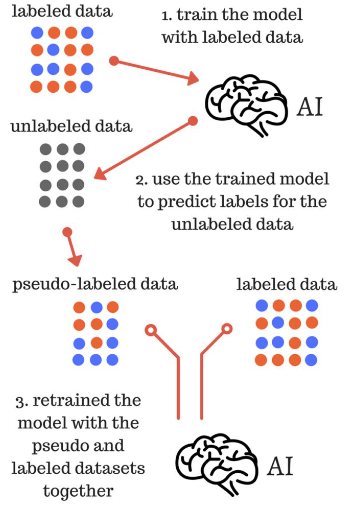
目录
2.搜索结果处理
2.1.排序
2.1.1.普通字段排序
2.1.2.地理坐标排序
2.2.分页
2.2.1.基本的分页
2.2.2.深度分页问题
2.2.3.小结
2.3.高亮
2.3.1.高亮原理
2.3.2.实现高亮
2.4.总结
3.RestClient查询文档
3.1.快速入门
3.1.1.发起查询请求
3.1.2.解析响应
3.1.3.完整代码
3.1.4.小结
3.2.match查询
3.3.精确查询
3.4.布尔查询
3.5.排序、分页
3.6.高亮
3.6.1.高亮请求构建
3.6.2.高亮结果解析
2.搜索结果处理
搜索的结果可以按照用户指定的方式去处理或展示。
2.1.排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
2.1.1.普通字段排序
keyword、数值、日期类型排序的语法基本一致。
语法:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
示例:
需求描述:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序

2.1.2.地理坐标排序
地理坐标排序略有不同。
语法说明:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
这个查询的含义是:
-
指定一个坐标,作为目标点
-
计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
-
根据距离排序
示例:
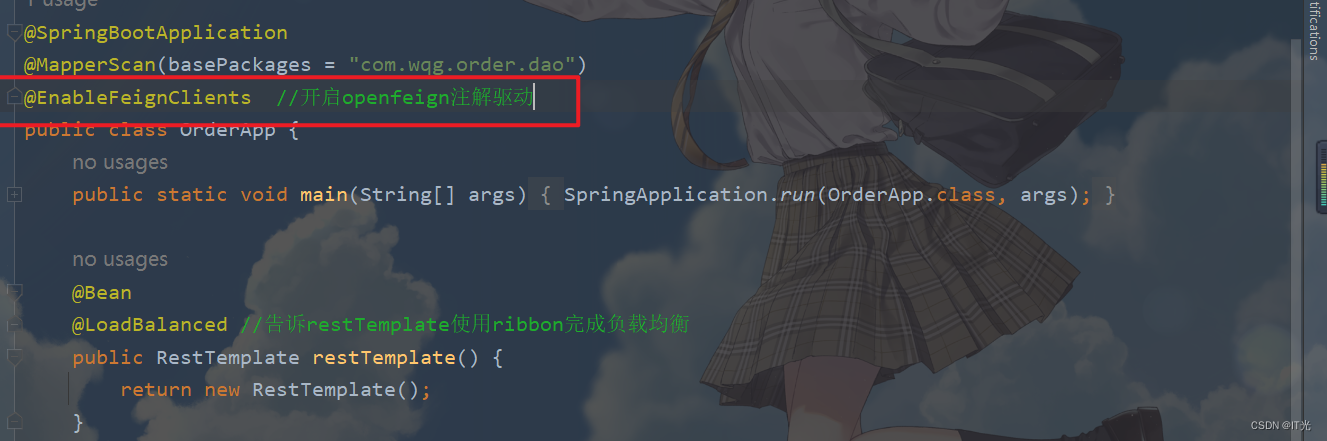
需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
提示:获取你的位置的经纬度的方式:获取鼠标点击经纬度-地图属性-示例中心-JS API 2.0 示例 | 高德地图API
假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
2.2.分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
-
from:从第几个文档开始
-
size:总共查询几个文档
类似于mysql中的limit ?, ?
