一、图的基本概念
1.图的定义
图是由顶点集合V和边集合E组成的,记为G=(G,V)。图可以只有点没有边,但不能只有边没有点。边:用(x,y)表示为xy之间的一条无向边;用<x,y>表示xy之间的一条有向边,x为有向边的起点,y为有向边的终点
2.图的基本术语
邻接:有边相连的两个顶点之间的关系。存在(x,y)则称xy互为邻接点;存在<x,y>则称x邻接到y,y邻接于x
顶点的度、入度和出度:度是与该顶点相关联的边的数目。入度是该顶点作为终点的有向边的条数,出度是该顶点作为始点的有向边的条数
路径和路径长度:路径是接续的边构成的顶点序列。路径长度是路径上权值的和或者数目之和
完全图:具有n个顶点的无向图有最多的边数,即有n(n-1)/2条边;具有n个顶点的有向图有最多的边数,即有n(n-1)条边
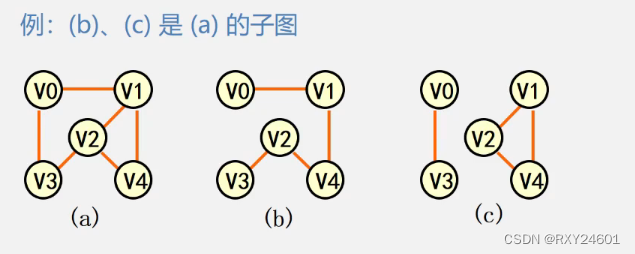
子图:即是原本图的子集
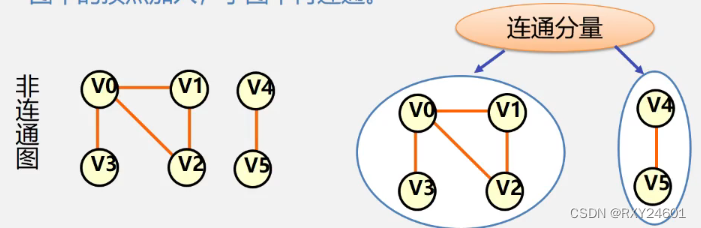
(强)连通图:任意两个顶点u,v之间都存在从u到v的路径
(强)连通分量:无(有)向图的极大连通子图即为连通分量,极大连通子图顶点数目最多,再增加顶点子图不再连通。
生成树:包含图所有顶点的极小连通子图。极小连通子图删除任何一条边子图就不在连通
生成森林:对非连通图,由各个连通分量的生成树的集合
权和网:权是指图的每条边上的某种意义的数值,网是指每条边都有权值的图。
3.图的类型定义
图的数据包括点和边
ADT Graph
{
数据对象V:具有相同特性的数据元素的集合,称为顶点集
数据关系R:是多对多的运算
};二、图的存储结构
1.邻接矩阵的表示法
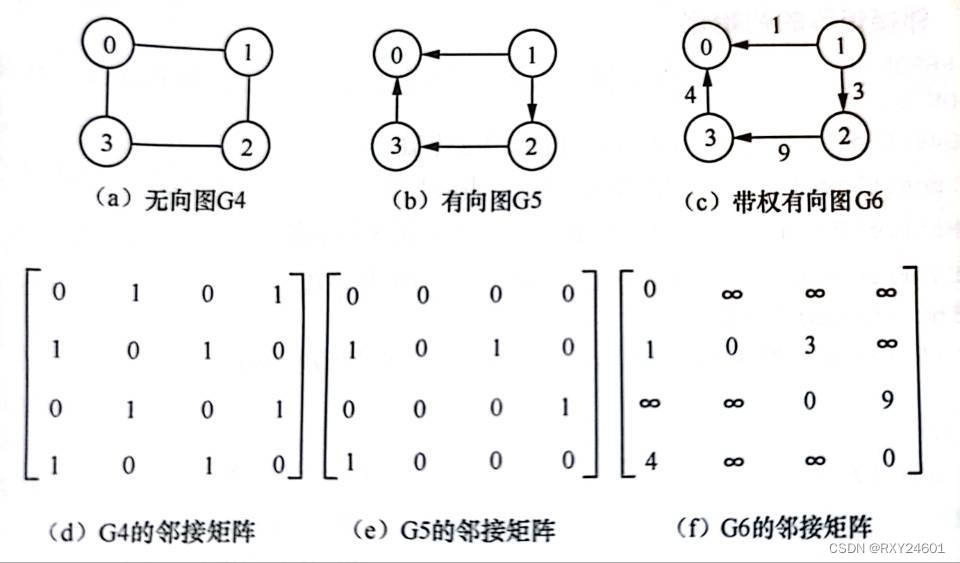
图没有顺序存储结构,但可以借助二维数组来表示元素间的关系。
建立一个顶点表(记录各个顶点信息)和一个邻接矩阵(表示各个顶点之间关系)
矩阵的行数与列数取决与图中的顶点个数


无向图的邻接矩阵是对称的,顶点i的度=第i行(列)中1的个数
有向图中顶点的出度=第i行的元素个数和。顶点的入度=第i列元素之和
在带权无向图中,w(u,v)表示边(u,v)或边(v,u)的权值;在带权有向图,w(u,v)表示边<u,v>的权值。∞表示一个计算机允许的、大于所有边上权值的数。
完全图的邻接矩阵中,对角元素为0,其余为1
邻接矩阵中的元素只有0和1。1代表两点之间由连接,0代表两顶点之间无连接。
2.邻接矩阵的实现
邻接矩阵有两种:不带权图的和网的邻接矩阵。不带权图的邻接矩阵元素取值为0或1,网的邻接矩阵的元素取值为0,∞或者权值。
(1)使用一个三元组(u,v,w)代表一条边,u和v是边上的两个顶点,w是边的权
(2)对于两种邻接矩阵的主对角线元素的三元组(u,u,w)都有w=0
(3)对于无向图的每条无向边(u,v),需存储两条边(u,v)和(v,u)
typedef int MGDataType;
typedef struct mGraph
{
MGDataType nodege;//两顶点间无边时的值
int n;//顶点个数
int e;//边数
MGDataType** a;//二维数组,邻接矩阵
}MGraph;头文件:
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<stdbool.h>
#include<assert.h>
typedef int MGDataType;
typedef struct mGraph
{
MGDataType noEdge;//两顶点间无边时的值
int vertex;//顶点个数
int edge;//边数
MGDataType** a;//二维数组,邻接矩阵
}MGraph;
void MGInit(MGraph* mg, int nSize, MGDataType noEdgeValue);//矩阵初始化
void MGDestory(MGraph* mg);//矩阵销毁
