接上篇《27、Handler处理器使用及代理和Cookie登录实现》
上一篇我们讲解了urllib中Handler处理器的基本使用,以及实现代理访问和Cookie的登录。本篇我们来讲解HTML文档解析中的核心插件xpath的安装及使用。
一、xpath介绍
XPath是由W3C(World Wide Web Consortium)组织发布的。W3C是一个国际性组织,负责制定Web标准和推动Web技术的发展。XPath最初在1999年发布,并成为XML Path Language的一部分。它由James Clark提出并提交给W3C进行标准化,目的是为XML文档提供一种统一而强大的查询语言。
XPath是一种用于在XML文档中定位和提取数据的查询语言。它可以通过路径表达式来描述XML文档中的节点结构,并根据这些路径表达式来选择特定的节点或节点集合。XPath可用于查找元素、属性、文本和命名空间等信息,以及执行各种节点之间的关系操作。它广泛应用于Web抓取、数据提取、XML解析和XSLT转换等领域。
如下图例子就是通过xpath路径查询语言命中的一个页面上带有提交功能的登录按钮: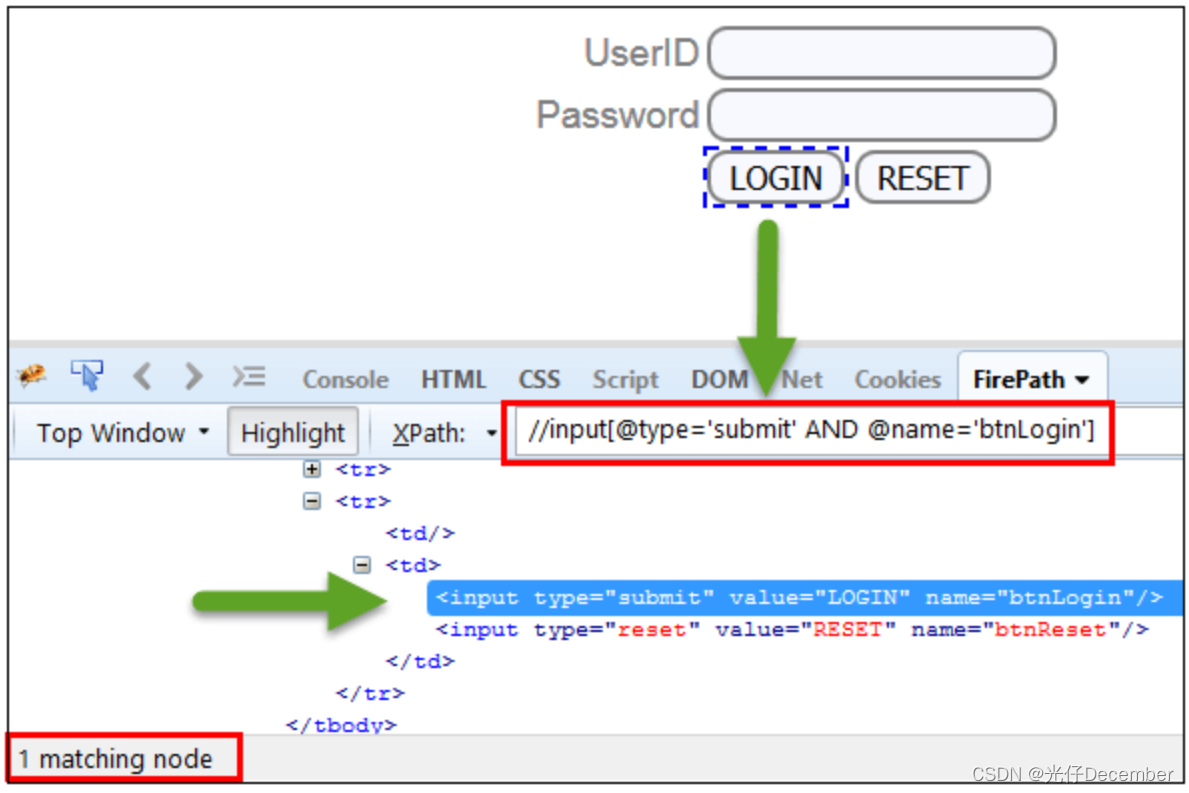
二、XPath在python爬虫中起到的作用
XPath在Python爬虫中起到了重要的作用。通过使用XPath,可以方便地定位和提取网页中的特定数据,从而实现网页内容的抓取和分析。
以下是XPath在Python爬虫中的主要作用:
1、定位元素:XPath可以通过路径表达式准确定位HTML或XML文档中的元素。这样,爬虫就可以精确地找到所需的数据所在的位置。
2、提取数据:XPath可以根据指定的路径表达式提取特定节点的文本、属性或标签等信息。通过使用XPath表达式,可以轻松地获取所需的数据,如标题、价格、日期等。
3、遍历结构:XPath可以遍历HTML或XML文档的节点结构,让爬虫能够顺序访问文档中的各个节点,并根据需要进行数据提取和处理。
4、过滤数据:XPath支持谓词(Predicate)语法,可以对节点进行条件过滤。这使得爬虫可以根据特定规则筛选所需的数据,例如只提取某个类别的商品或符合某个条件的新闻文章。
