记录一下如何使用 InsCode Stable Diffusion 进行 AI 绘图以及使用感受。
一、背景介绍
目前市面上比较权威,并能用于工作中的 AI 绘画软件其实就两款。一个叫 Midjourney(简称 MJ),另一个叫 Stable Diffusion(简称 SD)。MJ 需要付费使用,而 SD 开源免费,但是上手难度和学习成本略大,并且非常吃电脑配置(显卡、内存)。
和 MJ 相比,SD 最大的优势是开源,这意味着 Stable Diffusion 的潜力巨大、发展飞快。由于开源免费属性,SD 已经收获了大量活跃用户,开发者社群已经为此提供了大量免费高质量的外接预训练模型(fine-tune)和插件,并且在持续维护更新。在第三方插件和模型的加持下,SD 拥有比 Midjourney 更加丰富的个性化功能。
Stable Diffusion 简介
Stable Diffusion 是 2022 年发布的深度学习文本到图像生成模型,它主要用于根据文本的描述产生详细图像(即 txt2img 应用场景),尽管它也可以应用于其他任务,如内补绘制(inpainting)、外补绘制(outpainting),以及在提示词(英语)指导下产生图生图的翻译(img2img)。
模型原理

引用一张广为人知的 SD 原理图(源于论文https://arxiv.org/abs/2112.10752),该模型主要可以分为三个部分:
- 变分编码器(Vector Quantised Variational AutoEncoder,VQ-VAE)
- 扩散模型(Diffusion Model, DM),在生成图片中起着最重要的作用
- 条件控制器(Conditioning)
详细原理介绍可参考文章 Stable Diffusion 简介
用一句话总结 SD 的模型原理:图片通过 VAE 转换到低维空间,配合 Conditioning 的 DM 产生新的变量,再通过 VAE 将生成的变量转换为图片。
推荐电脑配置
Stable Diffusion 对电脑配置有一定的要求,比较推荐的配置如下:
操作系统:SD 更加适配于 windows。建议使用 windows10、windows11。
内存:8GB 以上,建议使用 16GB 或以上的内存。在内存比较小的情况下,可能需要调高虚拟内存,以容纳模型文件。
硬盘:40GB 以上的可用硬盘空间,建议准备 60GB 以上空间,最好是固态硬盘。
