生成树问题汇总
- 注
- 1、最小(大)生成树
- 思路
- 代码
- 例子:
- 1、最小生成树结果是
- 2、最大生成树结果
- 2、在最小生成树中再加一条边,求新的最小生成树
- 思路
- 代码
- 核心代码
- 全部代码
- 例子
- 3、次小生成树
- 思路:在上一个功能基础上进一步扩充
- 代码
- 核心代码
- 全部代码
- 例子
- 4、判断最小生成树是否唯一
- 思路
- 代码
- 核心代码
- 全部代码
- 例子
- 5、极差(生成树:最长边-最短边)最小生成树
- 思路
- 代码
- 核心代码
- 完整代码
- 例子
注
1、我们这里都采用kruskal算法,都使用邻接矩阵存储,这样是最方便的
2、生成树问题中,我们都认为图是:无向有权图
3、生成树,是在图的基础上完成的,虽然名字叫树,但本质上仍然是图,所以仍然用邻接矩阵存
4、完成生成树的问题时,必须要提前实现并查集,并查集是最基本的工具
1、一定记住,并查集序号是从1开始计算的
2、并查集详细解析见:第五章–二叉树 板子
class unions {
public:
unions(int n) {//初始化
this->n = n;
for (int i = 0; i <= n; i++) {
rank[i] = 0;
father[i] = i;
}
}
int find(int item) {
//注意边界处理
if (item > this->n || item <= 0) {
return 0;
}
if (father[item] == item) {
return item;
}
father[item] = find(father[item]);//路径压缩
return father[item];
}
void merge(int x, int y) {
link(find(x), find(y));
}
private:
int father[1000];//存爹数组
int rank[1000];//秩
int n;//规模
void link(int x, int y) {//按秩合并
if (rank[x] > rank[y]) {
father[y] = x;
}
else {
father[x] = y;
}
if (rank[x] == rank[y]) {
rank[y]++;
}
return;
}
};
1、最小(大)生成树
思路
基础算法:
1、给边按照升序(最小生成树)或者降序(最大生成树)排序
2、枚举所有边,如果边的端点属于不同的联通集合,那么该条边成功的连接了两者,合并进入并查集中
3、集合数为1时候,可以退出(但在实现时候没写,懒了,直接枚举所有边了,但这样不好)
代码
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
class unions {//并查集
public:
unions(int n) {
this->n = n;
for (int i = 0; i <= n; i++) {
rank[i] = 0;
father[i] = i;
}
}
int find(int item) {
//注意边界处理
if (item > this->n || item <= 0) {
return 0;
}
if (father[item] == item) {
return item;
}
father[item] = find(father[item]);
return father[item];
}
void merge(int x, int y) {
link(find(x), find(y));
}
private:
int father[1000];
int rank[1000];
int n;
void link(int x, int y) {
if (rank[x] > rank[y]) {
father[y] = x;
}
else {
father[x] = y;
}
if (rank[x] == rank[y]) {
rank[y]++;
}
return;
}
};
//存储边的信息
struct Node_min {
int x;
int y;
int dis;
bool operator < (const Node_min & node) {
//return dis > node.dis;//最大生成树,从大到小排序
return dis < node.dis;//最小生成树,从小到大排序
}
};
//所有示例的编号都从1开始
int minTree[100][100] = {};//存储生成树,都用邻接矩阵存储,方便
int n = 0;//全部的点数
int m = 0;//边数
int min_dis = 0;
vector<Node_min> edge;//存储全部边信息
//最小(大)生成树:kruskal算法
void function_one() {
unions u(n);//一定看好点的编号,并查集从1开始
int mins = 0;
for (int i = 0; i < m; i++) {
Node_min item = edge[i];
if (u.find(item.x) != u.find(item.y)) {//只有新来的边的两个顶点,不在一个集合里,才能合并
