文章目录
- 一、相关实际问题
- 二、深入理解listen
- 1)listen系统调用
- 2)协议栈listen
- 3)接收队列定义
- 4)接收队列申请和初始化
- 5)半连接队列长度计算
- 6)小结
- 三、深入理解connect
- 1)connect调用链展开
- 2)选择可用端口
- 3)端口被使用过怎么办
- 4)发起SYN请求
- 5)小结
- 四、完整TCP连接建立过程
- 1)服务端响应SYN
- 2)客户端响应SYNACK
- 3)服务端响应ACK
- 4)服务端accept
- 5)小结
- 五、异常TCP建立情况
- 1)connect系统调用耗时失控
- 2)第一次握手丢包
- 1. 半连接队列满
- 2. 全连接队列满
- 3. 客户端发起重试
- 4. 实际抓包结果
- 3)第三次握手丢包
- 4)握手异常总结
- 六、如何查看是否有连接队列溢出发生
- 1)全连接队列溢出判断
- 2)半连接队列溢出判断
- 七、问题解答
系列文章:
- 深入理解Linux网络——内核是如何接收到网络包的
- 深入理解Linux网络——内核与用户进程协作之同步阻塞方案(BIO)
- 深入理解Linux网络——内核与用户进程协作之多路复用方案(epoll)
- 深入理解Linux网络——内核是如何发送网络包的
- 深入理解Linux网络——本机网络IO
- 深入理解Linux网络——TCP连接建立过程(三次握手源码详解)
一、相关实际问题
- 为什么服务端程序都需要先listen一下
- 半连接队列和全连接队列长度如何确定
- “Cannot assign requested address”这个报错是怎么回事
- 一个客户端端口可以同时用在两条连接上吗
- 服务端半/全连接队列满了会怎么样
- 新连接的soket内核对象是什么时候建立的
- 建立一条TCP连接需要消耗多长时间
- 服务器负载很正常,但是CPU被打到底了时怎么回事
二、深入理解listen
1)listen系统调用
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
// 根据fd查找socket内核对象
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if(sock) {
// 获取内核参数net.core.somaxconn
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if((unsigned int)backlog > somaxconn)
backlog = somaxconn;
// 调用协议栈注册的listen函数
err = sock->ops->listen(sock, backlog);
}
用户态的socket文件描述符只是一个整数而已,内核是没有办法直接使用的,所以首先就是先根据用户传入的文件描述符来查找对应的socket内核对象。
再接着获取了系统里的net.core.somaxconn内核参数的值,和用户传入的backlog作比较后取一个最小值传入下一步。
所以虽然listen允许我们传入backlog(该值和半连接队列、全连接队列都有关系),但是会受到内核参数的限制。
接着通过调用sock->ops->listen进入协议栈的listen函数。
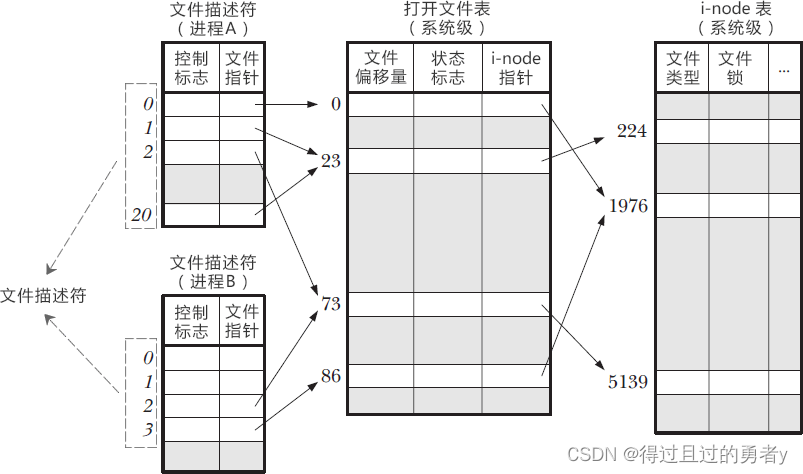
- 文件描述表:进程级别。一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表,记录着当前进程所有可用的文件描述符,也即当前进程所有打开的文件。
- 打开文件表:系统级别。内核对所有打开文件维护的一个描述表格,将表格中的每一项称为打开文件句柄。它存储了一个打开文件的所有相关信息,例如当前文件的偏移量,访问模式,状态等等。
- inode:系统级别。文件系统中的每个文件都有自己的i-node信息,它包含文件类型,访问权限,文件属性等等。
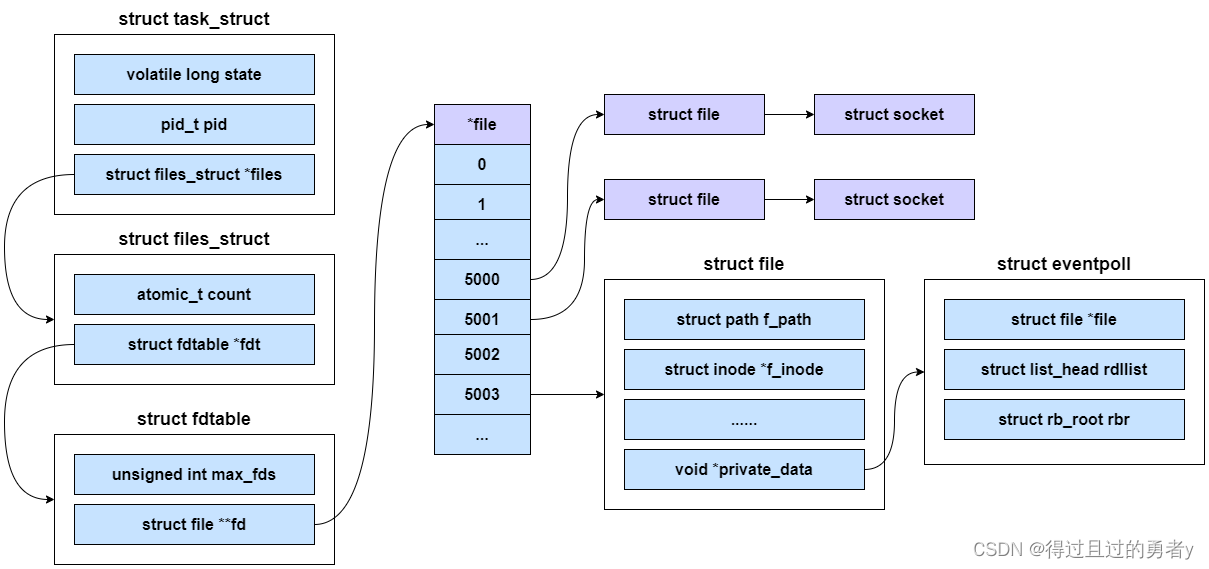
fdtable对应用户已打开文件表,或者说文件描述符表,是进程私有的。它的成员fd是file指针数组的指针,其中数组的索引就是文件描述符,而数组元素就是file指针,或者说已打开文件句柄。一个struct file的实例代表一个打开的文件,当一个用户进程成功打开文件时,会创建次结构体,并包含调用者应用程序的文件访问属性,例如文件数据的偏移量、访问模式和特殊标志等。此对象映射到调用者的文件描述符表,作为调用者应用程序对文件的句柄。
以c语言为例,文件指针/句柄:fopen->FILE *,文件描述符:open->int
通常数组的第一个元素(索引为0)是进程的标准输入文件,数组的第二个元素(索引为1)是进程的标准输出文件,数组的第三个元素(索引为2)是进程的标准错误文件。查看进程允许打开的最大文件句柄数:ulimit -n;设置进程能打开的最大文件句柄数:ulimit -n xxx。
以上说法是在linux中的概念,而在windows中句柄的概念对应的是linux中文件描述符的概念,都是一个非负的整数。
2)协议栈listen
上文提到系统调用最后会通过sock->ops->listen进入协议栈的listen函数,对于AF_INET而言,指向的是inet_listen
int inet_listen(struct socket *sock, int backlog)
{
// 还不是listen状态(尚未listen过)
if(old_state != TCP_LISTEN) {
// 开始监听
err = inet_csk_listen_start(sk, backlog);
// 设置全连接队列长度
sk->sk_max_ack_backlog = backlog;
}
可以看到,全连接队列的长度就是执行listen调用时传入的backlog和系统参数之间较小的那个值。所以如果再线上遇到了全连接队列溢出的问题,想加大该队列的长度,那么可能需要将它们都设置得更大。
回过头来看inet_csk_listen_start函数
int inet_csk_listen_start(struct sock *sk, const int nr_table_entries)
{
struct inet_connection_sock *icsk = inet_csk(sk);
// icsk->icsk_accept_queue时接收队列
// 接收队列内核对象的申请和初始化
int rc = reqsk_queue_alloc(&icsk->icsk_accept_queue, nr_table_entries);
......