显卡:最低需要显存 2GB,建议显存不少于 4GB,推荐 8GB 以上。型号方面,因为需要用到 CUDA 加速,所以 N 卡支持良好。A 卡可以用,但速度明显慢于英伟达显卡,当然,如果你的电脑没有显卡也可以用 CPU 花几百倍时间生成。
下面是进行 512x 图片生成时主流显卡速度对比:

Stable Diffusion WebUI
目前有一些基于 Stable Diffusion 封装的 webui 开源项目,可以通过界面交互的方式来使用 Stable-diffusion,自身还可以通过插件等方式获得更多能力,极大的降低了使用门槛,以下是几个比较火的 webui 项目:
- https://github.com/AUTOMATIC1111/stable-diffusion-webui
- https://github.com/Sygil-Dev/sygil-webui
这些项目,和平常软件安装方法有所不同,不是下载安装即可用的软件,需要准备执行环境、编译源码,针对不同操作系统(操作系统依赖)、不同电脑(硬件依赖)还有做些手工调整,这需要使用者拥有一定的程序开发经验。
二、Stable Diffusion 模型在线使用地址
InsCode 的 Stable Diffusion 环境主要用于学习和使用 Stable Diffusion,已经安装了相关软件和组件库,可在线直接启动 Stable Diffusion WebUI 进行创作。还可以一键购买算力,训练大模型,极大的降低了 AI 绘图使用门槛。
Stable Diffusion 模型在线使用地址:https://inscode.csdn.net/@inscode/Stable-Diffusion
进入之后点击运行并使用,会弹出一个购买算力资源的窗口。由于是试用,不涉及到连续生成多张图片等场合,因此算力足够用了,选择 RTX 3080 即可(0.51元/小时),目前活动免费试用。
操作完成之后,会跳转到 InsCode 工作台界面,在算力资源中,已经可以看到刚才选择的机器了。
待它初始化完成,右侧有三个选项,选择 Stabel Diffusion WebUI 进入即可。进入界面如下图:
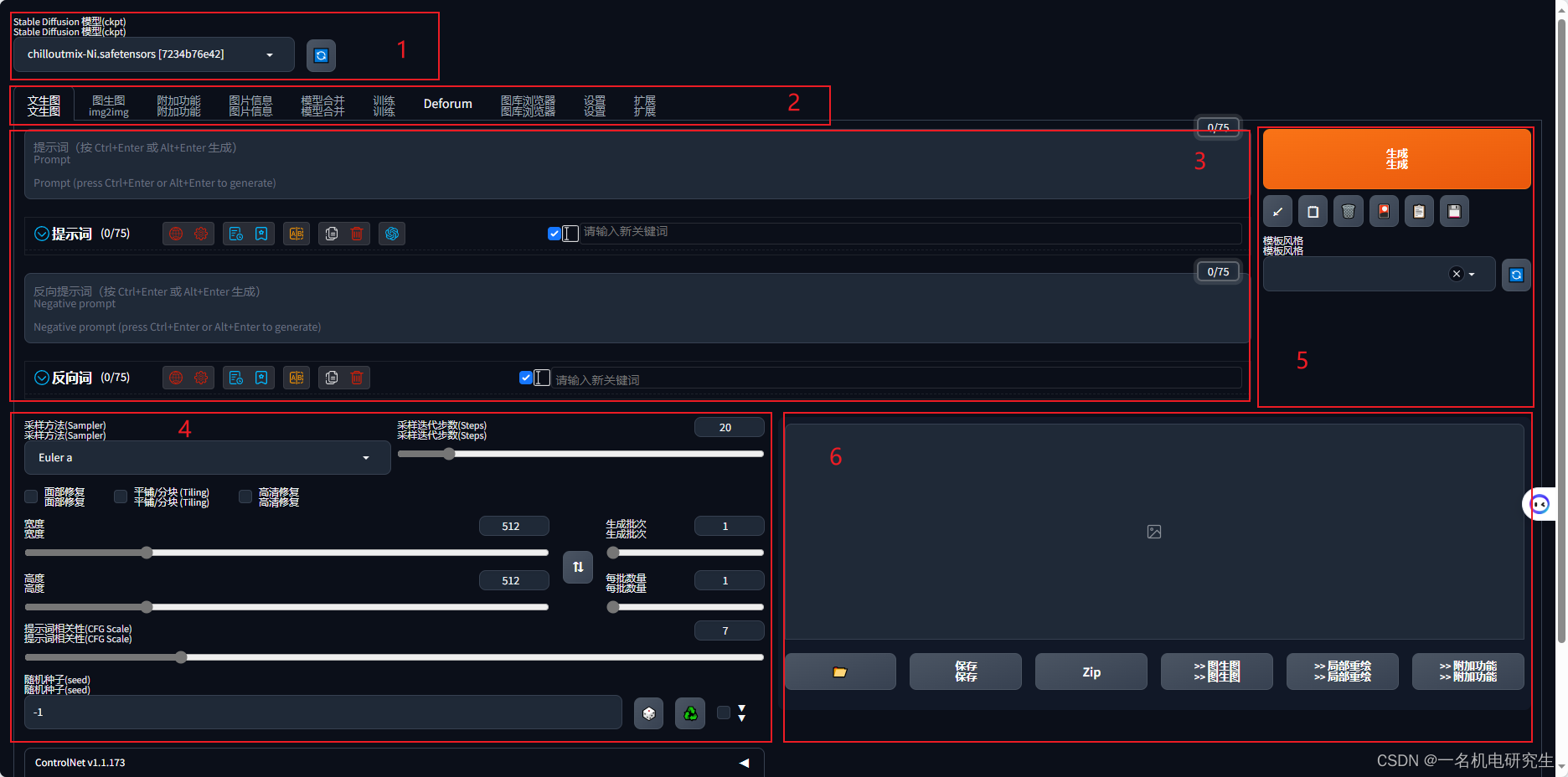
三、Stable Diffusion WebUI 界面介绍与参数解析
-
第一部分:界面最上端
stable diffusion ckpt可以选择模型文件,InsCode 上面提供了几个常用模型,如 chilloutmix、GuoFeng3、Cute_Animals 可供选择。为 InsCode Stable Diffusion 安装某个自己喜欢的模型可查看这里! -