2.2.1.基本的分页
分页的基本语法如下:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
2.2.2.深度分页问题
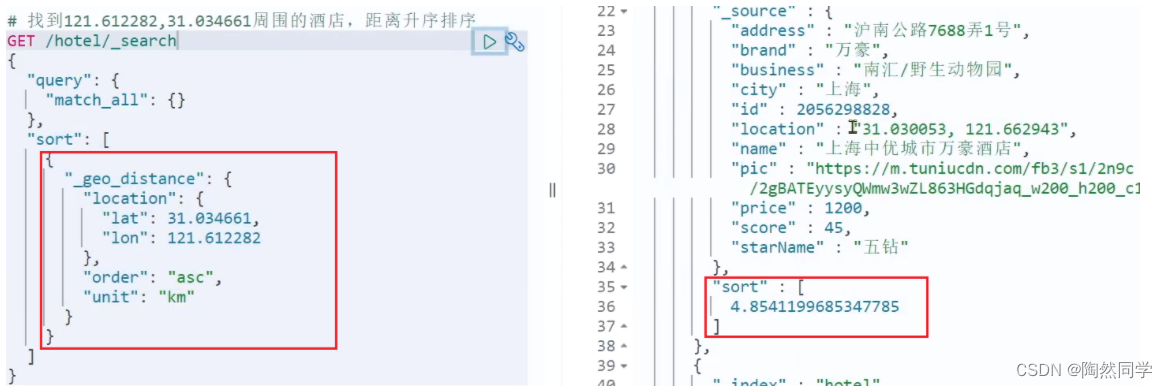
现在,我要查询990~1000的数据,查询逻辑要这么写:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
这里是查询990开始的数据,也就是 第990~第1000条 数据。
不过,elasticsearch内部分页时,必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:
查询TOP1000,如果es是单点模式,这并无太大影响。
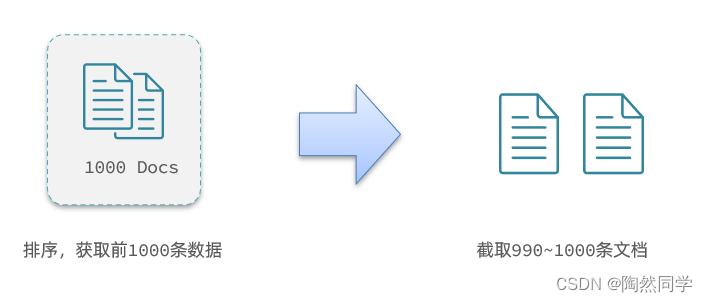
但是elasticsearch将来一定是集群,例如我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了。
因为节点A的TOP200,在另一个节点可能排到10000名以外了。
因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。
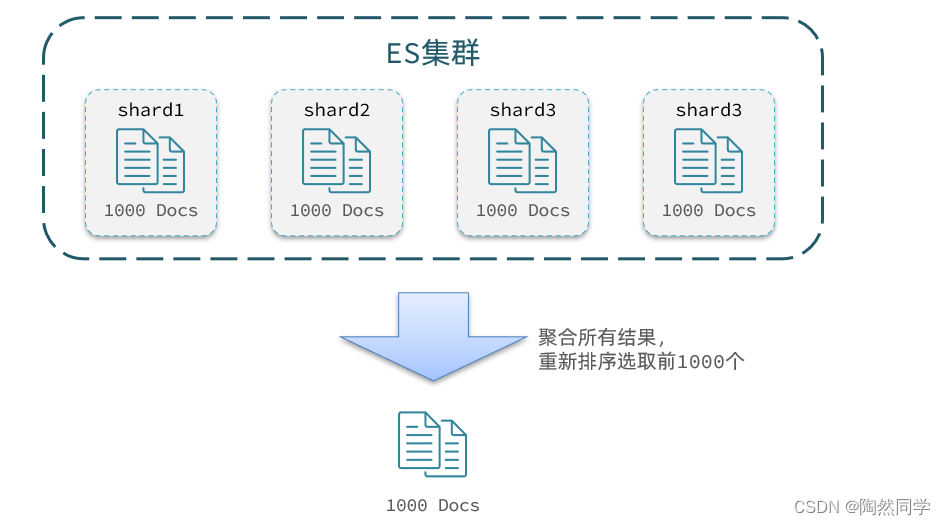
那如果我要查询9900~10000的数据呢?是不是要先查询TOP10000呢?那每个节点都要查询10000条?汇总到内存中?