bool MGFind(MGraph* mg, int u, int v);//边的搜索
bool MGInsert(MGraph* mg, int u, int v, MGDataType w);//边的插入
bool MGDelete(MGraph* mg, int u, int v);//边的删除源文件:
#include"MGraph.h"
void MGInit(MGraph* mg, int nSize, MGDataType noEdgeValue)
{
int i, j;
mg->vertex = nSize;
mg->edge = 0;
mg->noEdge = noEdgeValue;
mg->a = (MGDataType**)malloc(sizeof(MGDataType*) * nSize);
if (!mg->a)
{
printf("malloc fail \n");
exit(-1);
}
for (int i = 0; i < mg->vertex; i++)
{
mg->a[i] = (MGDataType*)malloc(sizeof(MGDataType) * nSize);
for (int j = 0; j < mg->vertex; j++)
{
mg->a[i][j] = mg->noEdge;//权值初始默认为0或∞
}
mg->a[i][i] = 0;
}
}
void MGDestory(MGraph* mg)
{
assert(mg);
int i;
for (int i = 0; i < mg->vertex; i++)
{
free(mg->a[i]);
}
free(mg->a);
}
bool MGFind(MGraph* mg, int u, int v)
{
assert(mg);
if (u<0 || v<0 || u>mg->vertex - 1 || v>mg->vertex - 1 || u == v || mg->a[u][v] == mg->noEdge)
{
return false;
}
return true;
}
bool MGInsert(MGraph* mg, int u, int v, MGDataType w)
{
if (u<0 || v<0 || u>mg->vertex - 1 || v>mg->vertex - 1 || u == v )
{
return false;
}
if (mg->a[u][v] != mg->noEdge)//u,v两点之间有边
{
printf("already alive\n");
exit(-1);
}
mg->a[u][v] = w;
mg->edge + 1;
return true;
}
bool MGDelete(MGraph* mg, int u, int v)
{
if (u<0 || v<0 || u>mg->vertex - 1 || v>mg->vertex - 1 || u == v )
{
return false;
}
if (mg->a[u][v] == mg->noEdge)//u,v两点之间无边
{
printf("no vertex\n");
exit(-1);
}
mg->a[u][v] = mg->noEdge;
mg->edge--;
return true;
}邻接矩阵不利于增加和删除结点
空间复杂度为O(N^2),对于稀疏图浪费空间,但对于稠密图特别是完全图十分合算
统计稀疏图中一共有多少边,需要遍历很浪费时间
3.邻接表表示法
邻接表表示法时图的另一种常用的存储表示法。邻接表为图的每一个顶点建立一个单链表。单链表中的每个结点代表一条边,称为边节点
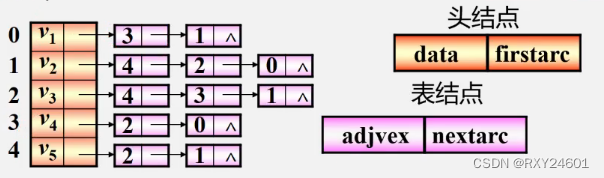
按照编号顺序将顶点数据存储在一维数组中
关联同一顶点的边(以顶点为尾的弧):用线性链表存储
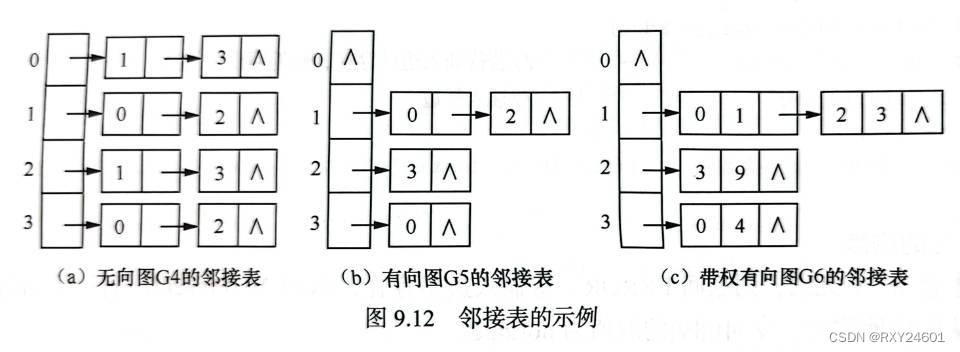 无向图的邻接表不唯一,边结点的顺序可以改变
无向图的邻接表不唯一,边结点的顺序可以改变