5、动态页面处理:许多网页采用动态加载的方式呈现数据,这对传统的基于正则表达式的爬虫来说可能较为困难。而XPath可以应对这种情况,因为它能够在解析前或解析后对文档进行动态的查询和处理。
综上所述,XPath在Python爬虫中充当了一个强大的工具,使得开发者可以更加灵活、准确地抓取和提取网页数据。它简化了数据提取过程,并提供了便捷的方式来处理各种复杂的网页结构和内容。
三、XPath相关匹配规则语法
XPath利用路径表达式来选择XML中的节点,从而实现对元素的定位。现在我们将先介绍一些与XPath相关的语法规则。
这里举一个HTML的例子,在下面语法讲解中,以该例子作为讲解语法的使用示例。
<?xml version="1.0" encoding="ISO-8859-1"?>
<studentList>
<student>
<name lang="eng">Jack</title>
<age>15</price>
</student>
<student>
<name lang="eng">Tom</title>
<age>20</price>
</student>
</studentList>1、选取节点
XPath使用路径表达式在XML文档中选取节点。节点是通过沿着路径或者step来选取的。
下面列出了最有用的路径表达式:
【实例】
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
2、谓语(Predicates)
谓词用于过滤节点,只选择满足特定条件的节点。谓词通过方括号[]表示,并可以包含一系列条件表达式。
[@attribute='value']:选择具有特定属性值的节点。
[condition]:根据满足特定条件的节点来选择。【实例】
在下面的表格中,列出了带有谓语的一些路径表达式,以及表达式的结果:
3、选取未知节点
XPath通配符可用来选取未知的XML元素。
【实例】
在下面的表格中,列出了一些路径表达式,以及这些表达式的结果:
4、选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
【实例】
在下面的表格中,列出了一些路径表达式,以及这些表达式的结果: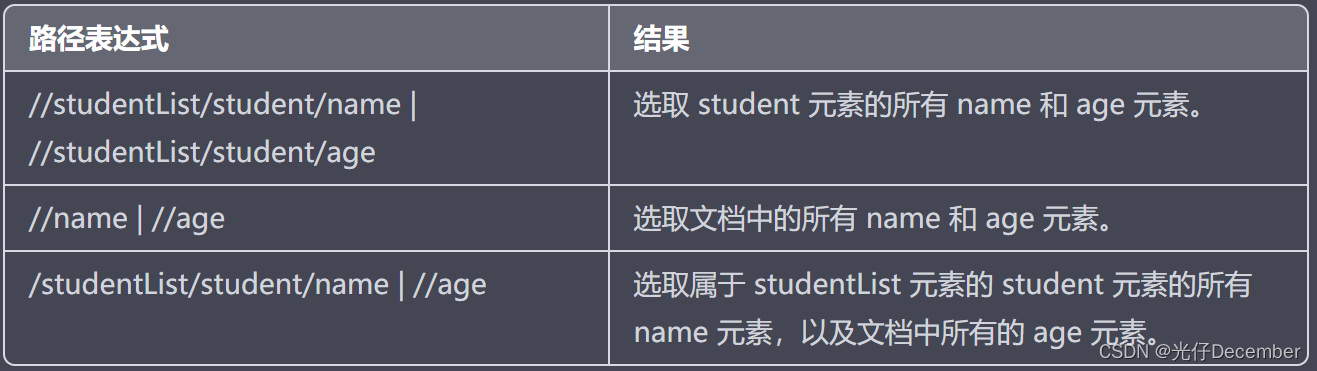
5、Axes(轴)
