点击关注

文|郝鑫
编|刘雨琦
刚过去的WAIC(世界人工智能大会)俨然成为了大模型厂商的成果汇报大会。
百度文心大模型升级到3.5版本,训练速度提升2倍,推理速度提升30倍;华为云发布盘古大模型3.0,包含L0基础大模型、L1行业大模型和L2场景模型;阿里云发布AI绘画创作模型通义万相;腾讯云MaaS底座、行业大模型场景全面升级;商汤“日日新”大模型升级,金融、医疗等行业场景落地已超20个。
大模型走过从无到有,在当下的阶段,即使是站在同一起跑线的厂商,也走上了不同的分叉路:有人做通用大模型,有人做行业大模型;有人在为大模型的安全运行保驾护航,有人在提供造大模型的工具。
7月7日,在中国信通院发布的《2023大模型和AIGC产业图谱》中,将大模型和AIGC产业链上下游分成了行业应用、产品服务、模型与工具和基础层四个主要部分。

(图源:中国通讯院)
从图上看,大模型就像造房子,很难有一家企业完成所有环节。也就是说,如同互联网的大航海时代一般,大模型生态建设,所有人都有机会。
正如腾讯云副总裁、腾讯云智能负责人、优图实验室负责人吴运声告诉光锥智能:“大模型时代,开放是非常重要的特点。大模型要结合行业落地,需要花费大量的成本,在这种情况下,要想发挥最大的价值,只有开放,通过让各行各业的专家、各类角色的人员加入进来,才能让整个生态体系更健康,从而产生更多的可能性。”
发展的同时,问题也在逐渐暴露出来。相较于国外成熟的大模型市场,中国到现在还未构建起完整的大模型产业链,在底层的数据、芯片、计算能力存在欠缺,在模型训练、部署等环节还十分薄弱。
针对大模型产业链存在的痛点,腾讯云MaaS大模型精选商店升级技术底座,发布向量数据库和星脉网络,创新行业大模型的应用场景。
追本溯源,可以看出腾讯延续互联网时代的思路,腾讯云依然不做通用大模型,要继续做工具箱和连接器。
Always工具箱和连接器
据光锥智能了解到,早在6月19日,腾讯云就公布了行业大模型技术解决方案。该方案依托腾讯云TI平台打造行业大模型精选商店,为客户提供MaaS一站式服务,客户只需要加入自己独有的场景数据,就可以快速生成专属模型,结合实际业务场景需求,开发低成本、高可用的智能应用和服务。
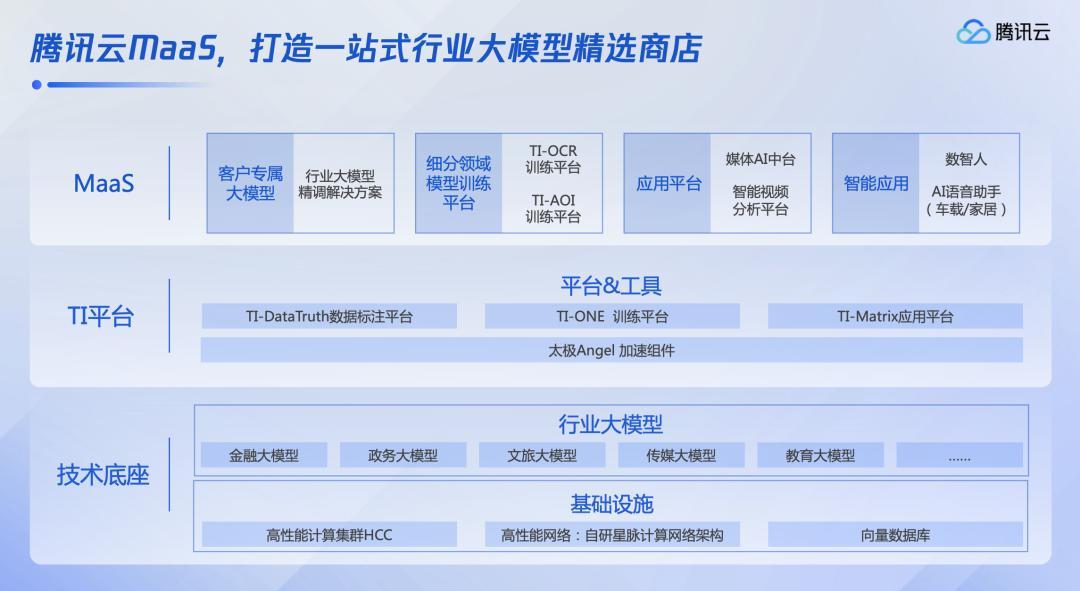
腾讯云MaaS大模型商店重点突出了两个特点,一是精专,二是灵活。
“精专”主要体现在对行业模型的训练上,腾讯云在其技术底座就内置了金融、政务、文旅、传媒、教育等多个行业大模型,这意味着从预训练时期开始,大模型便明确了方向,开始与行业经验结合。
打个比方,就好比大学生一入学就被分到了不同的专业,之后在此基础上继续研究生、博士深造。腾讯云的思路也是如此,把训练的数据先在行业大模型中磨砺一遍,然后再结合企业的私有数据,精调后生成企业专属模型。可以说,行业认知贯穿了模型训练、推理、部署的全过程,由此来提升行业场景的应用能力。
“灵活”主要体现在企业调取、使用模型能力、工具上。互联网时代,马化腾曾将腾讯的角色定位为“工具箱”,在大模型时代,腾讯云TI平台的角色有着异曲同工之处。
工具链决定着企业能不能把大模型能力和自己的业务、产品相结合,为此,腾讯云提供了包括数据标注、训练、评估、测试和部署等大模型工具箱和配套服务。企业可以在本地按需选用和组合工具,在保障安全的前提下进行私有化数据训练,还可根据业务场景需求,按需定制不同参数、规格的模型服务。
以前,腾讯连接了B端商家和C端用户,现在腾讯云也将这种能力复刻到大模型商店。工具组合形成的工具链还只是平台中的一环,连接起企业产品和大模型;另一条主线——数据(私有+公有),则串连起了大模型、企业、产业和用户。
行业应用是起点,也是终点,正如吴运声所言,“不管是什么样的技术,我们最根本的出发点,还是要解决实际的问题。”
大模型加速器
如何在大模型赛道上找到合适自己的节奏,腾讯云似乎已经摸到了脉路。
腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生曾表示:“关键还是要把底层的算法、算力和数据扎扎实实做好,而且更关键的是场景落地。”
延续着这样的思路,腾讯云一手抓底层算法、算力和数据,一手落地场景,MaaS大模型商店实现了全面的升级。