}
函数再一开始就将struct sock对象强制转换成了inet_connection_sock,名叫icsk。之所以可以强制转换是因为inet_connection_sock是包含sock的。tcp_sock、inet_connection_sock、inet_sock、sock是逐层嵌套的关系,类似面向对象里继承的概念。而对于TCP的socket来说,sock对象实际上是一个tcp_sock。因此TCP的sock对象可以强制类型转换为tcp_sock、inet_connection_sock、inet_sock来使用。即子类转换为父类。
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
u16 tcp_header_len; /* Bytes of tcp header to send */
u16 xmit_size_goal_segs; /* Goal for segmenting output packets */
...
};
struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet;
struct request_sock_queue icsk_accept_queue;
struct inet_bind_bucket *icsk_bind_hash;
...
};
struct inet_sock {
/* sk and pinet6 has to be the first two members of inet_sock */
struct sock sk;
#if IS_ENABLED(CONFIG_IPV6)
struct ipv6_pinfo *pinet6;
#endif
...
};
struct socket {
socket_state state;
...
struct sock *sk;
const struct proto_ops *ops;
};
也可以由sock强制转换为tcp_sock,因为在套接字创建的时候,就是以struct tcp_sock作为大小进行分配的。也就是内核中的每个sock都是tcp_sock类型,而struct tcp_sock正好是最大的那个结构体,不会出现越界访问的情况。
在接下来的一行reqsk_queue_alloc中实际上包含了两件重要的事情。一是接收队列数据结构的定义,二是接收队列的申请和初始化。
3)接收队列定义
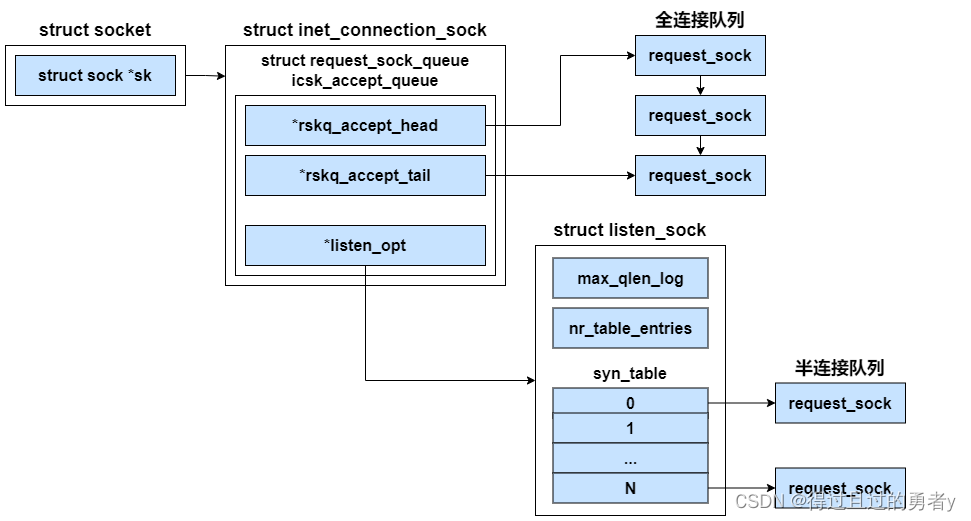
icsk->icsk_accept_queue定义在inet_connection_sock下,是一个request_sock_queue类型的对象,是内核用来接收客户端请求的主要数据结构。我们平时说的全连接队列、半连接队列全都是在这个数据结构里实现的。
我们来看具体的代码。
struct inet_connection_sock {
struct inet_sock icsk_inet;
struct request_sock_queue icsk_accept_queue;
......
}
struct request_sock_queue {
// 全连接队列
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
// 半连接队列
struct listen_sock *listen_opt;
......
}
struct listen_sock {
u8 max_qlen_log;
u32 nr_table_entires;
......
struct request_sock *syn_table[0];
}
对于全连接队列来说,在它上面不需要进行复杂的查找工作,accept处理的时候只是先进先出地接受就好了。所以全连接队列通过rskq_accept_head和rskq_accept_tail以链表的形式来管理。
和半连接队列相关联的数据对象是listen_opt,它是listen_sock类型的。因为服务端需要在第三次握手时快速地查找出来第一次握手时留存的request_sock对象,所以其实是用了一个哈希表来管理,就是struct request_sock *syn_table[0]。max_qlen_log和nr_table_entries都和半连接队列的长度有关。
4)接收队列申请和初始化
了解了全/半连接队列数据结构后,再回到inet_csk_listen_start函数中。它调用了reqsk_queue_alloc来申请和初始化icsk_accept_queue这个接收队列。
在reqsk_queue_alloc这个函数中完成了接收队列request_sock_queue内核对象的创建和初始化。其中包括内存申请、半连接队列长度的计算、全连接队列头的初始化等等。
int reqsk_queue_alloc(struct request_sock_queue *queue, unsigend int nr_table_entries)
{
size_t lopt_size - sizeof(struct listen_sock);
struct listen_sock *lopt;
// 计算半连接队列的长度
nt_table_entries = min_t(u32, nr_table_entries, sysctl_max_syn_backlog);
nr_table_entries = ......