第二部分,便是 stable diffusion webui 项目的主要功能与设置操作
文生图:顾名思义是通过文本的描述来生成图片
图生图:用一张图片生成相似的图片
附加功能:额外的设置
图片信息:若图片是由 AI 生成的图片,当上传一张图片后,这里会提示图片的相关 prompt 关键字与模型参数设置
模型合并:可以合并多个模型,有多个模型的权重来生成图片
训练:模型训练,可以提供自己的图片进行模型的训练,这样别人就可以使用自己训练的模型进行图片的生成
设置:UI 界面设置
扩展:插件扩展,这里可以安装一些开源的插件,例如汉化插件 -
第三部分:是正(负)面提示词输入框,我们需要在此框中输入图片的描述信息,正面提示词是我们希望生成的图片需要的文本,负面提示词是我们不希望生成的图片文本。
开始不知道怎么写提示词,可以先参考优秀的风格模板作为起手式,还可以借助描述语工具和网站,多出图多研究,掌握了出图规律,慢慢就可以自己写提示词啦,写提示词要尽可能写的详细。跑 AI 的过程就像抽卡,抽出一堆卡,选出你审美范畴里觉得好看的。
-
第四部分:界面左下方,便是模型输入的相关参数:
采样方法:里面设置了很多采样算法,各有优缺,具体每个算法的效果,可以自行尝试
采样迭代步数:模型迭代一次的步数
平铺:生成一张可以平铺的图像
面部修复:面部修复功能,可以提供面部细节,但是非写实风格的人物开启面部修复可能导致面部崩坏
高清修复:可以把低分辨率的照片调整到高分辨率
宽度,高度:输出图片的尺寸
提示词相关性CFG:较高的数值将提高生成结果与提示的匹配度
随机种子:seed 一样的情况下,可以生成比较相似的图片,记住保留你喜欢的种子,以便下次再次生成相似的图像
生成批次:每次生成图像的组数。一次运行生成图像的数量为生成批次 * 每批数量
每批数量:同时生成多少个图像 -
第五部分:便是一键生成图片的按键,我们设置完成以上参数的设置后,点击生成按键,便可以自动生成图片了,
生成下面的5个小图标(从左到右依次分别是)
- 复原上次生成图片的提示词(自动记录)
- 清空当前所有提示词
- 打开模型选择界面
- 应用选择的风格模板到当前的提示词
- 存档当前的正(负)面提示词
-
相关的图片会展示在第六部分区域。
四、如何在 InsCode 给 Stable Diffusion 安装模型
常用模型下载网址
目前,模型数量最多的两个网站是 civitai 和 Huggingface。
civitai 又称 C 站,有非常多精彩纷呈的模型,有了这些模型,但是该网站在国内是被屏蔽的。登录需要科学上网。
