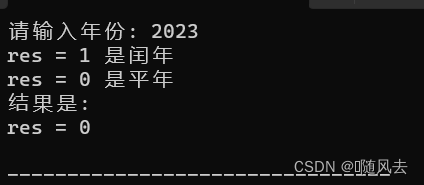
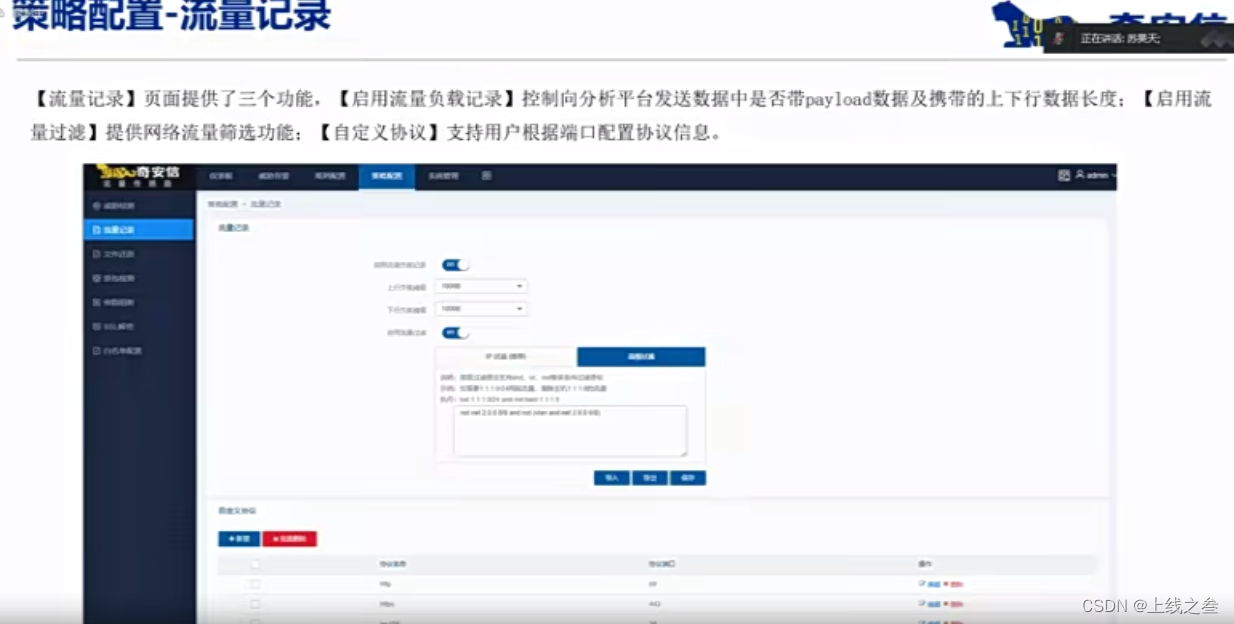
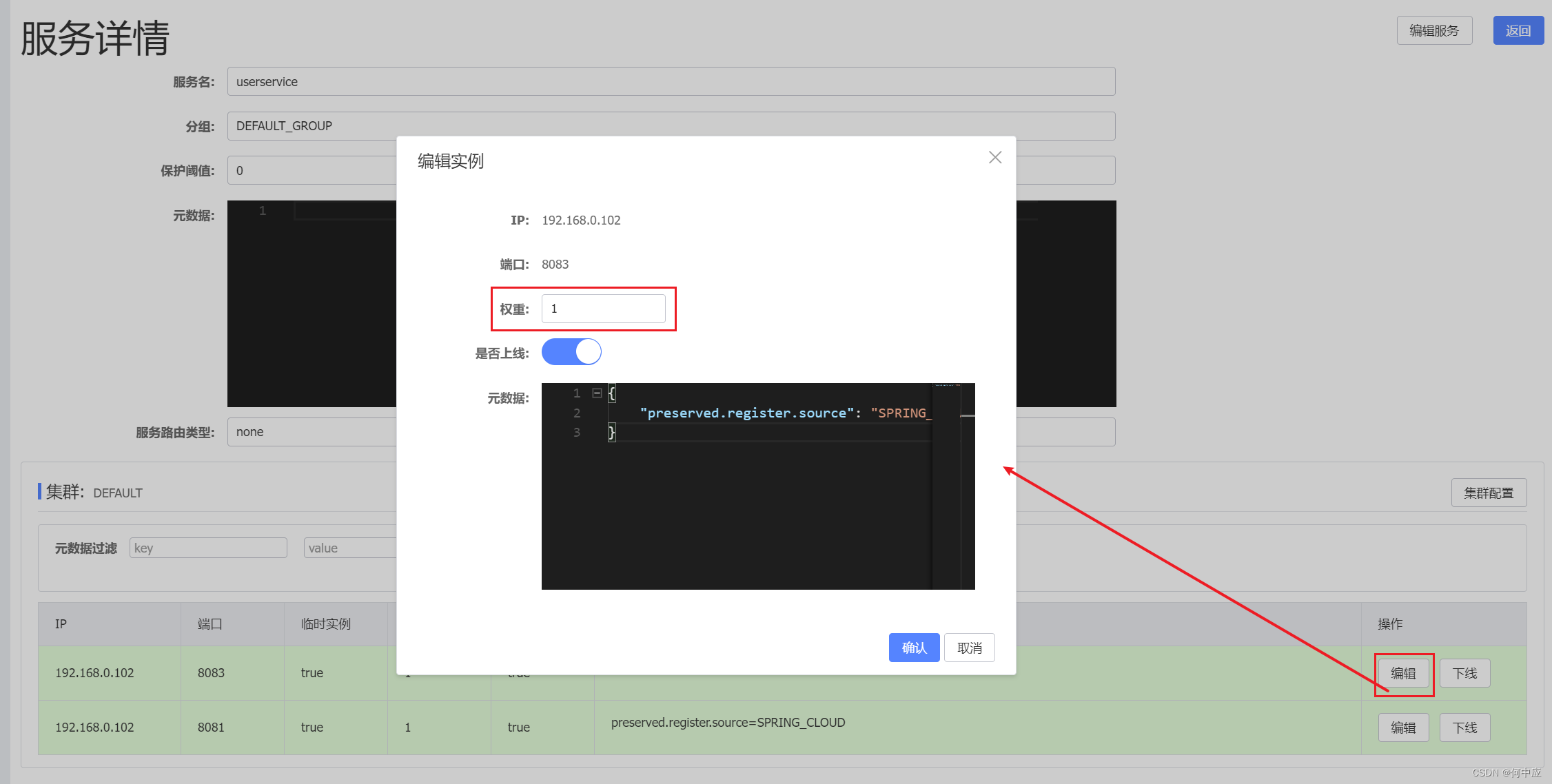
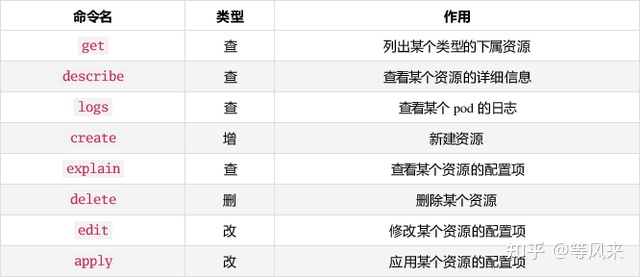
通过kubectl命令可以操作和管理K8S资源,对于初学者可以在掌握K8S基础命令的基础上再去学习K8s的原理和架构,那么K8S常用的命令有哪些呢?
01
K8S命令概述
在学习K8s基础命令前,了解和学习docker命令是很有必要的,kubectl和docker很多命令都有相通之处
docker ps #查看所有up状态容器
docker ps -a#查看所有状态的容器
docker inspect containerid#查看容器详情
docker images #查看容器镜像
docker start/stop/restart containerid #启动/停止/重启容器
docker exec -it containerid bash #进入容器
docker exec containerid bash -c 'uptime' #容器外执行命令
docker rmi imageid #删除镜像
docker rm containerid #删除容器- K8S常用命令
02
K8S集群资源操作
- 集群资源查看
kubectl get cs #集群健康情况
kubectl version #K8S集群版本查看
kubectl get node #查看集群节点
kubectl get pods -o wide -A #查看所有命命空间pod
-n #后跟指定命名空间
--all-namespaces #等同于-A
kubect get deployments -A
kubectl get svc,ep -A #查看svc和endpoints- 标签查看
kubectl get pod --show-labels #查看pod标签
kubectl get node --show-labels #查看node标签- 资源配置查看
查看配置
kubectl get deployments.apps nginxtest-xxx -oyaml #查看deployment资源
kubectl get pods nginxtest-xxx -oyaml #查看pod资源配置
- 资源限制
查看是否有资源限制
kubectl describe node 192.168.1.2capacity代表减去系统预留的资源总量
Allocatable可分配给K8S资源的总量
pod资源限制,防止单个服务占用资源过高影响其他pod,达到limits数值后会oom重启
kubectl get pods nginx-test -oyaml | grep -A 6 resources