u.merge(item.x, item.y);//合并两个点
cout << item.x << "-->" << item.y << endl;
mins += item.dis;
minTree[item.x][item.y] = item.dis;
minTree[item.y][item.x] = item.dis;
}
}
min_dis = mins;
cout << min_dis << endl;//打印最小/最大权值
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
int main()
{
cin >> n >> m;
edge.resize(m);//共m条边
for (int i = 0; i < m; i++) {
cin >> edge[i].x >> edge[i].y >> edge[i].dis;
}
sort(edge.begin(), edge.end());//按照边长排序
cout << "开始构造最小(大)生成树" << endl;
function_one();
return 0;
}
例子:
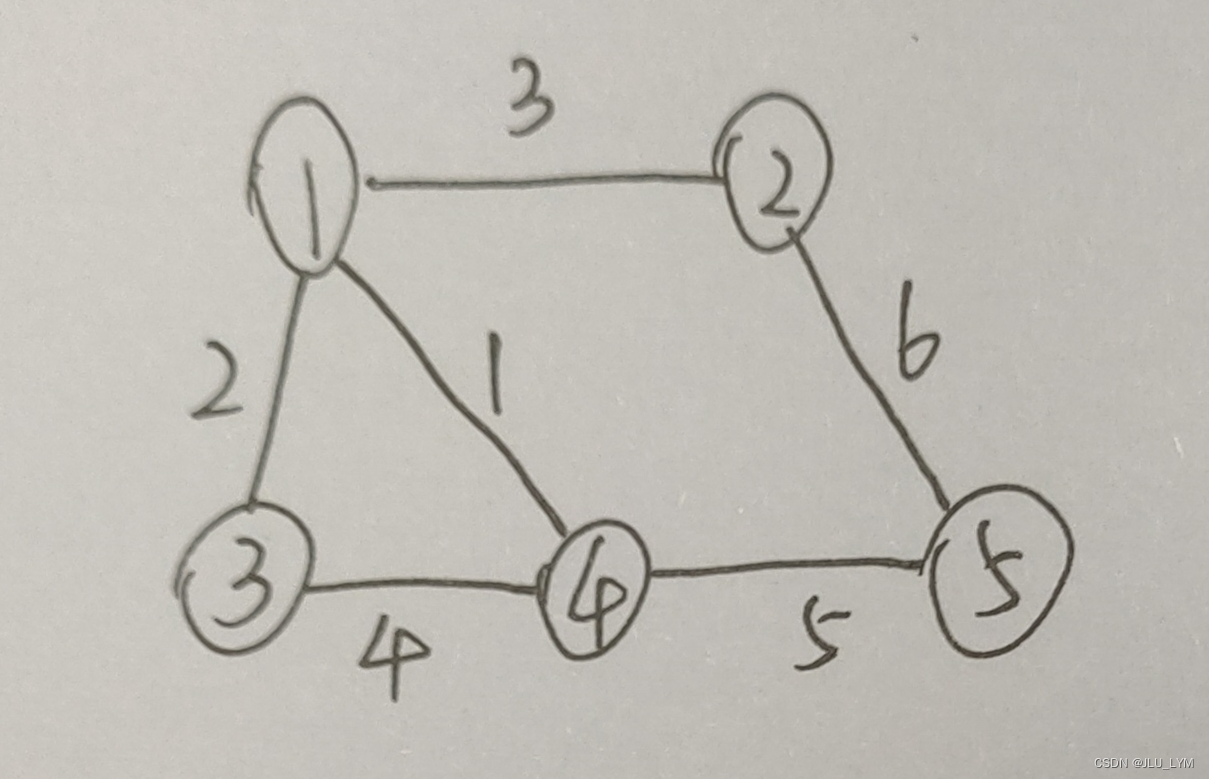
1、最小生成树结果是

程序输出:

2、最大生成树结果


2、在最小生成树中再加一条边,求新的最小生成树
思路
在a—b之间(二者在原最小生成树中未必直接相连)加一条边
1、必会产生环路。
2、在原最小生成树中,找a和b之间的,最长边(dfs函数)
3、新加的边>=最长边,则属于无效添加边,最小生成树不变;反之,替换掉最长边,这样,生成树权值进一步减少,成为新的最小生成树
代码
注:
1、先产生,最小生成树,在执行添加边操作
2、最小生成树中,到达任何一个点都是唯一路径的,所以到达之后,直接做标记即可
核心代码
int s1 = 0, e1 = 0;//全局变量带出最大值对应边的端点(起点、终点)
void dfs(int v, int b, bool visit[], int crew, int s, int e, int* ans) {//参数:当前点,目标点,辅助遍历数组,辅助记录当前最大值,辅助记录最大值边端点,用于带出最大值
visit[v] = true;
if (v == b) {//因为最小生成树没有环路,所以只可能是单一路径到这里,所以到这里就截止即可,看最大值
*(ans) = crew;//crew就是在a-->b遍历途中,不断访问可以访问的点,在所有边中找到最大值,给他带出去
s1 = s;//带出对应边端点
e1 = e;
return;
}
for (int i = 1; i <= n; i++) {
if (minTree[v][i] != 0 && !visit[i]) {//枚举所有可到达的,并且没访问的点
int tmp = crew, s0 = s, e0 = e;//记录本函数原始的数值
//之后过程:对于当前要走的点,看看能否更新最大值,再dfs,再恢复,为下一次做准备
if (minTree[v][i] > crew) {//发现一条边权值更大
crew = minTree[v][i];//更新
s = v;
e = i;
}
dfs(i, b, visit, crew, s, e, ans);
//往这个点走已经走完,所以要继续往别的点走,数据恢复到初始状态,准备走下一次(回溯想法)
crew = tmp;
s = s0;
e = e0;
}
}
}
void function_two() {
int a = 0, b = 0, newe = 0;
cin >> a >> b >> newe;//从a到b,权值是newe
bool visit[1000];
for (int i = 0; i < n; i++) {//n为全局变量,记录总点数
visit[i] = false;
}
int ans = 0;//记录a-->b最长的边
dfs(a, b, visit, 0, 1, 1, &ans);
cout << "a-->b之间最长边是从" << s1 << "-->" << e1 << "长度是" << ans << endl;
if (ans <= newe) {
cout << "输入的新边大于a-->b的最长边,所以原最小生成树不变" << endl;
}
else {
cout << "输入的新边小于于a-->b的最长边,所以原最小生成树改变" << endl;
minTree[s1][e1] = 0;
minTree[e1][s1] = 0;//最长边删除
minTree[a][b] = newe;
minTree[b][a] = newe;//把新的边加进来
}
for (int i = 1; i <= n; i++) {//打印生成树
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
全部代码
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
//并查集(作为工具类使用)
class unions {
public:
unions(int n) {
this->n = n;
for (int i = 0; i <= n; i++) {
