相关博客
【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装mappings
【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
【深度学习】混合精度训练与显存分析
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
Megatron-DeepSpeed是DeepSpeed版本的NVIDIA Megatron-LM。像BLOOM、GLM-130B等主流大模型都是基于Megatron-DeepSpeed开发的。这里以BLOOM版本的Megetron-DeepSpeed为例,介绍其张量并行代码mpu的细节(位于megatron/mpu下)。
相关原理知识建议阅读:
- 【深度学习】【分布式训练】Collective通信操作及Pytorch示例
- 【深度学习】【分布式训练】一文捋顺千亿模型训练技术:流水线并行、张量并行和3D并行
- 【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
强烈建议阅读,不然会影响本文的理解:
- 【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
阅读建议:
- 本文仅会解析核心代码,并会不介绍所有代码;
- 本文会提供一些测试脚本来展现各部分代码的功能;
- 建议实际动手实操来加深理解;
- 建议对Collective通信以及分布式模型训练有一定理解,再阅读本文;
一、总览
mpu目录下核心文件有:
- initialize.py:负责数据并行组、张量并行组和流水线并行组的初始化,以及获取与各类并行组相关的信息;
- data.py:实现张量并行中的数据广播功能;
- cross_entropy.py:张量并行版本的交叉熵;
- layers.py:并行版本的Embedding层,以及列并行线性层和行并行线性层;
- mappings.py:用于张量并行的通信操作;
二、代码实现及测试
1. _reduce
源代码
_reduce提供在整个张量并行组进行All-Reduce的功能,函数定义如下 :
def _reduce(input_):
"""
在模型并行组上对输入张量执行All-reduce.
"""
if get_tensor_model_parallel_world_size()==1:
return input_
# All-reduce.
torch.distributed.all_reduce(input_, group=get_tensor_model_parallel_group())
return input_
测试代码
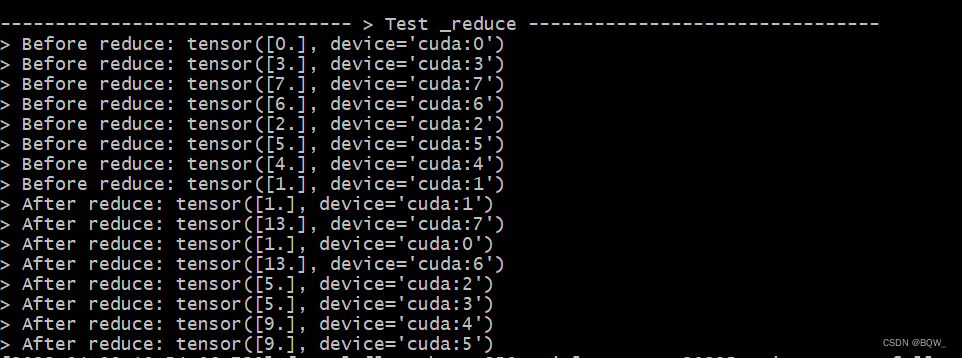
测试遵循文章【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化 中的设置,张量并行度为2,且流水线并行度为2。则张量并行组为:[Rank0, Rank1],[Rank2, Rank3],[Rank4,Rank5],[Rank6,Rank7]。
def test_reduce():
print_separator(f'> Test _reduce')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before reduce: {tensor}")
# 保证reduce前后的输出不混乱
torch.distributed.barrier()
# reduce操作
# 期望结果:[Rank0, Rank1]为一组,经过reduce后均为tensor([1])
# 期望结果:[Rank6, Rank7]为一组,经过reduce后均为tensor([13])
mappings._reduce(tensor)
print(f"> After reduce: {tensor}")
测试结果
2. _gather
源代码
收集张量并行组中的张量,并按照最后一维度拼接.
def _gather(input_):
"""
gather张量并按照最后一维度拼接.