轴可定义相对于当前节点的节点集。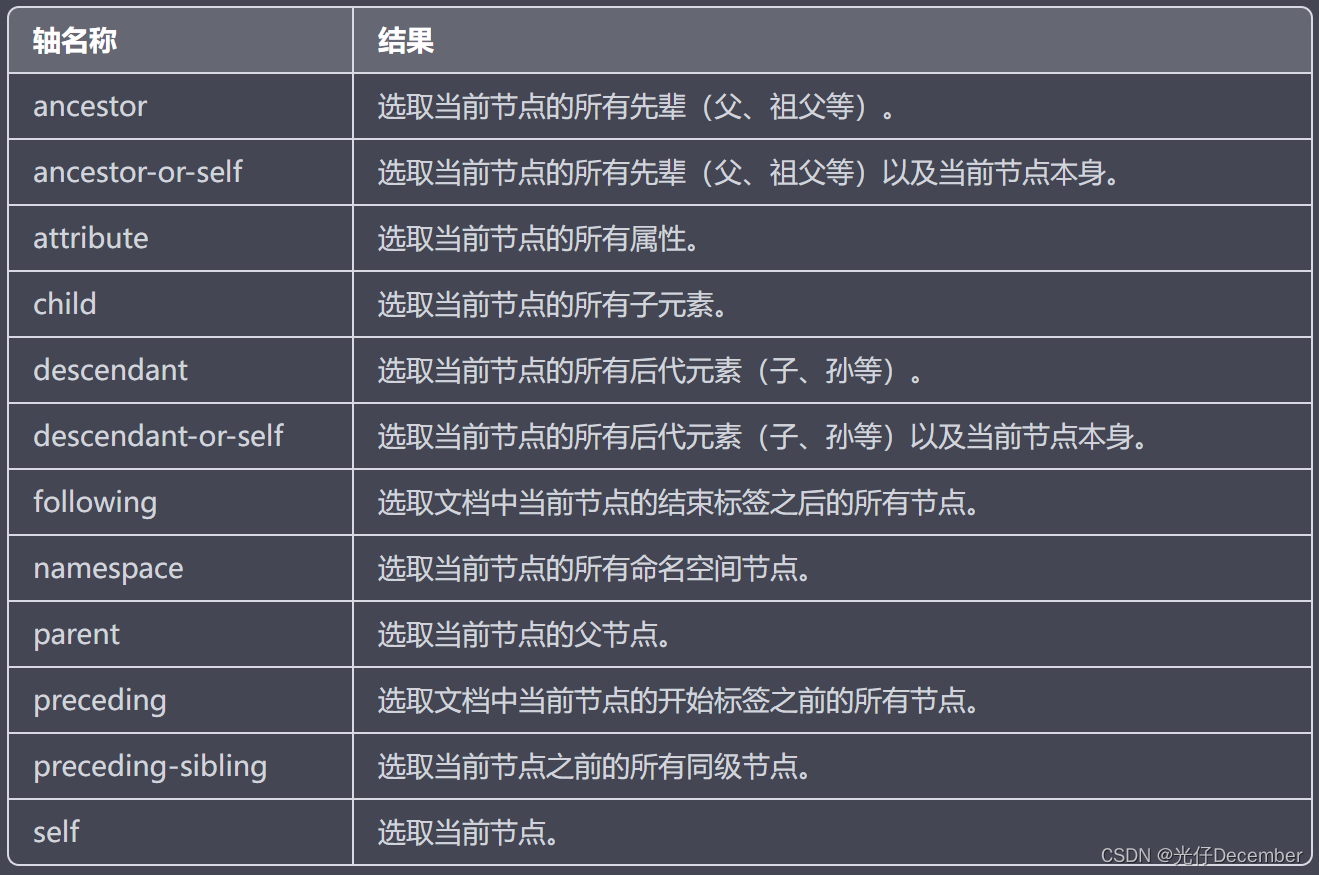
我们可以配合前面的路径(step),来获取XML文档中的复杂关系信息,语法为:
轴名称::节点测试[谓语]【实例】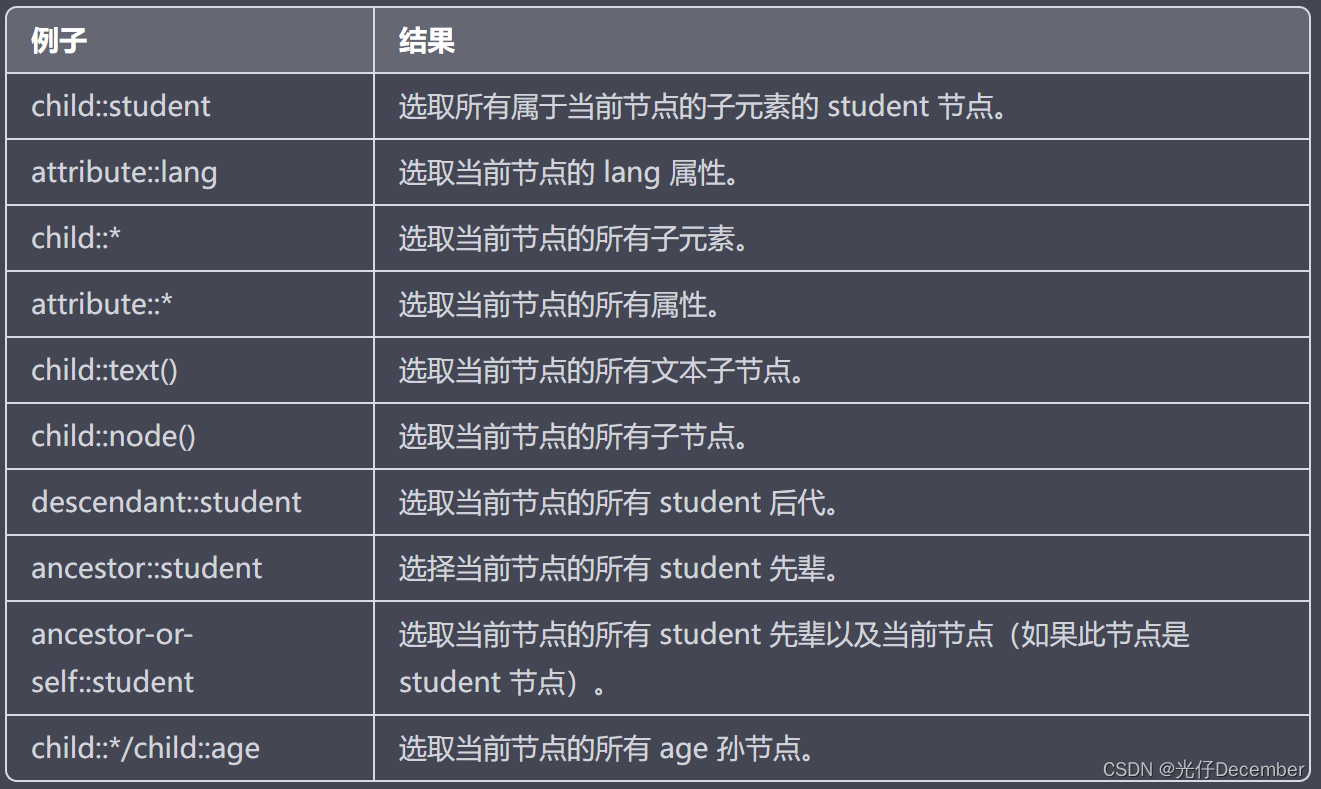
6、运算符
下面列出了可用在XPath表达式中的运算符: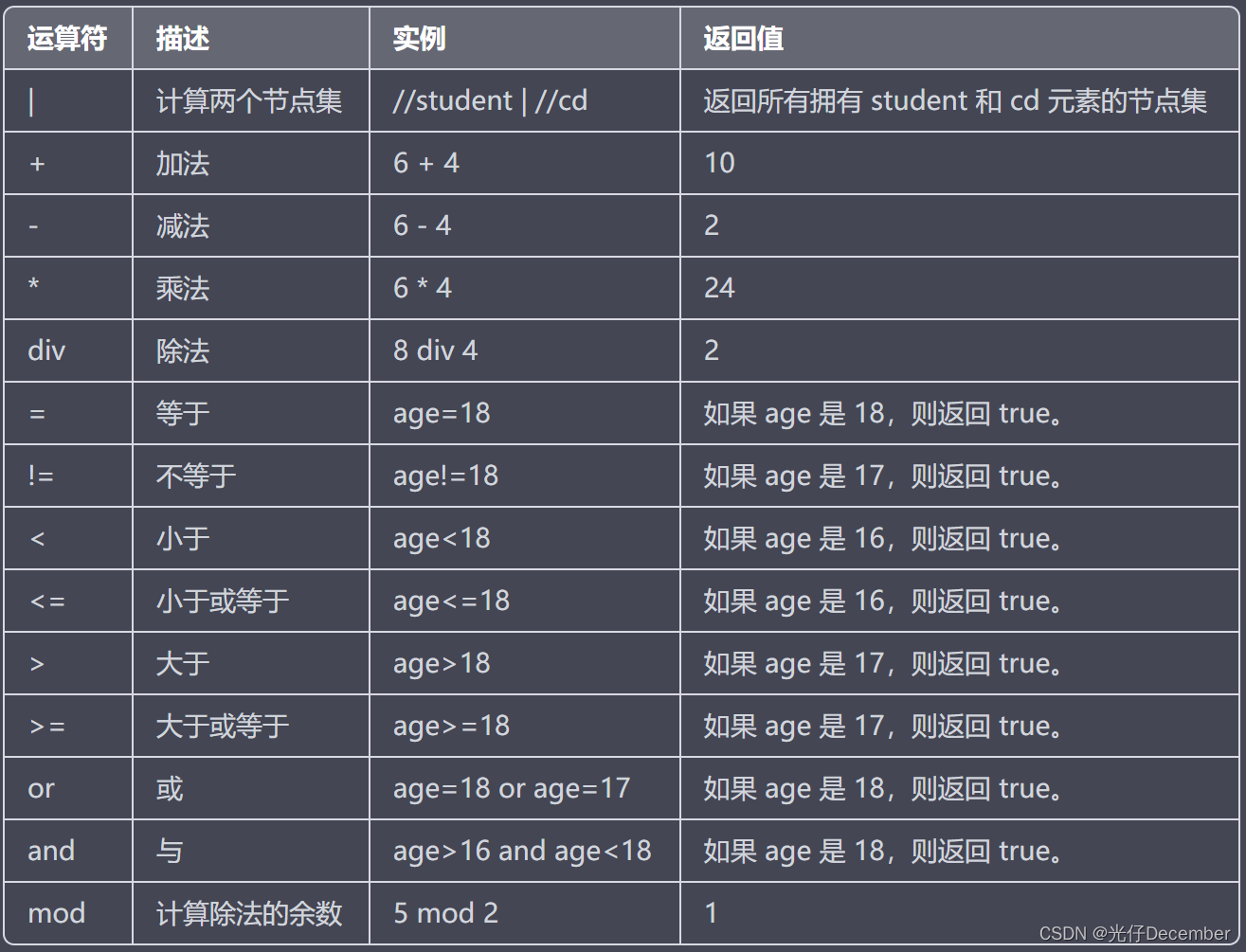
7、函数
xpath支持一些关于数值、字符串、逻辑、时间等操作的函数,功能十分丰富,由于函数类型太多,这里不进行一一赘述,详见w3school对xpath的函数介绍:
https://www.w3school.com.cn/xpath/xpath_functions.asp
这里列举一下经常用到的xpath的字符串函数: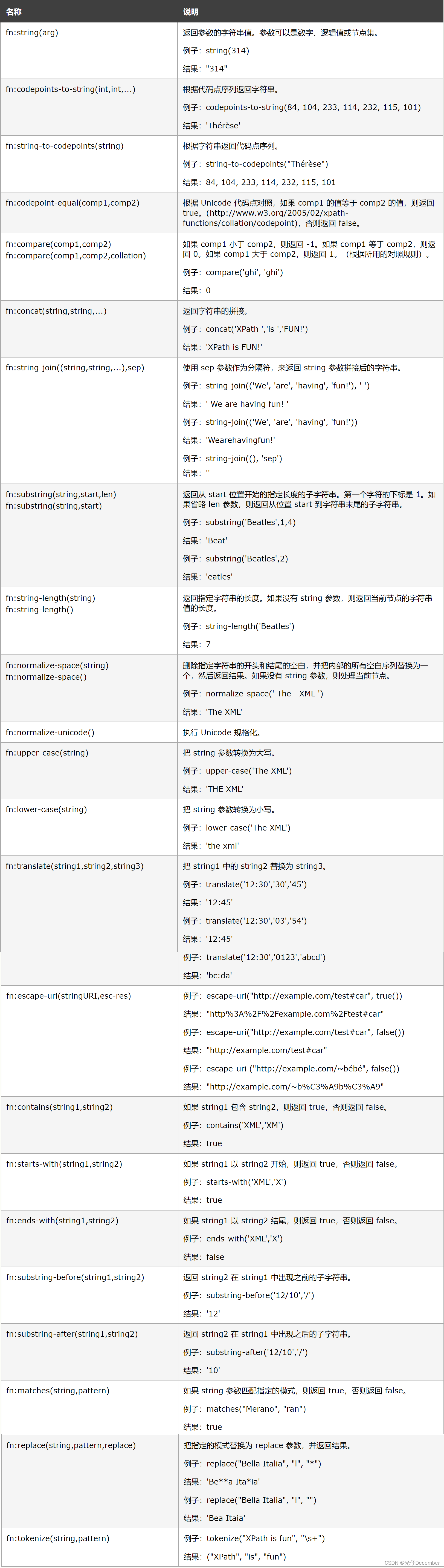
下面我们在浏览器中装好xpath插件就可以试验这些语法了。
四、浏览器安装xpath插件
1、xpath浏览器插件介绍
一些浏览器提供了支持XPath的插件或扩展,可以在浏览器中使用XPath进行网页内容的选择和操作。这些插件通常提供了一个XPath解析器,可以直接在浏览器的开发者工具或插件界面中执行XPath查询。
以下是一些常用的浏览器插件或扩展,用于支持XPath:
(1)Chrome浏览器:Chrome浏览器可以通过安装XPath Helper插件来支持XPath。XPath Helper提供了一个交互式的XPath查询编辑器,方便用户在网页上执行XPath查询,并显示匹配的结果。
(2)Firefox浏览器:Firefox浏览器可以通过安装Firebug插件或使用Firefox自带的开发者工具(控制台)来支持XPath。在开发者工具的控制台中,可以使用"$x()"函数执行XPath查询,并查看匹配的结果。
(3)Safari浏览器:Safari浏览器本身内置了支持XPath的开发者工具。在开发者工具的控制台中,可以使用"$x()"函数执行XPath查询,并查看匹配的结果。
我们接下来就以安装Chrome谷歌浏览器的XPath Helper插件为示例。
2、Chrome浏览器xpath安装
