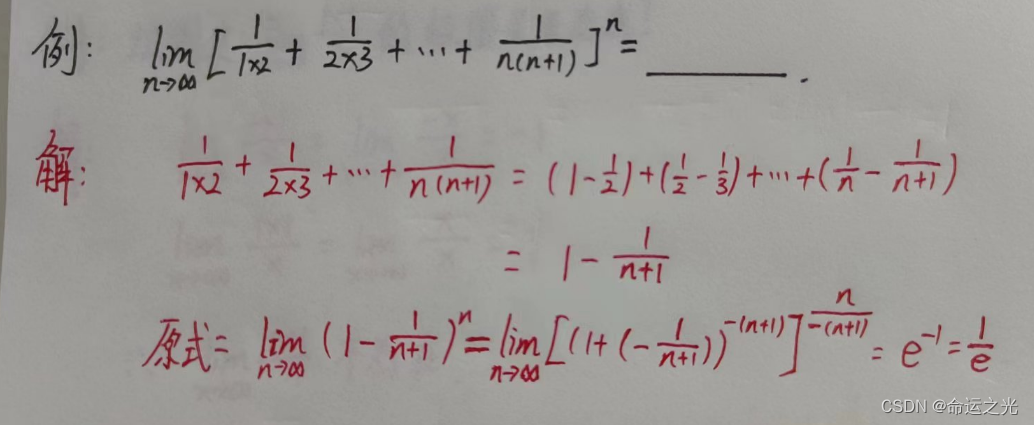导语:
近几年,国产化创新潮流席卷全国,异构数据库迁移成了不少同行、客户争相讨论的话题,大家或争论方案、或求解答疑、或讨论产品,总之问题林林总总,涉及的面还很多,笔者也在近期的几个项目中做了几个异构数据库迁移的项目,项目过后感觉大家最感兴趣的还是异构数据库迁移有哪些注意事项,所以闲暇期间把自己做的一些项目中遇到的问题总结下来,供大家参考借鉴。
一、字符集转换问题
目前做字符集转换的工具不少,有操作系统自带的,也有各种脚本语言、高级语言自带的函数库,然而在进行跨字符集转换过程中其实有很多陷阱。通常,常用的字符集转换多数是GBK、GB2312、CP936、UTF8、UNICODE、LATIN等常用字符集之间的互相转换。因此,遇到不同字符集迁移的项目,建议还是要以实际项目情况出发合理选择方案。以下是笔者在处理不同字符集转换的几点建议:
■中文字段值域范围问题
中文不同的字符集按其编码规范占用的字节数并不一致,如GBK字符集下中文一个汉字占2字节,而UTF8字符集为3字节(少数占用4个字节)。此种情况下需要在模型设计过程中做好值域范围的调整,防止数据加工时报错。
■中文乱码问题
中文乱码是大家经常碰到的问题,多数是因为不同字符集覆盖范围不同,不同字符集在做转换时,因源和目标映射不对称,转码程序通常采用舍去不能转换的字符,或将其转换为预先指定的字符,此种情况下导致转换后的部分结果是乱码。以下为常用字符集范围及编码规范:
GB2312字符集
作用:国家简体中文字符集,兼容ASCII
位数:使用2个字节表示,能表示7445个符号,包括6763个汉字,涵盖所有常用汉字
范围:高字节从A1到F7, 低字节从A1到FE
BIG5字符集
作用:统一繁体字编码
位数:使用2个字节表示,总计13053个汉字
范围:高字节从A1到F9,低字节从40到7E,A1到FE
GBK字符集
作用:它是GB2312的扩展,加入对繁体字的支持,兼容GB2312
位数:使用2个字节表示,可表示21886个字符
范围:高字节从81到FE,低字节从40到FE (7F 除外)
GB18030字符集
作用:它解决了中文、日文、朝鲜语等的编码,兼容GBK
位数:它采用变字节表示(1 ASCII,2,4字节)。可表示27484个文字
范围:1字节从00到7F; 2字节高字节从81到FE,低字节从40到7E和80到FE;4字节第一三字节从81到FE,第二四字节从30到39
UNICODE字符集
作用:为世界650种语言进行统一编码,兼容ISO-8859-1
位数:UNICODE字符集有多个编码方式,分别是UTF-8,UTF-16和UTF-32
范围:UNICODE中文字符范围是[U+4E00-U+9FBF],常用范围是[U+4E00-U+9FA5]
▲上下滑动查看
■ 转码处理策略
转码处理策略主要是指转码过程中对于异常字符的处理方式,通常在指定完目标字符集后对于异常字符的处理方式有3种:
🔹报错退出
🔹不报错,将不识别的舍去(对内容有影响)
🔹不报错,将不识别的指定为特殊字符
通常会将不识别的内容转换为?、空格、“ ”或其他指定字符。
具体采用哪种处理策略笔者建议按实际情况出发合理即可。
■ 字符集选择问题
字符集选择问题主要是指知道源字符集后,向目标字符集转换时,源字符集该如何选择。假设我们已经知道原来用的是GBK,那么具体做转换时我们应该采用BIG5、CP936、GB2312、GB18030哪种进行转换比较合适呢?此时建议选择转码处理策略中可以最大力度保留源内容的方式为主。
二、隐式转换问题
异构数据库迁移、数据类型转换工作主要涉及“精度”“效率”以及“兼容性”等方面。部分数据同步软件确实具备自动转换的功能,但是仅对于管理规范的数据库适用,对于不规范的数据库在进行转换时则需要耗费较大精力,下面举几个典型的例子说明这个问题:
■ 以Teradata到GaussDB(DWS)的同步为例
整型的值固然可以通过number类型(不设定精度和小数位)存放到源端DWS数据库中,然而此时会遇到一个问题,DWS中应该用啥字段对应呢?安全起见,为了避免精度丢失,肯定是选择numeric类型,但是选择numeric类型会存在性能损失。这时,选择Bigint等类型似乎更为合适,但这又会牵涉到下游应用是否报错的问题。
■ 再以Teradata到DWS的日常加工为例
这里我们要注意中间过程的计算,防止精度溢出,导致数值不一致的情况出现。如在DWS库下目标字段为decimal(38,5)中间加工结果的精度和目标字段精度不一致,通常需要在计算过程种转换精度保证最后数据的一致性。