"""
world_size = get_tensor_model_parallel_world_size()
if world_size==1:
return input_
# 最后一维的索引
last_dim = input_.dim() - 1
# 张量并行组中的rank
rank = get_tensor_model_parallel_rank()
# 初始化空张量列表,用于存储收集来的张量
tensor_list = [torch.empty_like(input_) for _ in range(world_size)]
tensor_list[rank] = input_
torch.distributed.all_gather(tensor_list, input_, group=get_tensor_model_parallel_group())
# 拼接
output = torch.cat(tensor_list, dim=last_dim).contiguous()
return output
测试代码
实验设置同上。
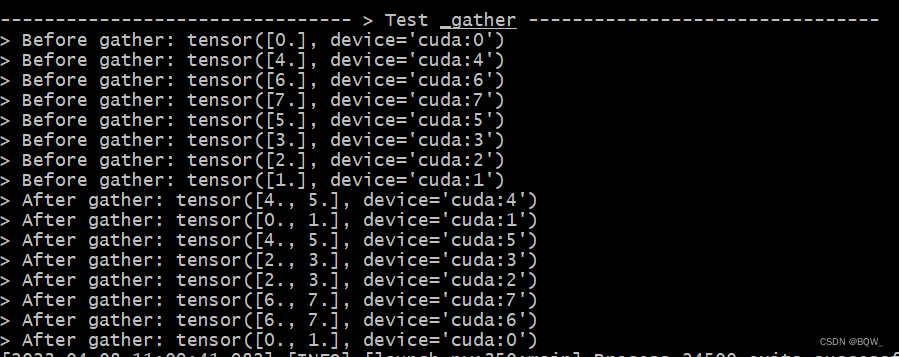
def test_gather():
print_separator(f'> Test _gather')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before gather: {tensor}\n", end="")
torch.distributed.barrier()
# 期望结果:[Rank0, Rank1]为一组,经过gather后均为tensor([0., 1.])
gather_tensor = mappings._gather(tensor)
print(f"> After gather: {gather_tensor}\n", end="")
测试结果
3. _split
源代码
沿最后一维分割张量,并保留对应rank的分片.
def _split(input_):
"""
沿最后一维分割张量,并保留对应rank的分片.
"""
world_size = get_tensor_model_parallel_world_size()
if world_size==1:
return input_
# 按world_size分割输入张量input_
input_list = split_tensor_along_last_dim(input_, world_size)
# Note: torch.split does not create contiguous tensors by default.
rank = get_tensor_model_parallel_rank()
output = input_list[rank].contiguous()
return output
测试代码
测试设置同上。
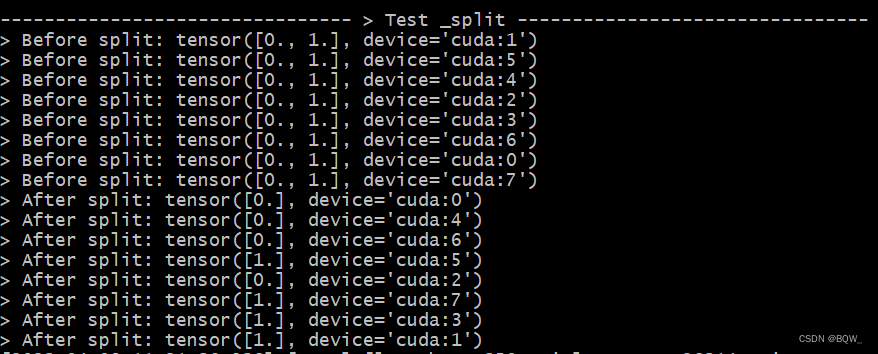
def test_split():
print_separator(f'> Test _split')
global_rank = torch.distributed.get_rank()
# 在实验设置下为tp_world_size=2
tp_world_size = mpu.get_tensor_model_parallel_world_size()
# 在实验设置下tensor=[0,1]
tensor = torch.Tensor(list(range(tp_world_size))).to(torch.device("cuda", global_rank))
print(f"> Before split: {tensor}\n", end="")
torch.distributed.barrier()
