nabla_{w_{ji}} \sum_{H} P(v, H) \\ &= \sum_{H} \frac{P(H|v)}{P(H, v)} \nabla_{w_{ji}} P(v, H) \\ &= \sum_{S} P(S|v) \frac{1}{P(S)} \nabla_{w_{ji}} P(S) \\ &= \sum_{S} P(S|v) \frac{\nabla_{w_{ji}} \prod_{k=1}^{|S|} P(S_k| S_j: j<k)}{\prod_{k=1}^{|S|} P(S_k| S_j: j<k)} \\ \end{align}
log−likelihood∇wjilogP(v)=N1v∈V∑logP(v)=P(v)1∇wjiP(v)=P(H,v)P(H∣v)∇wjiH∑P(v,H)=H∑P(H,v)P(H∣v)∇wjiP(v,H)=S∑P(S∣v)P(S)1∇wjiP(S)=S∑P(S∣v)∏k=1∣S∣P(Sk∣Sj:j<k)∇wji∏k=1∣S∣P(Sk∣Sj:j<k)
答疑:
- 对于上面为什么 P ( H , v ) = P ( S ) P(H, v) = P(S) P(H,v)=P(S):因为v在这里表示的是一个随机变量,所以 P ( H , v ) P(H, v) P(H,v)也可以写成 P ( H , V = v ) P(H, V=v) P(H,V=v)
- 上文中为什么 ∑ H P ( H ∣ v ) ⟺ ∑ S P ( S ∣ v ) \sum_{H} P(H|v) \iff \sum_{S} P(S|v) ∑HP(H∣v)⟺∑SP(S∣v),因为这里 S S S表示联合概率分布实际上 P ( S ∣ v ) P(S|v) P(S∣v)应该表达为 P ( H , v ∣ v ) P(H, v|v) P(H,v∣v),但是 P ( H , v ∣ v ) ⟺ P ( H ∣ v ) P(H, v|v) \iff P(H|v) P(H,v∣v)⟺P(H∣v),所以没问题
因为上文中
P
(
S
)
P(S)
P(S)中实际只有一项与
w
j
i
w_{ji}
wji相关,所以可以的得到:
∇
w
j
i
log
P
(
v
)
=
∑
S
P
(
S
∣
v
)
∇
w
j
i
P
(
S
i
∣
S
j
:
j
<
i
)
P
(
S
i
∣
S
j
:
j
<
i
)
=
∑
S
P
(
S
∣
v
)
∇
w
j
i
σ
(
S
i
∗
∑
j
<
i
w
j
i
S
j
)
σ
(
S
i
∗
∑
j
<
i
w
j
i
S
j
)
=
∑
S
P
(
S
∣
v
)
σ
(
S
i
∗
∑
j
<
i
w
j
i
S
j
)
⋅
σ
(
−
S
i
∗
∑
j
<
i
w
j
i
S
j
)
⋅
S
i
∗
⋅
S
j
σ
(
S
i
∗
∑
j
<
i
w
j
i
S
j
)
=
∑
S
P
(
S
∣
v
)
σ
(
−
S
i
∗
∑
j
<
i
w
j
i
S
j
)
⋅
S
i
∗
⋅
S
j