在技术底座环节,腾讯云聚焦一个“快”字,发布了星脉网络和向量数据库,为大模型安上了“风火轮”。
大模型进入万亿参数时代,单体服务器算力有限,需要将大量服务器通过高性能网络相连,打造大规模算力集群。
基于此,腾讯云通过对处理器、网络架构和存储性能的全面优化,攻克下了大集群场景下算力损耗问题,正式发布新一代HCC(High-Performance Computing Cluster)高性能计算集群。
该集群采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU,能提升40%的GPU利用率,节省30%-60%的模型训练成本,为AI大模型带来10倍通信性能提升。基于腾讯云新一代算力集群HCC,可支持10万卡的超大计算规模。
据腾讯云透露,腾讯云新一代集群的算力性能较前代提升高达3倍,是国内性能最强的大模型计算集群。
高性能计算群是一种底座能力,其技术的应用体现了通过技术手段的降本增效。
首先,相比于大量分散的计算机,高性能计算集群可以降低硬件成本和运维成本,同时方便集中管理。其次,它可以提升计算、搜索的效率。提供分布式的计算能力,为向量数据库提供支持;还能进行复杂的科学计算和建模,这也是腾讯云“AI for Science”能迅速在天文、甲骨文考释取得成果的原因。
在大模型训练过程中,汤道生谈起过数据质量的问题,他表示:“目前通用大模型一般都是基于广泛的公开文献与网络信息来训练的,网上的信息可能有错误、有谣言、有偏见,许多专业知识与行业数据积累不足,导致模型的行业针对性与精准度不够,数据噪音过大。”
数据对大模型训练的意义不言而喻,当前,除了数据噪声过大,还存在数据处理、数据更新、数据安全等众多问题。
此外,大模型还存在一个致命的缺点——没有长期记忆,C端对话场景还可以重新提问,但应用在行业,就可能造成系统崩溃。
OpenAI 很早就意识到这个问题,通过与Zilliz、Pinecone、Weaviate等向量数据库公司合作,为ChatGPT配置上了“外置缓存”,向量数据库+大模型也被称之为“黄金搭档”。
国外向量数据库大热带动了国内厂商加速,腾讯云也赶上了第一波,发布了国内首个AI 原生向量数据库。