(1)插件下载网址:https://crxdl.com/,进入之后,搜索XPath Helper: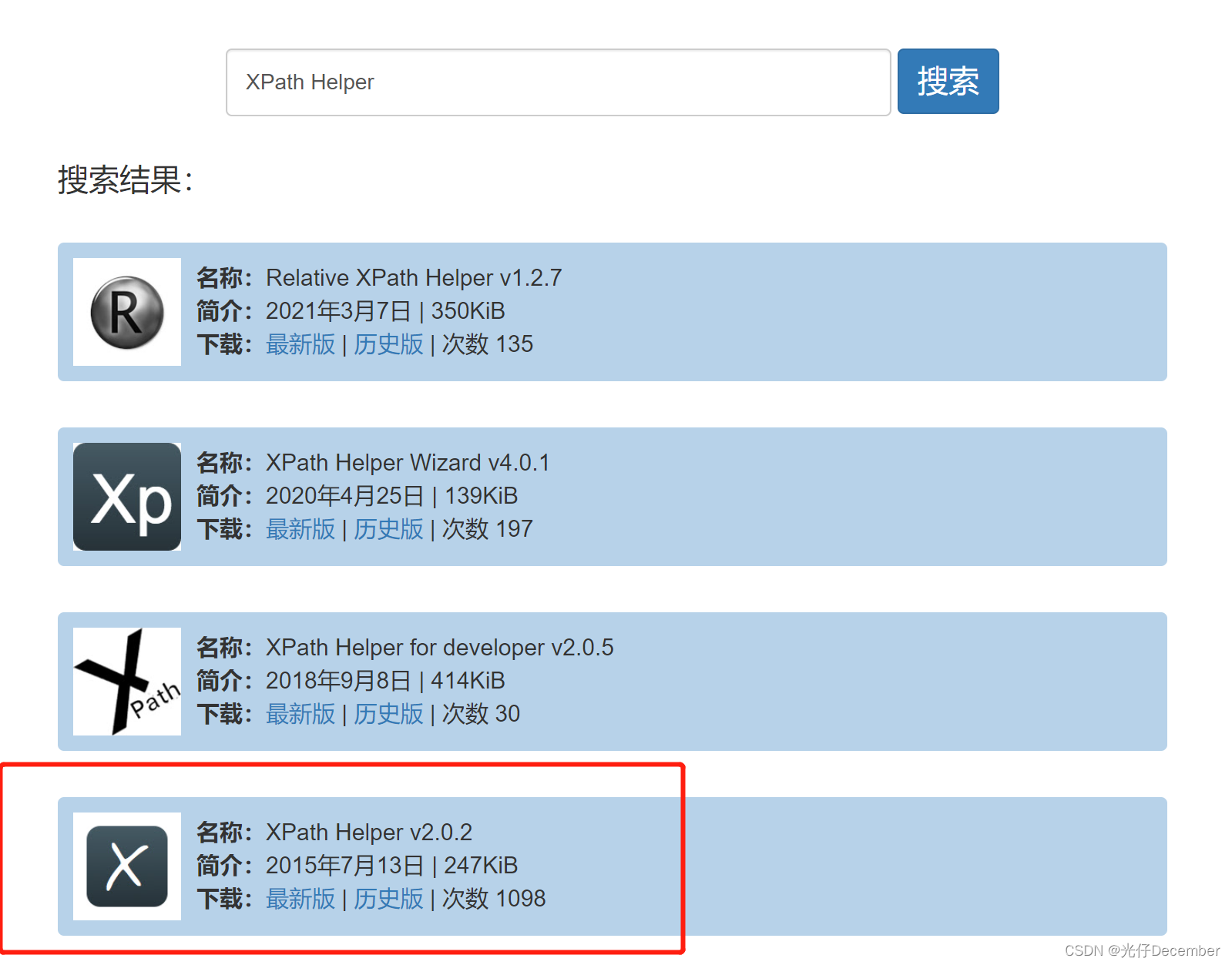
(2)找到自己下载的插件装包,解压.zip文件:
(3)再解压后的文件夹中找到 .CRX类型文件, 修改文件类型为 .rar文件:
(4)在修改文件名称后, 解压该 .rar压缩包, 得到文件夹: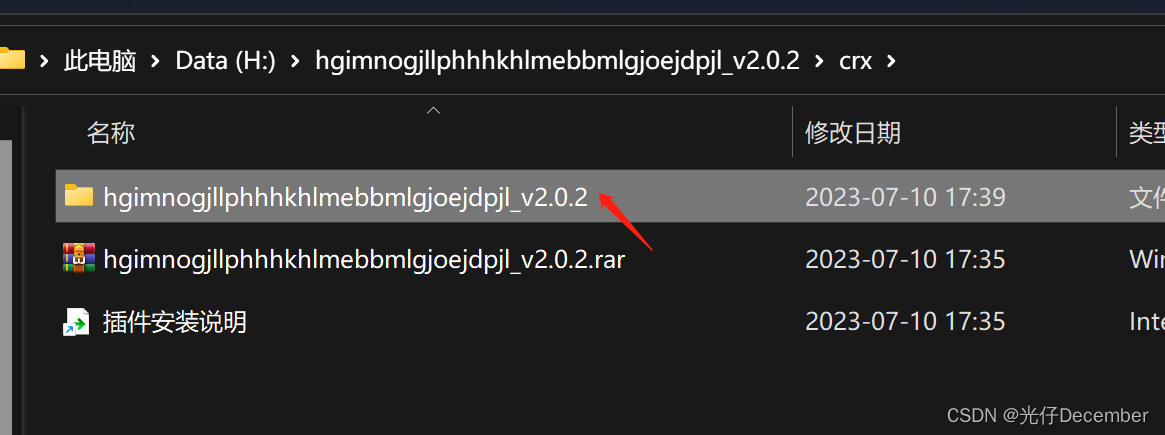
(5)然后打开谷歌浏览器,打开右上角的"拓展程序",打开下面的"管理拓展程序", 进去后打开"开发者模式":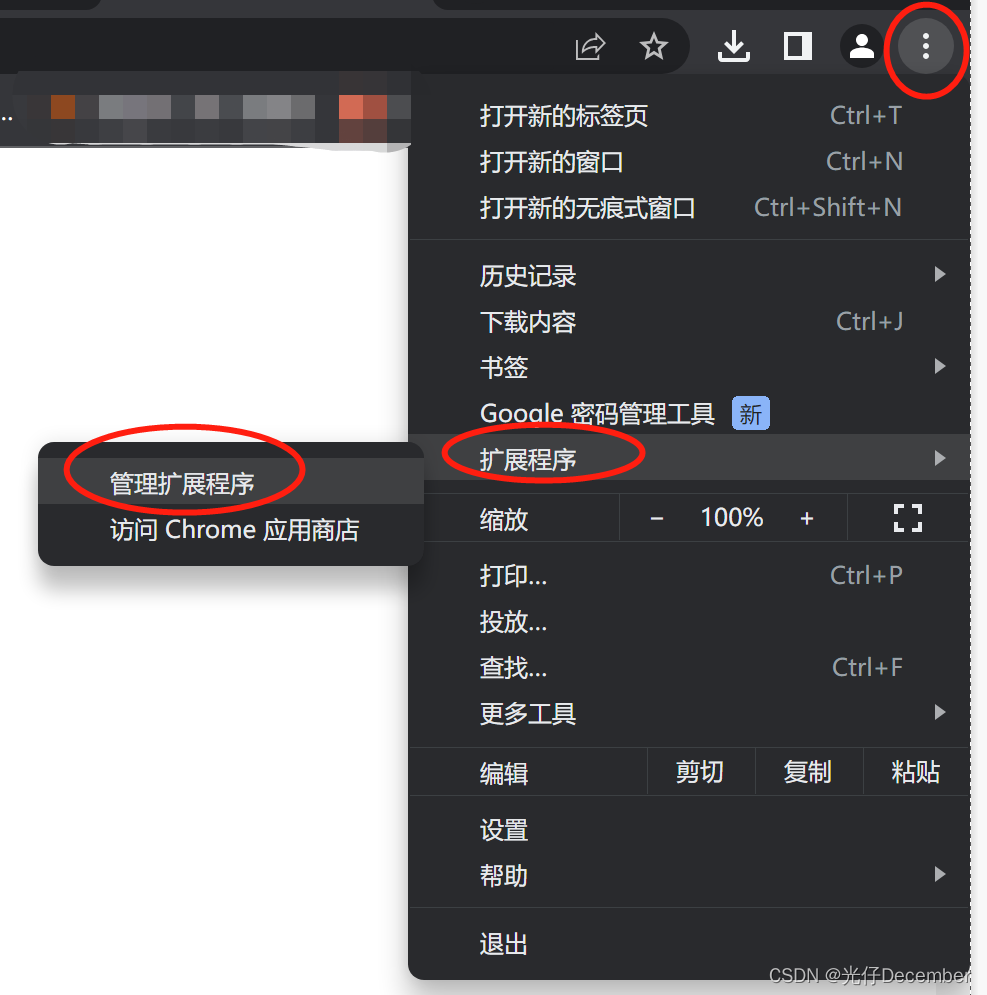
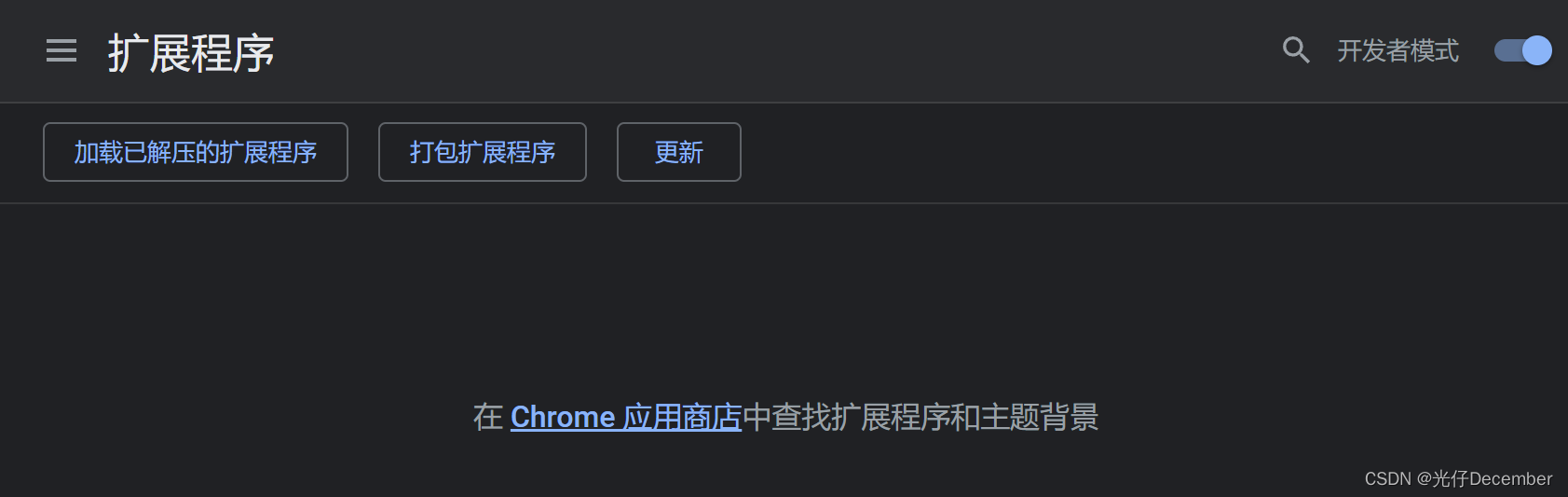
(6)下面把解压后的插件包直接拖进"拓展程序"里面,然后关闭浏览器再打开就可以使用插件: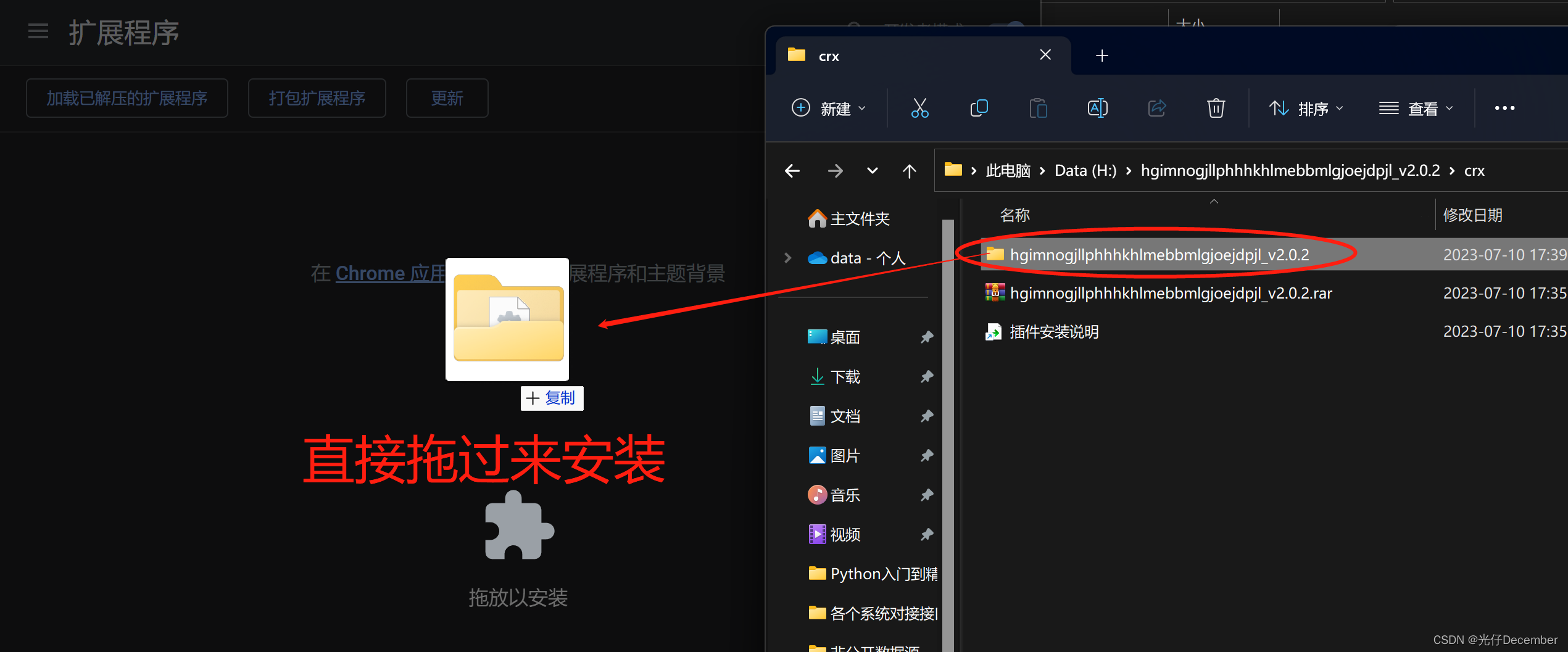
(7)一些常用的插件建议固定(点亮图中的锥子),使用插件的时候直接点击下插件的图标, 插件使用结束推出的时候再点击下插件的图标: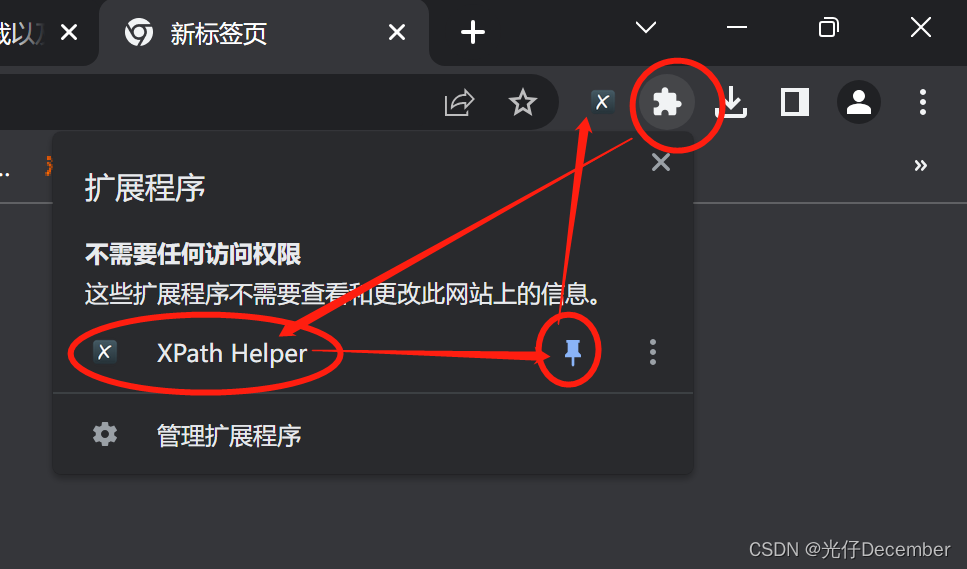
点击插件出现小黑框后则意味着插件安装成功:
如何在浏览器中使用xpath呢?上面的小黑框分为两个区域,左边是QUERY的区域,右边是RESULTS的区域,分别代表查询编辑框和结果展示框。我们可以在右侧编写xptah语法来分析当前网页的HTML文档,右侧RESULTS区域会显示最终的分析结果,我们下面找几个示例测试一下。
【示例一】获取简书的文字列表
语法:
//div[@id="list-container"]/ul[@class="note-list"]/li//a[@class="title"]结果: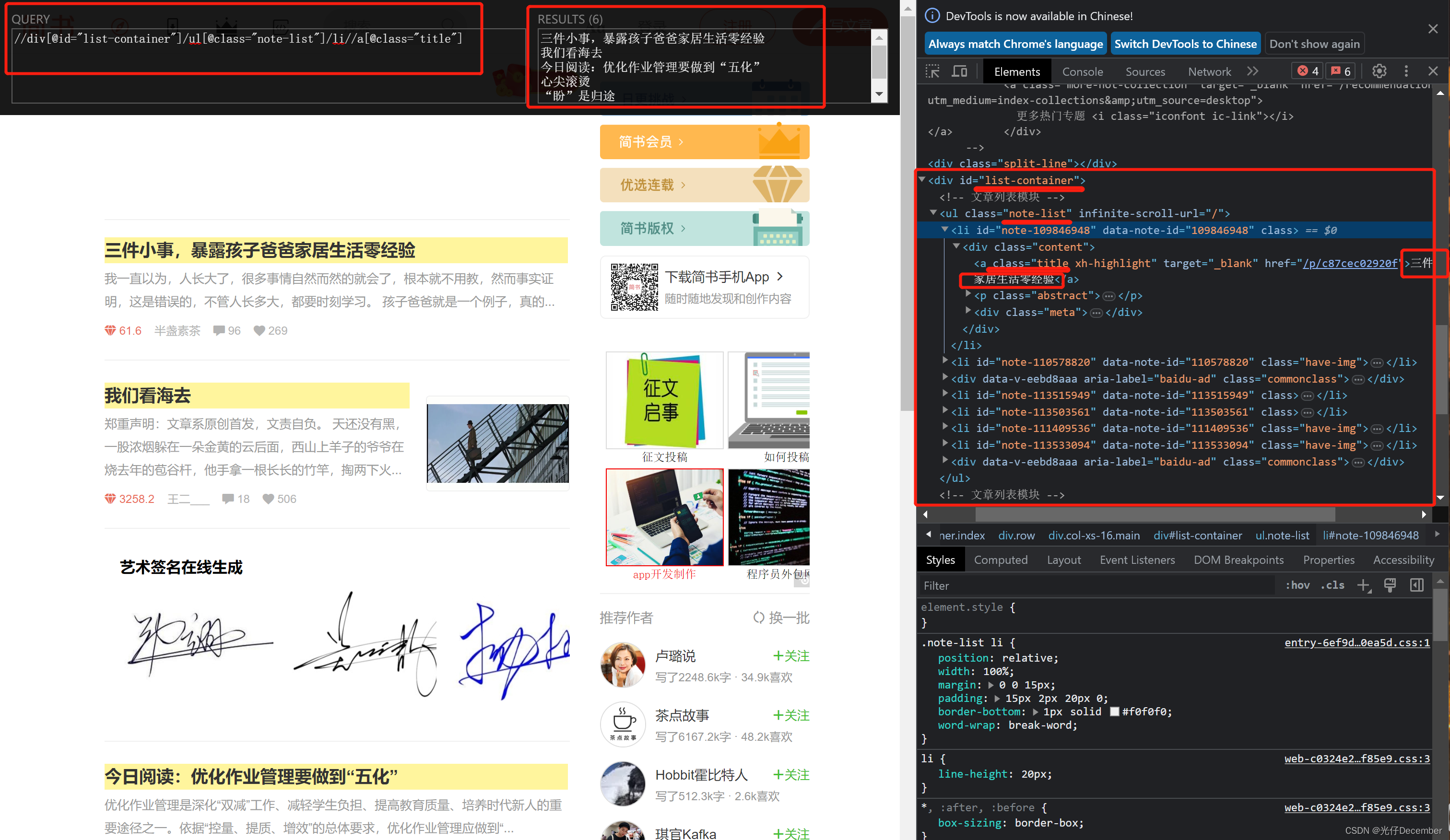
【示例二】找到baidu首页的“百度一下”
语法:
//input[@id="su"]/@value结果: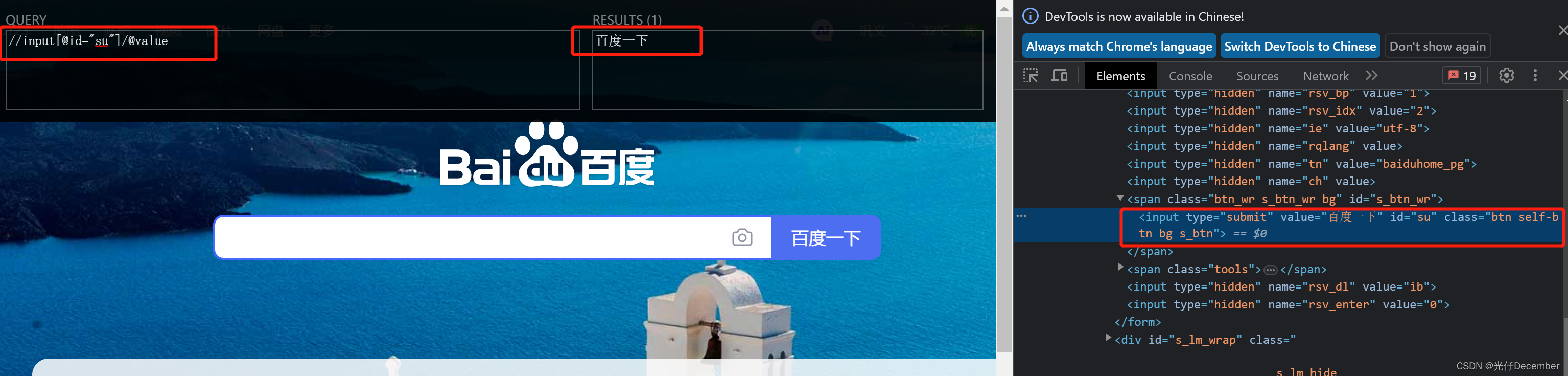
【示例三】获取今日头条置顶的新闻标题
语法:
//div[@class="main-content"]//a[@class="title stick-tag"]结果:

五、python如何使用xpath
1、安装XPath解析库lxml
XPath本身并不需要安装,因为它是一种查询语言,而非具体的软件或工具。XPath通常会和其他编程语言或工具库结合使用,以解析和查询XML文档。以下是一般的步骤,用于在Python环境中使用XPath:
(1)安装Python:如果你还没有安装Python,请从Python官方网站(https://www.python.org)下载并安装Python解释器。
(2)安装XPath解析库:Python有多个XPath解析库可供选择,比如lxml和xml.etree.ElementTree。你可以使用pip命令来安装这些库。例如,使用以下命令安装lxml库:
pip install lxml建议使用豆瓣源,下载比较快:
pip install lxml -i https://pypi.douban.com/simple注:lxml库是基于C语言的libxml2和libxslt库,提供了高效且功能强大的解析、操作和生成XML/HTML的能力。
(3)导入XPath解析库:在Python代码中,通过导入相应的XPath解析库,使其可用于解析和查询XML文档。例如,在使用lxml库时,可以使用以下导入语句:
from lxml import etree(4)使用XPath查询:使用XPath解析库lxml提供的查询方法,结合XPath表达式,对XML文档进行查询。
2、lxml.etree解析网页元素的步骤
使用lxml.etree来解析网页元素的一般步骤如下:
(1)导入模块:首先,需要导入lxml.etree库,并可能导入其他相关的模块,例如requests用于获取网页内容。以下是导入lxml.etree的示例代码:
from lxml import etree(2)获取网页内容:使用适当的方法(如requests库)获取要解析的网页内容。例如,使用requests库发送GET请求并获取网页内容的示例代码如下:
import requests
url = "https://example.com" # 要解析的网页URL
