文章目录
- 文本生成
- 文本摘要
- 抽取式文本摘要
- 抽取式文本摘要方法
- 案例分析
- 优点
- 缺点
- 生成式文本摘要
- 指针生成网络文本摘要
- 预训练模型与生成式摘要
- 优点
- 缺点
- TextRank文本摘要
- BertSum模型文本摘要
文本生成
文本生成(Text Generation):接收各种形式的文本信息作为输入,生成可读的文字表述。
文本摘要
文本摘要也是文本生成的应用,旨在将文本或文本集合转换为包含关键信息的简短摘要。摘要应该涵盖最重要的信息,同时要连贯无冗余,并在语法上可读。
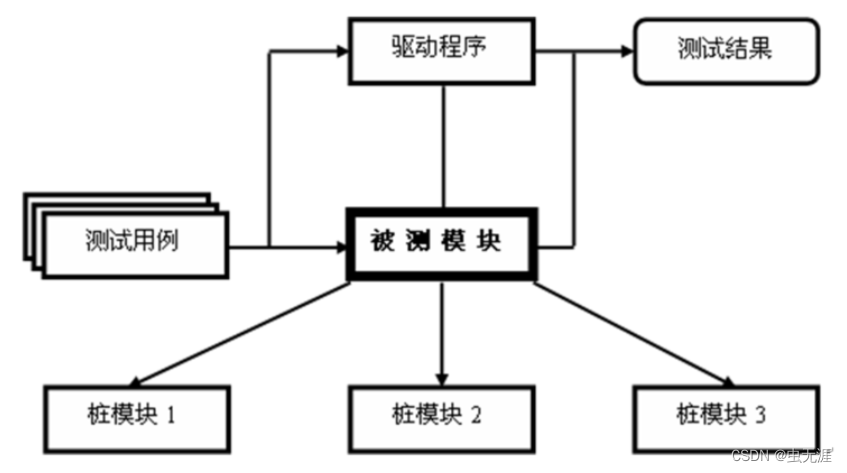
文本摘要的分类:
摘要质量的评价指标:
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)分数,判断自动摘要和参考摘要的符合程度。其中最常用的是ROUGE-1、ROUGE-2和ROUGE-L。ROUGE-1和ROUGE-2的计算方式相同,即:

ROUGE-L即最长公共子序列(Longest Common Subsequence,LCS),计算如下:
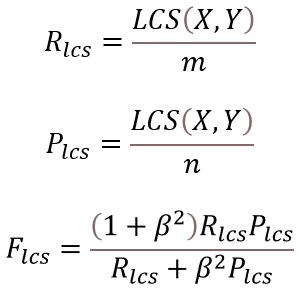
抽取式文本摘要
抽取式摘要(Extractive Summarization),从原文中选取关键词或句组成摘要,可以看作是一种序列标注问题,对原文中的每个句子(或字、词等单位)都做一个二分类,判断是否属于摘要,并组合起来作为摘要。
抽取式文本摘要方法
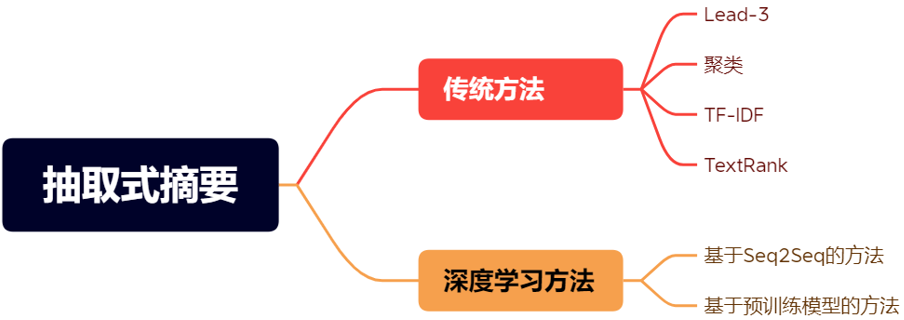
1.Lead-3方法:
抽取式摘要方法中,最简单的就是Lead-3方法:直接选取原文的前三句作为摘要。但因为许多语料会在文档开头就表明主题,因此Lead-3 方法虽然简单,但往往有着不错的表现。
2.基于聚类的方法:
通常情况下,文档中的相近的语句或段落会描述相近的内容,所以我们可以使用聚类完成摘要任务。例如可以通过余弦相似度的度量指标,将一篇文档中里的语义相近的句子聚到一簇,不同簇间往往表征着差别较大的语义。然后通过对簇内部的句子进行筛选,可以达到精简句子、提炼主题关键句的目的。
3.TF-IDF:
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用技术,常用于挖掘文章中的关键词,算法简单而高效,常被工业用于最开始的文本数据清洗。
