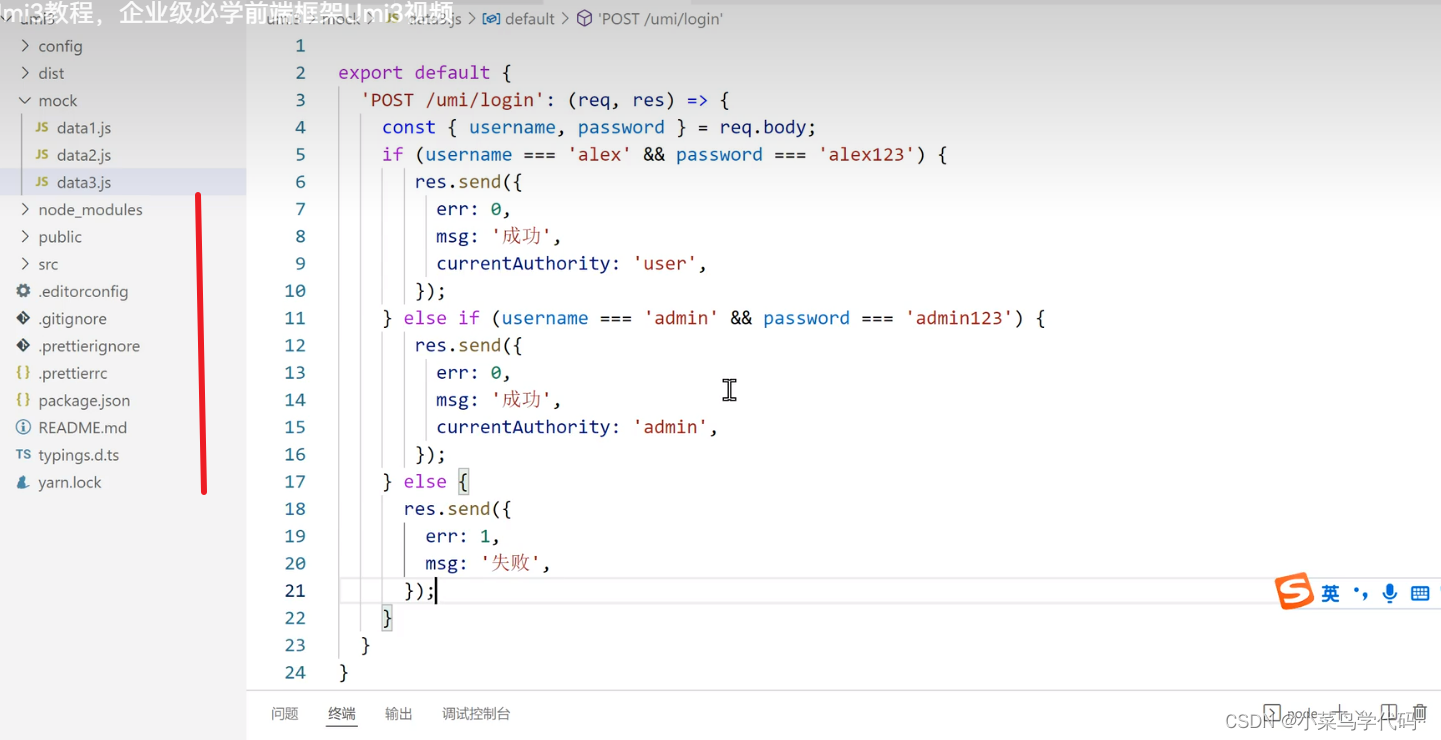
1. 机器学习的定义
基于历史经验的,描述和预测的理论、方法和算法。
从历史数据中,发现某些模式或规律(描述),利用发现的模式和规律进行预测。
2. 机器学习能做什么
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识
别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战
略游戏和机器人运用。
机器学习方法在大型数据库中的应用被称为数据挖掘(Data Mining)。
大量的金属氧化物以及原料从矿山开采出来,处理后产生少量的珍贵物质。数据挖掘中,需要处理
大量的数据以构建简单有用的模型,例如高精度的预测模型。
机器学习还可以解决视觉、语音识别以及机器人方面的许多问题。
通过分析一个人脸部图像的多个样本,学习程序可以捕获到那个人特有的模式。然后进行辨认。
3. 机器学习算法的分类
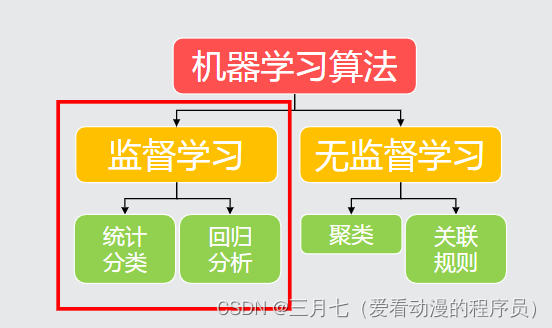
监督学习:数据集中的每个样本有相应的正确答案。
比如:在婴儿的大脑中,可以将大脑看为模型。
监督学习算法图示:

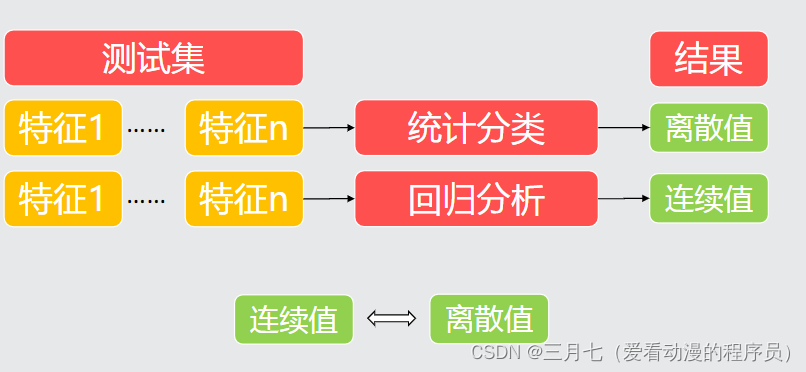
分类和回归的区别在于输出变量的类型。
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
比如:预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,这是一个分类任务;
预测人脸、鼻子、眼睛坐标位置;这是一个回归任务;
预测这是谁的人脸?是小明的脸吗?这是一个分类任务;
预测这张图是猫?狗?牛?鸟?这是一个分类任务;
预测这张图是猫的概率?这是一个回归任务。
无监督学习图示:
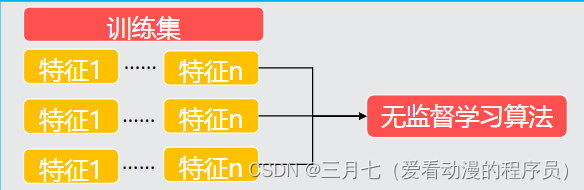
比如:Google News搜集网上的新闻,并且根据新闻的主题将新闻分成许多簇, 然后将在同一个簇
的新闻放在一起。
