目录
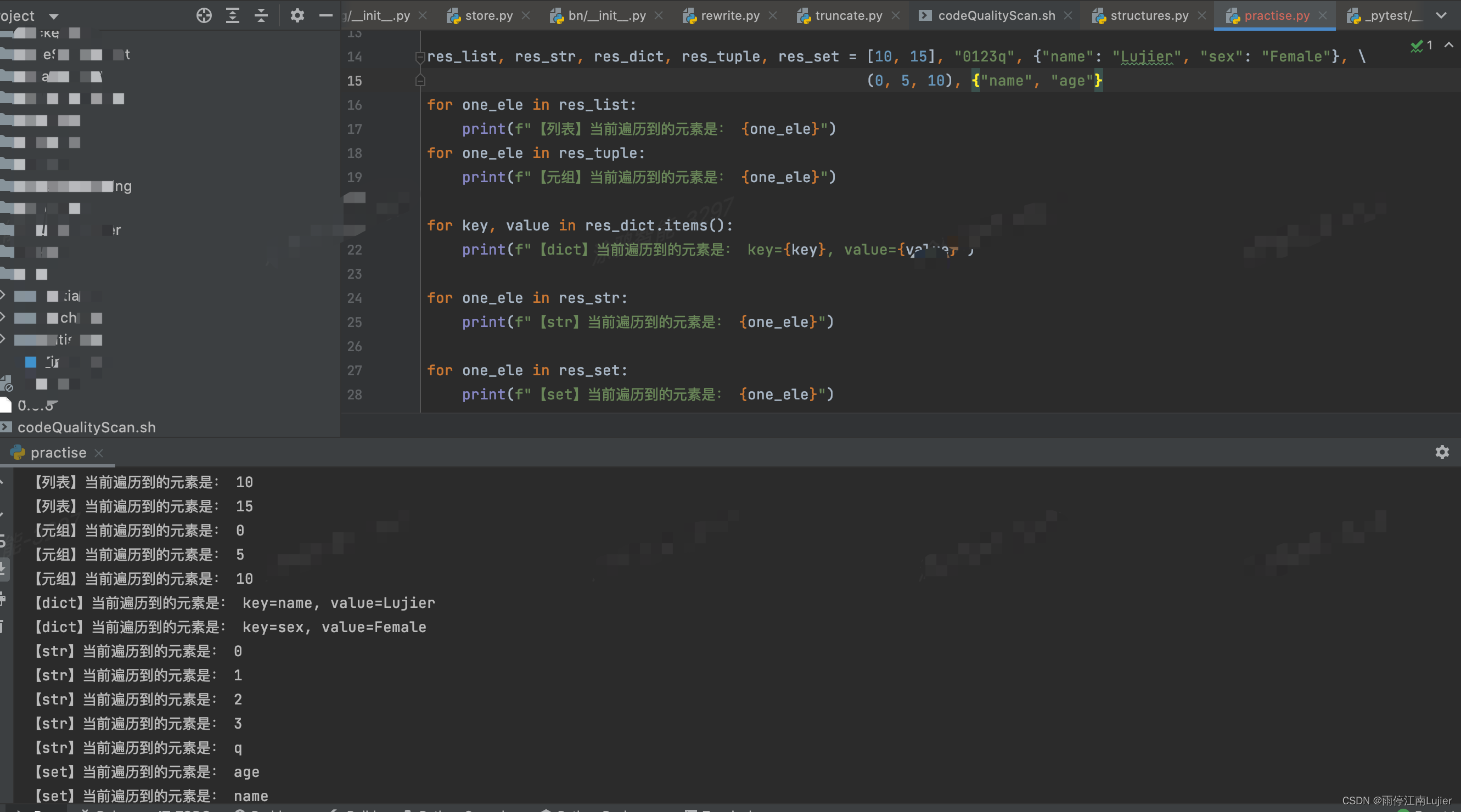
cookie工作原理
cookie绕过登录
总结
在编写接口自动化测试用例或其他脚本的过程中,经常会遇到需要绕过用户名/密码或验证码登录,去请求接口的情况,一是因为有时验证码会比较复杂,比如有些图形验证码,难以通过接口的方式去处理;再者,每次请求接口前如果都需要先去登录一次,这样不仅效率低,还耗费资源。
有些网站是使用cookie辨别用户身份的,此时我们便可以先登录一次,拿到登录成功后的cookie,后续请求时在请求头中加入该cookie,便可保持登录状态直接请求。
cookie工作原理
HTTP协议1.0版本是无状态的,对于事务处理没有记忆能力,比如用户登录了某个网站后,再次刷新这个页面去请求服务器,如果没有相关机制的话,服务器是不知道这个请求是否还是刷新之前登录的用户发出来的。此时,为了维持用户的登录状态,即为了使服务器能够识别页面刷新之后的请求,就可以使用cookie机制。
cookie原理简单概括如下:
-
用户在客户端 (一般为浏览器) 中访问某个页面 ,也就是向服务器发送请求。
-
服务器收到请求后,会在响应头中设置
Set-Cookie字段值,该字段存储相关信息和状态。 -
客户端解析服务器HTTP响应头中的Set-Cookie字段,并以key=value的形式保存在本地,之后客户端每次发送HTTP请求时,都会在请求头中增加Cookie字段。