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,ES提供了两种解决方案,官方文档:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
-
scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
2.2.3.小结
分页查询的常见实现方案以及优缺点:
-
from + size:-
优点:支持随机翻页
-
缺点:深度分页问题,默认查询上限(from + size)是10000
-
场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
-
after search:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:只能向后逐页查询,不支持随机翻页
-
场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
-
scroll:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:会有额外内存消耗,并且搜索结果是非实时的
-
场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
-
2.3.高亮
2.3.1.高亮原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
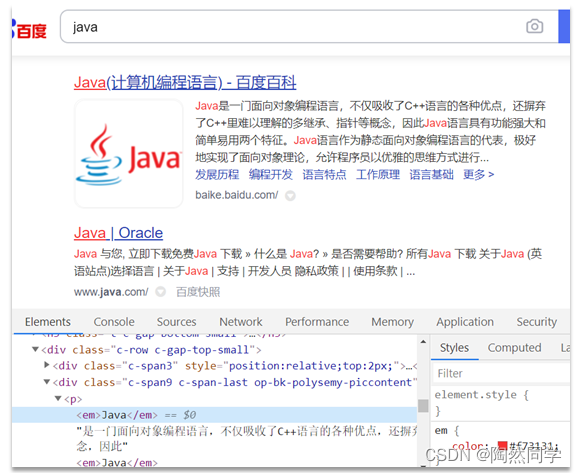
高亮显示的实现分为两步:
-
1)给文档中的所有关键字都添加一个标签,例如
<em>标签 -
2)页面给
<em>标签编写CSS样式
2.3.2.实现高亮
高亮的语法:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
注意:
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
示例:

2.4.总结
查询的DSL是一个大的JSON对象,包含下列属性:
-
query:查询条件
-
from和size:分页条件
-
sort:排序条件
-
highlight:高亮条件
示例:

3.RestClient查询文档
文档的查询同样适用昨天学习的 RestHighLevelClient对象,基本步骤包括:
-
1)准备Request对象
-
2)准备请求参数
-
3)发起请求
-
4)解析响应
3.1.快速入门
我们以match_all查询为例
3.1.1.发起查询请求
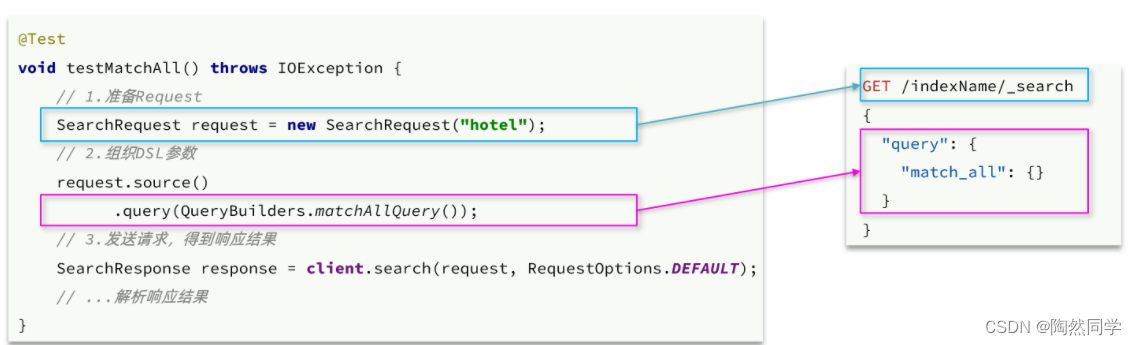
代码解读:
-
第一步,创建
SearchRequest对象,指定索引库名 -
第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等-