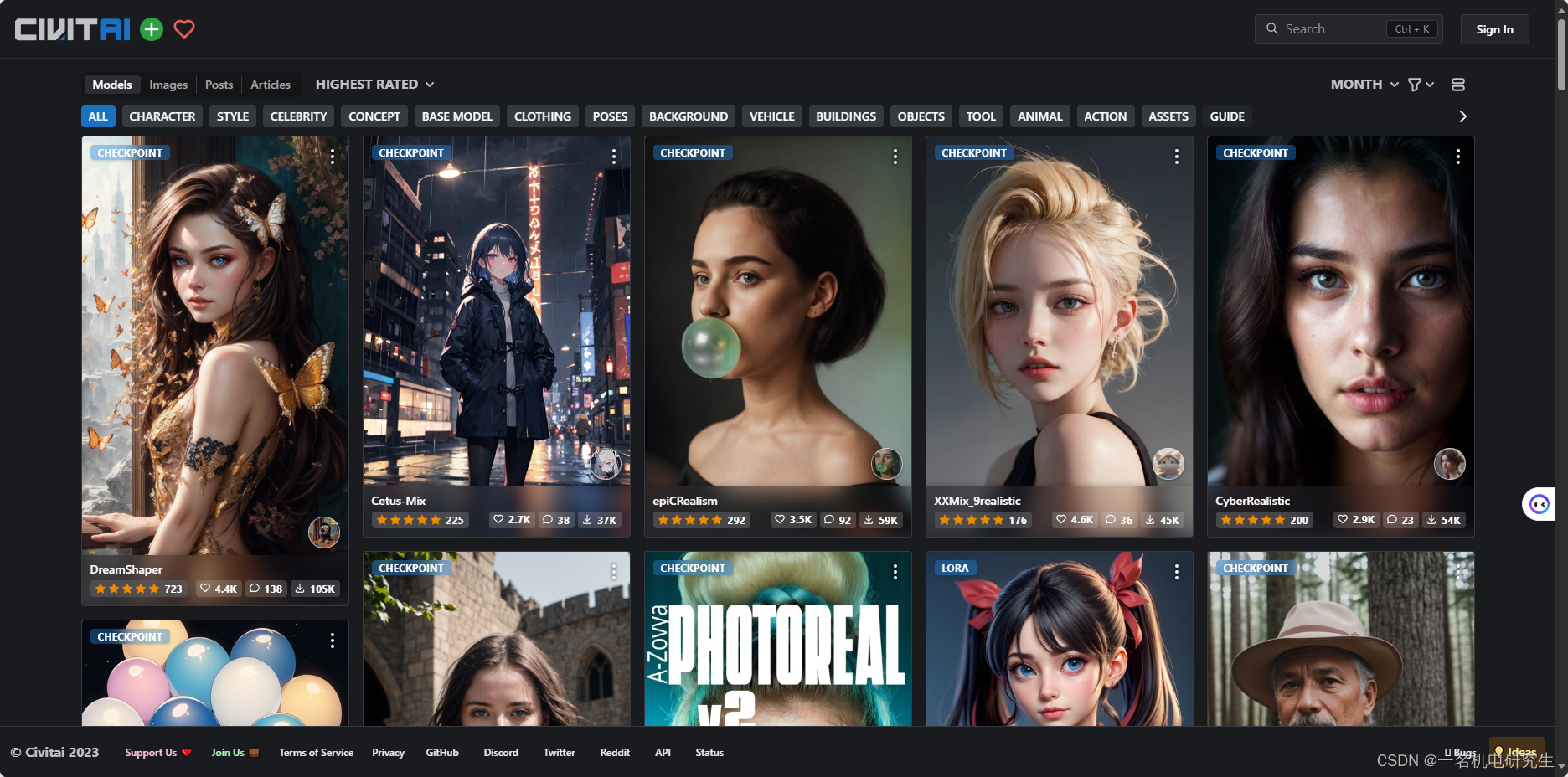
Huggingface 则相对朴实无华一些,对模型的审核也会更加严格一些。但是好处在于不需要科学上网,而且网速很快。
此外,AI 图站可以淘到不少 C 站下架了的模型,也是相当不错的。
常用模型及说明
如果你点开上述网站去下载模型,就会发现有各种不同类型的模型。
CivitAI 上的模型主要分为四类:Checkpoint、LoRA、Textual Inversion、Hypernetwork,分别对应 4 种不同的训练方式。
-
Checkpoint:是 SD 能够绘图的基础模型,因此被称为大模型、底模型或者主模型,WebUI 上就叫它 Stable Diffusion 模型。安装完 SD 软件后,必须搭配主模型才能使用。不同的主模型,其画风和擅长的领域会有侧重。Checkpoint 模型包含生成图像所需的一切,不需要额外的文件。但是它们体积很大,通常为2G-7G。存放在 Stable Diffusion 安装目录的 models 的 Stable-diffusion 目录里。
-
LoRA:一种轻量化的模型微调训练方法,是在原有大模型的基础上,对该模型进行微调,用于输出固定特征的人或事物。特点是对于特定风格特征的出图效果好,训练速度快,模型文件小,一般 10-200 MB,需要搭配大模型使用。存放在 Stable Diffusion 安装目录的 models 的 Lora 目录里
-
Embedding/Textual lnversion:一种使用文本提示来训练模型的方法,可以简单理解为一组打包的提示词,用于生成固定特征的人或事物。特点是对于特定风格特征的出图效果好,模型文件非常小,一般几十 K,但是训练速度较慢,需要搭配大模型使用。存放在 Stable Diffusion 安装目录下的 Embeddings 目录里。
-
Hypernetwork:目前 Hypernetworks 已经不太用,类似 LoRA,但模型效果不如 LoRA,一般几十 K,需要搭配大模型使用。存放在 Stable Diffusion 安装目录的 models 下的 Hypernetworks 目录里。
模型推荐:Checkpoint > LoRA > Textual Inversion > Hypernetwork
通常情况 Checkpoint 模型搭配 LoRA 或 Textual Inversion 模型使用,可以获得更好的出图效果。
补充:还有一类 VAE 模型,简单理解它的作用就是提升图像色彩效果,让画面看上去不会那么灰蒙蒙,此外对图像细节进行细微调整。