若无向图中有n个顶点,e条边,则其邻接表需n个头结点和2e个表结点。适合存储稀疏图。
有向图顶点的出度为单链表中结点的个数
4.邻接表的实现
头文件:
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<stdbool.h>
#include<assert.h>
typedef int LGDataType;
typedef struct eNode
{
int adjVex;//相连的顶点
LGDataType w;//边的权值
struct eNode* next;
}ENode;
typedef struct lGraph
{
int vertex;//顶点个数
int edge;//边数
ENode** a;
}LGraph;
void LGInit(LGraph* lg,int nSize);//矩阵初始化
void LGDestory(LGraph* lg);//矩阵销毁
bool LGFind(LGraph* lg, int u, int v);//边的搜索
bool LGInsert(LGraph* lg, int u, int v, LGDataType w);//边的插入
bool LGDelete(LGraph* lg, int u, int v);//边的删除源文件:
#include"LGraph.h"
void LGInit(LGraph* lg, int nSize)//表初始化
{
lg->vertex = nSize;
lg->edge = 0;
lg->a = (ENode**)malloc(sizeof(ENode*) * nSize);
if (!lg->a)
{
printf("malloc fail\n");
exit(-1);
}
for (int i = 0; i < lg->vertex; i++)
{
lg->a[i] = NULL;//将指针数组a置空
}
}
void LGDestory(LGraph* lg)
{
ENode* front, *behind;
for (int i = 0; i < lg->vertex; i++)
{
front = lg->a[i];
behind = front;
while (front)
{
front = front->next;
free(behind);
behind = front;
}
}
free(lg->a);
}
bool LGFind(LGraph* lg, int u, int v)
{
ENode* p;
if (u<0 || v<0 || u>lg->vertex - 1 || v>lg->vertex - 1 || u == v)
{
return false;
}
p = lg->a[u];
while (p && p->adjVex != v)
{
p = p->next;
}
if (!p)
{
return false;
}
return true;
}
bool LGInsert(LGraph* lg, int u, int v, LGDataType w)
{
ENode* p;
if (u<0 || v<0 || u>lg->vertex - 1 || v>lg->vertex - 1 || u == v)
{
return false;
}
if (LGFind(lg, u, v))
{
printf("already alive\n");
exit(-1);
}
p = (ENode*)malloc(sizeof(ENode));
p->adjVex = v;
p->w = w;
p->next = lg->a[u];//将新的边界点插入单链表的最前面
lg->a[u] = p;
lg->edge++;
return true;
}
bool LGDelete(LGraph* lg, int u, int v)
{
ENode* p, * q;