resources:
limits:
cpu: "5"
memory: 5000Mi
requests:
cpu: 55m
memory: 100Mikubectl --help 多用help03
K8S运维场景
- 副本扩容
通过副本扩容实现流量分摊,避免单个节点负载过高,建议资源中增加反亲和性,达到不同副本调度到不同node
kubectl scale deployment nginx-test --replicas=2 #副本扩容
kubectl edit deployment nginx-test #直接编辑修改spec.replicas标签扩容- 进入pod
kubectl exec -it podname bash #或者sh
-n 指定名字空间
kubectl exec nginx-965048598-jt28d -n test uptime #不进入容器,只获取命令输出
- pod删除操作
kubectl delete pods nginx-test-6fc6d8666b-mhl48 #常规删除
kubectl delete pod -l app=test #基于标签删除,批量操作效率高
kubectl delete pods nginx-test -n dev --grace-period=0 --force #强制删除,没有terminationGracePeriodSeconds 30s的时间还可以通过kubectl scale命令将副本缩为0的方式删除pod
- pod污点
对于设置了污点的服务,普通pod无法调用到此节点,只有增加了Tolerations容忍配置才可以
[root@wpseco-node-1 log]# kubectl describe node 192.168.0.1 | grep Taints
Taints: <none>
kubectl taint node 192.168.0.1 test-access-node=:NoSchedule --overwrite=true #污点添加
kubectl taint node 192.168.0.1 test-access-node:NoSchedule- #污点删除
其中[effect] 可取值:
NoSchedule :一定不能被调度(新来的不要来,在这的就别动了)
PreferNoSchedule:尽量不要调度(尽量不要来,除非没办法)
NoExecute:不仅不会调度,还会驱逐Node上已有的Pod
- pod文件拷贝
kubectl cp my_item.tar.gz redis-6c98cb5b5f-nxb59:/tmp/ #宿主机拷贝到容器内
kubectl cp redis-6c98cb5b5f-nxb59:/tmp/start.sh ./start.sh #pod内文件拷贝到宿主机- 静态pod