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)。词频即词出现的次数,一个词的词频越高,越可能作为句子的关键词。


但是在一篇文章中,两个相同词频的词未必有相同的重要性,因为有些词如“系统”、“算法”这种词在某个计算机相关语料库中可能本身就比较常见。这个时候就需要IDF,IDF会给常见的词较小的权重,它的大小与一个词的常见程度负相关。
当有TF(词频)和IDF(逆文档频率)后,将这两个量相乘,就能得到一个词的TF-IDF值。
TF-IDF文本摘要流程:
某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。包含关键词较多的句子,就可以作为摘要句。
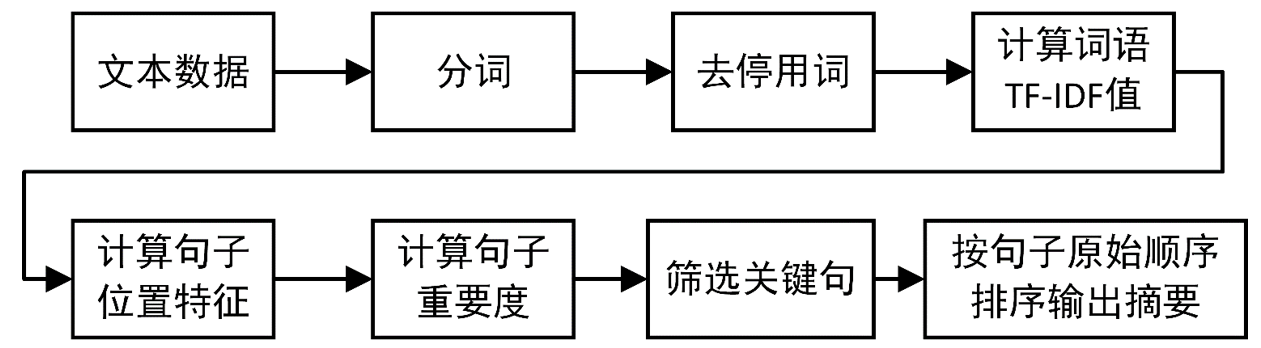
① 对于给定的文档进行分词、去停用词等数据预处理操作。保留如“名词”,“动词”,“形容词”等有实意的词语,最终得到n个候选关键词,即
“D=[” 𝑡_1 “,” “t” _2 “,…,” “t” _𝑛]
② 统计词语𝑡_𝑖在文本D中的词频TF;
③ 统计词语ti的逆文档频率IDF,整个语料库文档个数为D_n, D_𝑡为语料库中词语𝑡_𝑖出现的文档个数;
“IDF=log (” 𝐷_𝑛/(𝐷_𝑡 “+1))”
④ 基于TF-IDF公式,计算得到词𝑡_𝑖的权重值, 并重复2到4得到所有候选关键词的TF-IDF数值;
𝑇𝐹−𝐼𝐷𝐹=𝑇𝐹∗𝐼𝐷𝐹
⑤ 前边得到了词的权重,就可以计算句子的权重,例如一个句子分词得到的词序列为[𝑡_1,𝑡_2,…,𝑡_𝑛],那么该句子权重为:
𝑠𝑐𝑜𝑟𝑒=∑𝑖=1𝑛 𝑇𝐹-𝐼𝐷𝐹(𝑡_𝑖)
此外由于新闻文本等语料往往会在开头就表明主旨,也可以选择为前几条句子添加额外权重。
⑥ 按照句子分数由高到低对句子排序,然后截取权重最高的几条句子,按照它们在原文中的原始顺序排序,输出作为摘要。
案例分析
【例】在认真听取大家发言后,李鹏宇做了总结。他表示,今年是新中国成立70周年,也是全面建成小康社会、实现第一个百年奋斗目标的关键之年。今年以来,面对纷繁复杂的国际国内形势,我们要好好学习。贯彻新发展理念,统筹推进稳增长、促改革、调结构、惠民生、防风险、保稳定各项工作。经济运行总体平稳、稳中有进,经济高质量发展取得新的进展。
def train(self):
self.IDF = {}
document_freq = {} # 词语的文档频率,即包含特定词语的文档个数
documents = self.load_corpus(default_corpus_size=None) # 读取语料库,返回文档合集