if (u<0 || v<0 || u>lg->vertex - 1 || v>lg->vertex - 1 || u == v)
{
return false;
}
p = lg->a[u], q = NULL;
while (p && p->adjVex != v)
{
q = p;
p = p->next;
}
if (!p)
{
printf("no vertex\n");
exit(-1);
}
if (q)
{
q->next = p->next;
}
else
{
lg->a[u] - p->next;
}
free(p);
lg->edge--;
return true;
}方便找任一顶点的所有“邻接点”
节约稀疏图的空间:需要N个头指针+2E个结点(每个结点至少2个域)
方便计算任一顶点的度,但对于有向图只能计算出度
5.邻接矩阵域邻接表的关系
(1)联系:
邻接表中每个链表对应于邻接矩阵中的一行,链表中结点个数等于一行中非零元素的个数
(2)区别:
对于任一确定的无向图,邻接矩阵是唯一的,但是邻接表不唯一,链表的链接次序与顶点编号无关
邻接矩阵的空间复杂度为O(N^2),而邻接表的空间复杂度为O(N+e)
三、图的遍历
从图中任一顶点v出发,按照某种次序访问图中的所有顶点,且每个顶点仅访问一次的过程称为图的遍历。
图中可能存在回路,为了避免重复访问设置辅助数组visited,用于标记访问状态,防止被多次访问
1.深度优先遍历(DFS)
连通图的深度优先遍历类似于树的先根遍历,对于同一种图可有多种不同的访问次序

深度优先遍历图的过程本质上是对每个顶点搜索其邻接点的过程。此过程中,每个顶点仅被访问一次,其所消耗的时间取决于图所采用的存储结构。
设图的顶点数为N,边数为e
当采用邻接表表示图,虽然有2e个表结点,但是只需要扫描e个结点即可完成遍历时,DFS算法的时间复杂度为O(N+e)
而采用邻接矩阵表示图时,遍历图中每个顶点都要从头扫描该顶点所在行,DFS算法的时间复杂度为O(N^2)
对于非连通图,一次优先遍历之后,图中必定还有顶点未被访问,需从图中另一个未访问顶点出发再次深度优先遍历,直达图中所有的顶点均被访问为止
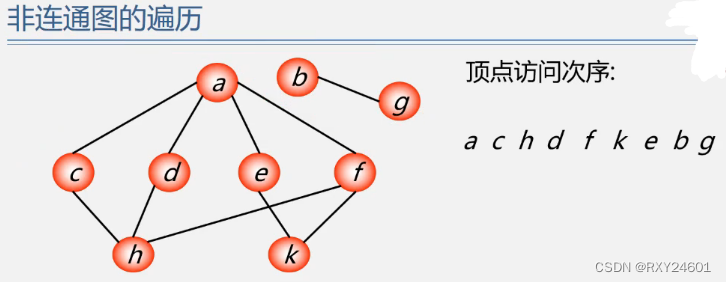
代码实现:
#include"LGraph.h"
void DFS(int v, int visited[], LGraph lg)
{
ENode* neighbor;
printf("%d ", v);
visited[v] = 1;
for (neighbor = lg.a[v]; neighbor; neighbor = neighbor->next)
{
if (!visited[neighbor->adjVex])//如果neighbor尚未访问,则递归调用DFS
{
DFS(neighbor->adjVex, visited, lg);
}
}
}
void DFSGraph(LGraph lg)
{
int i;
int* visited = (int*)malloc(sizeof(int) * lg.vertex);
for (int i = 0; i < lg.vertex; i++)//初始化visited数组
{
visited[i] = 0;
}
for (int i = 0; i < lg.vertex; i++)//逐步遍历检查每一个结点
{
if (!visited[i])//如果未被访问则调用DFS
{
DFS(i, visited, lg);
}
}
free(visited);
}2.广度优先遍历(BFS)
类似于树的层次遍历过程

广度优先遍历需要借助队列来实现,与层序遍历思路类似
代码实现:
#include"LGraph.h"
#include"Queue.h"
void BFS(int v, int visited[], LGraph lg)
{
ENode* neighbor;
Queue q;
QueueInit(&q);
visited[v] = 1;//给顶点v打上访问标记
printf("%d ", v);