静态pod 是由 kubelet 管理的,只在特定node上存在的pod;静态pod总是由kubelet创建的,并且只在kubelet所在的Node上运行。静态pod 不能通过 api-server来管理,无法和 RC,RS,Deployment或者 DaemonSet进行关联;并且 kubelet无法对静态pod 进行健康检查
静态pod资源文件默认存放路径/etc/kubernetes/manifests,也可以直接查看kubelet启动参数staticPodPath: /etc/kubernetes/manifests配置确定
kubectl exec -it kafka-1-192.168.0.1 -c kafka sh #进入静态pod
-c #po有多个容器要加-c指定
kubectl logs kafka-1-192.168.0.1 -c kafka 04
K8S问题定位
处理K8S环境问题,首先要了解pod的生命周期和pod的状态

常见状态原因
- ImagePullBackOff 镜像拉取失败,网络不通,镜像名称有误或者镜像仓库认证失败都可能有这个报错
- CrashLoopBackOff 探针检测失败,服务对网络或者其他pod服务有依赖等,此外宿主机上的安全软件可能也会导致容器无法正常启动
- Pending 一般是调度失败,pod没有可调度的节点,常见原因:节点有污点,不满足节点亲和性,或者节点处于notready状态
- Evicted 当节点内存、磁盘或者cpu资源不足时,K8s 会按照 QoS 等级对节点上的某些 Pod 进行驱逐,释放资源保证节点可用性,kubelet可以配置内存,cpu和磁盘的驱逐阈值
- Terminating pod删除后超过terminationGracePeriodSeconds参数时间还处于Terminating状态可能是存在节点故障,和master节点失联,可以检查节点状态或者尝试重启kubelet
- Completed 此状态通常是job类的pod执行完成了正常退出容器
- Init:Error pod初始化失败,可以查看init pod的日志定位
问题定位经常需要使用如下命令
kubectl logs -f podname
kubectl logs -f -l app=nginx-test #多副本情况下,可以看到所有pod日志
kubectl describe pods podname #pod启动日志
kubectl describe node 192.168.0.1 #节点状态日志
kubectl get events #查看集群事件
系统服务查看
systemctl status kubelet/docker/etcd
系统服务日志查看
journalctl -xeu kubelet/docker
--since指定时间