# 期望结果:Rank0,Rank2,Rank4,Rank6持有张量tensor([0])
# 期望结果:Rank1,Rank3,Rank5,Rank7持有张量tensor([1])
split_tensor = mappings._split(tensor)
print(f"> After split: {split_tensor}\n", end="")
测试结果
4. copy_to_tensor_model_parallel_region
源代码
- 前向传播时,不进行任何操作
- 反向传播时,对相同张量组中所有对input_的梯度求和
class _CopyToModelParallelRegion(torch.autograd.Function):
@staticmethod
def symbolic(graph, input_):
return input_
@staticmethod
def forward(ctx, input_): # 前向传播时,不进行任何操作
return input_
@staticmethod
def backward(ctx, grad_output): # 反向传播时,对同张量并行组的梯度进行求和
return _reduce(grad_output)
def copy_to_tensor_model_parallel_region(input_):
return _CopyToModelParallelRegion.apply(input_)
测试代码
测试设置同上。本次实验中,会分别使用copy和非copy的张量来求梯度,展示其区别。
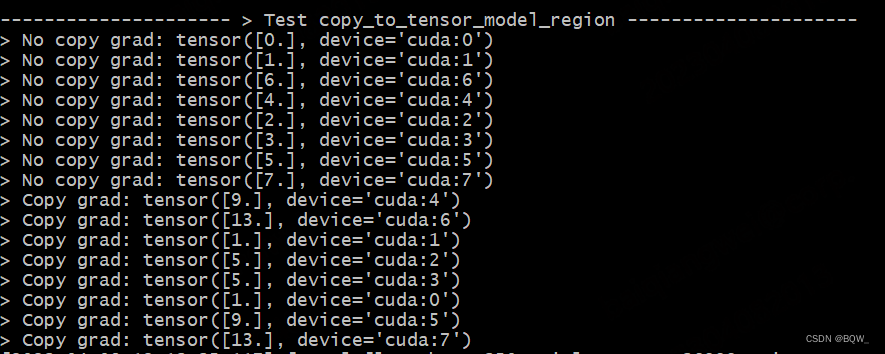
def test_copy_to_tensor_model_parallel_region():
print_separator(f'> Test copy_to_tensor_model_region^S')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
loss = global_rank * tensor
loss.backward()
# 非copy的tensor梯度期望结果为,Ranki的梯度为i
print(f"> No copy grad: {tensor.grad}\n", end="")
torch.distributed.barrier()
tensor.grad = None
# 使用copy_to_tensor_model_parallel_region对tensor进行操作
# 该操作不会影响前向传播,仅影响反向传播
tensor_parallel = mappings.copy_to_tensor_model_parallel_region(tensor)
# 例:对于rank=5,则loss=5*x,其反向传播的梯度为5;依次类推
loss_parallel = global_rank * tensor_parallel
loss_parallel.backward()
torch.distributed.barrier()
# 例:张量组[Rank6, Rank7]的期望梯度均为13
print(f"> Copy grad: {tensor.grad}\n", end="")
测试结果
5. reduce_from_tensor_model_parallel_region
源代码
- 前向传播时,将同张量并行组的输入input_进行allreduce;
- 反向传播时,直接返回input_的梯度;
class _ReduceFromModelParallelRegion(torch.autograd.Function):
@staticmethod
def symbolic(graph, input_):
return _reduce(input_)
@staticmethod
def forward(ctx, input_): # 前向传播时,对张量并行组中的输入进行allreduce
return _reduce(input_)
@staticmethod