QueuePush(&q, v);//放入队列
while (!QueueEmpty(&q))
{
QueueFront(&q,v);
QueuePop(&q);//队首顶点出列
for (neighbor = lg.a[v]; neighbor; neighbor = neighbor->next)//循环遍历所有邻接点
{
if (!visited[neighbor->adjVex])//如果没有被访问则放入队列中
{
visited[neighbor->adjVex] = 1;//将放入队列中的标记
printf("%d ", neighbor->adjVex);
QueuePush(&q, neighbor->adjVex);
}
}
}
}
void BFSGraph(LGraph lg)
{
int* visited = (int*)malloc(sizeof(int) * lg.vertex);
for (int i = 0; i < lg.vertex; i++)
{
visited[i] = 0;//初始时数组visited都为0
}
for (int i = 0; i < lg.vertex; i++)
{
if (!visited[i])
{
BFS(i, visited, lg);
}
}
free(visited);
}3.DFS与BFS算法效率比较
空间复杂度相同,都是O(N)
时间复杂度只与存储结构(邻接矩阵或者邻接表)有关,与搜索路径无关
四、拓扑排序
1.AOV网
用一个有向图表示一个工程的各子工程及其相互制约的关系,其中以顶点表示活动,弧表示活动之间的优先制约关系,称这种有向图为顶点表示活动的网,简称AOV网(Activity On Vertex network)
若从i到j有一条有向路径,则i是j的前驱;j是i的后继。
若<i,j >是网中有向边,则i是j的直接前驱;j是i的直接后继。
AOV网中不允许有回路,如果有回路存在,则表明某项活动以自己为前提条件,这是不符合逻辑的
2.AOV网的拓扑排序
在AOV网没有回路的前提下,我们将全部活动排列成一个线性序列,使得若AOV 网中有弧<i,j>存在,则在这个序列中,i一定排在j的前面,具有这种性质的线性序列称为拓扑有序序列,相应的拓扑有序排序的算法称为拓扑排序。
拓扑排序步骤:①在图中选择一个入度为0的顶点②从图中删除此顶点,以及该顶点的所有出边③重复前两个步骤,直至不存在入度为0的顶点
一个AOV网的拓扑序列不是唯一的

检测AOV网中是否存在环的方法:对有向图构造其顶点的拓扑有序序列,如果网中所有顶点都在它的拓扑有序序列中,则该AOV网必定不存在环。
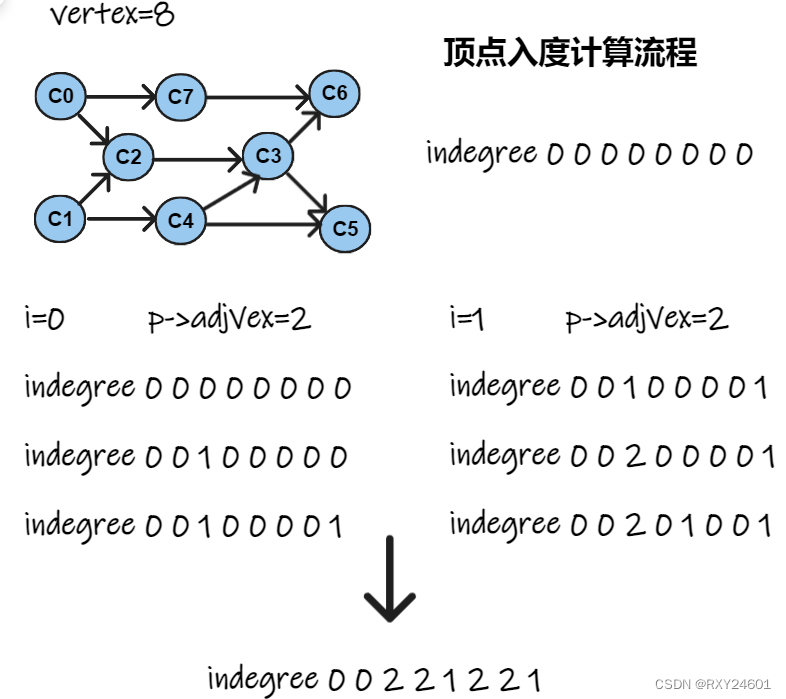
代码实现:
#include"LGraph.h"
#include"Stack.h"
//degree计算顶点入度
void Degree(int* inDegree, LGraph* lg)
{
ENode* p;
for (int i = 0; i < lg->vertex; i++)//初始化degree数组
{
inDegree[i] = 0;
}
for (int i = 0; i < lg->vertex; i++)
{
for (p = lg->a[i]; p; p = p->next)//检查以顶点i为尾的所有邻接点
{
inDegree[p->adjVex]++;//将顶点i的邻接点p->adjVex的入度加1
}
}
}
//AOV网拓扑排序
void TopoSort(int* topo, LGraph* lg)
{
ENode* p;
ST s;
int* inDegree = (int*)malloc(sizeof(int) * lg->vertex);
StackInit(&s);
Degree(inDegree, lg);//计算顶点的入度
for (int i = 0; i < lg->vertex; i++)
{
if (!inDegree[i])//入度为0的进栈
