一、概述
awk命令是一种在Unix或类Unix系统上使用的文本处理工具。它以行为单位读取输入文件,按照预定义规则对每一行进行处理并生成输出。
通过使用一种简单的编程语言,awk提供了对文本数据进行过滤、处理和转换的强大能力。它可以轻松地提取文本中的特定字段、计算和操作数据、执行条件判断、循环处理等。
二、作用流程
1、读取输入文件:awk以逐行的方式读取输入文件。输入文件可以通过管道传递给awk,也可以作为awk命令的参数。
2、匹配模式:对于每一行,awk会尝试将该行与指定的模式进行匹配。模式可以是正则表达式,也可以是字符串等。
3、执行操作:如果当前行满足匹配模式,awk将执行相应的操作。操作可以是打印行、修改行的内容、计算数据等。
4、循环处理:awk会自动处理输入文件的每一行,重复执行匹配和操作的过程,直到处理完所有行。
5、输出结果:在处理完所有行之后,awk将输出根据操作生成的结果。默认情况下,结果会打印到标准输出(即终端),但也可以重定向到文件或通过管道传递给其他命令。
三、awk的使用
awk格式:awk '作用行 变量' 要修改的文件
awk 'FS' 文本字段的分割符,可以使用空格为占位符
awk 'NF' 过滤空行
这个命令使用了一个内置变量 NF,它表示当前行中的字段数量。如果字段数量不为零(即非空行),则条件为真。因此,它也会打印所有空行。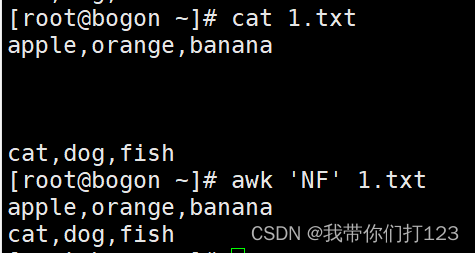
awk 'NR' 处理数据的行号
awk '$0' 处理整行的数据
这个命令使用了一个条件表达式,即整行内容 $0。如果整行内容不为空,则条件为真。因此,它会打印所有非空行。 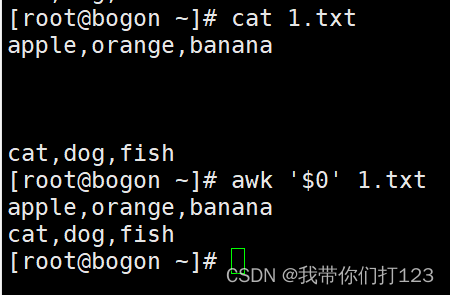
awk '{print $n}' 处理数据行第几列的数据 这里n代表的是列 
四、配合awk使用的命令
sort 这个命令用于排序 (默认顺序是:字符、数字、字母)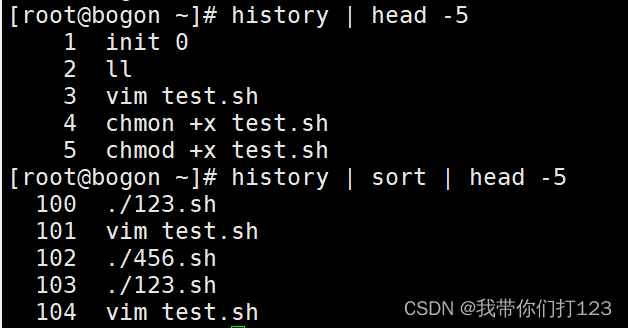
sort -n 按照顺序进行排序
sort -r 按照逆序进行排序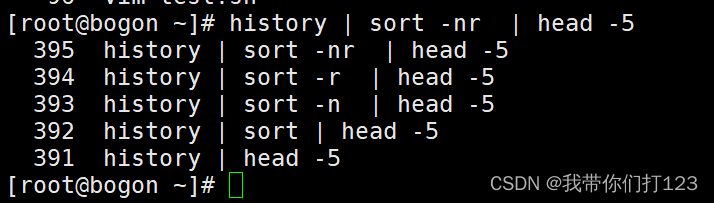
uniq -c 命令是用来去重 统计次数的这里可以看到统计我使用次数最多的前五个命令
history | awk '{print $2}' | sort | uniq -c |sort -nr |head -5
首先使用history查看使用过的命令
awk '{print $2}' 用于查看第二列
sort 进行第一次排序
uniq -c 进行去重统计
sort -nr 进行逆序排序
head -5 查看前五行
五、三剑客使用实例
这是一个朋友在上班的时候服务器被攻击了,然后用三剑客查找是哪个IP进行的攻击就用到了以下的命令
cat /var/log/httpd/access_log | grep `date "+%d"` | awk '{print $1}'| sort | uniq -c |sort -nr | head -5
cat用来输出日志
grep筛选当天的日志
awk单独筛选出ip
sort进行排序
uniq -c 进行去重
sort -nr 再进行逆序查看谁访问的最多
head -5 查看前五行