rank[i] = 0;
father[i] = i;
}
}
int find(int item) {
//注意边界处理
if (item > this->n || item <= 0) {
return 0;
}
if (father[item] == item) {
return item;
}
father[item] = find(father[item]);
return father[item];
}
void merge(int x, int y) {
link(find(x), find(y));
}
private:
int father[1000];
int rank[1000];
int n;
void link(int x, int y) {
if (rank[x] > rank[y]) {
father[y] = x;
}
else {
father[x] = y;
}
if (rank[x] == rank[y]) {
rank[y]++;
}
return;
}
};
//存储边的信息
struct Node_min {
int x;
int y;
int dis;
bool operator < (const Node_min & node) {
return dis < node.dis;//最小生成树,从小到大排序
}
};
//最小(大)生成树:kruskal算法
void function_one() {
unions u(n);//一定看好点的编号,并查集从1开始
int mins = 0;
for (int i = 0; i < m; i++) {
Node_min item = edge[i];
if (u.find(item.x) != u.find(item.y)) {//只有新来的边的两个顶点,不在一个集合里,才能合并
u.merge(item.x, item.y);//合并两个点
cout << item.x << "-->" << item.y << endl;
mins += item.dis;
minTree[item.x][item.y] = item.dis;
minTree[item.y][item.x] = item.dis;
}
}
min_dis = mins;
cout << min_dis << endl;//打印最小/最大权值
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
//开始添加边并且调整生成树
int s1 = 0, e1 = 0;//全局变量带出最大值对应边的端点
void dfs(int v, int b, bool visit[], int crew, int s, int e, int* ans) {//参数:当前点,目标点,辅助遍历数组,辅助记录当前最大值,辅助记录最大值边端点,用于带出最大值
visit[v] = true;
if (v == b) {//因为最小生成树没有环路,所以只可能是单一路径到这里,所以到这里就截止即可,看最大值
*(ans) = crew;//crew就是在a-->b遍历途中,不断访问可以访问的点,在所有边中找到最大值,给他带出去
s1 = s;
e1 = e;
return;
}
for (int i = 1; i <= n; i++) {
if (minTree[v][i] != 0 && !visit[i]) {
int tmp = crew, s0 = s, e0 = e;
if (minTree[v][i] > crew) {
crew = minTree[v][i];
s = v;
e = i;
}
dfs(i, b, visit, crew, s, e, ans);
//往这个点走已经走完,所以要继续往别的点走,数据恢复到初始状态,准备走下一次(回溯想法)
crew = tmp;
s = s0;
e = e0;
}
}
}
void function_two() {
int a = 0, b = 0, newe = 0;
cin >> a >> b >> newe;
bool visit[1000];
for (int i = 0; i < n; i++) {//n为全局变量,记录总点数
visit[i] = false;
}
int ans = 0;//记录a-->b最长的边
dfs(a, b, visit, 0, 1, 1, &ans);
cout << "a-->b之间最长边是从" << s1 << "-->" << e1 << "长度是" << ans << endl;
if (ans <= newe) {
cout << "输入的新边大于a-->b的最长边,所以原最小生成树不变" << endl;
}
else {
cout << "输入的新边小于于a-->b的最长边,所以原最小生成树改变" << endl;
minTree[s1][e1] = 0;
minTree[e1][s1] = 0;//最长边删除
minTree[a][b] = newe;
minTree[b][a] = newe;//把新的边加进来
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
int main()
{