// 为listen神奇对象申请内存,这里包括了半连接队列
lopt_size += nr_table_entries * sizeof(sturct request_sock *);
if(lopt_size > PAGE_SIZE)
lopt = vzalloc(lopt_size);
else
lopt = kzalloc(lopt_size, GFP_KERNEL);
// 全连接队列头初始化
queue->rskq_accept_head = NULL;
// 半连接队列设置
lopt->nr_table_entries = nr_table_entries;
queue->listen_opt = lopt;
}
开头定义了一个struct listen_sock的指针,这个listen_sock就是我们平时经常说的半连接队列。接下来计算半连接队列的长度,计算出来实际大小后进行内存的申请。最后将全连接队列呕吐设置成了NULL,将半连接队列挂到了接收队列queue上。
半连接队列上每个元素分配的是一个指针大小,实际指向的request_sock的内存还未分配。这其实是一个哈希表,真正的半连接用的request_sock对象是在握手的过程中分配的,计算完哈希值后挂到这个哈希表上。
5)半连接队列长度计算
reqsk_queue_alloc函数中计算了半连接队列的长度,因为有些复杂所以没有在前面展开,这里深入一下。
int reqsk_queue_alloc(struct request_sock_queue *queue, unsigend int nr_table_entries)
{
// 计算半连接队列的长度
nr_table_entries = min_t(u32, nr_table_entries, sysctl_max_syn_backlog);
nr_table_entries = max_t(u32, nr_table_entries, 8);
nr_table_entries = roundup_pow_of_two(nr_table_entries + 1);
// 为了效率,不记录nr_table_entries而是记录2的N次幂等于nr_table_entries
for(kopt->max_qlen_log = 3; (1 << lopt->max_qlen_log) < nr_table_entries; lopt->max_qlen_log++);
......
}
传进来的nr_table_entries在最初是用户传入的backlog和内核参数net.core.somaxconn二者之间的较小值。而在这个reqsk_queue_alloc函数里又将完成三次的对比和计算。
- min_t(u32, nr_table_entries, sysctl_max_syn_backlog):和sysctl_max_syn_backlog内核对象比较,取较小值
- max_t(u32, nr_table_entries, 8):用来保证nr_table_entries不能比8小,避免传入太小的值导致无法建立连接
- roundup_pow_of_two(nr_table_entries + 1):用于上对齐到2的整数次幂
总的来说半连接队列的长度是min(backlog, somaxconn, tcp_max_syn_backlog)+1再向上取整到2的N次幂,但最小不能小于16。
最后为了提升比较性能,内核并没有直接记录半连接队列的长度,而是采用了一种晦涩的方法,只记录其N次幂。即如果队列长度为16,则记录max_qlen_log为4,只需要直到它是为了提升性能的即可。
6)小结
listen的主要工作其实就是申请和初始化接收队列,包括全连接队列和半连接队列。其中全连接队列是一个链表,而半连接队列由于需要快速地查找,所以使用的是一个哈希表。这两个队列是三次握手中很重要的两个数据结构,有了它们服务端才能正常相应来自客户端的三次握手。所以服务端都需要先调用listen才行。
同时我们也知道了去内核时如何确定全连接队列和半连接队列的长度。
- 全连接队列:min(backlog, net.core.somaxconn)
- 半连接队列:max(min(backlog, net.core.somaxconn, tcp_max_syn_backlog) + 1向上取整到2的幂次, 16)
三、深入理解connect
客户端再发起连接的时候,创建一个socket,如何瞄准服务端调用connect就可以了,代码可以简单到只有两句。
int main(){
fd = socket(AF_INET, SOCK_STREAM, 0);
connect(fd, ...);
}
但这两行代码背后隐藏的技术细节却很多。
1)connect调用链展开
当客户机调用connect函数的时候,进入系统调用
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, int, addrlen)
{
struct socket *sock;
// 根据用户fd查找内核中的socket对象
sock = sockfd_lookup_light(fd, &err, &fput_needed);
// 进行connect
err = sock->ops->connect(sock, (struct sockaddr *)&address, addlen, sock->file->f_flags);
......
}
同理还是首先根据用户传入的文件描述符来查询对应的socket内核对象,如何再调用sock->ops->connect,对于AF_INET类型的socket而言,指向的是inet_stream_connect。而inet_stream_connect实际会去调用__inet_stream_connect
int __inet_stream_connect(struct socket *sock, ...)
{
struct sock *sk = sock->sk;
witch(sock->state) {
default:
err = -EINVAL;
goto out;
case SS_CONNECTED: // 此套接口已经和对端的套接口相连接了,即连接已经建立
err = -EISCONN;
goto out;
case SS_CONNECTING: // 此套接口正在尝试连接对端的套接口,即连接正在建立中
err = -EALREADY;
break;
case SS_UNCONNECTED:
err = sk->sk_prot->connect(sk, uaddr, addr_len);
sock->state = SS_CONNECTING;
err = -EINPROGRESS;
break;
}
......
}
刚创建完毕的socket的状态就是SS_UNCONNECTED,根据switch判断会去调用sk->sk_prot->connect,对于TCP socket而言,调用的是tcp_v4_connect。
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
// 设置socket的状态为TCP_SYN_SENT
tcp_set_state(sk, TCP_SYN_SENT);
// 动态选择一个端口
err = inet_hash_connect(&tcp_death_row, sk);
// 函数用来根据sk中的信息,构建一个syn报文,并将它发送出去
err = tcp_connect(sk);
}
在这里会把socket的状态设置为TCP_SYN_SENT,再通过inet_hash_connect来动态地选择一个可用的端口。
2)选择可用端口
找到inet_hash_connect的源码,我们来看看到底端口时如何选择出来的。
int inet_hash_connect(struct inet_timewait_death_row *death_row, struct sock *sk)
{
return __inet_hash_connect(death_row, sk, inet_sk_port_offset(sk), __inet_check_established, __inet_hash_nolisten);
}
这里需要关注一下调用__inet_hash_connect的两个参数 :
- inet_sk_port_offset(sk):这个函数根据要链接的目的IP和端口等信息生成一个随机数
- __inet_check_established:检查是否和现有ESTABLISH状态的连接冲突的时候用的函数
接着进入__inet_hash_connect函数
int __inet_hash_connect(...)
{
// 是否绑定过端口
const unsigned short snum = inet_sk(sk)->inet_num;
// 获取本地端口配置
inet_get_local_port_range(&low, &high);
remaing = (high - low) + 1;
if(!sum) {
// 遍历查找
for(int i = 1; i <= remaining; i++){
port = low + (i + offset) % remaining; // 保证了port会在范围之间
// 查看是否是保留端口,是则跳过
if(inet_is_reserverd_local_port(port))
continue;
// 查找和遍历已经使用的端口的哈希表链
head = &hinfo->bhash[inet_bhashfn(net, port, hinfo->bhash_size)];
inet_bind_bucket_for_each(tb, &head->charin) {
// 如果端口已经使用
if(net_eq(ib_net(tb), net) && tb->port == port) {
// 通过check_established继续检查是否可用
if(!check_established(death_row, sk, port, &tw))
goto ok;
}
}
// 未使用的话
tb = inet_bind_bukcet_create(hinfo->bind_bucket_cachep, ...);
......