for doc in documents:
for word in set(doc):
document_freq[word] = document_freq.get(word, 0) + 1 # 对于其中的每个词,获取包含该词的文档数
corpus_size = len(documents)
for word in document_freq:
self.IDF[word] = np.log(corpus_size/(document_freq[word] + 1)) # 计算每个词的IDF
pickle.dump(self.IDF, open("IDF_model.pkl", 'wb'))
def summary(self, text): # summary函数接受一段文本,返回对按TF-IDF进行句子重排后的文本。
sentences = text.split("。") # 将文本切分为句子。
new_sentences = []
sentence_score = {}
words_in_sentences = []
word_weight = {} # 存储本文档中各个词语的词频
for sentence in sentences:
if len(sentence)>100 or len(sentence)<2: continue
words = jieba.cut(sentence) #对句子分词,得到词语list
for word in words:
word_weight[word] = word_weight.get(word, 0) + 1 # 计算每个词的词频
words_in_sentences.append(words)
new_sentences.append(sentence)
print("计算句子权重", word_weight)
for i in range(len(new_sentences)):
sentence_score[new_sentences[i]] = np.sum([word_weight[word] * self.IDF.get(word, 0.01) for word in words_in_sentences[i]]) # TF*IDF,然后求和作为句子的权重
print("对句子排序")
sentence_sorted = sorted(sentence_score.items(), key=lambda x: x[1], reverse=True)[:2]
summary = "。".join(map(lambda x: x[0], sentence_sorted))
