YOLO学习笔记1. YOLOV1的基本概念
- 一、 YOLO简介
- 二、一些基本概念
- 1. two-stage和one-stage
- 2. 指标分析
- (1)精度的概念
- (2)召回率的概念
- (3)IOU
- (4)置信度阈值
- (5) mAP
- 3. 示例
- 三、YOLOV1网络架构
- 1. 整体说明
- 2. 预测边界框和条件类别概率
- (1) 网格单元(Grid Cell):
- (2) 边界框预测(Bounding Box Prediction):
- (3) 条件类别概率(Conditional Class Probability):
- 3. 预测后处理
- (1)置信度过滤(Confidence Thresholding):
- (2) 非极大值抑制(Non-Maximum Suppression,NMS):
- (3)全概率计算
一、 YOLO简介
YOLO(You Only Look Once)是一种流行的实时目标检测算法,由Joseph Redmon和Ali Farhadi等人开发。
YOLO作为目标检测算法,旨在识别图像中出现的物体以及它们的位置。与其他目标检测算法不同的是,YOLO将整个图像看作一个整体,并使用单个CNN(卷积神经网络)模型直接预测图像中所有物体的类别和位置。这使得YOLO具有更快的速度和更高的实时性,而不需要额外的后处理步骤。
YOLO算法通过在图像上滑动网格来实现目标检测,每个单元格负责预测一组边界框和类别概率。每个边界框由5个值表示,包括中心坐标、宽度、高度和一个表示对象存在的置信度得分。分类概率为每个单元格预测的每个对象类别提供了一个分数。
尽管YOLO在速度和实时性方面表现出色,但也存在一些缺点,如难以检测小目标和位于密集区域的物体。然而,YOLO算法在许多实际应用中已被证明是一种高效、准确的目标检测算法。
二、一些基本概念
1. two-stage和one-stage
two-stage和one-stage都是目标检测算法中常用的概念。
two-stage算法包括两个阶段:区域提取和分类定位。首先,算法会生成一些候选区域,然后对这些区域进行分类和回归,获取最终的目标检测结果。例如,Faster R-CNN就是一种经典的two-stage算法。
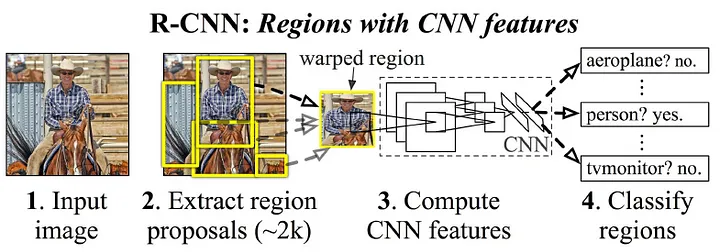
one-stage算法只包括一个阶段,直接对整张图像进行分类和回归得到目标检测结果。相比于two-stage算法,one-stage算法的速度更快,但准确率较低。常见的one-stage算法有SSD和YOLO等。

2. 指标分析
(1)精度的概念
精度(Precision)是用于评估分类器预测结果的指标之一,表示预测为正例的样本中,真正为正例的比例。
在二分类问题中,我们可以将预测结果分为:
- 真正例(True Positive,TP):预测为正例且实际为正例的样本数
- 假正例(False Positive,FP):预测为正例但实际为负例的样本数
- 真反例(True Negative,TN)
- 假反例(False Negative,FN):预测为负例但实际为正例的样本数
四种情况。
精度的计算公式如下:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP+FP}
Precision=TP+FPTP
即精度等于真正例的数量除以所有被预测为正例的样本的数量之和。
精度是一个重要的指标,因为它告诉我们分类器正确预测为正例的概率有多大。在某些任务中,例如医学诊断或金融欺诈检测等任务中,准确性至关重要,因此精度通常被用作主要的性能指标。
(2)召回率的概念
在目标检测领域,召回率(recall)也是一个非常重要的指标,它用于衡量目标检测算法的查全率。
在目标检测中,召回率是指算法正确检测到的物体框(true positives,TP)的数量与实际物体框(ground truth,GT)的数量之比。具体来说,如果检测到的物体框与GT的IoU超过了设定的阈值,那么就视为检测成功,否则视为检测失败。召回率计算公式如下:
R e c a l l = T P / ( T P + F N ) Recall = TP / (TP + FN) Recall=TP/(TP+FN)
其中,FN表示未被检测到的GT框的数量,即算法漏检的框数。
在目标检测领域,正确检测到目标非常重要,因为检测到的目标框将被用于后续的目标跟踪、目标识别、行为分析等任务。
一个算法的召回率表示它成功检测到的目标占全部目标的比例,召回率越高,代表算法能够更好地找到目标,具有更高的查全率,对于提高目标检测算法的性能和实用性都是非常有益的。
(3)IOU
IOU(Intersection over Union,交并比)用于评估目标检测算法的准确度,它通过计算预测边界框和真实边界框之间的交集和并集之间的比率来计算的,公式如下:
I O U = 交集面积 / ( 预测框面积 + 真实框面积 − 交集面积 ) IOU = 交集面积 / (预测框面积 + 真实框面积 - 交集面积) IOU=交集面积/(预测框面积+真实框面积−交集面积)