goto ok;
}
}
}
在这个函数中首先判断了inet_sk(sk)->inet_num,如果调用过bind,那么这个函数会选择好端口并设置在inet_num上,加入没有调用过bind,那么snum为0。
接着调用inet_get_local_port_range,这个函数读取的是net.ipv4.ip_local_port_range这个内核参数,来读取管理员配置的可用的端口范围。
该参数的默认值是32768-61000,意味着端口与总可用量是61000-32768=28232个。如果觉得这个数字不够用,那么可以通过修改net.ipve4.ip_local_port_range内参参数来重新设置。
接下来进入for循环,其中offset是通过inet_sk_port_offset(sk)计算出来的随机数(是调用__inet_hash_connect时传进来的参数)。这段循环的作用就是从某个随机数开始,把整个可用端口范围遍历一遍,直到找到可用的端口为止。具体逻辑如下
- 从随机数+low开始选取一个端口
- 判断端口是否是保留端口,即判断端口是否在net.ipv4.ip_local_reserved_ports中(如果因为某种原因不希望某些端口被内核使用则可以写入这个参数)
- 获取已使用端口的哈希表
- 遍历哈希表判断端口是否被使用,如果没有找到则说明可以使用,已使用过则调用check_established(具体逻辑见下部分)
- 找到合适的端口:通过inet_bind_bucket_create申请一个inet_bind_bucket来记录端口已经使用了,并用哈希表的形式管理起来。
- 找不到合适的端口:返回-EADDRNOTAVAIL,也就是我们在用户程序上看到的Cannot assign requested address
所以如果遇到这个错误,应该想到去查一下net.ipv4.ip_local_port_range中设置的可用端口的范围是不是太小了。
3)端口被使用过怎么办
在遍历已使用端口的哈希表时,对于已被使用的端口,会去调用check_established继续检查是否可用,如果这个函数返回0,则说明端口可以继续使用。
对于TCP连接而言,维护的是一对四元组,分别由收发双方的端口号和ip地址决定,只要四元组中任意一个元素不同,都算是两条不同的连接。所以只要现有的TCP连接中四元组不与要建立的连接的其他三个元素完全一致,该端口就仍然可以使用。
check_established实际上会去调用__inet_check_established
static int __inet_check_established(struct inet_timewait_death_row *death_row,
struct sock *sk, __u16 lport,
struct inet_timewait_sock **twp)
{
// 查找哈希桶
ehash_bucket *head = inet_ehash_buket(hinfo, hash);
// 遍历看看有没有四元组一样的,一样的话就报错
sk_nulls_for_each(sk2, node, &head->chain) {
if(sk2->sk_hash != hash)
continue;
if(likely(INET_MATCH(sk2, net, acookie, saddr, daddr, ports, dif))
goto not_unique;
}
unique:
return 0;
not_uniqueue:
return -EADDRNOTAVAIL;
}
该函数首先找到inet_ehash_bucket(类似bhash,只不过这是所有ESTABLISH状态的socket组成的hash表),然后遍历整个哈希表,如果哈希值不相同则说明当前四元组不一致,如果哈希值相同则使用INET_MATCH进一步进行比较。如果匹配就是说明四元组完全一致,所以这个端口不可用,返回-EADDRNOTAVAIL,如果不匹配(四元组有一或以上个元素不一样)那么就返回0,表示该端口仍然可以用于建立新连接。
INET_MATCH中除了将__saddr、__daddr、__ports进行了比较,还比较了一些其他项目,所以TCP连接还有五元组、七元组之类的说法。
一台客户机的最大建立的连接数并不是65535,只要有足够多的服务端,单机发出百万条连接没有任何问题。
4)发起SYN请求
找到可用的端口后,回到tcp_v4_connect,接下来会去调用tcp_connect来根据sk中的信息构建一个syn报文发送出去。
int tcp_connect(struct sock *sk)
{
// 申请并设置skb
buff = alloc_skb_fclone(MAX_TCP_HEADER + 15, sk->sk_allocation);
tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
// 添加到发送队列sk_write_queue
tcp_connect_queue_skb(sk, buff)
// 实际发出syn
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
// 启动重传定时器
inet_csk_resetxmit_timer(sk, ICSK_TIME_RETRANS, inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
}
tcp_connect一口气做了这么几件事:
- 申请一个skb,并将其设置为syn包
- 添加到发送队列上
- 调用tcp_transmit_skb将该包发出(同之前内核发送网络包的方式,传递给网络层)
- 启动一个重传定时器,超时会重发
该定时器的作用是等到一定时间后收不到服务端的反馈的时候来开启重传。首次超时时间是在TCP_TIMEOUT_INIT宏中定义的,该值在Linux3.10版本是1秒, 在一些老版本中是3秒。
TCP在实现过程中,发送队列和重传队列都是sk_write_queue,这两个队列是一并处理的。
5)小结
客户端执行connect函数的时候,把本地socket状态设置成了TCP_SYN_SENT,选了一个可用的端口,接着发出SYN握手请求并启动重传定时器。
在选择端口时,会随机地从ip_local_port_range指定的范围中选择一个位置开始循环遍历,找到可用端口后发出syn握手包,如果端口查找失败则抛出异常“Cannot assign requested address”。如果当前可用端口很充足,那么循环很快就可以退出。而如果ip_local_port_range中的端口快被用完了,那么这时候内核就大概率要把循环执行很多轮才能找到可用端口,这会导致connect系统调用的CPU开销上涨。
而如果在connect之前使用了bind,将会使得connect系统调用时地端口选择方式无效,转而使用bind时确定的端口。即如果提前调用bind选了一个端口号,会先尝试使用该端口号,如果传入0也会自动选择一个。但默认情况下一个端口只会被使用一次,所以对于客户端角色的socket,不建议使用bind。
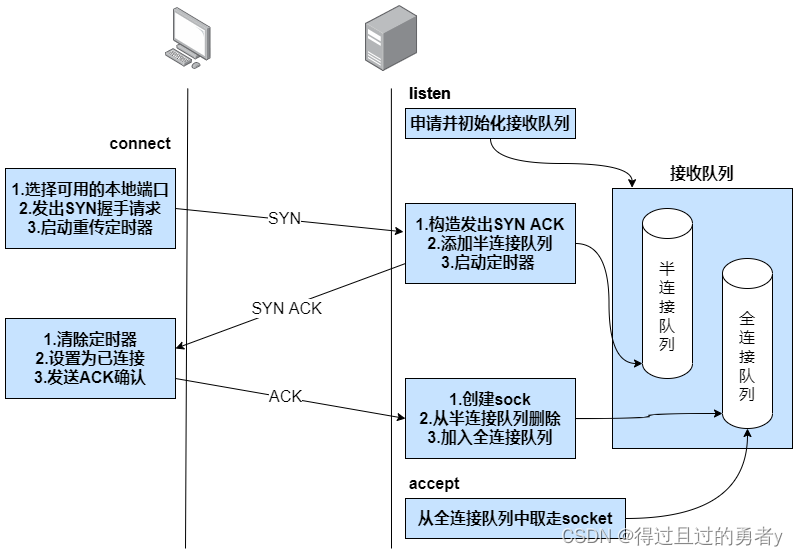
四、完整TCP连接建立过程
在一次TCP连接建立(三次握手)的过程中,并不只是简单的状态的流转,还包括端口选择、半连接队列、syncookie、全连接队列、重传计时器等关键操作。
在三次握手的过程,服务端核心逻辑是创建socket绑定端口,listen监听,最后accept接收客户端的的请求;而客户端的核心逻辑是创建socket,然后调用connect连接服务端。
socket的创建、服务端的listen、客户端的connect在前面都已经讲解过了,那么这里从客户端connect发出syn包之后开始。
1)服务端响应SYN
在服务端,所有的TCP包(包括客户端发来的SYN握手请求)都经过网卡、软中断进入tcp_v4_rcv。在该函数中根据网络包skb的TCP头信息中的目的IP信息查找当前处于listen状态的socket,然后继续进入tcp_v4_do_rcv处理握手过程(因为listen状态的socket不会收到的进入预处理队列。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
......
if(sk->sk_state == TCP_ESTABLISHED) {}
// 服务端收到第一步握手SYN或者第三步ACK都会走到这里
if(sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if(!nsk)
goto discard;
if(nsk != sk) {
if(tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
if(tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
}
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb)
{
// 查找listen socket的半连接队列
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source, iph->saddr, iph->daddr);
if(req)
return tcp_check_req(sk, skb, req, prev, false);
......