return summary
摘要结果:
在认真听取大家发言后,李鹏宇做了总结。他表示,今年是新中国成立70周年,也是全面建成小康社会、实现第一个百年奋斗目标的关键之年。
4.基于Seq2Seq的方法:
文本摘要任务的输入是一个序列,输出也是一个序列,那么就可以用Seq2Seq解决。编码器可以使用RNN或者CNN,解码器也可以使用RNN。进一步地,可以引入注意力机制,在解码器的不同阶段,对原文不同位置分配不同的注意力,也就是解码器的每个阶段对应的语义向量是不同的。
5.基于RNN的抽取式摘要:
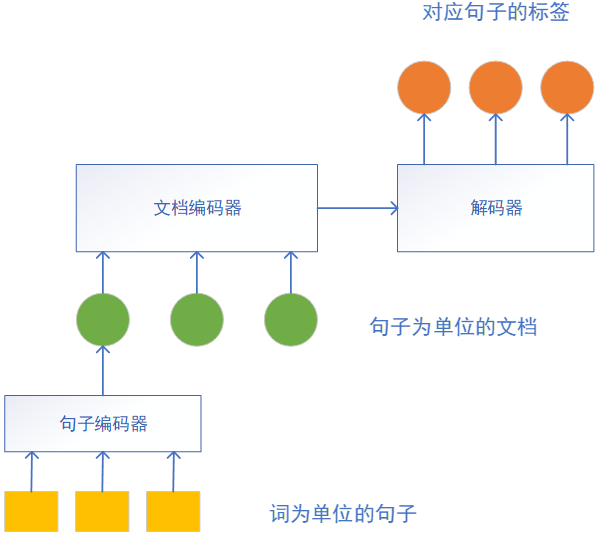
抽取式摘要生成任务通常被视为序列标注任务,大都是基于RNN的Seq2Seq结构,通常由句编码器、文档编码器和解码器(句子抽取器)组成。
句编码器:将句子以词为单位输入,获得句子的向量表示。
文档编码器:以句编码器得到的句向量作为输入,得到文档的向量表示。
解码器:通过编码结果给每个句子分配一个二分类标签,判断是否要将当前句子放入摘要。
6.基于预训练模型的抽取式摘要:
Transformer模型提出后,在Transformer的基础上,预训练模型如Bert在NLP的各个领域都取得了优异的表现,文本摘要领域当然也不例外。例如2019年被提出的HIBERT模型,是专为抽取式文本摘要任务设计的,他们采用的方法便是将摘要任务看作序列标注任务。
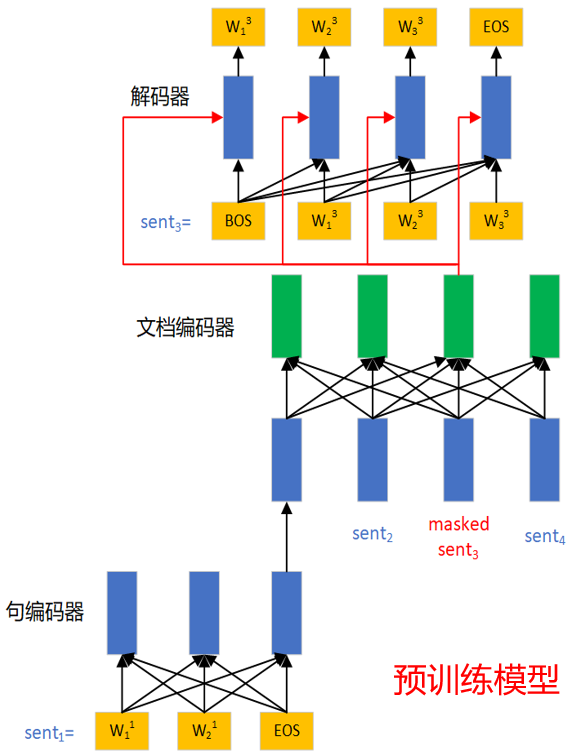
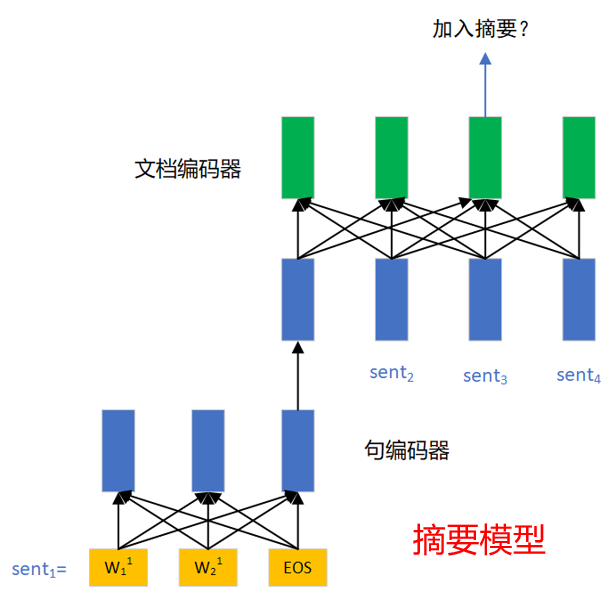
预训练的模型结构分为三部分:句编码器、文档编码器和解码器。句编码器接收一个以词为单位的句子,得到单个句子的句向量;文档编码器则接收句编码器得到的句向量进行编码,得到结合了文档信息的句向量表示。
预训练阶段的任务是预测被mask的句子,和BERT的MLM任务类似,将一个句子mask掉,然后将对应位置向量输入解码器,对该句子进行自回归的预测。预训练的过程中,文档编码器就隐式地学习到了文档中的句子和当前句子之间的关系,即当前句子对全文的重要性。
在摘要阶段,将原文输入层次编码器,取文档编码器每个位置的输出,即结合了文档信息的句向量表示,接入全连接层二分类,判断是否属于摘要。
HIBERT模型结构:
优点
抽取式方法实现一般较简单。且由于摘要内容都来自原文,在天然语法上错误率低,保证了一定的摘要质量,适合科技文献、法律文书、医疗诊断书等文本载体。
缺点