{
StackPush(&s, i);
}
}
for (int i = 0; i < lg->vertex; i++)
{
if (StackEmpty(&s))
{
printf("loop in Graph\n");
exit(-1);
}
else
{
int j = StackTop(&s);//顶点出栈
StackPop(&s);
topo[i] = j;//将顶点j输出到拓扑序列中
printf("d ", j);
for (p = lg->a[j]; p; p = p->next)//检查顶点j为尾的所有邻接点
{
int k = p->adjVex;
inDegree[k]--;
if (!inDegree[k])//顶点入度为0,入栈
{
StackPush(&s, k);
}
}
}
}
}
五、关键路径
1.AOE网
用一个有向图表示一个工程的各子工程及其相互制约的关系,以弧表示活动,以顶点表示活动的开始或结束事件,称这种有向图为边表示活动的网,简称为AOE网(Activity On Edge)
AOE网中只有一个出度为0的顶点,用来表示工程的结束,称为汇点。
AOE网中同样不存在回路
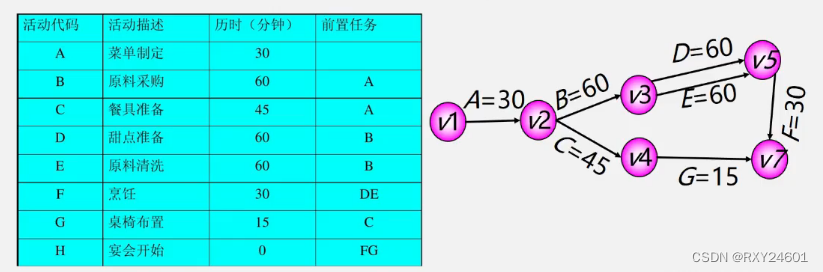
2.AOE网的关键路径
对于AOE网有两个问题:①完成整个工程至少需要多少时间②那些活动是影响工程进度的关键
关键路径:路径长度最长的路径
路径长度:路径上各个活动持续时间的总和
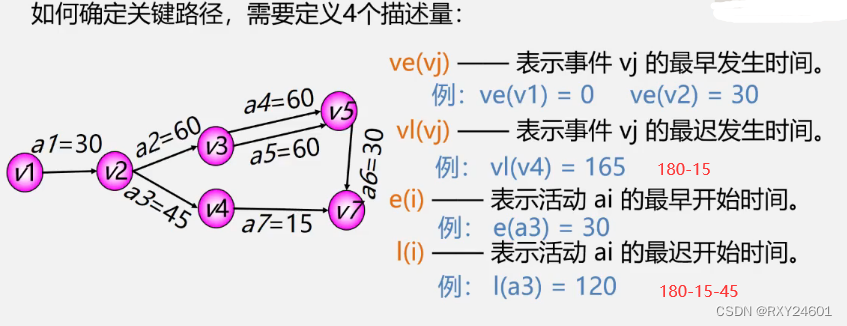
关键活动:关键路径上的活动,即l(i)==e(i)的活动
(1)最早发生时间

w为权值,最早发生时间取决于其直接前驱时间用时最久的边
最早发生时间从源点向汇点计算
(2)最迟发生时间

最迟发生时间从汇点向源点计算
求关键路径的步骤:
①求最早发生时间ve②求最迟发生时间vl③求最早开始时间e(i)④求最晚开始时间l(i)⑥求时间余量l(i)-e(i)
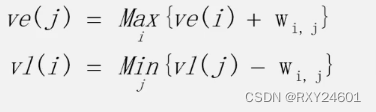

以下图为例求关键路径
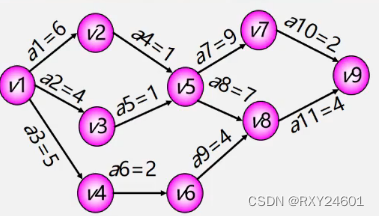
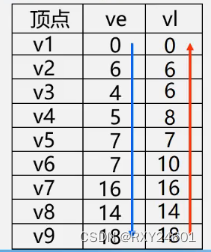
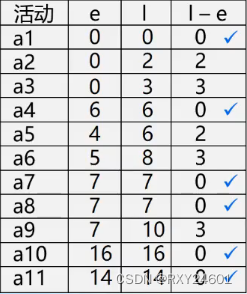
代码实现:
//AOE网Eearly函数
void Eearly(int* eearly, int* topo, LGraph lg)
{
ENode* p;
for (int i = 0; i < lg.vertex; i++)//初始化数组eearly
{
eearly[i] = 0;
}
for (int i = 0; i < lg.vertex; i++)
{
int k = topo[i];//获取拓扑排序中的顶点序号k
for (p = lg.a[k]; p; p = p->next)
{
if (eearly[p->adjVex] < eearly[k] + p->w)//更新eearly
{
eearly[p->adjVex] = eearly[k] + p->w;
}
}
}
}
//AOE网Elate函数
void Elate(int* elate, int* topo, int longest, LGraph lg)
{
ENode* p;
for (int i = 0; i < lg.vertex; i++)
{
elate[i] = longest;
}
for (int i = lg.vertex - 2; i > -1; i--)
{
int j = topo[i];
for (p = lg.a[j]; p; p = p->next)
{
if (elate[j] > elate[p->adjVex] - p->w)
{
elate[j] = elate[p->adjVex] - p->w;
}
}
}
}六、最小代价生成树
