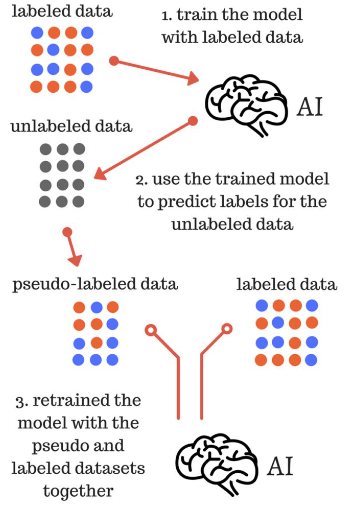
使用伪标签进行半监督学习,在机器学习竞赛当中是一个比较容易快速上分的关键点。下面给大家来介绍一下什么是基于伪标签的半监督学习。在传统的监督学习当中,我们的训练集具有标签,同时,测试集也具有标签。这样我们通过训练集训练到的模型就可以在测试集上验证模型的准确率。
然而使用伪标签的话,我们则可以使用训练集训练出一个最好的模型,然后再去除测试集的真实的标签,然后用这个已经train好的模型去predict测试集的标签。然后将这个predict后的标签假装认为是真实的标签,也就是"伪标签’。将其放到原来的训练集当中,同时再次开始训练出一个最新的model。
最后再用这个最新的model,在我们的测试集上用真实的标签来验证模型的正确性。整体流程如下图所示:
在半监督学习当中,用无标签数据的优点如下:
1、有标签数据往往意味着高成本和难以获得,但无标签数据量大又便宜。
2、通过提高决策边界的精确性,它们能提高模型的稳健性。
3、在机器学习竞赛当当中常常用来上分。
具体的步骤整理如下,和大家一起看一下:
1、将有标签部分数据分为两份:train_set&validation_set,并训练出最优的model1。
2、用model1对未知标签数据(test_set)进行预测,给出伪标签结果pseudo-labeled。
3、将train_set中抽取一部分做新的validation_set,把剩余部分与pseudo-labeled部分融合作为新的train_set,训练出最优的model2。
4、再用model2对未知标签数据(test_set)进行预测,得到最终的final result label。