几个推荐模型
-
DreamShaper
胜任多种风格(写实、原画、2.5D 等),能生成很棒的人像和风景图的 Checkpoint 模型。

-
Chilloutmix/Chikmix
Chilloutmix 就是大名鼎鼎的亚洲美女模型。市面上你看到的大量的 AI 美女,基本上都是这个模型生成的。当时最火的图应该下面这个系列。

也正是这个模型,让 AI 绘画彻底出圈。
-
Cetus-Mix
这是一个二次元的混合模型,融合了很多二次元的模型,实际使用效果还不错。对提示词的要求不高。

-
Guofeng 系列
这是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有 2.5D 的质感。目前最新的版本是 GuoFeng3.4。

-
blindbox
可生成盲盒风格的 LoRA 模型,使用时主模型建议选 ReV Animated。

如何在 InsCode 给 Stable Diffusion 安装 Lora
-
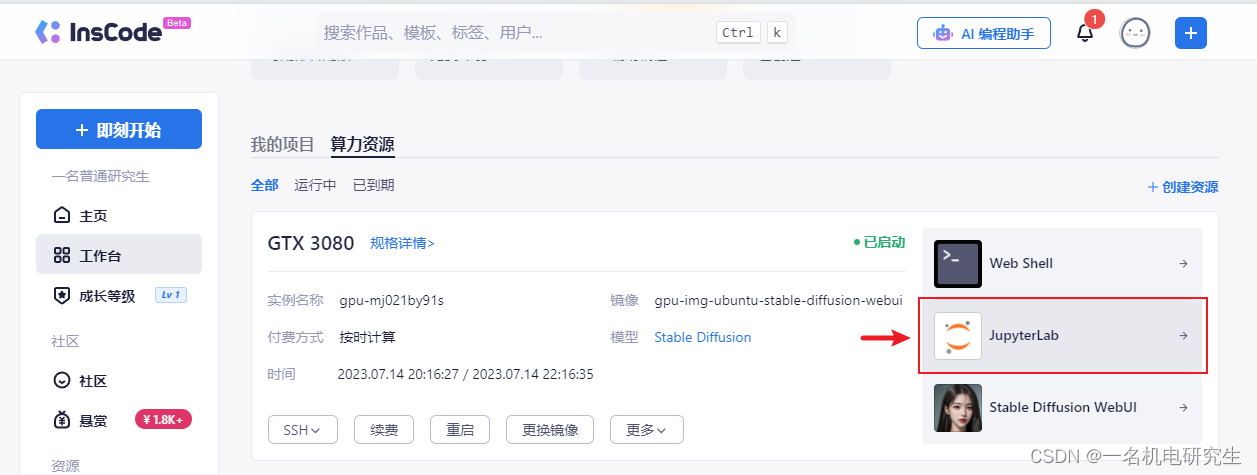
首先,在自己的电脑上下载好需要安装的 Lora 文件,并通过 Jupyter Lab 启动 GPU,如下图所示:
-
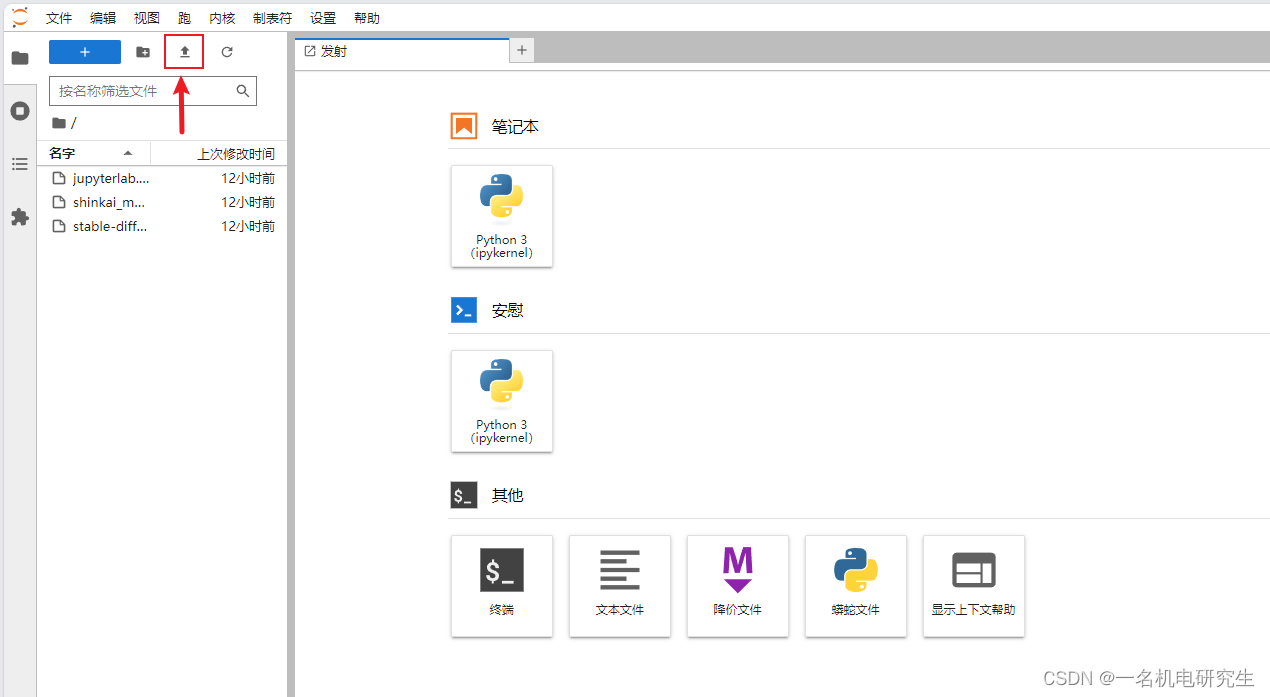
打开 JupyterLab 界面,找到上传入口,将下载好的 Lora 上传到 GPU。
-
打开 Terminal ,将已经上传到 GPU 的 Lora 文件复制到 /release/stable-diffusion-webui/models/Lora 文件夹下。
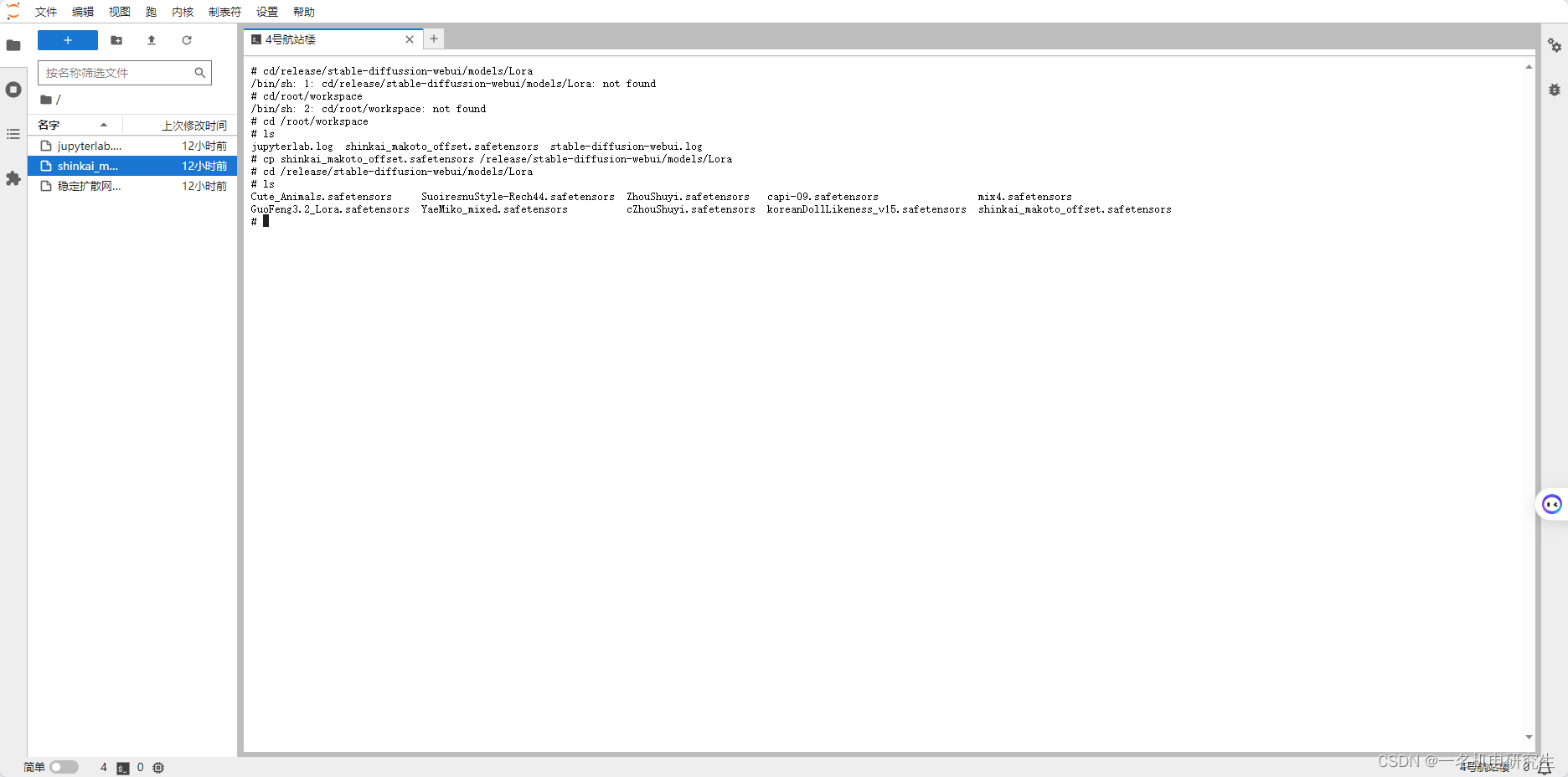
具体命令:# cd /root/workspace # ls jupyterlab.log shinkai_makoto_offset.safetensors stable-diffusion-webui.log # cp shinkai_makoto_offset.safetensors /release/stable-diffusion-webui/models/Lora # cd /release/stable-diffusion-webui/models/Lora # ls Cute_Animals.safetensors SuoiresnuStyle-Rech44.safetensors ZhouShuyi.safetensors