query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
-
-
第三步,利用client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),其中包含了查询、排序、分页、高亮等所有功能:

另一个是QueryBuilders,其中包含match、term、function_score、bool等各种查询:

3.1.2.解析响应
响应结果的解析:
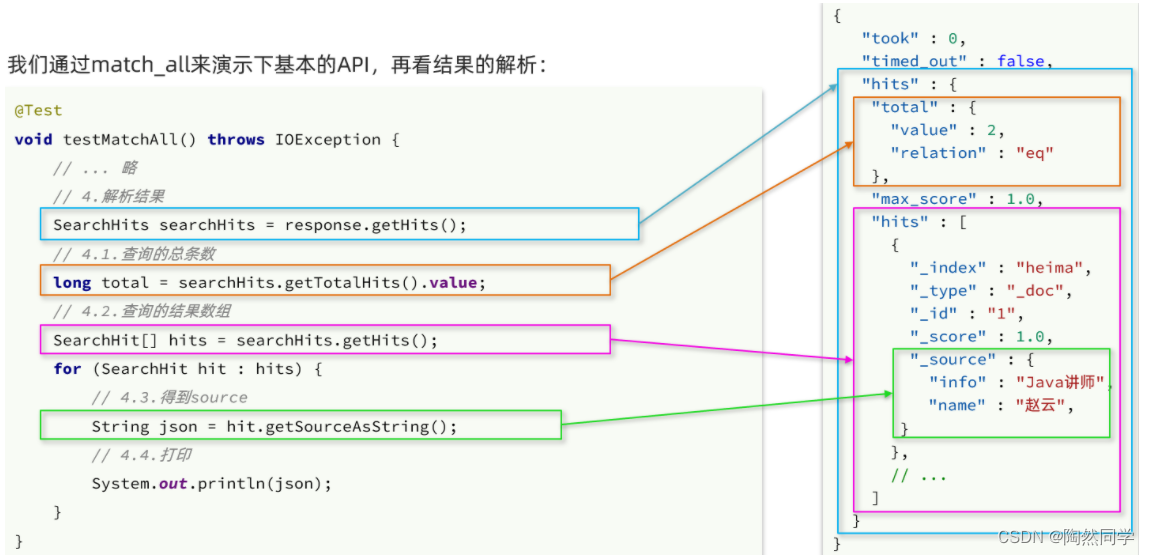
elasticsearch返回的结果是一个JSON字符串,结构包含:
-
hits:命中的结果-
total:总条数,其中的value是具体的总条数值 -
max_score:所有结果中得分最高的文档的相关性算分 -
hits:搜索结果的文档数组,其中的每个文档都是一个json对象-
_source:文档中的原始数据,也是json对象
-
-
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
-
SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果-
SearchHits#getTotalHits().value:获取总条数信息 -
SearchHits#getHits():获取SearchHit数组,也就是文档数组-
SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
-
-
3.1.3.完整代码
完整代码如下:
@Test
void testMatchAll() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
3.1.4.小结
查询的基本步骤是:
-
创建SearchRequest对象
-
准备Request.source(),也就是DSL。
① QueryBuilders来构建查询条件
② 传入Request.source() 的 query() 方法
-
发送请求,得到结果
-
解析结果(参考JSON结果,从外到内,逐层解析)
3.2.match查询
全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query的部分。
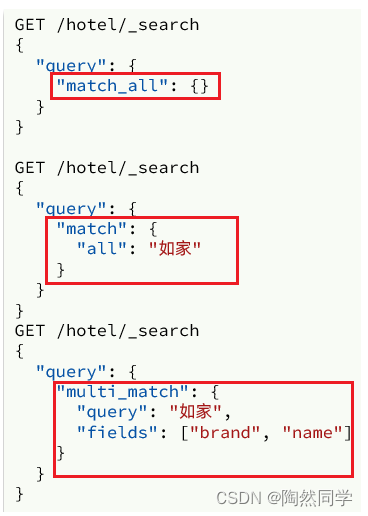
因此,Java代码上的差异主要是request.source().query()中的参数了。同样是利用QueryBuilders提供的方法:

而结果解析代码则完全一致,可以抽取并共享。
完整代码如下:
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.3.精确查询
精确查询主要是两者:
-
term:词条精确匹配
-
range:范围查询
与之前的查询相比,差异同样在查询条件,其它都一样。
查询条件构造的API如下:

3.4.布尔查询