当抽取式方法选择摘要句的数量确定时,可能会有较重要的语句不会被抽取,如取3条句子作为摘要,但实际上要4条句子才能对原文进行较好的概括,这会造成摘要内容的不连贯和缺失。而且一个句子的表达可能会很冗余,其内容并不一定都是重要的,以句子为单位做摘要,可能会有很大冗余。
生成式文本摘要
生成式摘要(Abstractive Summarization),作为生成式任务,常采用编码器-解码器(Encoder-Decoder)结构实现。在编码器-解码器结构中,编码器“理解”输入序列,而解码器根据编码器对原文的理解(编码结果)和已生成的部分摘要信息来生成后续内容。
相对于抽取式方法,生成式摘要内容来源不局限于原文内容,可以是原文中从未出现的,这更贴近人类做摘要的做法,摘要表达可以更为简练,冗余度更低,但相应的实现难度也较高。
生成式摘要常采用编码器-解码器模型实现。通常而言,编码器将原文转换为向量表示,即语义向量,解码器通常是自回归的,在语义向量和前一段文字的基础上,生成下一个词,从而生成一段完整的摘要。
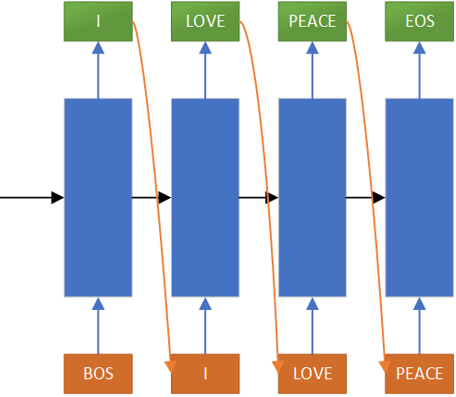
首先向解码器输入编码器输出的语义向量和“BOS”,生成“I”,然后将“I”作为编码器下一时间步的输入,生成“LOVE”,以此类推直到输出“EOS”结束。这就是自回归解码器。
Seq2Seq为生成式文本摘要提供了一种可行的方法,这意味着它们不局限于简单地从原文中选择和重排段落。然而,这些模型大都有两个问题 :
1.OOV(out of vocabulary)问题:目标任务中可能出现一些罕见词或是派生词,词的复数或者其他的一些组合词的规则而产生的词无法用现有词向量模型表示。
2.重复生成。
指针生成网络文本摘要
2017年《Get To The Point: Summarization with Pointer-Generator Networks》中提出了用于文本摘要的指针生成网络模型。该模型是抽取式与生成式的结合,引入了两种机制解决以上问题:
1.生成概率指针𝑝_𝑔𝑒𝑛;2.覆盖机制
网络模型:
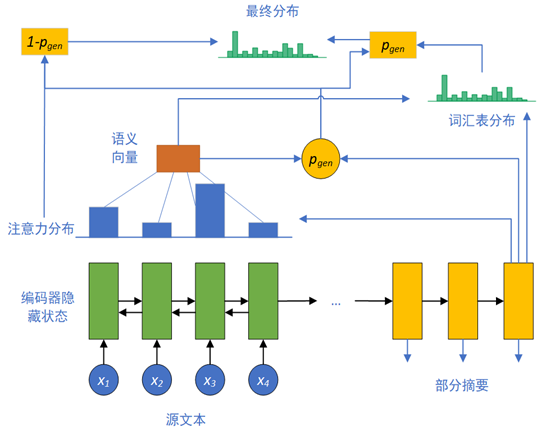
源文本输入编码器,在解码器的对应阶段产生注意力分布,并产生生成概率指针pgen,pgen为1时表示生成新文本,pgen为0时表示从原文中抽取。从而得到最终分布。
生成概率𝑝_𝑔𝑒𝑛计算如下:
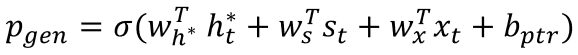