capi-09.safetensors mix4.safetensors GuoFeng3.2_Lora.safetensors YaeMiko_mixed.safetensors cZhouShuyi.safetensors koreanDollLikeness_v15.safetensors shinkai_makoto_offset.safetensors注意,这里的 shinkai_makoto_offset.safetensors 是我下载的 Lora 文件
-
当看到下载的 Lora 模型文件已经存在 Lora 文件夹下,重新打开 Stable Diffusion WebUI,点击右侧红圈中的 icon,稍等片刻,可以看到 Lora 界面被打开
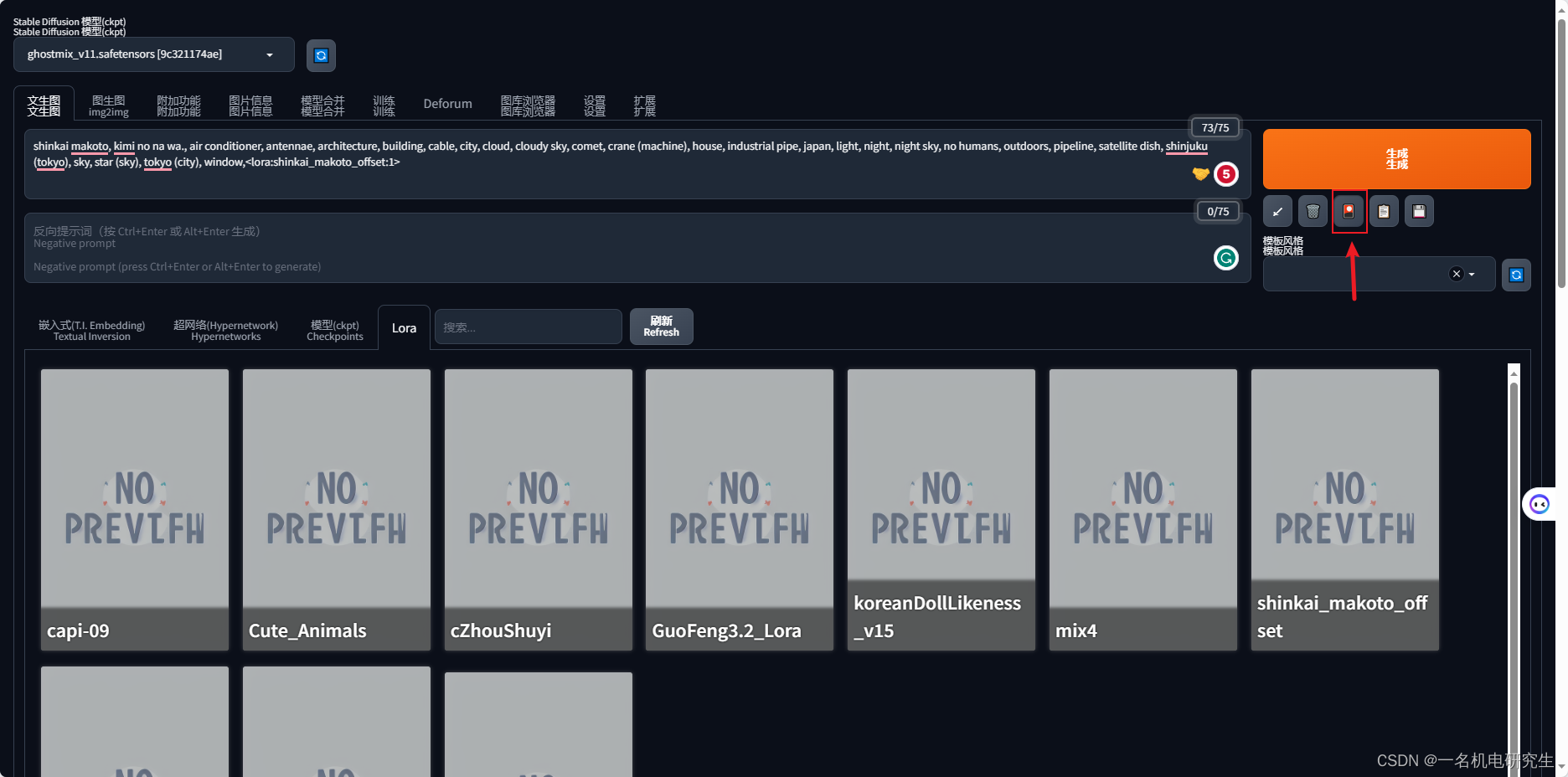
-
点击 Lora 之后,可以看到当前 Stable Diffusion 已经安装的 Lora,找到自己上传的 Lora,就会在 Prompt 产生一行对该 Lora 的引用。
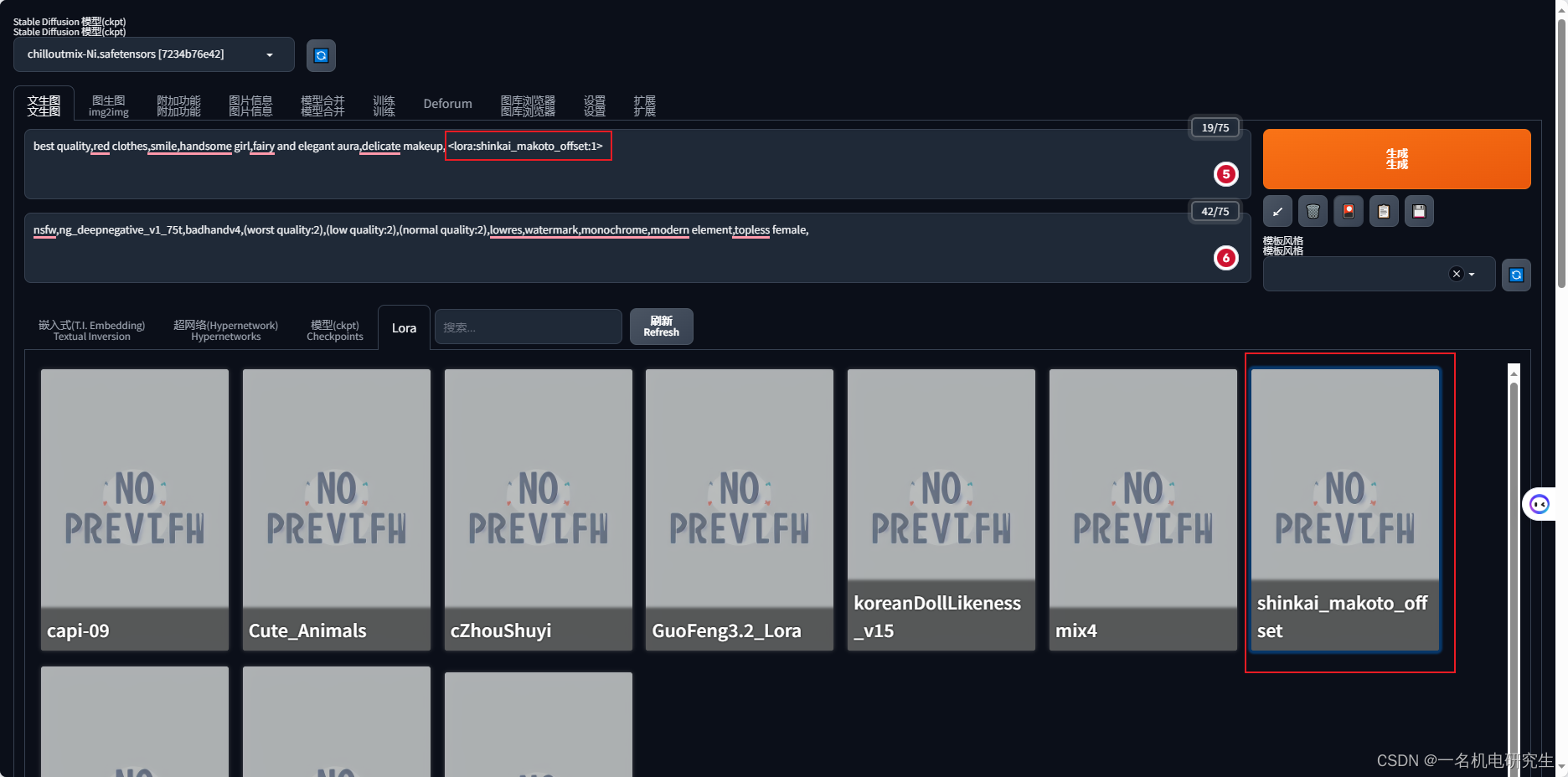
至此,当前的 Stable Diffusion 版本已经装好了某个自己喜欢的 Lora,同理 , 可以用同样的操作方式安装 Checkpoint、 Embedding 等。
接下来我们使用 InsCode Stable Diffusion 来进行 AI 绘图。
五、使用 InsCode Stable Diffusion 进行 AI 绘图
下面是我的一些生成例子的图片展示,附带参数设置以提示词和种子:
生成图一

参数配置:
Steps(采样迭代步数): 30
Sampler(采样方法): Euler a
生成批次:1
批次数量:1
CFG scale: 7
Size: 768x1024
Model hash: 7234b76e42
Model: chilloutmix-Ni
Version: v1.2.0
Seed: 162297642
提示词:
Prompt: Best quality,raw photo,seductive smile,cute,realistic lighting,beautiful detailed eyes,(collared shirt:1.1),bowtie,pleated skirt,floating long hair,beautiful detailed sky,