cin >> n >> m;
edge.resize(m);//共m条边
for (int i = 0; i < m; i++) {
cin >> edge[i].x >> edge[i].y >> edge[i].dis;
}
sort(edge.begin(), edge.end());//按照边长,从小到大排序
cout << "开始构造最小(大)生成树" << endl;
function_one();
cout << "开始加入一条新的边" << endl;
function_two();
return 0;
}
例子



3、次小生成树
思路:在上一个功能基础上进一步扩充
1、枚举所有未加入的边,动态维护哪一条边加入之后,新的生成树权值最小,就是答案
2、在原图之上加入一条新的边(新的边一定加进来),必定会产生环路,必须要删去原图中一条边,因为求得是第二小生成树,删去原图之中在这两个目标点之间最长的边,这样新的边对权值的增量最小,所以,找最长边函数和"图中加入新边"那个递归函数一致
3、新的生成树权值=原来的最小值-找到的最长边长+欲加入的边的长度
代码
核心代码
int s1 = 0, e1 = 0;//全局变量带出最大值对应边的端点(起点、终点)
void dfs(int v, int b, bool visit[], int crew, int s, int e, int* ans) {//参数:当前点,目标点,辅助遍历数组,辅助记录当前最大值,辅助记录最大值边端点,用于带出最大值
visit[v] = true;
if (v == b) {//因为最小生成树没有环路,所以只可能是单一路径到这里,所以到这里就截止即可,看最大值
*(ans) = crew;//crew就是在a-->b遍历途中,不断访问可以访问的点,在所有边中找到最大值,给他带出去
s1 = s;//带出对应边端点
e1 = e;
return;
}
for (int i = 1; i <= n; i++) {
if (minTree[v][i] != 0 && !visit[i]) {//枚举所有可到达的,并且没访问的点
int tmp = crew, s0 = s, e0 = e;//记录本函数原始的数值
//之后过程:对于当前要走的点,看看能否更新最大值,再dfs,再恢复,为下一次做准备
if (minTree[v][i] > crew) {//发现一条边权值更大
crew = minTree[v][i];//更新
s = v;
e = i;
}
dfs(i, b, visit, crew, s, e, ans);
//往这个点走已经走完,所以要继续往别的点走,数据恢复到初始状态,准备走下一次(回溯想法)
crew = tmp;
s = s0;
e = e0;
}
}
}
//生成次小生成树
void function_three() {
int sec_min = 9999;//新的权值,以下三行都是动态维护
int s2 = 0, e2 = 0, dis2 = 0;//新加入的边的 起点终点
int s0 = 0, e0 = 0;//要删除的原最小生成树边
for (int i = 0; i < m; i++) {//枚举边
bool visit[1000] = { false };//辅助数组
if (minTree[edge[i].x][edge[i].y] == 0) {//说明这条边没进入最小生成树中,是潜在的可能的构成次小生成树的边
int tmp_maxs = 0;//在edge[i].x和edge[i].y之间的最长边长,被edge[i].dis所替换
dfs(edge[i].x, edge[i].y, visit, 0, 0, 0, &tmp_maxs);
if (min_dis - tmp_maxs + edge[i].dis < sec_min) {//在所有这种生成树中动态找到最小值,即为答案
sec_min = min_dis - tmp_maxs + edge[i].dis;
s0 = s1, e0 = e1;//s1 e1 全局变量带出最大值(tmp_maxs)对应边的端点
s2 = edge[i].x, e2 = edge[i].y, dis2 = edge[i].dis;
}
}
}
cout << "次小生成树的的值是" << sec_min << endl;
minTree[s0][e0] = 0;
minTree[e0][s0] = 0;//删除一条边边
minTree[s2][e2] = dis2;
minTree[e2][s2] = dis2;//把新的边加进来
cout << "次小生成树:" << endl;
for (int i = 1; i <= n; i++) {//打印生成树
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
全部代码
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
//并查集(作为工具类使用)
class unions {
public:
unions(int n) {
this->n = n;
for (int i = 0; i <= n; i++) {
rank[i] = 0;
father[i] = i;