}
在tcp_v4_do_rcv中判断当前socket是listen状态后,首先会到tcp_v4_hnd_req查看是否处于半连接队列。如果再半连接队列中没有找到对应的半连接对象,则会返回listen的socket(连接尚未创建);如果找到了就将该半连接socket返回。服务端第一次响应SYN的时候,半连接队列自然没有对应的半连接对象,所以返回的是原listen的socket,即nsk == sk。
在tcp_rcv_state_process里根据不同的socket状态进行不同的处理
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr th, unsigned int len)
{
swich(sk->sk_state) {
case TCP_LISTEN:
// 判断是否为syn握手包
if(th->syn) {
......
if(icsk->icsk_af_ops->conn_request(sk, skb) < 0)
return 1;
......
}
其中conn_request是一个函数指针,指向tcp_v4_conn_request。服务端响应SYN的主要逻辑都在整个tcp_v4_conn_request里。
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
// 查看半连接队列是否满了
if(inet_csk_reqsk_is_full(sk) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, "TCP");
if(!want_cookie)
goto drop;
}
// 在全连接队列满的情况下,如果有young_ack,那么直接丢弃
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
......
// 分配request_sock内核对象
req = inet_reqsk_alloc(&tcp_request_sock_ops);
// 构造syn+ack包
skb_synack = tcp_make_synack(sk, dst, req, fastopen_cookie_present(&valid_foc) ? &valid_foc : NULL);
if(likely(!do_fastopen)) {
// 发送syn+ack响应
err = ip_build_and_send_pkt(skb_aynack, sk, ireq->loc_addr, ireq->rmt_addr, ireq->opt);
// 添加到半连接队列,并开启计时器
inet_csk_reqsk_queue_hash_add(sk, req, TCP_TIMEOUT_INIT);
} else ...
}
在这里首先判断半连接队列是否满了,如果满了进入tcp_syn_flood_action去判断是否开启了tcp_syncookies内核参数。如果队列满且未开启tcp_syncookies,那么该握手包将被直接丢弃。
TCP Syn Cookie 是一个防止 SYN Flood 攻击的技术。当服务器接收到大量伪造的 SYN 请求时,可以消耗掉所有的连接资源,导致合法用户无法建立新的连接,这种攻击方式被称为 SYN Flood 攻击。SYN Flood 是一种 DoS(Denial of Service,服务拒绝)攻击。
这种技术的主要思想是不在服务器上为每个收到的 SYN 请求分配资源,而是通过计算一个 Cookie(实质上是一个哈希值),将这个 Cookie 作为 SYN-ACK 包的序列号发回客户端。当客户端回复 ACK 包时,服务器可以从 ACK 包的确认号中恢复出之前发送的 Cookie,从而验证这个连接请求是有效的。
这种方式可以有效抵御 SYN Flood 攻击,因为服务器不需要为每个 SYN 请求分配资源,伪造的 SYN 请求不会消耗服务器的资源。但是,SYN Cookie 技术也有一些局限性,例如它不兼容一些 TCP 的高级特性(如窗口缩放),并且在计算 Cookie 时也会消耗一些 CPU 资源
接着判断全连接队列是否满了,因为全连接队列满也会导致握手异常,那干脆就在第一次握手的时候也判断了。如果全队列满了,且young_ack数量大于1的话,那么同样也是直接丢弃。
young_ack是半连接队列里保存着的一个计时器,记录的是刚有SYN到达,没有被SYN_ACK重传定时器重传过SYN_ACK,同时也没有完成过三次握手的sock数量。
inet_csk_reqsk_queue_young(sk) > 1这一判断,其实是在检查是否存在"年轻"的连接请求。如果存在这样的请求,而且全连接队列又已经满了,那么就会选择拒绝新的连接请求,以防止服务器过载。
接下来是构造synack包,然后通过ip_build_and_send_pkt把它发送出去。
最后把当前的握手信息添加到半连接队列,并且启动计时器。计时器的作用是如果某个时间内还收不到客户端的第三次握手,服务端就会重传synack包。
此时半连接队列中的request_sock的状态为SYN_RECV。等到服务器收到客户端的ACK报文,也就是三次握手完成后,request_sock 会被"升级"为一个完整的 sock 结构体,状态变为 ESTABLISHED。
2)客户端响应SYNACK
客户端收到服务端发来的synack包的时候,由于自身状态是TCP_SYN_SENT,所以不会进入ESTABLISHED、LISTEN分支,同样进入tcp_rcv_state_process函数。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len)
{
switch(sk->sk_state) {
// 服务端收到第一个SYN包
case TCP_LISTEN:
......
// 客户端第二次握手处理
case TCP_SYN_SENT:
// 处理synack包
queued = tcp_rcv_synsent_state_process(sk, skb, th, len);
......
return 0;
}
tcp_rcv_synsent_state_process是客户端响应synack的主要逻辑
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *tp, unsigned int len)
{
......
tcp_ack(sk, skb, FLAG_SLOWPATH);
// 连接建立完成
tcp_finish_connect(sk, skb);
if(sk->sk_write_pending ||
icsk->icsk_accept_queue.rskq_defer_accept ||
icsk->icsk_ack.pingpong)
// 延迟确认......
else {
tcp_send_ack(sk);
}
}
-
tcp_ack(sk, skb, FLAG_SLOWPATH):这行代码在收到SYN-ACK包后更新了socket的状态,包括序列号、确认号等。
-
tcp_clean_rtx_queue:删除重传队列中已被确认的数据包,停止重传定时器
在TCP协议中,当发送一个数据包时,发送方将这个数据包存储在重传队列中,并启动一个定时器。如果在定时器超时之前收到了这个数据包的确认(ACK),那么发送方就知道这个数据包已经成功地到达接收方,它就会从重传队列中删除这个数据包。否则,当定时器超时时,发送方就会重新发送这个数据包。
tcp_clean_rtx_queue函数就是处理这个重传队列的函数。它遍历重传队列,查看哪些数据包已经得到了确认,然后从重传队列中删除这些数据包。它还会计算网络的往返时间(RTT),以便于调整TCP的超时时间。
如果重传队列中的所有数据包都已经被确认,那么停止重传定时器。
-
-
tcp_finish_connect(sk, skb):这行代码完成了TCP连接的建立。它将socket的状态从SYN_SENT改为ESTABLISHED,初始化TCP连接的拥塞控制算法、接收缓存和发送缓存空间等信息,开启keep alive计时器,然后唤醒等待连接完成的进程。
Keep-alive计时器就是用于控制发送keep-alive数据包的计时器。通常,当一个TCP连接上没有任何数据包的传输时,我们就启动这个计时器。如果在计时器超时之前有新的数据包在这个连接上发送或接收,那么我们就重置计时器。如果计时器超时,那么我们就发送一个keep-alive数据包,并重新启动计时器等待响应。如果接收到了对这个数据包的响应,那么我们就知道连接仍然存在。如果在一定时间内没有收到响应,那么我们就假定连接已经断开,并将其关闭。
-
满足TCP的延迟确认(Delayed ACK)机制:这种情况下,ACK包可能会和后续的数据包一起发送,以减少网络上的包的数量。
-
不满足延迟确认机制:立即调用tcp_send_ack(sk),申请和构造ACK包然后发送出去。这个ACK包是对对方SYN-ACK包的确认,也是TCP三次握手的最后一步。
即客户端响应来自服务端的synack时清除了connect时设置得重传定时器,把当前socket状态设置为ESTABLISHED,开启保活计时器然后发出第三次握手的ack确认。
3)服务端响应ACK
服务端响应第三次握手的ack时同样会进入tcp_v4_do_rcv。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
......