对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚
类算法将他们分成不同的类型。这就是一种无监督学习, 因为我们只是给定了一些数据,而并不知
道哪些是第一种类型的人,哪些是第二种类型的人等等。
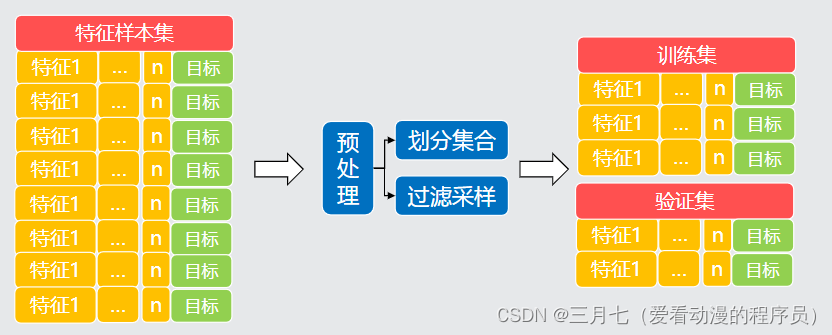
4. 机器学习过程

预处理的过程:
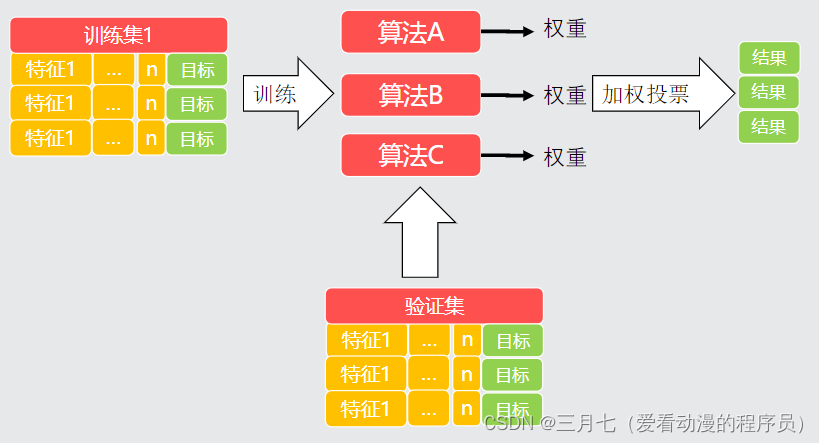
可能需要用多多种算法,算法融合的过程:
5. 假设空间与归纳偏好
假设空间是指所有可能的能满足样本输入和输出的假设函数h(x)的集合。假设函数一定是一个无穷
大的集合。也就是说,如果样本是一串有穷的离散点(xi,yi),i属于1到N,那么能够拟合这这些
点的无穷多个函数都是可能的假设函数。
归纳偏好是一个能挑选最佳假设函数的基准。
以韦小宝的7个老婆为例,这7个老婆均满足小宝的要求,因此构成了大小为7的假设空间。(实际
上,假设空间的大小一定是无穷大的。为了说明问题,我们暂时以7为大小)。那么,如何衡量哪
一个假设空间中哪一个假设函数(老婆)最好呢?如果以温柔体贴为偏好来选,当然是小双;如果
以小宝的迷恋为偏好来讲,假设函数就是阿珂。
一般情况下,我们都使用“奥卡姆剃刀”原则,也就是选择最简单的假设函数。也就是变量最少,变
量的幂指数最小的函数。也就是说,一次函数能拟合时就不选二次函数作为假设函数。
奥卡姆剃刀原理(Ockham's Razor)是由14的世纪哲学家、圣方济各会修士奥卡姆的威廉
(William of Occam,约1285年至1349年)提出的一个原理。这个原理是告诫人们“切勿浪费较多
东西去做用较少的东西同样可以做好的事情。”后来以一种更为广泛的形式为人们所知,即“如无必
要,勿增实体。”
当你有两个处于竞争地位的理论能得出同样的结论,那么简单的那个更好。如果你有两个原理,它
们都能解释观测到的事实,那么你应该使用简单的那个,直到发现更多的证据。对于现象最简单的
解释往往比较复杂的解释更正确。如果你有两个类似的解决方案,选择最简单的。需要最少假设的
解释最有可能是正确的。或者以这种自我肯定的形式出现:让事情保持简单。