针对大模型场景,它在接入层、计算层、存储层实现了全面AI化:
在接入层,智能化支持自然语言文本的直接检索;
在计算层,通过AI算子替代企业寻找/调优AI算法,将接入工期从一个月缩短到3天;
在存储层,融合智能压缩算法,把向量存储成本降低50%。
企业数据接入需要分为三步,分别为文本切分、向量化以及导入。以前,这三步分别由不同的公司来做,因此周期被拉得无限长,而腾讯云将三步化作一步,直接实现了一站式接入,效率提升了10倍。

不过,从参数来看,目前腾讯云向量数据库性能依旧在初级的阶段。
举个例子,腾讯云向量数据库最高支持10亿级向量检索规模,并将延迟控制在毫秒级。作为对比Milvus最大能支持560亿向量检索规模,支持每秒进行上百万的向量相似性搜索。
但10亿级也可以说是向量数据库的入门级参数。Pinecone 官方demo 表明其可以在 10 亿条向量中实时搜索;Weaviate算法可支持十亿量级的向量索引。
工欲善其事,必先利其器。从最底层一步步砸实技术,看似腾讯云走了一条慢路,但小布快走,实现快速迭代后,带动的将是整个生态系统的提升。
50个场景,腾讯云批量着陆
场景一直是腾讯所强调的产品文化,即做一个产品或者上线一个功能,首先考虑的是,能不能找到场景,找到用户。
同样切入MaaS,站在新的起跑线上,腾讯云通过沉淀的行业Konw-how,瞄准企业应用刚需,推进大模型应用落地,将场景作为训练大模型的磨刀石。
“大模型虽好,但用起来还是有很高的门槛。尤其对一些传统领域企业而言,通用大模型无法精准适配、达到降本增效的预期。企业需要的,是在实际场景中真正解决某个问题,而不是在100个场景中解决了70%-80%的问题。”吴运声道。
腾讯云认为,大模型不只是少数人的游戏,把大模型从“通才”转变为“专才”,对企业来说或许是一个可行的路径。腾讯云在其中承担的角色,就是要将门槛打下来,提供一条龙服务,帮助企业跳过模型训练、部署的“冷启动”阶段。
据光锥智能了解,基于腾讯在互联网行业的长期沉淀,腾讯云已联合金融、文旅、政务、传媒、教育等十多个行业头部客户,共同打造了超过50个行业大模型解决方案,这些都是腾讯 CSIG 的重点服务行业。

在金融风控场景,腾讯云风控大模型融合了腾讯过去20多年黑灰产对抗经验,和上千个真实业务场景,提供了金融风控解决方案。企业可以基于prompt模式,迭代风控能力,从样本收集、模型训练到部署上线,实现全流程零人工参与,目前,建模时间已经做到从2周减少到仅需2天。
在交互翻译场景,基于行业大模型技术,腾讯云无需百万级的训练数据,使用小样本训练也可以获得不错的翻译结果,让每一次交互翻译,都能对下一句的翻译提升发挥实时作用。
以行业场景为切入,技术、应用同时迭代升级,这样的速度明显要更快,效果也更加显著。
据腾讯云在WAIC最新数据,上述金融风控解决方案,相比之前已有了10倍效率的提升,整体反欺诈效果比传统模式有20%左右的提升;腾讯云数智人工厂,内置超过10个AI算法模型,腾讯云MaaS能力,可以让2D数智人分身复刻缩短至24小时。
技术和应用两条腿同时跑,底层大模型支撑应用场景落地,场景也反过来反哺大模型。
正如同腾讯云所强调的一个观点“产业场景是大模型的最佳练兵场”,前期大模型所学习到的行业经验可以在现实应用场景中得到矫正,再次沉淀到腾讯云MaaS平台行业模型底座,重新更新认知,以此循环往复,行业大模型将越调越精,企业也越用越灵。
另一方面,成熟的应用落地场景,或许又将为大模型商业化开拓出新的道路。
事实证明,贪图一时的热闹并不长远,即使是拥有绝对技术壁垒的ChatGPT也面临着流量下滑的命运,OpenAI 创始人更是直言,ChatGPT插件不如预期的原因在于,人们更想把GPT的能力用到自己的应用当中。
开启大模型下一个竞争阶段,场景与商业化能力或将变得更加密切。
正如腾讯云副总裁、腾讯云智能研发负责人吴永坚所认为的:“互联网已经走到从最开始的纯免费阶段,慢慢向某些场景去如何商业化的阶段,这不是大模型带来的,但大模型将我们商业化的途径变得更清晰了。”
欢迎关注“光锥智能”CSDN号,关注前沿科技!




![Unity Shader - SV_POSITION 和 TEXCOORD[N] 的varying 在 fragment shader 中输出的区别](https://img-blog.csdnimg.cn/b25bef8b30844ed5815298fafa04e3d2.png)