if(sk->sk_state == TCP_ESTABLISHED) {}
// 服务端收到第一步握手SYN或者第三步ACK都会走到这里
if(sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if(!nsk)
goto discard;
if(nsk != sk) {
if(tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
}
由于此处已经是第三次握手了,半连接队列里会存在第一次握手时留下的半连接信息,所以tcp_v4_hnd_req会在半连接队列里找到半连接request_sock对象后进入tcp_check_req
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb)
{
// 查找listen socket的半连接队列
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source, iph->saddr, iph->daddr);
if(req)
return tcp_check_req(sk, skb, req, prev, false);
......
}
struct sock *tcp_check_req(...)
{
// 创建子socket
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
......
// 清理半连接队列
inet_csk_reqsk_queue_unlink(sk, req, prev);
inet_csk_reqsk_queue_removed(sk, req);
// 添加全连接队列
inet_csk_reqsk_queue_add(sk, req, child);
return child;
}
该函数完成了以下工作:
- 判断接收队列是不是满了,没满则创建子socket
- 把连接请求块从半连接队列删除
- 添加新创建的sock对象到全连接队列链表的尾部
因为是第三次握手所以返回了新的子socket,那么显然nsk!=sk,所以会执行tcp_child_process来为新的子socket进行一些初始化和处理工作,如设置TCP标志等,如果处理成功则会返回0。
int tcp_child_process(struct sock *parent, struct sock *child,
struct sk_buff *skb)
{
int ret = 0;
int state = child->sk_state;
if (!sock_owned_by_user(child)) {
ret = tcp_rcv_state_process(child, skb, tcp_hdr(skb), skb->len); // 进行状态处理
if (state == TCP_SYN_RECV && child->sk_state != state) // 状态处理结束后socket的状态发生了变化
// 调用sock_def_readable函数发送可读事件通告给listening socket,告知其可以进行accept系统调用
parent->sk_data_ready(parent, 0);
} else {
// 新的socket被进行系统调用的进程锁定;因为这是新的socket,所以在tcp_v4_rcv加的锁不会起到保护新socket的作用
__sk_add_backlog(child, skb); // 加入到后背队列
}
bh_unlock_sock(child);
sock_put(child);
return ret;
}
可以看到其中再一次调用了tcp_rcv_state_process,然后唤醒等待队列上的进程。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len)
{
switch(sk->sk_state) {
// 服务端收到第一次握手的SYN包
case TCP_LISTEN:
......
// 客户端第二次握手处理
case TCP_SYN_SENT:
......
// 服务端收到第三次握手的ACK包
case TCP_SYN_RECV:
// 改变状态为连接
tcp_set_state(sk, TCP_ESTABLISHED);
......
}
}
服务端响应第三次握手ACK所做的工作就是把当前半连接对象删除,创建了新的sock后加入全连接队列,最后将新连接状态设置为ESTABLISHED。
4)服务端accept
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err)
{
// 从全连接都列中获取
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
req = reqsk_queue_remove(queue);
newsk = req->sk;
return newsk;
}
struct request_sock {
// 和其它struct request_sock对象形成链表
struct request_sock *dl_next; /* Must be first member! */
// SYN段中客户端通告的MSS
u16 mss;
// SYN+ACK段已经重传的次数,初始化为0
u8 retrans;
......
// SYN+ACK段的超时时间
unsigned long expires;
// 指向tcp_request_sock_ops,该函数集用于处理第三次握手的ACK段以及后续accept过程中struct tcp_sock对象的创建
const struct request_sock_ops *rsk_ops;
// 连接建立前无效,建立后指向创建的tcp_sock结构
struct sock *sk;
......
};
reqsk_queue_remove操作很简单,就是从全连接队列的链表里获取一个头元素返回就行。
所以,accept的重点工作就是从已经建立好的全连接队列中取出一个返回给用户进程。
5)小结
TCP连接建立的操作可以简单划分为两类:
- 内核消耗CPU进行接收、发送或者处理,包括系统调用、软中断和上下文切换。它们的耗时基本是几微妙左右。
- 网络传输将包从一台机器上发出,经过各式各样的网络互联设备道到达目的及其。网络传输的耗时一般在几毫秒到几百毫秒,远超于本机CPU处理。
由于网络传输耗时比双端CPU耗时要高1000倍不止,所以在正常的TCP连接建立过程中,一般堪虑网络延时即可。
一个RTT指的是包从一台服务器到另一台服务器的一个来回的延迟时间。从全局来看,TCP连接建立的网络耗时大约需要三次传输,再加上少许的双方CPU开销,总共大约比1.5倍RTT大一点点。
不过从客户端的角度来看,只要ACK包发出了,内核就认为连接建立成功,可以开始发送数据了。所以如果在客户端统计TCP连接建立耗时,只需要两次传输耗时——即比1个RTT多一点时间(从服务端视角来看也是同理)。
五、异常TCP建立情况
1)connect系统调用耗时失控
客户端在发起connect系统调用的的时候,主要工作就是端口选择。在选择的过程中有一个大循环,从ip_local_port_range的一个随机位置开始把这个范围遍历一遍,找到可用端口则退出循环。如果端口很充足,那么循环只需要执行少数几次就可以退出。但是如果端口消耗掉很多已经不充足,或者干脆就没有可用的了,那么这个循环就得执行很多遍。
int inet_hash_connect(...)
{
inet_get_local_range(&low, &high);
remaining = (high - low) + 1;
for(int i = 1; i <= remaining; i++) {
// 其中offset是一个随机数
port = low + (i + offset) % remaining;
head = &hinfo->bhash[inet_bhashfn(net, port, hinfo->bhash_size)];
// 加锁
spin_lock(&head->lock);
// 一大段端口选择逻辑,选择成功就goto ok,选择不成功就goto next_port
......
next_port:
// 解锁
spin_unlock(&head->lock);
}
}
在每次循环内部需要等待所以及在哈希表中执行多次的搜索。并且这里的锁是自旋锁,如果资源被占用,进程并不会挂起,而是占用CPU不断地尝试去获得锁。假设端口范围ip_local_port_range配置的是10000~30000,而且已经用尽了。那么每次当发起连接的时候,都需要把循环执行两万遍才退出。这时会涉及大量的哈希查找以及自旋锁等待开销,系统态CPU将出现大幅度上涨。
所以当connect系统调用的CPU大幅度上涨时,可以尝试修改内核常熟ipv4.ip_local_port_range多预留一些端口、改用长连接或者尽快回收TIME_WAIT等方式。
2)第一次握手丢包
服务端在响应来自客户端的第一次握手请求的时候,会判断半连接队列和全连接队列是否溢出。如果发生溢出的,可能会直接将握手包丢弃,而不会反馈给客户端。
1. 半连接队列满
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
// 看看半连接队列是否满了
if(inet_csk_reqsk_queue_is_full(sk) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, "TCP");
if(!want_cookie)
goto drop;
}
......