}
}
int find(int item) {
//注意边界处理
if (item > this->n || item <= 0) {
return 0;
}
if (father[item] == item) {
return item;
}
father[item] = find(father[item]);
return father[item];
}
void merge(int x, int y) {
link(find(x), find(y));
}
private:
int father[1000];
int rank[1000];
int n;
void link(int x, int y) {
if (rank[x] > rank[y]) {
father[y] = x;
}
else {
father[x] = y;
}
if (rank[x] == rank[y]) {
rank[y]++;
}
return;
}
};
//存储边的信息
struct Node_min {
int x;
int y;
int dis;
bool operator < (const Node_min & node) {
return dis < node.dis;//最小生成树,从小到大排序
}
};
//最小(大)生成树:kruskal算法
void function_one() {
unions u(n);//一定看好点的编号,并查集从1开始
int mins = 0;
for (int i = 0; i < m; i++) {
Node_min item = edge[i];
if (u.find(item.x) != u.find(item.y)) {//只有新来的边的两个顶点,不在一个集合里,才能合并
u.merge(item.x, item.y);//合并两个点
cout << item.x << "-->" << item.y << endl;
mins += item.dis;
minTree[item.x][item.y] = item.dis;
minTree[item.y][item.x] = item.dis;
}
}
min_dis = mins;
cout << min_dis << endl;//打印最小/最大权值
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
//开始添加边并且调整生成树
int s1 = 0, e1 = 0;//全局变量带出最大值对应边的端点
void dfs(int v, int b, bool visit[], int crew, int s, int e, int* ans) {//参数:当前点,目标点,辅助遍历数组,辅助记录当前最大值,辅助记录最大值边端点,用于带出最大值
visit[v] = true;
if (v == b) {//因为最小生成树没有环路,所以只可能是单一路径到这里,所以到这里就截止即可,看最大值
*(ans) = crew;//crew就是在a-->b遍历途中,不断访问可以访问的点,在所有边中找到最大值,给他带出去
s1 = s;
e1 = e;
return;
}
for (int i = 1; i <= n; i++) {
if (minTree[v][i] != 0 && !visit[i]) {
int tmp = crew, s0 = s, e0 = e;
if (minTree[v][i] > crew) {
crew = minTree[v][i];
s = v;
e = i;
}
dfs(i, b, visit, crew, s, e, ans);
//往这个点走已经走完,所以要继续往别的点走,数据恢复到初始状态,准备走下一次(回溯想法)
crew = tmp;
s = s0;
e = e0;
}
}
}
//生成次小生成树
void function_three() {
int sec_min = 9999;//新的权值,以下三行都是动态维护
int s2 = 0, e2 = 0, dis2 = 0;//新加入的边的 起点终点
int s0 = 0, e0 = 0;//要删除的原最小生成树边
for (int i = 0; i < m; i++) {
bool visit[1000] = { false };//辅助数组
if (minTree[edge[i].x][edge[i].y] == 0) {//说明这条边没进入最小生成树中,是潜在的可能的构成次小生成树的边
int tmp_maxs = 0;//在edge[i].x和edge[i].y之间的最长边长,被edge[i].dis所替换
dfs(edge[i].x, edge[i].y, visit, 0, 0, 0, &tmp_maxs);
if (min_dis - tmp_maxs + edge[i].dis < sec_min) {//在所有这种生成树中动态找到最小值,即为答案
sec_min = min_dis - tmp_maxs + edge[i].dis;
s0 = s1, e0 = e1;//s1 e1 全局变量带出最大值(tmp_maxs)对应边的端点
s2 = edge[i].x, e2 = edge[i].y, dis2 = edge[i].dis;