response = requests.get(url) # 发送GET请求
html_content = response.text # 获取网页内容(3)创建解析器对象:使用lxml.etree模块中的etree.HTML()函数创建一个解析器对象,并将网页内容传递给它。这将返回一个可供后续查询和操作的ElementTree对象。以下是创建解析器对象的示例代码:
tree = etree.HTML(html_content)如果需要解析本地的html文件,使用etree.parse方法:
tree = etree.parse('D:/pages/test.html')(4)使用XPath进行查询:使用ElementTree对象的xpath()函数结合XPath表达式来查询特定的网页元素。xpath()函数将返回匹配XPath表达式的元素列表或单个元素。以下是使用XPath查询网页元素的示例代码:
elements = tree.xpath("//div[@class='content']") # 查询所有class为'content'的div元素
for element in elements:
# 处理每个匹配到的元素
print(element.text)在上述步骤中,etree.HTML()函数用于将HTML内容转换为ElementTree对象,而xpath()函数则用于执行XPath查询。其他常用的函数和方法还包括find()、findall()、get()、text属性等,它们可以根据需要用于获取特定元素的子元素、属性值或文本内容。
3、xpath解析实例
下面我们自己编写一个HTML,然后使用urllib+xpath,去解析HTML文档中的不同要求的内容。HTML页面代码如下:
首先我们要获取HTML页面的数据信息(被抓取样例.html):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="b1" class="c1">北京</li>
<li id="b2">上海</li>
<li id="c3">深圳</li>
<li id="cb4">武汉</li>
</ul>
<ul>
<li>大连</li>
<li>锦州</li>
<li>沈阳</li>
</ul>
</body>