def backward(ctx, grad_output):
return grad_output
def reduce_from_tensor_model_parallel_region(input_):
return _ReduceFromModelParallelRegion.apply(input_)
测试代码
测试设置同上。
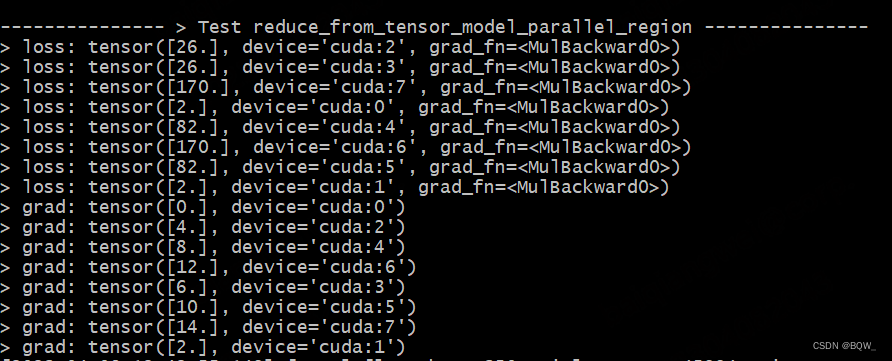
以张量并行组[Rank6, Rank7]为例, l o s s = 2 ∗ ( 6 ∗ x 6 + 7 ∗ x 7 ) loss=2*(6*x_6+7*x_7) loss=2∗(6∗x6+7∗x7)。所以,前向传播的结果为 2 ∗ ( 6 ∗ 6 + 7 ∗ 7 ) = 170 2*(6*6+7*7)=170 2∗(6∗6+7∗7)=170。Rank6的反向传播梯度为12,Rank7的反向传播梯度为14。
def test_reduce_from_tensor_model_parallel_region():
print_separator(f"> Test reduce_from_tensor_model_parallel_region")
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor1 = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
tensor2 = global_rank * tensor1
tensor_parallel = mappings.reduce_from_tensor_model_parallel_region(tensor2)
loss = 2 * tensor_parallel
loss.backward()
print(f"> value: {tensor1.data}\n", end="")
print(f"> grad: {tensor1.grad}\n", end="")
测试结果
6. scatter_to_tensor_model_parallel_region
源代码
- 前向传播时,将输入input_分片至同张量并行组的不同进程中;
- 反向传播时,将同张量并行组的梯度收集起来并拼接;
class _ScatterToModelParallelRegion(torch.autograd.Function):
"""
分割输入,仅保留对应rank的块。
"""
@staticmethod
def symbolic(graph, input_):
return _split(input_)
@staticmethod
def forward(ctx, input_): # 切分输入
return _split(input_)
@staticmethod
def backward(ctx, grad_output): # 收集梯度
return _gather(grad_output)
def scatter_to_tensor_model_parallel_region(input_):
return _ScatterToModelParallelRegion.apply(input_)
测试代码
测试设置同上。
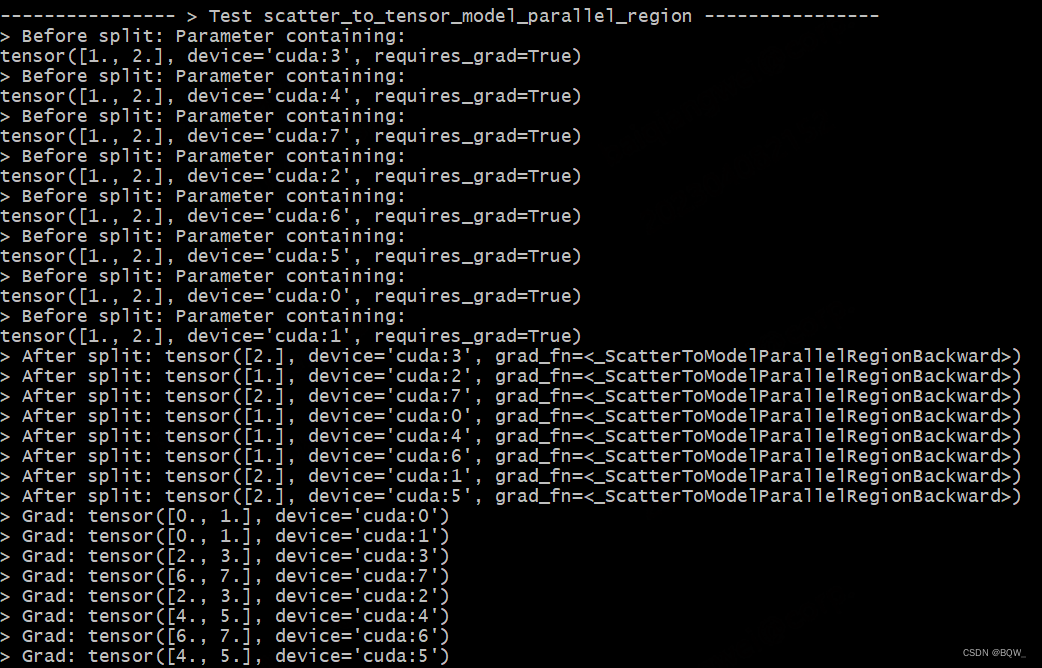
以张量并行组[Rank6, Rank7]为例,Rank6的梯度为6,Rank7的梯度为7。scatter_to_tensor_model_parallel_region的backward过程会收集两者的梯度,因此Rank6和Rank7的梯度均为tensor([6.,7.])。
def test_scatter_to_tensor_model_parallel_region():
print_separator(f'> Test scatter_to_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