布尔查询是用must、must_not、filter等方式组合其它查询,代码示例如下:
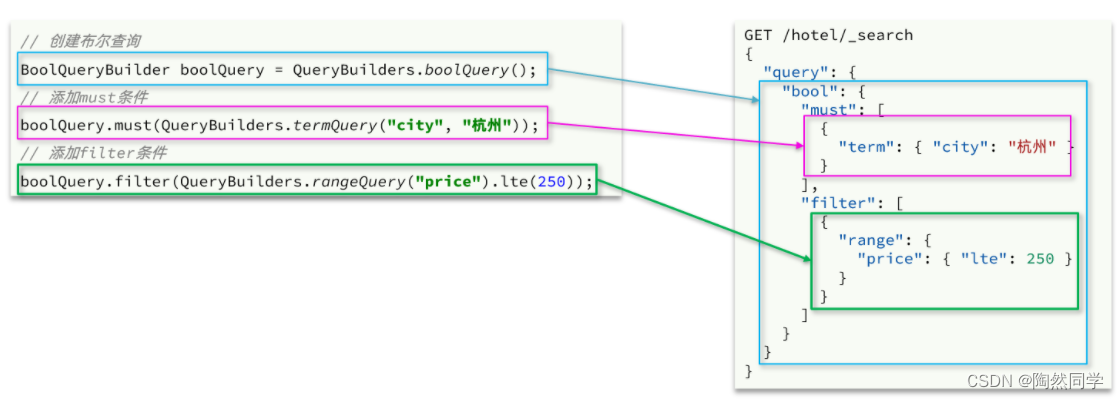
可以看到,API与其它查询的差别同样是在查询条件的构建,QueryBuilders,结果解析等其他代码完全不变。
完整代码如下:
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city", "杭州"));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.5.排序、分页
搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。
对应的API如下:
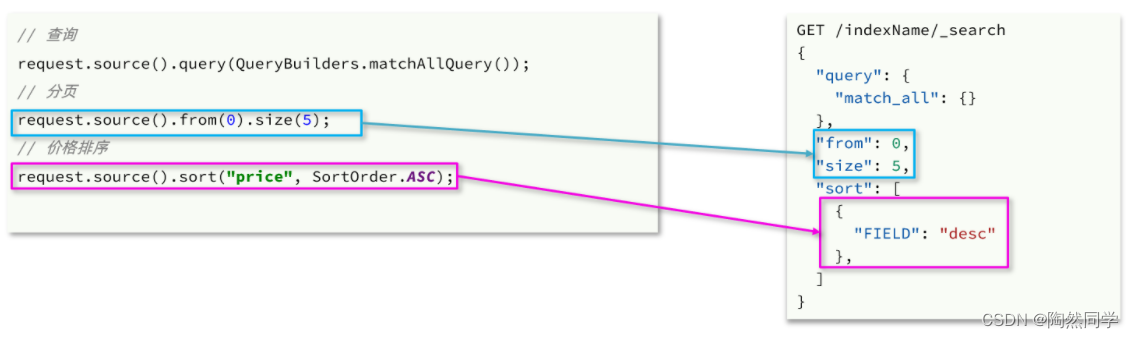
完整代码示例:
@Test
void testPageAndSort() throws IOException {
// 页码,每页大小
int page = 1, size = 5;
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort("price", SortOrder.ASC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.6.高亮
高亮的代码与之前代码差异较大,有两点:
-
查询的DSL:其中除了查询条件,还需要添加高亮条件,同样是与query同级。
-
结果解析:结果除了要解析_source文档数据,还要解析高亮结果
3.6.1.高亮请求构建
高亮请求的构建API如下:

上述代码省略了查询条件部分,但是大家不要忘了:高亮查询必须使用全文检索查询,并且要有搜索关键字,将来才可以对关键字高亮。
完整代码如下:
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.6.2.高亮结果解析
高亮的结果与查询的文档结果默认是分离的,并不在一起。
因此解析高亮的代码需要额外处理:
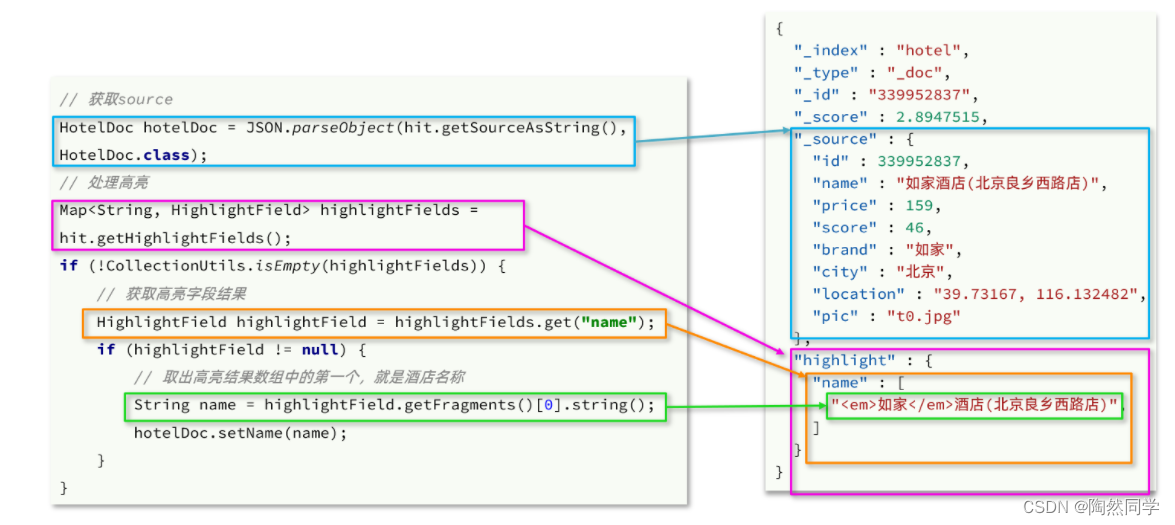
代码解读:
-
第一步:从结果中获取source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为HotelDoc对象
-
第二步:获取高亮结果。hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值
-
第三步:从map中根据高亮字段名称,获取高亮字段值对象HighlightField
-
第四步:从HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了
-
第五步:用高亮的结果替换HotelDoc中的非高亮结果
完整代码如下:
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}