</html>然后我们有以下需求,大家可以动脑想一下,然后使用xpath来获取HTML文字中相应需求的数据,这里举了一些示例的分析需求及相应的语法:
# _*_ coding : utf-8 _*_
# @Time : 2023-07-13 15:08
# @Author : 光仔December
# @File : xpath解析样例
# @Project : Python基础
# 导入1xml.etree,需提前安装lxml库
# pip install lxml -i https://pypi.douban.com/simple
from lxml import etree
# 解析本地文件
html_tree = etree.parse('被抓取样例.html')
# 查找ul下面的li
li_list = html_tree.xpath('//ul/li')
print("1、查找ul下面的li:\n", li_list)
print("结果长度:", len(li_list))
# 查找所有有id的属性的li标签
# text()获取标签中的内容
li_list = html_tree.xpath('//ul/li[@id]/text()')
print("2、查找所有有id的属性的li标签:\n", li_list)
# 找到id为b1的li标 注意引号的问题
li_list = html_tree.xpath('//ul/li[@id="b1"]/text()')
print("3、找到id为b1的li标:\n", li_list)
# 查找到id为b1的li标签的class的属性值
li_list = html_tree.xpath('//ul/li[@id="b1"]/@class')
print("4、查找到id为b1的li标签的class的属性值:\n", li_list)
# 查询id中包合b的li标签
li_list = html_tree.xpath('//ul/li[contains(@id,"b")]/text()')
print("5、查询id中包合b的li标签:\n", li_list)
# 查询id的值以b开头的li标签
li_list = html_tree.xpath('//ul/li[starts-with(@id,"b")]/text()')