tp_world_size = mpu.get_tensor_model_parallel_world_size()
# tensor = [1,2]
tensor = Parameter(torch.Tensor(list(range(1, tp_world_size+1))).to(torch.device("cuda", global_rank)))
# split之后, Rank0、Rank2、Rank4、Rank6为tensor([1]), 其余Rank为tensor([2])
tensor_split = mappings.scatter_to_tensor_model_parallel_region(tensor)
loss = global_rank * tensor_split
loss.backward()
print(f"> Before split: {tensor}\n", end="")
torch.distributed.barrier()
print(f"> After split: {tensor_split}\n", end="")
torch.distributed.barrier()
print(f"> Grad: {tensor.grad}\n", end="")
测试结果
7. gather_from_tensor_model_parallel_region
源代码
- 前向传播时,将同张量并行组的input_收集在一起并进行拼接;
- 反向传播时,将梯度分片至同张量并行组的不同进程中;
class _GatherFromModelParallelRegion(torch.autograd.Function):
"""
收集张量并行组的张量并拼接
"""
@staticmethod
def symbolic(graph, input_):
return _gather(input_)
@staticmethod
def forward(ctx, input_): # 前向传播时,相同张量并行组gather在一起
return _gather(input_)
@staticmethod
def backward(ctx, grad_output): # 反向传播时,将张量split至张量组中的机器
return _split(grad_output)
测试代码
测试设置同上。
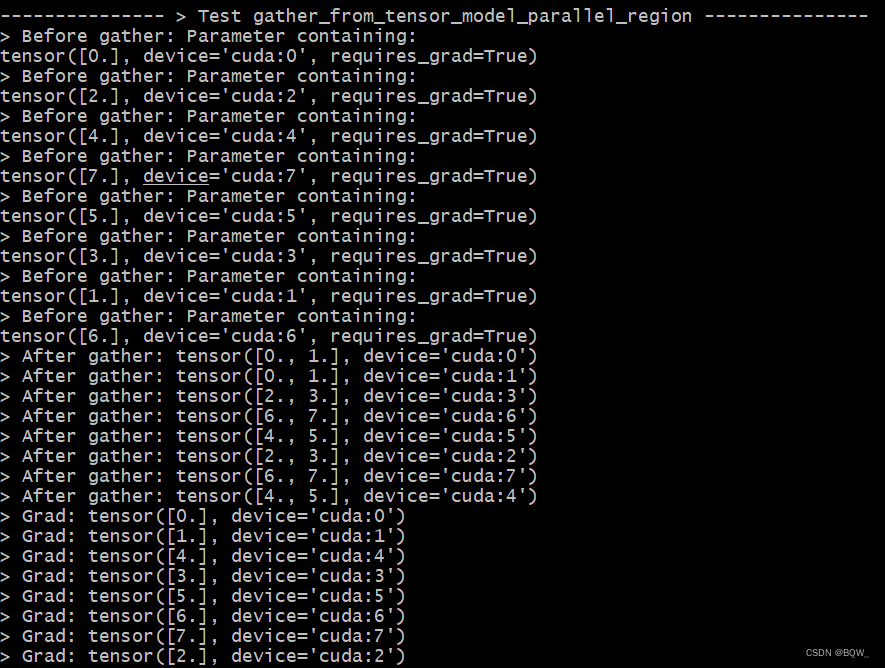
def test_gather_from_tensor_model_parallel_region():
print_separator(f'> Test gather_from_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
# tp_world_size = mpu.get_tensor_model_parallel_world_size()
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
print(f"> Before gather: {tensor}\n", end="")
torch.distributed.barrier()
gather_tensor = mappings.gather_from_tensor_model_parallel_region(tensor)
print(f"> After gather: {gather_tensor.data}\n", end="")
loss = (global_rank * gather_tensor).sum()
loss.backward()
print(f"> Grad: {tensor.grad}\n", end="")
测试结果
三、完整测试脚本
测试采用8张显卡。下面是完整的测试脚本:
# test_mappings.py
import sys
sys.path.append("..")