1.最小代价生成树的基本概念
生成树:所有顶点均由边连接在一起,并且不存在回路的图
一个图可以有许多棵不同的生成树
生成树的顶点个数与图的顶点个数相同;生成树是图的极小连通子图 ;一个有n个顶点的连通图的生成树一定有n-1条边;生成树中增加任意一条边则必然形成回路
最小生成树:给定一个无向网,在该网的所有生成树中,各边权值之和最少的生成树为最小生成树,也叫最小代价生成树
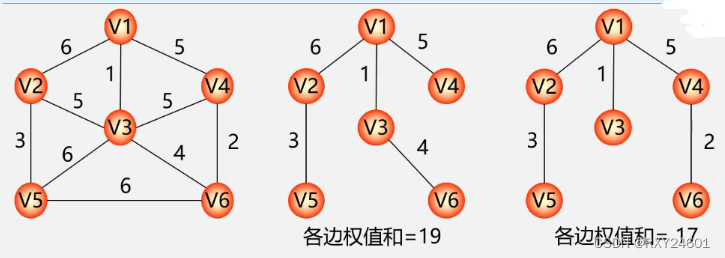
MST性质:
最小生成树(Minimum Spanning Tree, MST)是一种特殊的图
①在生成树的构造过程中,图中n个顶点分属两个集合:已落在生成树上的顶点集U;尚未落在生成树上的顶点集V-U。V为全集
②在所有连通U的顶点和V-U的顶点的边中选取权值最小的边
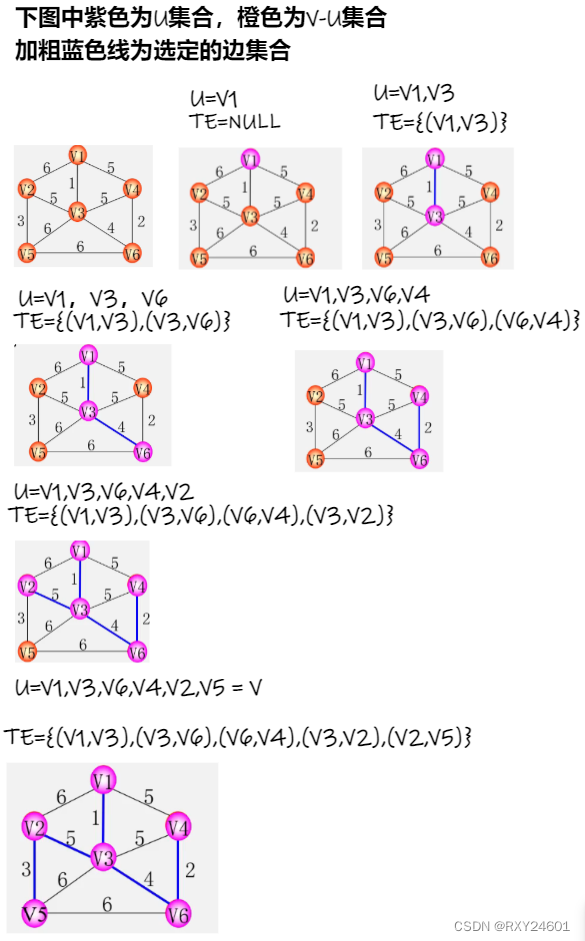
以上图为例:假设V1属于集合U中,V2-V6属于集合V-U中。使两个集合连接的顶点包括{(V1,V2),(V1,V3),(V1,V4)},其(V1,V3)顶点的边权值为1,最小。
2.普利姆算法

每次找一个顶点,这个顶点与U集合之间相连的边有最小的权值
每一个顶点都要找其他的所有顶点
代码实现:
①一维数组closeVex[v]存放与v距离最近的顶点编号u,距离最近是指边(u,v)是所有与顶点v关联的边中权值最小的边
②一维数组lowWeight[v]存放边(clowVex[v],v)的权值
③一维数组isMark[v]用于标记顶点v是否在生成树中,如果isMark[v]=0表示未加入生成树,否则表示已经加入生成树中
#include"LGraph.h"
#define INFTY 32767
bool Prim(int k, int* closeVex, LGDataType* lowWeight, LGraph lg)
{
ENode* p;
LGDataType min;
int* isMark = (int*)malloc(sizeof(int) * lg.vertex);
if (k<0 || k>lg.vertex - 1)
{
printf("k<0 k>lg.vertex\n");
exit(-1);
}
for (int i = 0; i < lg.vertex; i++)
{
closeVex[i] = -1;
lowWeight[i] = INFTY;
isMark[i] = 0;
}
//源点加入生成树
lowWeight[k] = 0;
closeVex[k] = k;
isMark[k] = 1;
//选择其余n-1条边加入生成树
for (int i = 1; i < lg.vertex; i++)
{
for (p = lg.a[k]; p; p = p->next)
{
int j = p->adjVex;
if ((!isMark[j]) && (lowWeight[j] > p->w))//更新生成树外顶点的lowWeight值
{
lowWeight[j] = p->w;
closeVex[j] = k;
}
}
min = INFTY;
for (int j = 0; i < lg.vertex; j++)//寻找生成树外顶点中,具有最小lowWeight值的顶点k
{
if((!isMark[j]) && (lowWeight[j] < min))
{
min = lowWeight[j];
k = j;
}
}
isMark[k] = 1;//将顶点k加入生成树
}
for (int i = 0; i < lg.vertex; i++)
{
printf("%d ", closeVex[i]);
printf("%d ", i);
printf("%d ", lowWeight[i]);
printf("/n");
}
return true;
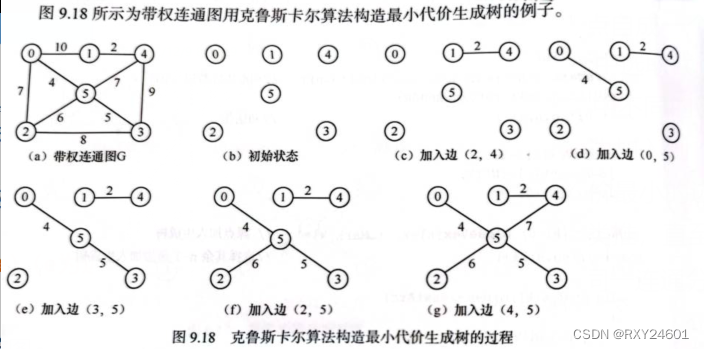
}3.克鲁斯卡尔算法