其中ℎ_𝑡∗是上下文向量(Context Vector),表征当前时刻加入注意力后的语义信息,𝑠_𝑡为解码器状态,𝑥_𝑡为解码器的输入,其余为可学习向量。𝑝_𝑔𝑒𝑛决定了当前时间步是生成还是从原文中抽取,可以通过指针从原文中复制单词,对于OOV词可以直接从原文获取,从而准确地复制信息,同时保留了通过生成器生成新词汇和词组的能力。
覆盖机制则首先将之前所有时间步的注意力权重加到一起,得到覆盖向量:
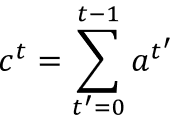
然后将其添加到注意力权重的计算过程中,覆盖向量𝑐_𝑡用来计算注意力向量𝑒_𝑖𝑡:
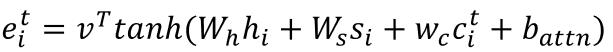
其中ℎ_𝑡即当前时刻的编码器隐藏状态,𝑠_𝑡为解码器状态,𝑐_𝑖𝑡为当前时间步的覆盖向量,其余为可学习向量。得到的𝑒_𝑖𝑡用来进行注意力分配。该方法用之前的注意力权重分配来影响当前注意力权重的分配,这样就避免在同一位置重复,从而避免重复生成文本。
于是最终分布为:
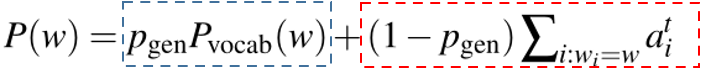
其中蓝框表示生成,红框表示抽取,从而可以选择性地从原文抽取内容,或是生成新的内容作为摘要。
预训练模型与生成式摘要
在Transformer之上产生了许多预训练模型,如大名鼎鼎的Bert,但Bert只是应用了Transformer的编码器,只能进行对文本的编码,不便进行生成式任务。于是在Bert的基础上出现了UniLM、BART、PreSumm等模型,可用于摘要任务。
UniLM
UniLM由微软研究院提出,其模型结构与BERT相同,并没有使用额外的解码器结构,而是利用三种不同的Self-attention Mask矩阵,以完成三种预训练语言模型任务:单向语言模型、双向语言模型,Seq2Seq语言模型。
其中Seq2seqLM是使得模型具有生成能力的关键,左侧的序列是源序列即原文,右侧的序列是目标序列即摘要。左侧的序列属于编码阶段,所以上下文信息都能看到;右侧的序列属于解码阶段,能看到所有源序列的信息、目标序列中当前位置及左侧(已生成)的信息。
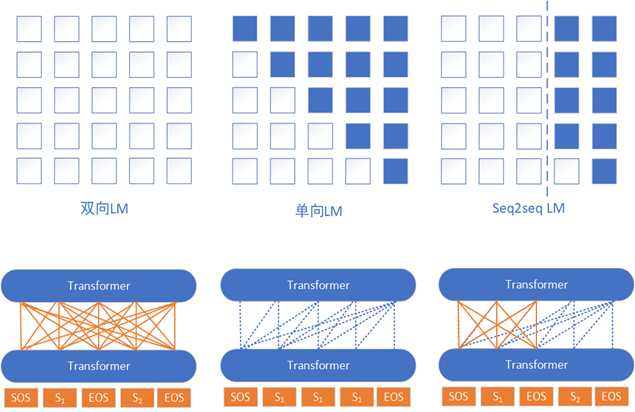
在预训练时,源序列和目标序列中的字符会被随机替换为[MASK]。在预测[MASK]的同时,因为源序列与目标序列被打包在一起,模型无形中学到了两个语句之间存在的紧密关系,这在生成式任务中非常有用。
在文本摘要任务上微调时,用S1和S2分别表示源序列和目标序列,构建出输入序列[SOS] S1 [EOS] S2 [EOS]。只对目标序列中的字符进行mask,让模型预测被mask的词。目标端的结束标识[EOS]也可以被mask掉,让模型学习预测,从而模型可以学习如何自动结束NLG任务。