-
服务器接收到客户端的HTTP请求之后,会从请求头中取出Cookie数据,来校验客户端状态或身份信息。
以登录某网站为例,点击登录时请求sign_in接口,请求成功后 (即登录成功后) 在响应头中会返回set-cookie字段,如下:
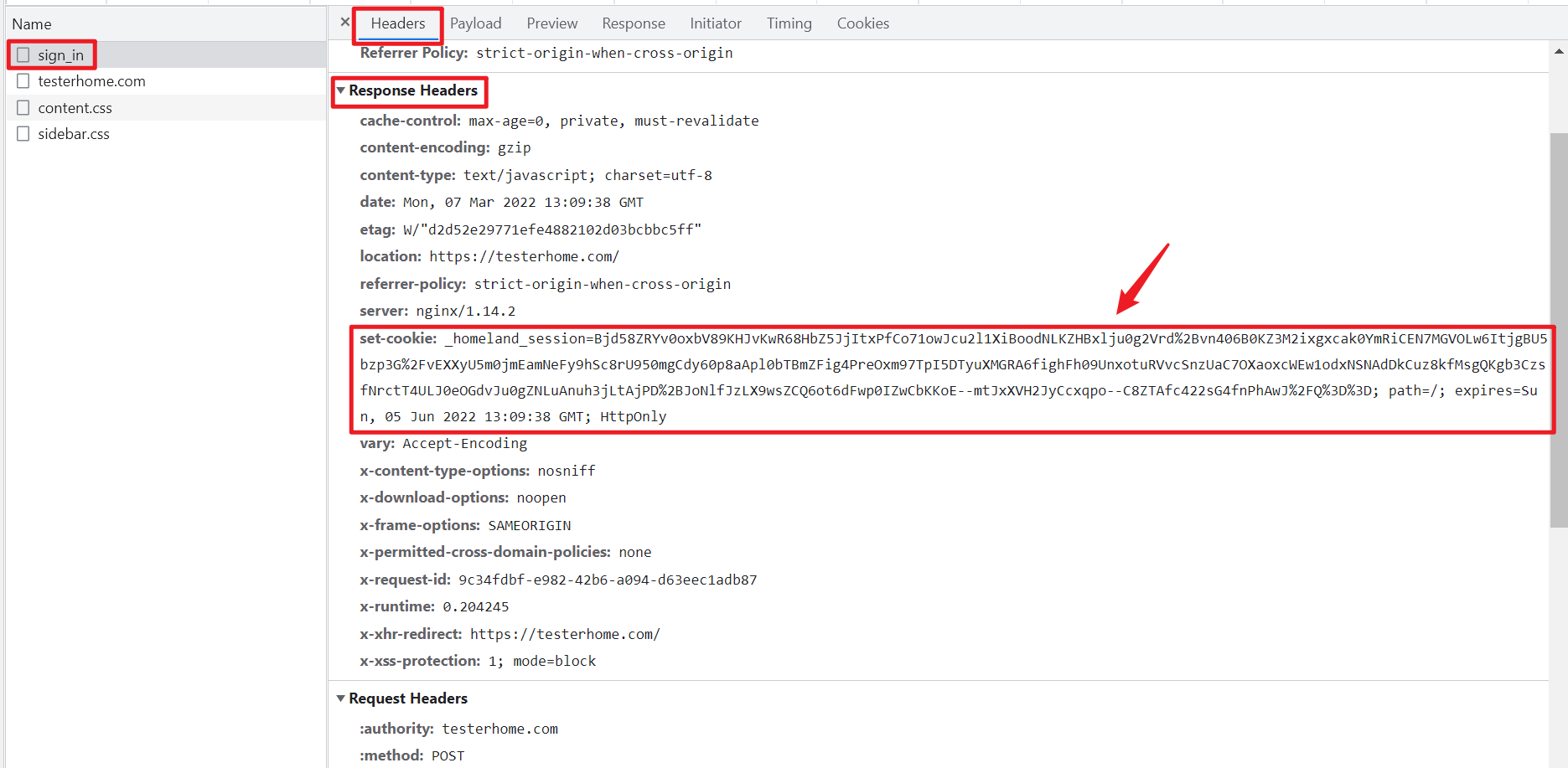
浏览器会保存上图中set-cookie字段的值,后续发送请求 (即登录后进行页面操作) 时,请求头中都会携带包含刚刚保存的set-cookie值的cookie,如下所示:

服务器接收到这个cookie后,便会用它去查找内存中的记录,有则校验成功。
由此可知,如果需要绕过用户名密码、验证码等进行模拟登录,然后再去请求其他接口,那么我们可以先拿到登录成功后的cookie,将cookie放在请求头中,再去调用需要登录才能请求的接口,便能调用成功。
cookie绕过登录
1,哪些场景需要使用cookie绕过登录?
-
网络爬虫,代码去爬取某个网站时需要验证码登录,而这时代码获取验证码登录有一定难度,就可以先抓取到登录后的cookie用于后续的接口请求。
-
接口自动化测试,对某个需要登录的项目进行接口测试,每次请求时都先请求登录接口进行登录会影响效率而且极其不方便,这时就可以抓取到第一次登录后的cookie,后续每次接口请求都带上该cookie,服务器就会认为是登录状态。