不处理时精度保留10位
SELECT 1.00000/2.13
1.00000/2.13
-------------------
0.4694835681处理后结果数据符合需求
SELECT cast(1.00000/2.13 as decimal(18,5)
1.00000/2.13
-------------------
0.46948三、同名函数的困惑
日常迁移过程中,客户通常都会要求我们:要原逻辑迁移,不能修改脚本逻辑。但是经常会出现一种情况,明明我们所用的函数都一致,结果却大相径庭。这是为什么呢?其实是因为异构数据库函数同名不同意造成的。下面我们举例说明:
Teradata数据库函数有length函数,GaussDB(DWS)也有length,但是在日常使用过程中,需要特别注意的一点是在TD Latin字符集下length函数中每个汉字是2个字节的长度,而在DWS UTF8字符集下length函数中每个汉字是1 个字节的长度。
源端:TD(Latin)
SELECT length(‘中国’);
length
----------------------------------------
4接下来看GaussDB(DWS) ‘UTF8’字符集
SELECT length(‘中国’);
length
----------------------------------------
2因此,在异构数据库日常开发过程中,一定要擦亮眼睛,即便是同名函数也要仔细查看手册。
四、特殊字符问题
对于数据库异构同步而言,一些特殊的字符诸如:单引号、双引号、换行、斜杠、反斜杠等等也是一个困扰项,这一点在数据全量同步阶段尤其明显。建议注意以下几点:
🔹避免字段中含有分隔符,分隔符最好用不可见控制符。如:0x1b、0x01、0x03等或双字节或多字节分隔符。
🔹卸载前对于特殊字符做好清洗工作,如回车换行,避免卸载下来的文件有折行现象。
🔹对于转义字符建议采用包围符进行处理。
五、数据库特性差异
不同数据库对于一些特殊的处理,它们的处理方式也是不同的,遇到此类问题需要特别注意。下图为其他数据库迁移GaussDB(DWS)时需要注意的事项。

六、数据同步问题
对迁移项目来说,数据同步是其中非常重要的一个环节,尤其是全量数据的铺底工作。通常大家关注的重点是是否有同步工具,笔者就此问题也深有感触。
通常数据同步有以下3种形式:
■ 同步工具解决
当前流行的同步工具多数是封装JDBC的通用接口采用多进程进行处理,此种场景对于小数据量的表还值得一试,但是当我们的数据量一旦达到TB级,且客户预留的同步窗口比较少时就会令人挠头了。此种方式不仅会消耗数据库资源,而且效率还很慢,同时还要避开业务繁忙期。
■ 离线文件抽取加载模式
也有人建议采用离线卸载文件的方式进行处理,在没有同步工具处理异构数据迁移时,这种方法不失为一种解决方案。但是从源端卸载落地成文件,然后再进行清洗转换,再入库多次的IO也是需要花费不少精力去应对各种问题的,笔者暂且认为这是一种备用方案吧。
■ 端到端批量模式
技术能力可行的情况下建议采用封装源和目标端的批量卸载和加载模式,通过管道方式减少中间落地,进行端到端的数据同步。当然这种方式需要有较高的技术能力进行支撑。
七、一致性校验问题
一致性校验问题是迁移环节实现数据一致性的重要保障,能够避免迁移过程中出现数据不一致的情况。在迁移过程中,我们首先要保证的就是数据的完整性、准确性和一致性。
那么如何才能做到呢?因为一致性校验是个十分复杂的问题,因此需要结合实际业务场景分别设计和校验。在次提出个人的几点建议供大家参考:
■ 完整性校验
建议通过记录数+ERR表监控做到记录不丢。ERR表会对关系型数据库加载中非法格式的数据或不完整的记录进行记录,在日常迁移过程中,我们通过以上监控基本就能保证数据的完整性。
■ 准确性校验
所谓准确性校验主要是验证数据在加工逻辑上是否正确。对于此类校验,建议通过关键汇总字段如KPI字段做汇总比对,以此来保障数据的加工逻辑正确。同时监控重要维度的汇总数据。
■ 一致性校验
一致性校验是保障数据准确性的进一步校验,它不仅要求数值型一致,对于字符型数据内容也要求一致。对于此类问题,常用的解决办法是通过MD5函数或Checksum函数分别对字段进行处理转换为数值然后比对两端。通常这种方式会比较消耗数据库资源,建议视情况而定。同时如果是字符集有差异的话,对于长字符串内容通常校验难度更大(有些情况下,两端长度不一致)。
以上校验逻辑多数为事后校验,建议采用自动化程序比对通知,以此来减少后期二次处理的问题。