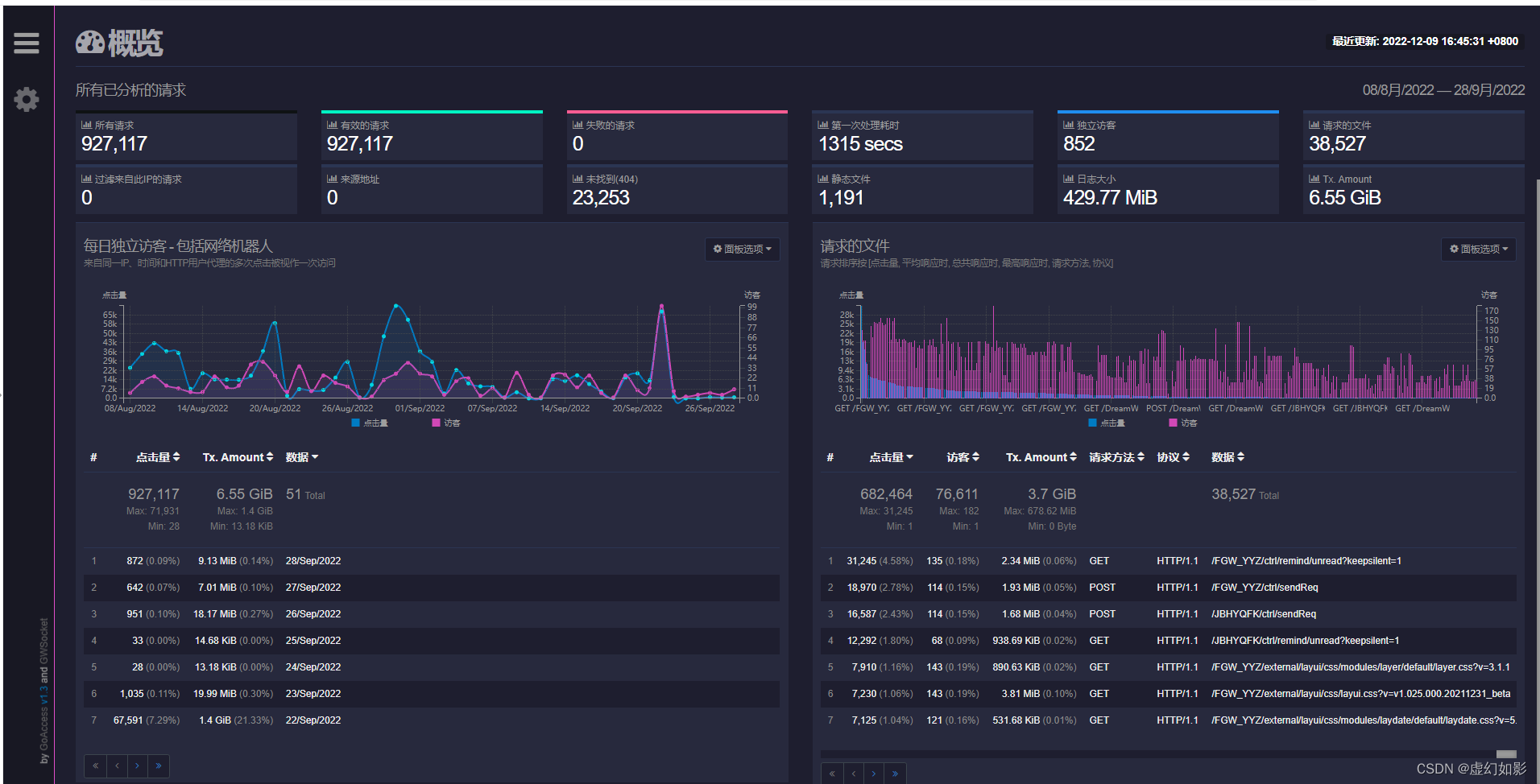
一个爬虫小例子:
import requests
import re
import json
def getPage(url):
response=requests.get(url)
return response.text
def parsePage(s):
com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S)
ret=com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
}
def main(num):
url='https://movie.douban.com/top250?start=%s&filter='%num
response_html=getPage(url)
ret=parsePage(response_html)
print(ret)
f=open("move_info7","a",encoding="utf8")
for obj in ret:
print(obj)
data=json.dumps(obj,ensure_ascii=False)
f.write(data+"\n")
f.close()
if __name__ == '__main__':
count=0
for i in range(10):
main(count)
count+=25但是这个例子我跑结果的时候出现问题,没有得到返回结果,我进行了单步调试:

看到reponse的返回值是418,百度下这个应该是网站的反爬程序返回的。所以,这个程序要进行下修改:
import requests
import urllib.request
import re
def getPage(url):
herders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML,like GeCKO) Chrome/45.0.2454.85 Safari/537.36 115Broswer/6.0.3',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive'}
req = urllib.request.Request(url, headers=herders)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
return html
def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S)
ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
}
def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
for obj in ret:
print(str(obj))
count = 0
for i in range(10):
main(count)
count += 25我们再来分析下正则表达式这块代码:
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>'上面这段是正则代码:
1)
.*? :这是一个惰性匹配,只匹配到之前标签的这个位置。

2)然后再看正则表达式:
(?P<id>\d+): 这是一个分组,然后里面\d是表示的数字,后面的加号,说明是多个数字。
前面的?P<id>是给这个分组一个名称。那么通过group(n)就可以获得这个值。
3)compile返回的com是一个正则表达式对象。然后该对象执行finditer,由于找的内容比较多,我们就使用迭代器。
4)然后我们就返回每个分组,每个分组都有自己的名称。我们没有使用return,而是使用的yield,那说明这个函数是生成器。这样就不会一下子占用很多内存,而是你边生成边获取。节省了内存空间。
5)再来看下爬虫程序的整个过程:
1. url从网页上将代码搞下来;
2、bytes code ->utf-8 网页内容就是我们的待匹配字符串;
3、ret是所有匹配的内容组成的列表;
6)理解下正则的用法。