删除排序链表中的重复元素(Ⅰ)
题目:
给定一个已排序的链表的头 head ,删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
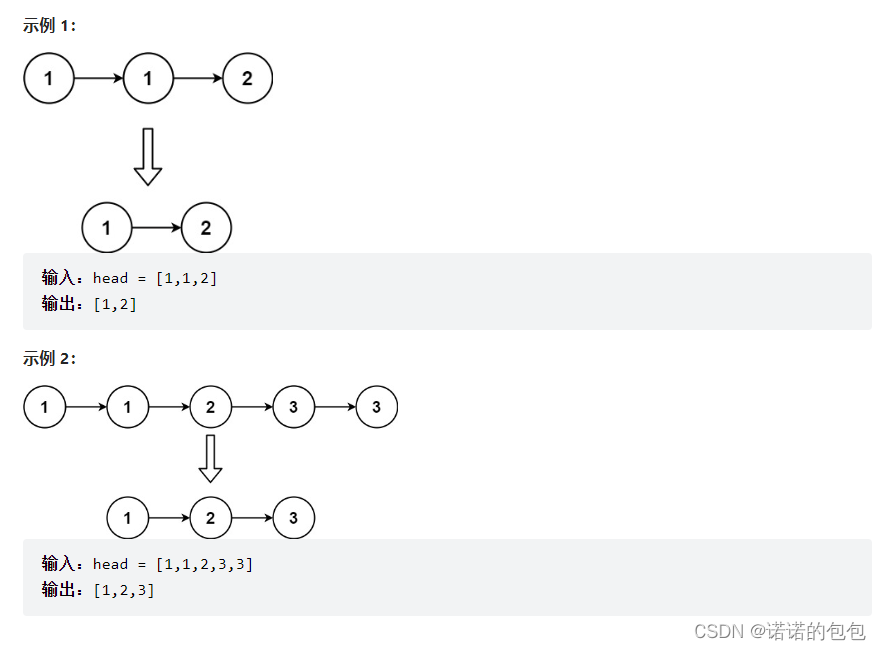
思路:这里的思路很简单,定义两个指针,一个指向head,一个指向head的后一个节点,然后遍历进行比较即可。不相同就尾插,相等就跳过(这里注意要先判断head是否为空,防止空指针解引用,还有就是tail最后一定要置空(野指针))。如下图:

ok,整理好思路后开始写代码,也很简单:
struct ListNode* deleteDuplicates(struct ListNode* head){
//判空
if(head == NULL)
{
return NULL;
}
struct ListNode*cur=head->next;
struct ListNode*tail=head;
//遍历
while(cur)
{
//不相等尾插,相等cur就继续往后走
if(tail->val != cur->val)
{
tail->next=cur;
tail=cur;
}
cur=cur->next;
}
//最后置空,防止野指针
tail->next=NULL;;
return head;
}
删除排序链表中的重复元素(Ⅱ)
题目:
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表
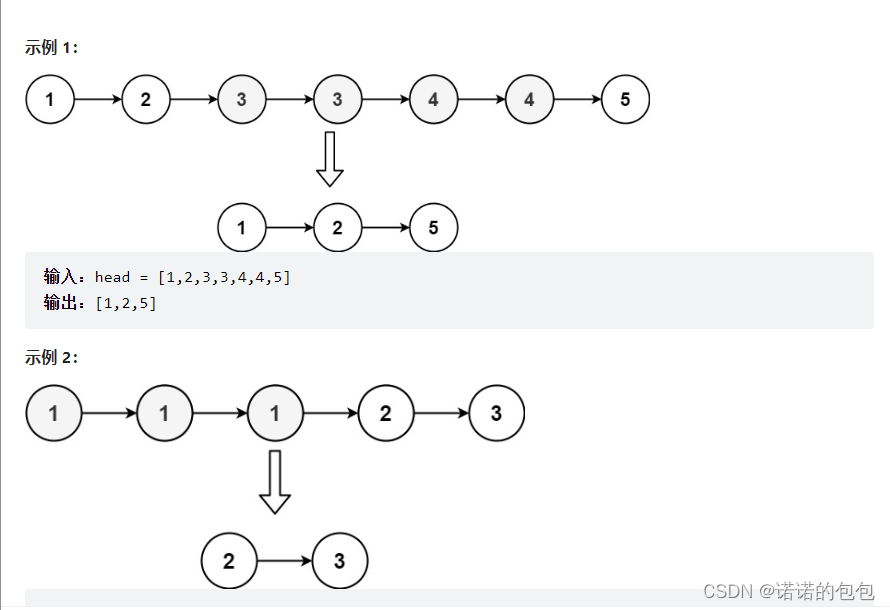
思路:该题是上题的升级版本,稍稍复杂了一点点,不过核心思想是一样的,为非就是遍历,然后比较。这里我们用哨兵卫的单链表,方便我们对节点进行比较。
cur指针从哨兵卫开始,对后面的两个节点进行比较,如果不相等,就进行尾插,如果相等的话,将这个值用tmp保存下来,然后让cur的next往后走,直到找到与该值不相等的,再进行与后面的节点比较是否相等,循环往后走,直到cur->next->next与cur->next 为 NULL。如下图(多画图会很容易理解)

代码实现:
struct ListNode* deleteDuplicates(struct ListNode* head){
//判空
if(head == NULL)
{
return NULL;
}
//哨兵卫
struct ListNode*phead=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode*cur=phead;
phead->next=head;
//进行遍历比较
while(cur->next && cur->next->next)
{
//相等
if(cur->next->val == cur->next->next->val)
{
//用tmp记录,然后next往后找到与tmp不同的,再与cur->next->next比较
int tmp=cur->next->val;
while(cur->next&&cur->next->val==tmp)
{
cur->next=cur->next->next;
}
//走到这,说明找到了与tmp不同的值,或者到空节点停止了,非空就再次进入循环,进行比较
}
//不相等,cur尾插
else
{
cur=cur->next;
}
}
//记录哨兵卫节点的下一个节点,然后释放哨兵卫头节点
//(注意,其实OJ题里面不进行释放,内存泄漏不会报错,也会提示通过的,但还是好习惯一点)
struct ListNode*pphead=phead->next;
free(phead);
return pphead;
}







![[python]初步练习脚本](https://img-blog.csdnimg.cn/268fecf5c30540bf82d96b47e0bfc418.png)