Bert编码器+解码器:
将Bert编码得到的语义向量输入解码器,由解码器生成摘要,也是可行的方案。如《Text Summarization with Pretrained Encoders》中,PreSumm采用预训练的Bert作为编码器,随机初始化的Transformer作为解码器,由于编码器是预训练的,而解码器是随机初始化的,两者间存在不匹配,所以可以为编码器和解码器应用不同的优化器来适应这种现象。此外,先执行抽取式任务,再在抽取式的结果上执行生成式任务,两阶段微调有着更好的表现。
BART(Bidirectional and Auto-Regressive Transformers)可以看作使用Bert作为预训练编码器,并使用GPT2作为预训练自回归解码器,从而使模型具有文本生成能力。
BART的预训练分为两个步骤:
(1) 使用多种方式加入噪声来破坏原始文本。意图是破坏掉这些有关序列结构的信息(如序列长度),防止模型去“依赖”这些信息。
(2) 让模型学习重构原始文本。
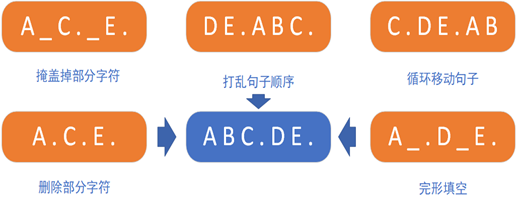
由于BART的解码器部分本身就采用了自回归方式,在进行文本摘要时,在编码器部分输入原始文本,解码器用于生成摘要。
优点
通过对句子进行融合,减小了句子的长度,从而减小了冗余;可以对非文本数据和跨语言数据进行摘要,例如可以用一段英文录音生成中文摘要。
缺点
实现难度较高;若训练不充分,生成的摘要可能不符合语法,从而难以理解。
TextRank文本摘要
TextRank是一种基于图的无监督摘要算法。与PageRank类似,TextRank算法是一种基于图的无监督抽取式文本摘要算法。TextRank用句子代替网页,任意两个句子的相似性代替于网页跳转概率,相似性得分存储在一个方阵中。 使用TextRank算法进行文本摘要的流程如图:
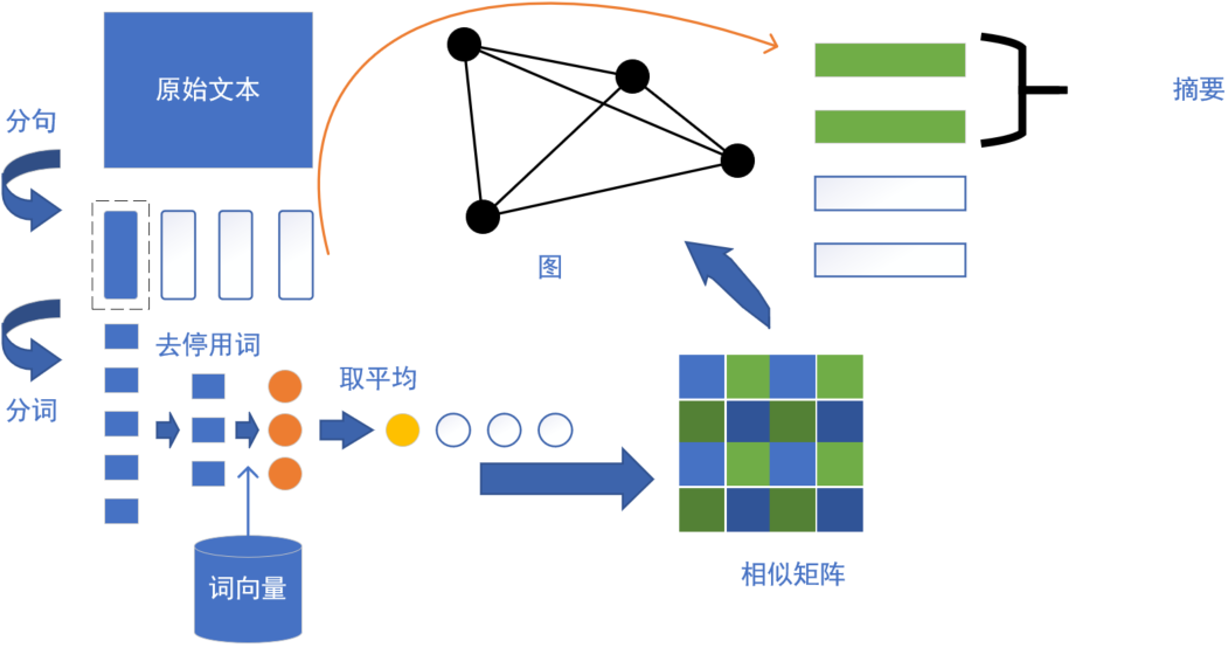
TextRank摘要案例:
class ExtractableAutomaticSummary:
# 定义一系列函数,略
…
def calculate(self.num_sents):
self.__get_word_embeddings() # 获取词向量
self.__get_stopwords() # 获取停用词
sentences = self.__get_sentences(self.article[0]) # 将文章分割为句子