}
}
}
cout << "次小生成树的的值是" << sec_min << endl;
minTree[s0][e0] = 0;
minTree[e0][s0] = 0;//删除一条边边
minTree[s2][e2] = dis2;
minTree[e2][s2] = dis2;//把新的边加进来
cout << "次小生成树:" << endl;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
int main()
{
cin >> n >> m;
edge.resize(m);//共m条边
for (int i = 0; i < m; i++) {
cin >> edge[i].x >> edge[i].y >> edge[i].dis;
}
sort(edge.begin(), edge.end());//按照边长,从小到大排序
cout << "开始构造最小(大)生成树" << endl;
function_one();
cout << "开始构建次小生成树" << endl;
function_three();
return 0;
}
例子



4、判断最小生成树是否唯一
思路
1、kruskal算法基础之上
2、两条权值一样的边(边的两个端点分属于不同的连通分量才有讨论意义)
3、二者能够连接相同的两个连通块,说明二者谁进入最小生成树都行,就不唯一
4、注意一下

代码
核心代码
void function_four() {
unions u(n);
for (int i = 0; i < m; i++) {
Node_min tmp = edge[i];
if (u.find(tmp.x) == u.find(tmp.y)) {//只有该条边的端点分属于两个不同联通集团时候,才有判断价值
continue;
}
int j = i + 1;
while (j < m) {//从他之后找权值和他一样的边,看端点所属的连通分量是否一致
if (edge[j].dis != tmp.dis) {//权值不一样不考虑
break;
}
//这里一定要找全了,我们找的是两个联通的集团,没有固定对应关系
if ((u.find(tmp.x) == u.find(edge[j].x) && u.find(tmp.y) == u.find(edge[j].y)) || (u.find(tmp.x) == u.find(edge[j].y) && u.find(tmp.y) == u.find(edge[j].x))) {
cout << "最小生成树不唯一";
cout << "边" << tmp.x << "--" << tmp.y << "和边" << edge[j].x << "--" << edge[j].y << "可任意选择" << endl;
return;
}
j++;
}
u.merge(tmp.x, tmp.y);
}
cout << "最小生成树唯一";
return;
}
全部代码
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
//并查集(作为工具类使用)
class unions {
public:
unions(int n) {
this->n = n;
for (int i = 0; i <= n; i++) {
rank[i] = 0;
father[i] = i;
}
}
int find(int item) {
//注意边界处理
if (item > this->n || item <= 0) {
return 0;
}
if (father[item] == item) {
return item;
}
father[item] = find(father[item]);
return father[item];
}
void merge(int x, int y) {
link(find(x), find(y));
}
private:
int father[1000];
int rank[1000];
int n;
void link(int x, int y) {
if (rank[x] > rank[y]) {
father[y] = x;
}
else {
father[x] = y;
}
if (rank[x] == rank[y]) {
rank[y]++;
}
return;
}
};
//存储边的信息
struct Node_min {
int x;
int y;
int dis;
bool operator < (const Node_min & node) {
return dis < node.dis;//最小生成树,从小到大排序
}
};
//最小(大)生成树:kruskal算法
void function_one() {
unions u(n);//一定看好点的编号,并查集从1开始
int mins = 0;
for (int i = 0; i < m; i++) {
Node_min item = edge[i];
if (u.find(item.x) != u.find(item.y)) {//只有新来的边的两个顶点,不在一个集合里,才能合并
u.merge(item.x, item.y);//合并两个点