-
其他需要绕过登录的场景。
2,接下来举例说明怎样编写python脚本,利用cookie机制绕过登录。
-
需求:请求接口获取博客园网自己账号的个人信息。
-
需求分析:
- 需要先登录博客园,才能去请求获取个人信息接口拿到个人信息
- 该网站的登录方式有两种:用户名、密码登录,手机验证码登录
- 可尝试使用cookie绕过这两种登录方式。
3,思路:
-
首先,先使用手机验证码登录网站,Fiddler进行抓包,获取登录后的cookie信息;
-
然后,编写python代码,拿上一步中获取到的cookie信息去请求获取个人信息接口;
-
最后,个人信息获取成功便说明绕过了登录。
4,实际操作流程如下:
-
首先,登录网站,Fiddler抓包获取登录成功后的cookie。
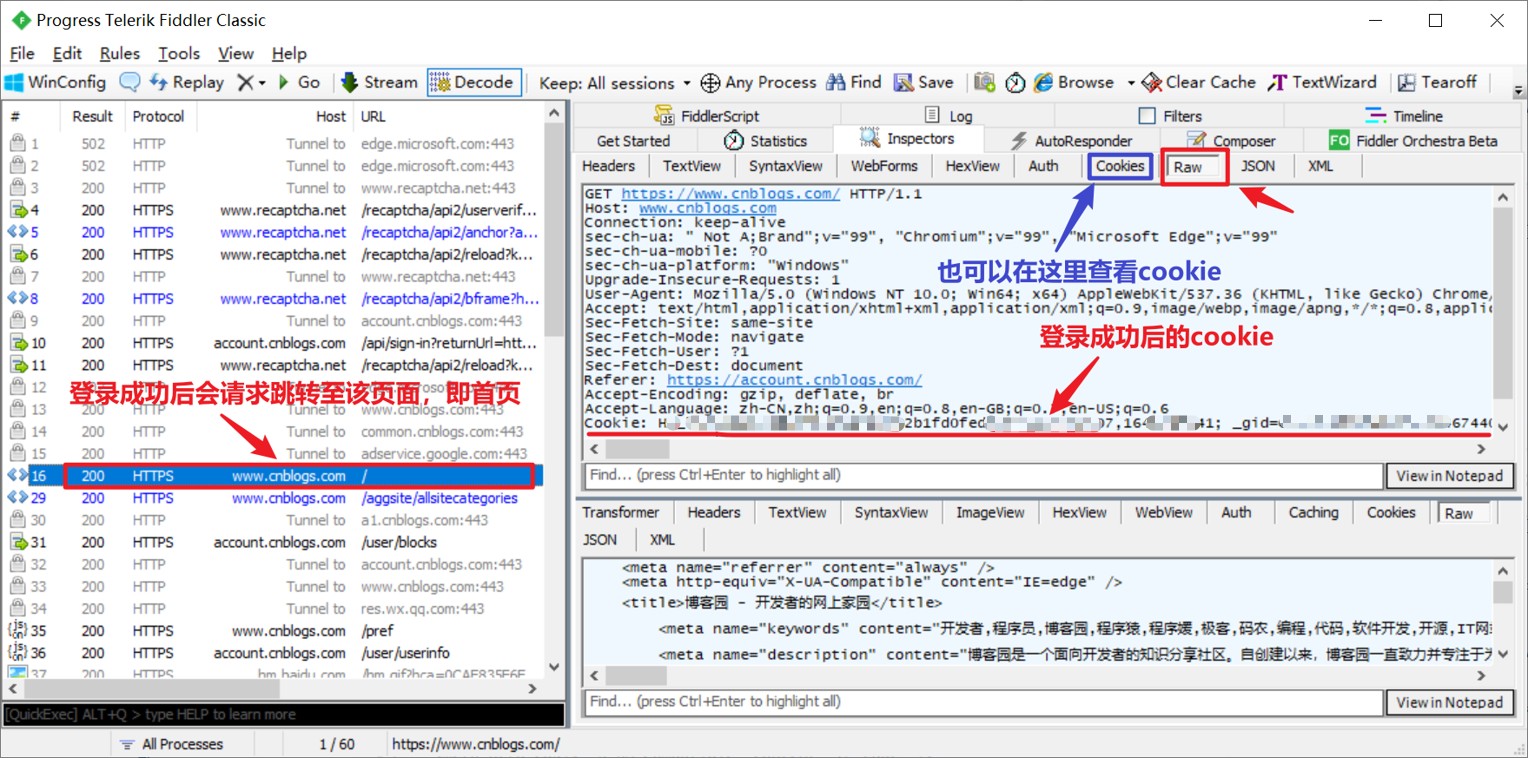
-
然后,cookie信息去请求获取个人信息接口。
登录后同样可以抓取到获取个人信息接口的信息,如下:

个人信息接口请求方式为GET,请求URL如图所示,那么我们只需要这两点信息就足够了。接下使用上一步中拿到的cookie去请求这个接口。代码如下:
import requests url = "https://account.cnblogs.com/user/userinfo" headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.30", "cookie": "登录成功后的cookie" } res = requests.get(url=url, headers=headers).text print(res)运行代码,结果如下:

可以看到,成功获取了个人信息。
-
最后,为了验证是cookie确实绕过了登录,我们修改上面的脚本,不加入该cookie,请求个人信息接口,代码如下:
import requests url = "https://account.cnblogs.com/user/userinfo" headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.30" } res = requests.get(url=url, headers=headers).text print(res)运行后结果如下:

从上图可以看出来,不加登录成功后的cookie去请求接口,则会提示先登录或注册。
总结
cookie绕过登录其实是登录状态保持,而不是真的不需要登录。
并非所有的网站都是使用cookie机制,除了cookie机制外,还有session、token等方式进行会话保持,这在后续的文章中会进行说明。