cutted_sentences = [jieba.lcut(s) for s in sentences] # 对每个句子分词
cutted_clean_sentences = [self.__remove_stopwords_from_sentence(sentence) for sentence in cutted_sentences] # 去停用词
self.__get_sentence_vectors(cutted_clean_sentences) # 获取句向量
self.__get_simlarity_matrix() # 基于余弦相似度获取相似度矩阵
# 将相似度矩阵转为图结构
nx_graph = networkx.from_numpy_array(self.similarity_matrix)
scores = networkx.pagerank(nx_graph) # 计算得分
# 按重要程度进行排序
self.ranked_sentences = sorted(
((scores[i], s) for i, s in enumerate(sentences)), reverse=True
)
# 取最高的N个句子输出作为摘要
for i in range(num_sents):
print(self.ranked_sentences[i][1])
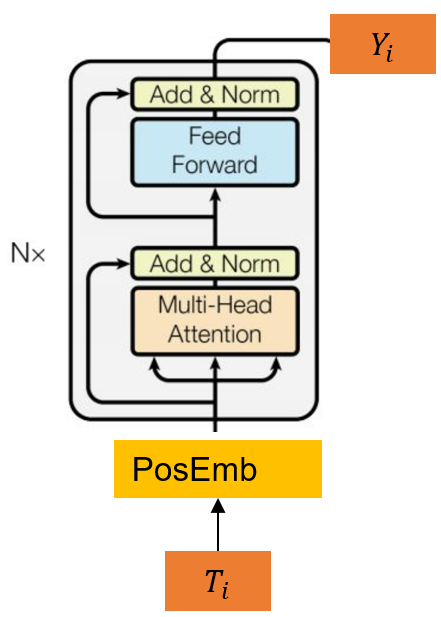
BertSum模型文本摘要
Yang Liu的《Fine-tune BERT for Extractive Summarization》中提出了BertSum,该方法使用基于Transformer的预训练编码器,并接入摘要层进行抽取式摘要。
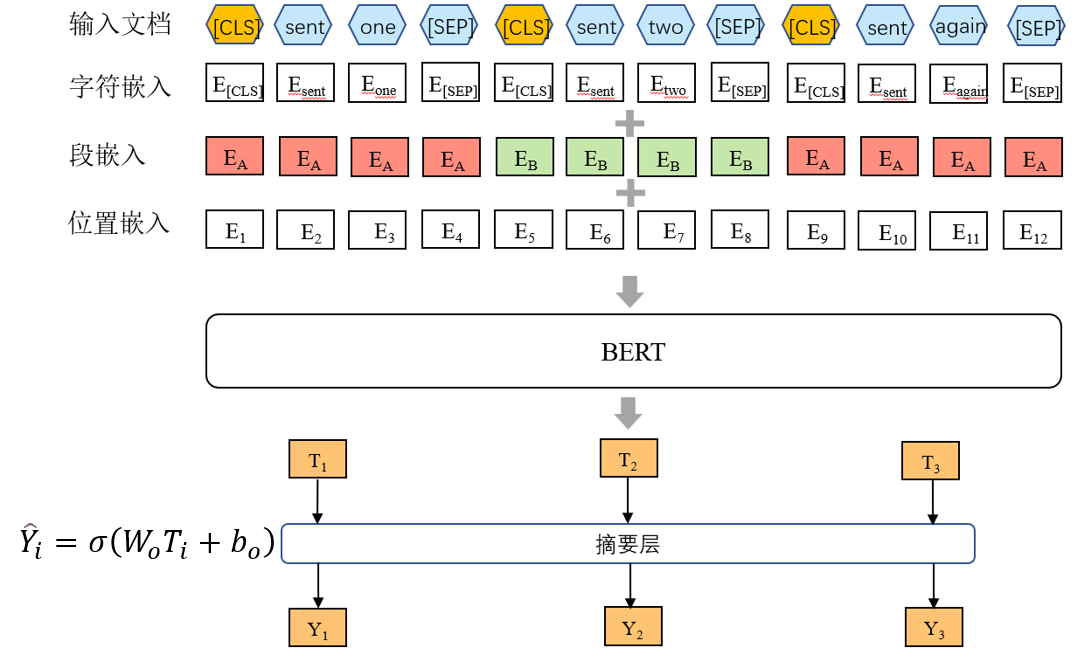
输出Y1Y2Y3分别代表这些句子属于摘要的概率。
摘要层可直接使用线性函数,并sigmod获取预测分数,其中Wo代表权重矩阵,Ti为输入的T向量。b为偏置量。
摘要层也可以使用句间Transformer,将多个Transformer层应用于句子表示,从BERT输出中抽取文档级特征:
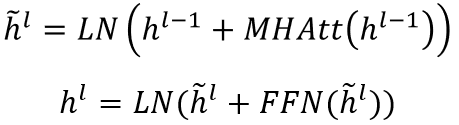
其中h_0= PosEmb(T),T为BERT输出的句向量,PosEmb为向T添加位置嵌入(表示每个句子的位置)的函数;h^L是句子对应的Transformer的顶层(第L层)的向量;LN为层归一化操作;MHAtt是多头注意力操作;上标l表示堆叠层的深度;最后一层也是sigmoid分类器。