1、确定索引库的名称
建议和使用的数据库的表名相对应
比如:数据库的表名为
那么索引库的名称可以为:item
2、确定索引库需要的字段
1.根据前端界面来判断需要什么字段
例如:
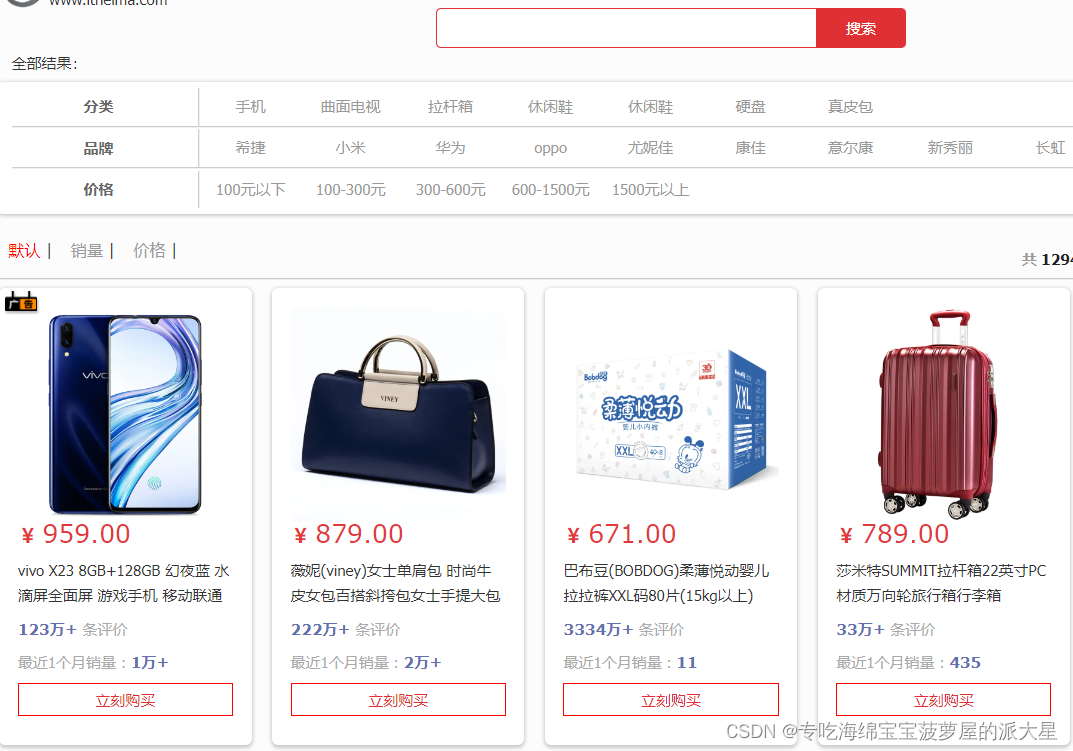
上边这个界面需要的就是:
分类,品牌,价格,商品图片,商品名称,评论数量,销量
除此之外,还需要
id,用于关键字全文检索的字段:all,用于自动补全的字段:suggestion,是否为推广广告:isAD
2.确定这些字段的属性
(图片不参与搜索,因此需要index为false)
分类:是字符串类型,且不可分词的,为keyword
品牌:是字符串类型,且不可分词的,为keyword
价格:是数值类型,为long
商品图片:存储的是网址,且不可分词的,为keyword
评论数量:是数值类型,为integer
销量:是数值类型,为integer
id:可以是long类型,也可以是keyword
all:因为搜索的时候,可以通过分类,商品名称,品牌进行搜索,所以为了提高效率,可以在床架索引库时,将这三个字段的内容复制一份到all字段,所以类型应该是可分词的文本text
suggestion:参与补全查询的字段必须是completion类型
isAD:只是保存是和否,所以是boolean(这个字段根据业务情况,可有可无)
3、根据上边分析的索引库结构创建索引库
es的索引库CRUD可以参考
http://t.csdn.cn/eSoyA
本例创建索引库的DSL语句为:
其中包含了自定义分词器,可以参考
http://t.csdn.cn/D7joj
# 商品数据索引库
PUT /item
{
"settings": {
"analysis": {
"analyzer": {
"text_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"price":{
"type": "long"
},
"image":{
"type": "keyword",
"index": false
},
"category":{
"type": "keyword",
"copy_to": "all"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer"
},
"isAD":{
"type": "boolean"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer",
"search_analyzer": "keyword"
},
"all":{
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}