print("6、查询id的值以b开头的li标签:\n", li_list)
# 查询id为b1且class为c1的li标签
li_list = html_tree.xpath('//ul/li[@id="b1" and @class="c1"]/text()')
print("7、查询id为b1且class为c1的li标签:\n", li_list)
# 查询id为b1或id为b2的li标签
li_list = html_tree.xpath('//ul/li[@id="b1" or @id="b2"]/text()')
print("8、查询id为b1或id为b2的li标签:\n", li_list)结果:
1、查找ul下面的li:
[<Element li at 0x23ccaea35c0>, <Element li at 0x23ccaea3700>, <Element li at 0x23ccaea3a00>, <Element li at 0x23ccaea3640>, <Element li at 0x23ccaea3780>, <Element li at 0x23ccaea3940>, <Element li at 0x23ccaea3900>]
结果长度: 7
2、查找所有有id的属性的li标签:
['北京', '上海', '深圳', '武汉']
3、找到id为b1的li标:
['北京']
4、查找到id为b1的li标签的class的属性值:
['c1']
5、查询id中包合b的li标签:
['北京', '上海', '武汉']
6、查询id的值以b开头的li标签:
['北京', '上海']
7、查询id为b1且class为c1的li标签:
['北京']
8、查询id为b1或id为b2的li标签:
['北京', '上海']请注意,上述步骤仅提供了一个基本的示例,并且可能需要根据具体的情况进行适当的调整和扩展。同时也可以参考lxml官方文档以获取更详细的信息和示例。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://blog.csdn.net/acmman/article/details/131705392