Negtive Prompt: Negative prompt: nsfw, ng_deepnegative_v1_75t,badhandv4, (worst quality:2), (low quality:2), (normal quality:2), lowres,watermark, monochrome
生成图二

参数配置:
Steps(采样迭代步数): 30
Sampler(采样方法): Euler a
生成批次:1
批次数量:1
CFG scale: 7
Size: 768x1024
Model hash: 74c61c3a52
Model: GuoFeng3
Version: v1.2.0
Seed: 1110161009
提示词:
Prompt: best quality,red clothes,smile,handsome girl,fairy and elegant aura,delicate makeup,
Negtive Prompt: nsfw,ng_deepnegative_v1_75t,badhandv4,(worst quality:2),(low quality:2),(normal quality:2),lowres,watermark,monochrome,modern element,topless female,
生成图三
在图三图四中使用了 Makoto Shinkai 的 Lora 模型,可以生成新海诚画风图片

参数配置:
Steps(采样迭代步数): 30
Sampler(采样方法): Euler a
生成批次:1
批次数量:1
CFG scale: 7
Size: 1440x810
Model hash: 9c321174ae
Model: ghostmix_v11
Version: v1.2.0
Seed: 2262843784
提示词:
Prompt: ((Best quality)), ((masterpiece)), abandoned brutalist architecture of Pripyat,sunlight,cloudy weather, hyper realistic DSLR photo, Nikon D5 lora:add_detail:1,mist,
Negtive Prompt: ng_deepnegative_v1_75t,easynegative,(worst quality:2), (low quality:2), (normal quality:1.8), lowres, ((monochrome)), ((grayscale)),sketch,ugly,morbid, deformed,logo,text, bad