}
在以上代码中inet_csk_reqsk_is_full如果返回true就表示半连接队列满了,另外tcp_syn_flood_action判断是否打开了内核参数cp_syncookies,如果未打开则返回false。
也就是说,如果半连接队列满了,而且没有开启tcp_syncookies,那么来自客户端的握手包将goto drop,即直接丢弃。
SYN Flood攻击就是通过耗光服务端上的半连接队列来使得正常的用户连接请求无法被响应。不过在现在的Linux内核里只要打开tcp_syncookies,半连接队列满了仍然可以保证正常握手的进行。
2. 全连接队列满
当半连接队列判断通过以后,紧接着还由全连接队列的相关判断。如果满了服务端还是会丢弃它。
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
// 看看半连接队列是否满了
......
// 在全连接队列满的情况下,如果有young_ack,那么直接丢弃
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
......
}
sk_aceeptq_is_full判断全连接队列是否满了,inet_csk_reqsk_queue_young判断有没有young_ack(未处理完的半连接请求)。如果全连接队列满且同时有young_ack,那么内核同样直接丢掉该SYN握手包。
3. 客户端发起重试
假设服务端发生了全/半连接队列溢出而导致的丢包,那么转换到客户端的视角来看就是SYN包没有任何响应。
因为客户端在发出握手包的时候,开启了一个重传定时器。如果收不到预期的synack,超时的逻辑就会开始执行。不过重传定时器的时间单位都是以秒来计算的,这意味着如果有握手重传发生,即使第一次重传就能成功,那接口最快响应也是一秒以后的事情了,这对接口耗时影响非常大。以下是connect系统调用关于重传的逻辑。
int tcp_connect(sruct sock *sk)
{
......
// 实际发出SYN
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
// 启动重传定时器
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
}
其中inet_csk(sk)->icsk_rto是超时时间,该值初始化的时候被设置为TCP_TIMEOUT_INIT(1秒,在一些老版本的内核里为3秒)。
void tcp_connect_init(struct sock *sk)
{
// 初始化为TCP_TIMEOUT_INIT
inet_csk(sk)->icsk_rto = TCP_TIMEOUT_INIT;
......
}
如果能正常接收到服务端响应的synack,那么客户端的这个定时器会清除。这段逻辑在tcp_rearm_rto里,具体的调用顺序为tcp_rcv_state_process->tcp_rcv_synsent_state_process->tcp_ack->tcp_clean_rtx_queue->tcp_rearm_rto;
void tcp_stream_rto(struct sock *sk)
{
inet_csk_clear_xmit_timer(sk, ICSK_TIME_RETRANS);
}
如果服务端发生了丢包,那么定时器到时候会进入回调函数tcp_write_timer中进行重传(其实不只是握手,连接状态的超时重传也是在这里完成的)。
static void tcp_write_timer(unsigned long data)
{
tcp_write_timer_handler(sk);
......
}
void tcp_write_timer_handler(struct sock *sk)
{
// 取出定时器类型
event = icsk->icsk_pending;
switch(event) {
case ICSK_TIME_RETRANS:
// 清除定时器
// icsk_pending用于标记一个 TCP 连接当前有哪些定时器是激活状态,是一个位掩码,每一位都对应一个特定的定时器
icsk->icsk_pending = 0;
tcp_retransmit_timer(sk);
break;
......
}
}
这里tcp_transmit_timer是重传的主要函数。在这里完成重传以及下一次定时器到期的时间设置。
void tcp_retransmit_timer(struct sock *sk)
{
......
// 超过了重传次数则退出
if(tcp_write_timeout(sk))
goto out;
// 重传
if(tcp_retransmit_skb(sk, tcp_write_queue_head(head)) > 0) {
// 重传失败
......
}
// 退出前重新设置下一次的超时时间
out_reset_timer:
// 计算超时时间
if(sk->sk_state == TCP_ESTABLISHED) {
......
} else {
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
}
// 设置
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, icsk->icsk_rto, TCP_RTO_MAX);
}
tcp_write_timeout用来判断是否重试过多,如果是则退出重试逻辑。
对于SYN握手包主要的判断依据是net.ipv4_tcp_syn_retries(内核参数,对于一个新建连接,内核要发送多少个SYN连接请求才决定放弃。不应该大于255,默认值是5),但其实并不是简单的对比次数,而是转化成了时间进行对比。所以如果在线上看到了实际重传次数和对应内核参数不一致也不用太奇怪。
接着调用tcp_retransmit_skb函数重发了发送队列里的头元素。
最后再次设置下一次超时的时间,为前一次时间的两倍。
4. 实际抓包结果
客户端发出TCP第一次握手之后,在1秒以后进行了第一次握手重试。重试仍然没有响应,那么接下来一次又分别在3秒、7秒、15秒、31秒和63秒等事件共重试了六次(我的tcp_syn_retries设置为6)。
当服务端第一次握手的时候出现了半/全连接队列溢出导致的丢包,那么接口响应的时间将会很久(只进行一次重试都需要一秒的时间),用户体验会受到很大的影响。并且如果某一个时间段内有多个进程/线程卡在了和Redis或者MySQL的握手连接上,那么可能会导致线程池剩下的线程数量不足以处理服务。
3)第三次握手丢包
客户端在收到服务器的synack相应的时候,就认为连接建立成功了,然后会将自己的连接状态设置为ESTABLISHED,发出第三次握手请求。但服务端在第三次握手的时候还有可能有意外发生。
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb)
{
// 查找listen socket的半连接队列
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source, iph->saddr, iph->daddr);
if(req)
return tcp_check_req(sk, skb, req, prev, false);
......
}
struct sock *tcp_check_req(...)
{
// 创建子socket
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
......
// 清理半连接队列
inet_csk_reqsk_queue_unlink(sk, req, prev);
inet_csk_reqsk_queue_removed(sk, req);
// 添加全连接队列
inet_csk_reqsk_queue_add(sk, req, child);
return child;
}
在第三次握手时,首先从半连接队列里拿到半连接对象,之后通过tcp_check_req => inet_csk(sk)->icsk_af_ops->syn_recv_sock来创建子socket
这里syn_recv_sock是一个函数指针,在ipv4中指向了tcp_v4_syn_recv_sock。
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, ...)
{
// 判断全连接队列是不是满了
if(sk_acceptq_is_full(sk))
goto exit_overflow;
......