cout << item.x << "-->" << item.y << endl;
mins += item.dis;
minTree[item.x][item.y] = item.dis;
minTree[item.y][item.x] = item.dis;
}
}
min_dis = mins;
cout << min_dis << endl;//打印最小/最大权值
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << minTree[i][j] << ' ';
}
cout << endl;
}
return;
}
//判断是否唯一
void function_four() {
unions u(n);
for (int i = 0; i < m; i++) {
Node_min tmp = edge[i];
if (u.find(tmp.x) == u.find(tmp.y)) {//只有该条边的端点分属于两个不同联通集团时候,才有判断价值
continue;
}
int j = i + 1;
while (j < m) {
if (edge[j].dis != tmp.dis) {//权值不一样不考虑
break;
}
//这里一定要找全了,我们找的是两个联通的集团,没有固定对应关系
if ((u.find(tmp.x) == u.find(edge[j].x) && u.find(tmp.y) == u.find(edge[j].y)) || (u.find(tmp.x) == u.find(edge[j].y) && u.find(tmp.y) == u.find(edge[j].x))) {
cout << "最小生成树不唯一";
cout << "边" << tmp.x << "--" << tmp.y << "和边" << edge[j].x << "--" << edge[j].y << "可任意选择" << endl;
return;
}
j++;
}
u.merge(tmp.x, tmp.y);
}
cout << "最小生成树唯一";
return;
}
int main()
{
cin >> n >> m;
edge.resize(m);//共m条边
for (int i = 0; i < m; i++) {
cin >> edge[i].x >> edge[i].y >> edge[i].dis;
}
sort(edge.begin(), edge.end());//按照边长,从小到大排序
cout << "开始构造最小(大)生成树" << endl;
function_one();
cout << "开始判断最小生成树是否唯一" << endl;
function_four();
return 0;
}
例子


5、极差(生成树:最长边-最短边)最小生成树


思路
1、极差:生成树中,最长边-最小边,所有生成树中,找这个值的最小值
2、他也是生成树问题,在考研的范围之内,直接使用类似于kruskal算法(从最小的边开始枚举,最后一个加入的边一定是最长的)+控制变量法(控制最短边,从头开始枚举最短边,最后一条边一定最长)
3、需要把边从小到大排序,传统的kruskal算法是构建以dis最小的边为最短边的最小生成树(这句话就是,枚举边的时候,从哪里开始,kruskal算法就是从头开始)
4、但是本算法需要极差最小,只从头开始枚举最短边很明显不够
5、所以从头枚举最短边执行kruskal算法(就是从头开始依次建立最小生成树),建立完成获得极差,直到从某一个点开始建立最小生成树失败,全停止,所有的极差中获取最小值
6、这样也相当于控制了最短边这个变量,使计算过程简化
代码
核心代码
void function_five() {
int ans = 99999;//记录最小极差
for (int i = 0; i < m; i++) {//外层循环,枚举最短边(以不同最短边分别进行建立最小生成树)
unions u(n);//本次建立最小生成树所用的并查集
Node_min item = edge[i];
cout << "以" << item.x << "--" << item.y << "为最短边的最小生成树" << endl;
int gap = item.dis;//用来计算极差,item.dis是最短边,相当于控制变量,控制最小值的边,找到最大值的边(最后一个进入最小生成树中的边),算极差
int sets = n;//集合数
int val = 0;//最小生成树权值
for (int j = i; j < m; j++) {
Node_min tmp = edge[j];
if (u.find(tmp.x) != u.find(tmp.y)) {
cout << tmp.x << "--" << tmp.y << ' ';
u.merge(tmp.x, tmp.y);
val += tmp.dis;
sets--;
if (sets == 1) {//集合数为1,说明最后一条最大边进来,生成树建立完毕,如果退出时都不为1,说明建立失败
gap = tmp.dis - gap;//这也是为什么用kruskal算法原因,控制最短边,只要能生成最小生成树 ,最后一条边,一定是最大边,以最快速度计算出极差