\begin{align} \nabla_{w_{ji}} \log P(v) &= \sum_{S} P(S|v) \frac{\nabla_{w_{ji}} P(S_i| S_j: j<i)}{P(S_i| S_j: j<i)} \\ &= \sum_{S} P(S|v) \frac{\nabla_{w_{ji}} \sigma( S_i^* \sum_{j<i} w_{ji} S_j )}{\sigma( S_i^* \sum_{j<i} w_{ji} S_j )} \\ &= \sum_{S} P(S|v) \frac{\sigma( S_i^* \sum_{j<i} w_{ji} S_j ) \cdot \sigma( - S_i^* \sum_{j<i} w_{ji} S_j ) \cdot S_i^* \cdot S_j}{\sigma( S_i^* \sum_{j<i} w_{ji} S_j )} \\\\ &= \sum_{S} P(S|v) \sigma( - S_i^* \sum_{j<i} w_{ji} S_j ) \cdot S_i^* \cdot S_j \\ \end{align}
∇wjilogP(v)=S∑P(S∣v)P(Si∣Sj:j<i)∇wjiP(Si∣Sj:j<i)=S∑P(S∣v)σ(Si∗∑j<iwjiSj)∇wjiσ(Si∗∑j<iwjiSj)=S∑P(S∣v)σ(Si∗∑j<iwjiSj)σ(Si∗∑j<iwjiSj)⋅σ(−Si∗∑j<iwjiSj)⋅Si∗⋅Sj=S∑P(S∣v)σ(−Si∗j<i∑wjiSj)⋅Si∗⋅Sj
所以我们可以得到:
∇
w
j
i
l
o
g
−
l
i
k
e
l
i
h
o
o
d
=
1
N
∑
v
∈
V
∑
S
[
P
(
S
∣
v
)
σ
(
−
S
i
∗
∑
j
<
i
w
j
i
S
j
)
⋅
S
i
∗
⋅
S
j
]
\nabla_{w_{ji}} log-likelihood = \frac{1}{N} \sum_{v \in V} \sum_{S} \left[ P(S|v) \sigma( - S_i^* \sum_{j<i} w_{ji} S_j ) \cdot S_i^* \cdot S_j \right]
∇wjilog−likelihood=N1v∈V∑S∑[P(S∣v)σ(−Si∗j<i∑wjiSj)⋅Si∗⋅Sj]
但是这个东西我们求不出来,为什么呢?因为这里面有
P
(
S
∣
v
)
P(S|v)
P(S∣v),也就是后验。由于SBN图的性质,隐节点之间并不相互独立,所以没法求解。我们其实也可以通过MCMC进行求解,我们可以把公式转换为(常数项都删掉):
∇
w
j
i
l
o
g
−
l
i
k
e
l
i
h
o
o
d
=
E
H
∽
P
(
S
∣
v
)
,
v
∽
P
d
a
t
a
[
σ
(
−
S
i
∗
∑
j
<
i
w
j
i
S
j
)
⋅
S
i
∗
⋅
S
j
]
\nabla_{w_{ji}} log-likelihood = E_{H \backsim P(S|v), v \backsim P_{data}} \left[ \sigma( - S_i^* \sum_{j<i} w_{ji} S_j ) \cdot S_i^* \cdot S_j \right]