其中:
- 交集面积是预测框和真实框的重叠部分面积,
- 预测框面积和真实框面积分别是两个框的面积。
在目标检测中,如果IOU的值大于或等于一个预设的阈值,则预测框被认为是正确的。一般来说,IOU的阈值为0.5或0.6,具体值可以根据具体的任务和数据集进行调整。
(4)置信度阈值
置信度阈值是指在进行物体检测时,对于预测框的置信度(confidence)进行二值化的阈值。只有当预测框的置信度大于等于阈值时,才会被视为有效的检测结果。换句话说,只有当算法非常确信预测框中包含一个目标时,才会将该预测框作为检测结果输出。
在YOLO中,通常先根据置信度阈值筛选出有效的预测框,然后再使用IOU阈值筛选出具有最高置信度的预测框。这样可以有效地提高检测结果的准确性和召回率。
(5) mAP
精度可以通过计算平均精度(mean average precision,mAP)来综合评估模型的性能。mAP是对每个类别计算的平均准确率(AP)的平均值。
mAP越高,说明该类别的检测效果越好。
mAP的计算方法包括以下几个步骤:
- 对于每个类别,按照置信度从高到低的顺序排序所有检测结果。
- 对于每个检测结果,计算其 Precision-Recall 曲线上每个 Recall 点处的 Precision 值,然后将这些 Precision 值进行插值得到平均精度(AP)。
- 对于每个类别,将所有检测结果的 AP 值进行平均,得到该类别的 mAP 值。
- 最后,将所有类别的 mAP 值进行平均,得到整个数据集的 mAP 值。
在YOLO中,有函数 calculate_mAP()函数用来计算并输出平均精度mAP及Precision-Recall曲线。
3. 示例
假设:有若干狗的图像数据集。
目标:检测在这些图像中识别狗的数量,并计算算法的精度和召回率。
假设:我们使用了一个算法,在这100张图片中检测出了1000只狗,其中正确识别的狗有800只,而错误的识别有200只。此外,还有400只狗没有被识别到。
我们可以使用以下公式计算TP、FP、Precision和Recall:
-
TP(真正例):算法正确识别为狗的狗的数量,即800只。
-
FP(假正例):算法错误地将非狗的物体识别为狗的数量,即200只。
-
FN(假反例):未被识别出的狗的数量,即400只。
-
Precision(精度):算法正确识别为狗的狗的比例,即:
P r e c i s i o n = T P T P + F P = 800 800 + 200 = 0.8 Precision=\frac{TP}{TP+FP}=\frac{800}{800+200}=0.8 Precision=TP+FPTP=800+200800=0.8 -
Recall(召回率):实际为狗的狗被正确识别为狗的比例,即:
R e c a l l = T P T P + F N = 800 800 + 400 = 0.6667 Recall=\frac{TP}{TP+FN}=\frac{800}{800+400}=0.6667 Recall=TP+FNTP=800+400800=0.6667
此算法召回率比较低,意思有很多狗没有检测到,算法有进一步优化的空间。
三、YOLOV1网络架构
1. 整体说明

YoLo的9层模型:

YOLOv1的网络架构包括以下几个部分:
- 输入层:4484483的图像,接受原始图像数据,并将其转化为CNN可以处理的形式。
- 卷积层:YOLOv1中采用了24个卷积层和2个全连接层,其中卷积层用于从图像中提取特征,全连接层用于将特征映射到物体类别和位置。
- 池化层:池化层用于对特征图进行下采样,减少特征图的大小,提高计算效率。
- 特征提取层:特征提取层是YOLOv1的核心组件,它将卷积层和池化层的输出转化为一个特征向量,并且包含了物体类别和位置信息。
- 全连接层:全连接层用于将特征向量映射到物体类别和位置的预测值。
- 输出层:输出层输出物体类别和位置的预测值,并计算损失函数,用于优化模型参数。
2. 预测边界框和条件类别概率
(1) 网格单元(Grid Cell):
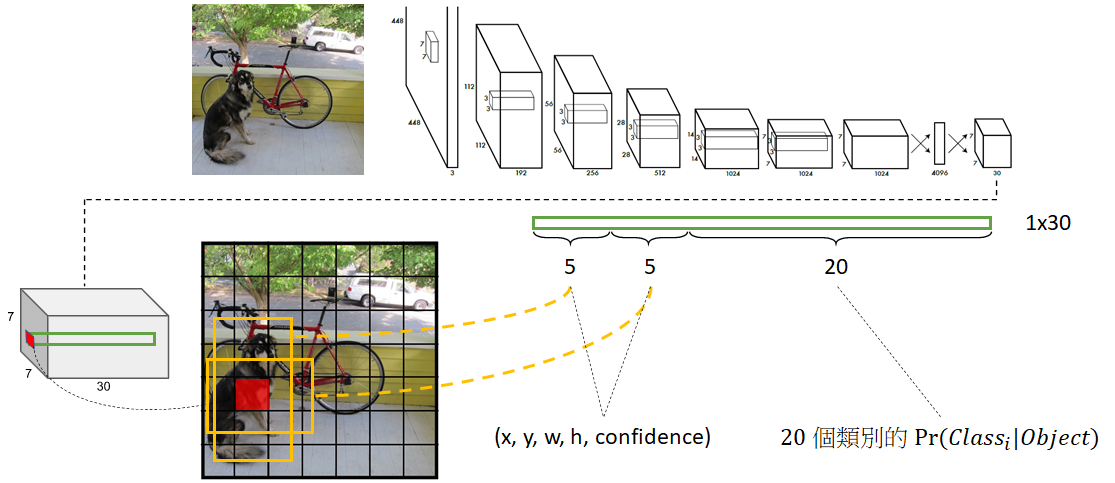
YOLOv1将输入图像分割为 S × S 的网格单元。每个网格单元负责预测一个或多个边界框,并判断边界框中是否存在目标物体。
网格单元的数量由网络结构和超参数决定。通常情况下,YOLOv1采用 7 × 7 的网格单元。
(2) 边界框预测(Bounding Box Prediction):
每个网格单元预测 B 个边界框,每个边界框由 5 个要素构成:(x, y, w, h, confidence)。
(x, y) 是边界框的中心坐标相对于当前网格单元的位置,并用相对值表示(相对于单元宽度和高度)。
(w, h) 是边界框的宽度和高度相对于整个图像的比例(相对于图像宽度和高度)。
confidence 是边界框中存在目标物体的置信度得分,用于衡量预测的准确性。
(3) 条件类别概率(Conditional Class Probability):
对于每个网格单元和每个边界框,YOLOv1预测 C 个类别的条件概率。
每个类别的条件概率表示在给定边界框存在目标物体的前提下,该边界框属于每个类别的概率。
通常,YOLOv1采用 softmax 函数将原始输出转换为类别概率,确保每个类别概率在 0 到 1 之间,并且所有类别的概率之和为 1。
总结来说,YOLOv1将输入图像划分为网格单元,并为每个网格单元预测边界框和条件类别概率。每个边界框由边界框坐标和置信度组成,表示边界框的位置和预测准确性。条件类别概率用于表示在给定边界框存在目标物体的前提下,边界框属于每个类别的概率。通过这种方式,YOLOv1可以同时进行目标检测和分类,并输出图像中所有目标物体的位置和类别信息。
最后输出 7730 维的张量。

3. 预测后处理
要把7730维张量变成最后的预测结果。
(1)置信度过滤(Confidence Thresholding):
在预测阶段,YOLO为每个边界框预测一个置信度得分,用于衡量预测的准确性。通常情况下,置信度得分介于0到1之间。
在置信度过滤中,我们通过设定一个阈值,将置信度得分低于阈值的边界框过滤掉。只有得分高于阈值的边界框会被保留下来,表示它们的预测较为可信。
(2) 非极大值抑制(Non-Maximum Suppression,NMS):
非极大值抑制是一种常用的技术,用于减少重叠边界框的数量,以提高检测结果的准确性。
在目标检测中,可能会存在多个边界框预测同一个目标物体。为了消除冗余的边界框,NMS算法会按照置信度得分进行排序,并逐个检查边界框。
对于每个边界框,NMS会计算其与其他边界框的重叠程度(例如,使用交并比IoU)。如果重叠程度超过了设定的阈值,则将该边界框剔除,否则将其保留下来。
通过不断迭代该过程,直到处理完所有边界框,NMS保留的边界框将具有最高的置信度得分,并且彼此之间没有太多重叠。
通过置信度过滤和非极大值抑制,可以剔除置信度较低的边界框并减少重叠的边界框数量,从而得到更准确的目标检测结果。这些后处理步骤有助于提高检测的精度和可靠性,并减少冗余的检测结果。
(3)全概率计算
-
对于每个网格单元和每个边界框,YOLOv1会预测 C 个类别的条件概率,表示在给定边界框存在目标物体的前提下,该边界框属于每个类别的概率。
-
在后处理阶段,首先需要对每个边界框的条件类别概率进行归一化,确保每个类别的概率值在0到1之间,且所有类别的概率之和为1。通常会使用 softmax 函数对原始输出进行归一化处理。
-
接下来,对于每个网格单元,需要将归一化的条件类别概率乘以预测的边界框的置信度得分。这是因为,置信度得分反映了边界框中存在目标物体的概率,乘以条件类别概率可以得到目标类别的置信度。
在完成上述步骤后,可以得到每个边界框的目标类别概率,即考虑了置信度得分和条件类别概率的综合。这样,每个边界框都会具有针对每个类别的目标概率。
![[JVM] 1. 初步认识JVM](https://img-blog.csdnimg.cn/fe3f6df33e5344cabc15b0ddb8d4a921.png)