break;
}
}
}
if (sets > 1) {//生成树构造失败:未能吧所有的点连接到一起(一个集合里面去)
cout << endl;
cout << "构造失败,停止全部构造" << endl;//只要这个失败了,后面不肯能还有成功的
break;
}
else {
cout << endl;
cout << "该最小生成树权值:" << val << "极差是" << gap << endl;
ans = min(ans, gap);
}
}
cout << "极差最小生成树的极差是" << ans << endl;
return;
}
完整代码
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
//并查集(作为工具类使用)
class unions {
public:
unions(int n) {
this->n = n;
for (int i = 0; i <= n; i++) {
rank[i] = 0;
father[i] = i;
}
}
int find(int item) {
//注意边界处理
if (item > this->n || item <= 0) {
return 0;
}
if (father[item] == item) {
return item;
}
father[item] = find(father[item]);
return father[item];
}
void merge(int x, int y) {
link(find(x), find(y));
}
private:
int father[1000];
int rank[1000];
int n;
void link(int x, int y) {
if (rank[x] > rank[y]) {
father[y] = x;
}
else {
father[x] = y;
}
if (rank[x] == rank[y]) {
rank[y]++;
}
return;
}
};
//存储边的信息
struct Node_min {
int x;
int y;
int dis;
bool operator < (const Node_min & node) {
return dis < node.dis;//最小生成树,从小到大排序
}
};
//开始判定极差最小生成树
void function_five() {
int ans = 99999;//记录最小极差
for (int i = 0; i < m; i++) {//外层循环,枚举最短边(以不同最短边分别进行建立最小生成树)
unions u(n);//本次建立最小生成树所用的并查集
Node_min item = edge[i];
cout << "以" << item.x << "--" << item.y << "为最短边的最小生成树" << endl;
int gap = item.dis;//用来计算极差,item.dis是最短边,相当于控制变量,控制最小值的边,找到最大值的边,算极差
int sets = n;//集合数
int val = 0;//最小生成树权值
for (int j = i; j < m; j++) {
Node_min tmp = edge[j];
if (u.find(tmp.x) != u.find(tmp.y)) {
cout << tmp.x << "--" << tmp.y << ' ';
u.merge(tmp.x, tmp.y);
val += tmp.dis;
sets--;
if (sets == 1) {
gap = tmp.dis - gap;//这也是为什么用kruskal算法原因,控制最短边,只要能生成最小生成树 ,最后一条边,一定是最大边,以最快速度计算出极差
break;
}
}
}
if (sets > 1) {//生成树构造失败:未能吧所有的点连接到一起(一个集合里面去)
cout << endl;
cout << "构造失败,停止全部构造" << endl;//只要这个失败了,后面不肯能还有成功的
break;
}
else {
cout << endl;
cout << "该最小生成树权值:" << val << "极差是" << gap << endl;
ans = min(ans, gap);
}
}
cout << "极差最小生成树的极差是" << ans << endl;
return;
}
int main()
{
cin >> n >> m;
edge.resize(m);//共m条边
for (int i = 0; i < m; i++) {
cin >> edge[i].x >> edge[i].y >> edge[i].dis;
}
sort(edge.begin(), edge.end());//按照边长,从小到大排序
cout << "开始构造极差最小的生成树" << endl;
function_five();
return 0;
}
例子



![[python]初步练习脚本](https://img-blog.csdnimg.cn/268fecf5c30540bf82d96b47e0bfc418.png)