∇wjilog−likelihood=EH∽P(S∣v),v∽Pdata[σ(−Si∗j<i∑wjiSj)⋅Si∗⋅Sj]
但是由于后验过于复杂,所以MCMC只能完成节点较少的SBN。
26.3 醒眠算法——Wake Sleep Algorithm
醒眠算法实际上是求解SBN的一个启发式算法,什么是启发式算法呢?就是不求精确,但求能求解出来。
为了实现该算法,我们首先要对我们的图增加一些条件,做出一些假设如下图:
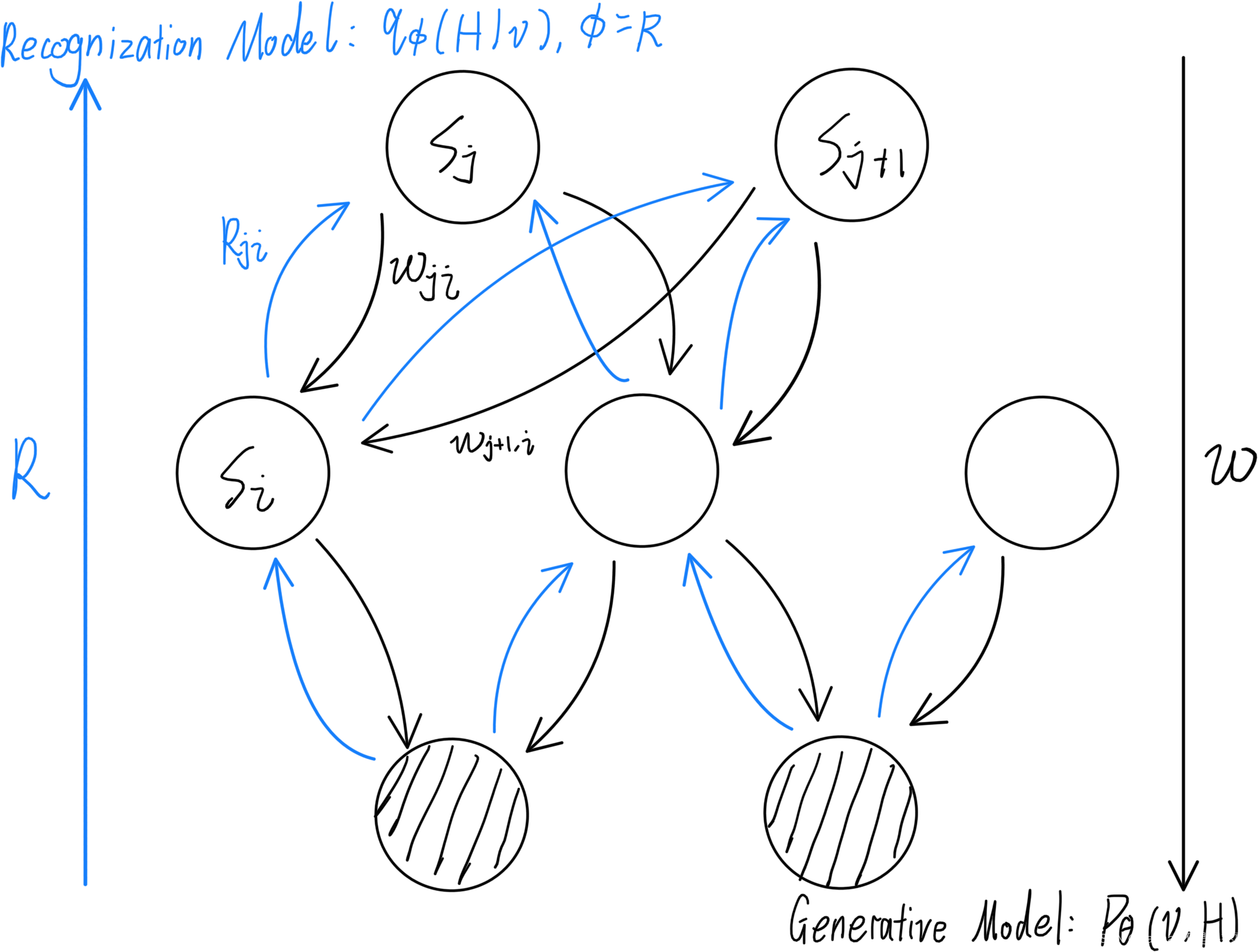
我们将所有节点之间的连接 w j i w_{ji} wji做出其反向连接,并取名为 R j i R_{ji} Rji。
醒眠算法正如其名,分为两个步骤:
- wake:从下往上(图中蓝色部分),通过已知条件(训练数据)对 H H H进行采样,假定反向图的参数为 ϕ \phi ϕ(已知),我们可以通过分布 q ϕ ( H ∣ v ) q_\phi (H|v) qϕ(H∣v)求得sleep需要用的参数 θ \theta θ
- sleep:从上往下(图中黑色部分),根据wake步得到的样本数据对 v v v采样,通过分布 P θ ( v , H ) P_\theta (v, H) Pθ(v,H)求取下一个wake步需要用的参数 ϕ \phi ϕ,此时 θ \theta θ已知(上一个wake步求到的)。
我们具体的目标函数表示为:
-
wake:通过分布 q ϕ ( H ∣ v ) q_\phi (H|v) qϕ(H∣v)求 θ \theta θ:
θ ( i ) = a r g max θ E q ϕ ( i ) ( H ∣ v ) [ log P θ ( H , v ) ] = a r g max θ L ( θ ) ⏟ E L B O + K L − H [ q ] = a r g min θ K L ( q ϕ ( i ) ( H ∣ v ) ∥ P θ ( H , v ) ) \begin{align} \theta^{(i)} &= arg\max_\theta E_{q_{\phi^{(i)}} (H|v)} \left[ \log P_\theta(H, v) \right] \\ &= arg\max_\theta \underbrace{{\mathcal L} (\theta)}_{ELBO + KL} - H[q] \\ &= arg\min_\theta KL(q_{\phi^{(i)}} (H|v) \Vert P_\theta(H, v)) \\ \end{align} θ(i)=argθmaxEqϕ(i)(H∣v)[logPθ(H,v)]=argθmaxELBO+KL L(θ)−H[q]=argθminKL(qϕ(i)(H∣v)∥Pθ(H,v)) -
sleep:通过分布 P θ ( v , H ) P_\theta (v, H) Pθ(v,H)求 ϕ \phi ϕ:
ϕ ( i + 1 ) = a r g max ϕ E P θ ( i ) ( H , v ) [ log q ϕ ( H ∣ v ) ] = a r g max ϕ ∫ P θ ( i ) ( H , v ) log q ϕ ( H ∣ v ) d H = a r g max ϕ ∫ P θ ( i ) ( v ) ⋅ P θ ( i ) ( H ∣ v ) ⋅ log ( q ϕ ( H ∣ v ) P θ ( i ) ( H ∣ v ) P θ ( i ) ( H ∣ v ) ) d H = a r g max ϕ ∫ P θ ( i ) ( H ∣ v ) ⋅ log q ϕ ( H ∣ v ) P θ ( i ) ( H ∣ v ) d H = a r g min ϕ K L ( P θ ( i ) ( H , v ) ∥ q ϕ ( H ∣ v ) ) \begin{align} \phi^{(i + 1)} &= arg\max_\phi E_{P_{\theta^{(i)}}(H, v)} \left[ \log q_{\phi} (H|v) \right] \\ &= arg\max_\phi \int {P_{\theta^{(i)}}(H, v)} \log q_{\phi} (H|v) {\rm d}H \\ &= arg\max_\phi \int P_{\theta^{(i)}}(v) \cdot P_{\theta^{(i)}}(H| v) \cdot \log \left( \frac{q_{\phi} (H|v)}{P_{\theta^{(i)}}(H| v)} P_{\theta^{(i)}}(H| v) \right) {\rm d}H \\ &= arg\max_\phi \int P_{\theta^{(i)}}(H| v) \cdot \log \frac{q_{\phi} (H|v)}{P_{\theta^{(i)}}(H| v)} {\rm d}H \\ &= arg\min_\phi KL(P_{\theta^{(i)}}(H, v) \Vert q_\phi (H|v)) \\ \end{align} ϕ(i+1)=argϕmaxEPθ(i)(H,v)[logqϕ(H∣v)]=argϕmax∫Pθ(i)(H,v)logqϕ(H∣v)dH=argϕmax∫Pθ(i)(v)⋅Pθ(i)(H∣v)⋅log(Pθ(i)(H∣v)qϕ(H∣v)Pθ(i)(H∣v))dH=argϕmax∫Pθ(i)(H∣v)⋅logPθ(i)(H∣v)qϕ(H∣v)dH=argϕminKL(Pθ(i)(H,v)∥qϕ(H∣v))
我们发现上面的步骤和EM算法很想,但又不一样。wake形如EM算法的M-Step,sleep形如E-Step,但sleep时的目标函数是 K L ( p ∥ q ) KL(p \Vert q) KL(p∥q),和wake的 K L ( q ∥ p ) KL(q \Vert p) KL(q∥p)不同,所以没法保证算法收敛。这也是为什么只能作为一个启发式算法的原因。