from torch.nn.parameter import Parameter
from commons import print_separator
from commons import initialize_distributed
import megatron.mpu.mappings as mappings
import megatron.mpu as mpu
import torch
def test_reduce():
print_separator(f'> Test _reduce')
global_rank = torch.distributed.get_rank()
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before reduce: {tensor}\n", end="")
torch.distributed.barrier()
mappings._reduce(tensor)
print(f"> After reduce: {tensor}\n", end="")
def test_gather():
print_separator(f'> Test _gather')
global_rank = torch.distributed.get_rank()
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before gather: {tensor}\n", end="")
torch.distributed.barrier()
gather_tensor = mappings._gather(tensor)
print(f"> After gather: {gather_tensor}\n", end="")
def test_split():
print_separator(f'> Test _split')
global_rank = torch.distributed.get_rank()
tp_world_size = mpu.get_tensor_model_parallel_world_size()
tensor = torch.Tensor(list(range(tp_world_size))).to(torch.device("cuda", global_rank))
print(f"> Before split: {tensor}\n", end="")
torch.distributed.barrier()
split_tensor = mappings._split(tensor)
print(f"> After split: {split_tensor}\n", end="")
def test_copy_to_tensor_model_parallel_region():
print_separator(f'> Test copy_to_tensor_model_region')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
loss = global_rank * tensor
loss.backward()
print(f"> No copy grad: {tensor.grad}\n", end="")
torch.distributed.barrier()
tensor.grad = None
# 使用copy_to_tensor_model_parallel_region对tensor进行操作
# 该操作不会影响前向传播,仅影响反向传播
tensor_parallel = mappings.copy_to_tensor_model_parallel_region(tensor)
# 例:对于rank=5,则loss=5*x,其反向传播的梯度为5;依次类推
loss_parallel = global_rank * tensor_parallel
loss_parallel.backward()
torch.distributed.barrier()
print(f"> Copy grad: {tensor.grad}\n", end="")
def test_reduce_from_tensor_model_parallel_region():
print_separator(f"> Test reduce_from_tensor_model_parallel_region")
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor1 = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
tensor2 = global_rank * tensor1
tensor_parallel = mappings.reduce_from_tensor_model_parallel_region(tensor2)
loss = 2 * tensor_parallel
loss.backward()
print(f"> loss: {loss}\n", end="")
print(f"> grad: {tensor1.grad}\n", end="")
def test_scatter_to_tensor_model_parallel_region():
print_separator(f'> Test scatter_to_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
tp_world_size = mpu.get_tensor_model_parallel_world_size()
# tensor = [1,2]
tensor = Parameter(torch.Tensor(list(range(1, tp_world_size+1))).to(torch.device("cuda", global_rank)))
# split之后, Rank0、Rank2、Rank4、Rank6为tensor([1]), 其余Rank为tensor([2])
tensor_split = mappings.scatter_to_tensor_model_parallel_region(tensor)
loss = global_rank * tensor_split
loss.backward()
print(f"> Before split: {tensor}\n", end="")
torch.distributed.barrier()
print(f"> After split: {tensor_split}\n", end="")
torch.distributed.barrier()
print(f"> Grad: {tensor.grad}\n", end="")
def test_gather_from_tensor_model_parallel_region():
print_separator(f'> Test gather_from_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
print(f"> Before gather: {tensor}\n", end="")
torch.distributed.barrier()
# 例: [Rank6, Rank7]的gather_tensor均为tensor([6.,7.])
gather_tensor = mappings.gather_from_tensor_model_parallel_region(tensor)
print(f"> After gather: {gather_tensor.data}\n", end="")
loss = (global_rank * gather_tensor).sum()
loss.backward()
print(f"> Grad: {tensor.grad}\n", end="")
if __name__ == '__main__':
initialize_distributed()
world_size = torch.distributed.get_world_size()
tensor_model_parallel_size = 2
pipeline_model_parallel_size = 2
# 并行环境初始化
mpu.initialize_model_parallel(
tensor_model_parallel_size,
pipeline_model_parallel_size)
test_reduce()
test_gather()
test_split()
test_copy_to_tensor_model_parallel_region()
test_reduce_from_tensor_model_parallel_region()
test_scatter_to_tensor_model_parallel_region()
test_gather_from_tensor_model_parallel_region()
启动脚本为
deepspeed test_mappings.py






![数据结构05:树与二叉树[C++][线索二叉树:先序、后序]](https://img-blog.csdnimg.cn/a4945c438b254692aadc64999ac4f6a6.png)