anatomy,bad proportions,disfigured,extra arms, extra legs, fused fingers,extra digits, fewer digits, mutated hands, poorly drawn hands,bad hands, (loli, young, child, infant, teenager:1.5), ((((turned on lights))))
生成图四

参数配置:
Steps(采样迭代步数): 30
Sampler(采样方法): Euler a
生成批次:1
批次数量:1
CFG scale: 7
Size: 1440x810
Model hash: 9c321174ae
Model: ghostmix_v11
Version: v1.2.0
Seed: 4267252388
提示词:
Prompt: shinkai makoto, kimi no na wa., air conditioner, antennae, architecture, building, cable, city, cloud, cloudy sky, comet, crane (machine), house, industrial pipe, japan, light, night, night sky, no humans, outdoors, pipeline, satellite dish, shinjuku (tokyo), sky, star (sky), tokyo (city), window,lora:shinkai_makoto_offset:1
Negtive Prompt: (painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), watermark, text, error, blurry, jpeg artifacts, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, (worst quality, low quality:1.4), bad anatomy
六、使用体验
本次功能测评到此结束。总得来说,InsCode 上面在线运行 Stable Diffusion 体验非常棒。然而,有时候会卡死,需要重启 GPU。此外,chilloutmix 在负面提示词较少时容易生成涩图。。。不利于青少年学习
感兴趣的小伙伴可以亲自尝试一下!