}
从上述代码可以看出,第三次握手的时候,如果服务器全连接队列满了,来自客户端的ack握手包又被直接丢弃。
由于客户端在发起第三次握手之后就认为连接建立了,所以如果第三次握手失败,是由服务端来重发synack(服务端发送synack之后启动了定时器,并将该半连接对象保存在了半连接队列中)。服务端等到半连接定时器到时后,想客户端重新发起synack,客户端收到后再重新恢复第三次握手。如果这个期间服务端全连接队列一直都是满的,那么服务端重试5次(受内核参数net.ipv4.tcp_synack_retries控制)后就放弃了。
客户端在发起第三次握手之后往往就开始发送数据,其实这个时候连接还没有真的建立起来。如果第三次握手失败了,那么它发出去的数据,包括重试都将被服务端无视,知道连接真正建立成功后才行。
4)握手异常总结
-
端口不足:导致connect系统调用的时候过多地执行自旋锁等待与哈希查找,会引起CPU开销上涨。严重的情况下会耗光CPU,影响用户逻辑的执行。
- 调整ip_local_port_range来尽量加大端口范围
- 尽量复用连接,使用长连接来削减频繁的握手处理
- 开启tcp_tw_reuse和tcp_tw_recycle
-
服务端在第一次握手丢包(半连接队列满且tcp_syncookies为0 || 全连接队列满且有未完成的半连接请求):客户端不断发起syn重试
-
服务端在第三次握手丢包(全连接队列满):服务端不断发起synack重试
握手重试对服务端影响很大,常见的解决方法如下:
- 打开syncookies:防止SYN Flood攻击等
- 加大连接队列长度:全连接是min(backlog,net.core.somaxconn),半连接是min(backlog,somaxconn,tcp_max_syn_backlog) + 1向上取整到2的幂次(且不小于16)
- 尽快调用accept
- 尽早拒绝:例如MySQL和Redis等服务器的内核参数tcp_abort_on_overflow设置为1,如果队列满了直接reset指令发送给客户端,告诉其不要继续等待。这时候客户端会收到错误“connection reset by peer”
- 尽量减少TCP连接的次数
六、如何查看是否有连接队列溢出发生
1)全连接队列溢出判断
全连接队列溢出都会记录到ListenOverflows这个MIB(管理信息库),对应SNMP统计信息中的ListenDrops这一项。
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
// 查看半连接队列是否满了
......
// 在全连接队列满的情况下,如果有young_ack,那么直接丢弃
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
......
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
}
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, ...)
{
// 判断全连接队列是不是满了
if(sk_acceptq_is_full(sk))
goto exit_overflow;
......
exit_overflow:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
exit:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
}
可以看到服务端在响应第一次握手和第三次握手的时候,在全队列满了时都会调用NET_INC_STATS_BH来增加LINUX_MIB_LISTENOVERFLOWS和LINUX_MIB_LISTENDROPS这两个MIB。
在proc.c中,这两个MIB会被整合到SNMP统计信息。
在执行netstat-s的时候,该工具会读取SNMP统计信息并展现出来。
#watch 'netstat -s | grep overflowed'
198 times the listen queue of a socket overflowed
通过netstat -s输出中的xx times the listen queue如果查看到数字有变化,则说明一定是服务端上发生了全连接队列溢出了。
2)半连接队列溢出判断
半连接队列溢出时更新的是LINUX_MIB_LISTENDROPS这个MIB,然而不只是半连接队列发生溢出的时候会增加该值,全连接队列满了该值也会增加。所以根据netstat -s查看半连接队列是否溢出是不靠谱的。
对于半连接队列是否溢出这个问题,一般直接看服务器tcp_syncookies是不是1就行了。如果该值是1,那么根本不会发生半连接溢出丢包。而如果不是1,则建议改为1。
如果因为其他原因不想打开,那么除了netstat -s,也可以同时查看listen端口上的SYN_RECV的数量,如果该数量达到了半连接队列的长度(根据内核参数和自己传递的backlog可以计算出来)则可以确定有半连接队列溢出。
七、问题解答
-
为什么服务端程序都需要先listen一下
- 内核在响应listen调用的时候创建了半连接、全连接两个队列,这两个队列是三次握手中很重要的数据结构,有了它吗才能正常响应客户端的三次握手。所以服务器提供服务前都需要先listen一下才行。
-
半连接队列和全连接队列长度如何确定
- 半连接队列:max((min(backlog, somaxconn, tcp_max_syn_backlog) + 1)向上取整到2的幂次), 16)
- 全连接队列:min(backlog, somaxconn)
-
“Cannot assign requested address”这个报错是怎么回事
- 一条TCP连接由一个四元组构成,其中目的IP和端口以及自身的IP都是在连接建立前确定了的,只有自身的端口需要动态选择出来。客户端会在connect发起的时候自动选择端口号。具体的选择就是随机地从ip_local_port_range选择一个位置开始循环判断,跳过ip_local_reserver_ports里设置的要避开的端口,然后挨个判断是否可用。如果循环完也没有找到可用端口,就会抛出这个错误。
-
一个客户端端口可以同时用在两条连接上吗
- connect调用在选择端口的时候如果端口没有被用上那就是可用的,但是如果被用过也不代表这个端口就不可用。
- 如果用过,则会去判断是否有老的连接四元组与当前要建立的这个新连接四元组完全一致,如果不完全一致则该端口仍然可用。
-
服务端半/全连接队列满了会怎么样
-
服务端响应第一次握手的时候会进行半连接队列和全连接队列是否满的判断
- 如果半连接队列满了且未开启tcp_syncookies,丢弃握手包
- 如果全连接队列满了且存在young_acck,丢弃握手包
-
服务端响应第三次握手的时候会进行全连接队列是否满的判断
- 如果全连接队列满了则丢弃握手包
-
-
新连接的soket内核对象是什么时候建立的
- 内核其实在第三次握手完毕的时候就把sock对象创建好了。在用户进程调用accept的时候,直接把该对象取出来,再包装一个socket对象就返回了。
-
建立一条TCP连接需要消耗多长时间
- 一般网络的RTT值根据服务器物理距离的不同大约是在零点几秒、几十毫秒之间。这个时间要比CPU本地的系统调用耗时长得多。所以正常情况下,在客户端或者是服务端看来,都基本上约等于一个RTT。
- 如果一旦出现了丢包,无论是那种原因,需要重传定时器来接入的话,耗时就最少要一秒了。
-
服务器负载很正常,但是CPU被打到底了时怎么回事
- 如果在端口极其不充足的情况下,connect系统调用的内部循环需要全部执行完毕才能判断出来没有端口可用。如果要发出的连接请求特别频繁,connect就会消耗掉大量的CPU。如果要发出的连接请求特别频繁,connect就会消耗掉大量的CPU。当服务器上的进程不多,但是每个进程都在疯狂的消耗CPU,这时候就会出现CPU被消耗光,但是服务器负载却不高的情况。
参考资料:
3.3 连接建立完成_tcp_v4_hnd_req_Remy1119的博客-CSDN博客
TCP输入 之 tcp_v4_rcv - AlexAlex - 博客园 (cnblogs.com)
Linux TCP数据包接收处理 tcp_v4_rcv - kk Blog —— 通用基础 (abcdxyzk.github.io)
Linux操作系统学习笔记(二十三)网络通信之收包 | Ty-Chen's Home
Linux socket系统调用(三)----tcp_sock、sock、socket结构体以及TCP slab缓存建立_Blue summer的博客-CSDN博客
《深入理解Linux网络》—— 张彦飞