克鲁斯卡尔算法采用直接选取权值最小的边加入,是否选取该边的判断条件为加入边后是否会形成环,如果形成环那么就选择其他边
代码实现:
①一维数组edgeset:从邻接矩阵中获取所有边保存在数组edgeset中,并用排序算法对边按照权值进行递增排序
②一维数组vexset:用于表示个顶点所属的连通分量,若两个顶点属于不同的连通分量,则将这两个顶点关联的边加到生成树中时不会形成回路
#include"MGraph.h"
//定义结构体--边
typedef struct edge
{
int u;
int v;
MGDataType w;
}Edge;
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int mini = begin;
int maxi = begin;
for (int i = begin + 1; i <= end; i++)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[begin], &a[mini]);
if (maxi == begin)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
begin++;
end--;
}
}
void Kruscal(MGraph mg)
{
int* vexSet = (int*)malloc(sizeof(int) * mg.vertex);
Edge* edgeset = (Edge*)malloc(sizeof(Edge) * mg.vertex);
int k = 0;
for (int i = 0; i < mg.vertex; i++)
{
for (int j = 0; j < i; j++)
{
if (mg.a[i][j] != 0 && mg.a[i][j] != mg.noEdge)
{
edgeset[k].u = i;
edgeset[k].v = j;
edgeset[k].w = mg.a[i][j];
}
}
}
SelectSort(edgeset, mg.edge / 2);
for (int i = 0; i < mg.vertex; i++)
{
vexSet[i] = i;
}
k = 0;
int j = 0;
while (k < mg.vertex - 1)
{
int u1 = edgeset[j].u;
int v1 = edgeset[j].v;
int vs1 = vexSet[u1];
int vs2 = vexSet[v1];
if (vs1 != vs2)
{
printf("%d ,%d ,%d\n", edgeset[j].u, edgeset[j].v, edgeset[j].w);
k++;
for (int i = 0; i < mg.vertex; i++)
{
if (vexSet[i] == vs2)
{
vexSet[i] = vs1;
}
j++;
}
}
}
}4.两种算法的比较
| 算法名 | 普利姆算法 | 克鲁斯卡尔算法 |
| 算法思想 | 选择点 | 选择边 |
| 时间复杂度 | O(N^2) N为顶点数 | O(NlogN) N为边数 |
| 适应范围 | 稠密图 | 稀疏图 |
七、最短路径
1.最短路径问题
路径问题大概有以下几种:
-
确定起点的最短路径问题:已知起始点,求起点到其他任意点最短路径的问题。即单源最短路径问题。
-
确定终点的最短路径问题:与确定起点的问题相反,该问题是已知终点,求最短路径的问题。在无向图(即点之间的路径没有方向的区别)中该问题与确定起点的问题完全等同,在有向图(路径间有确定的方向)中该问题等同于把所有路径方向反转的确定起点的问题。
-
确定起点终点的最短路径问题:已知起点和终点,求任意两点之间的最短路径。即多源最短路径问题。
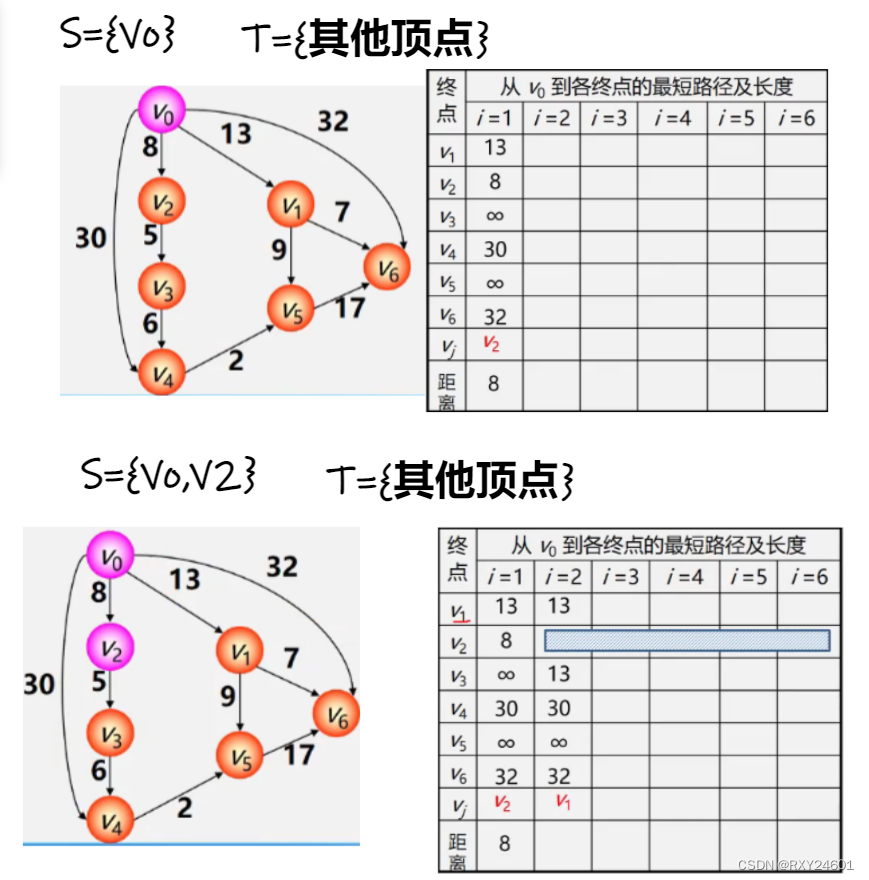
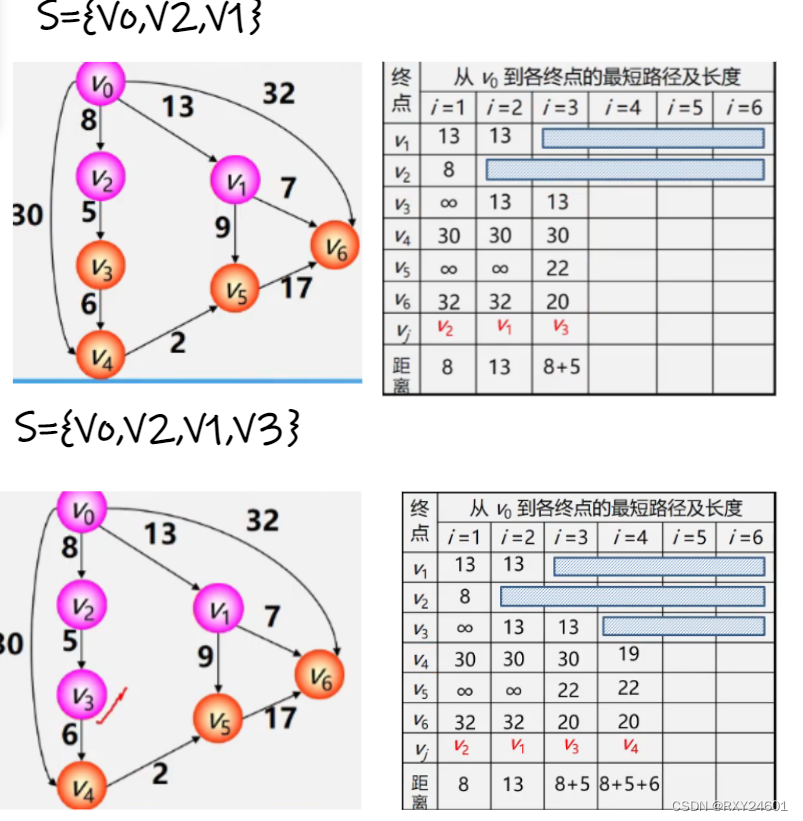
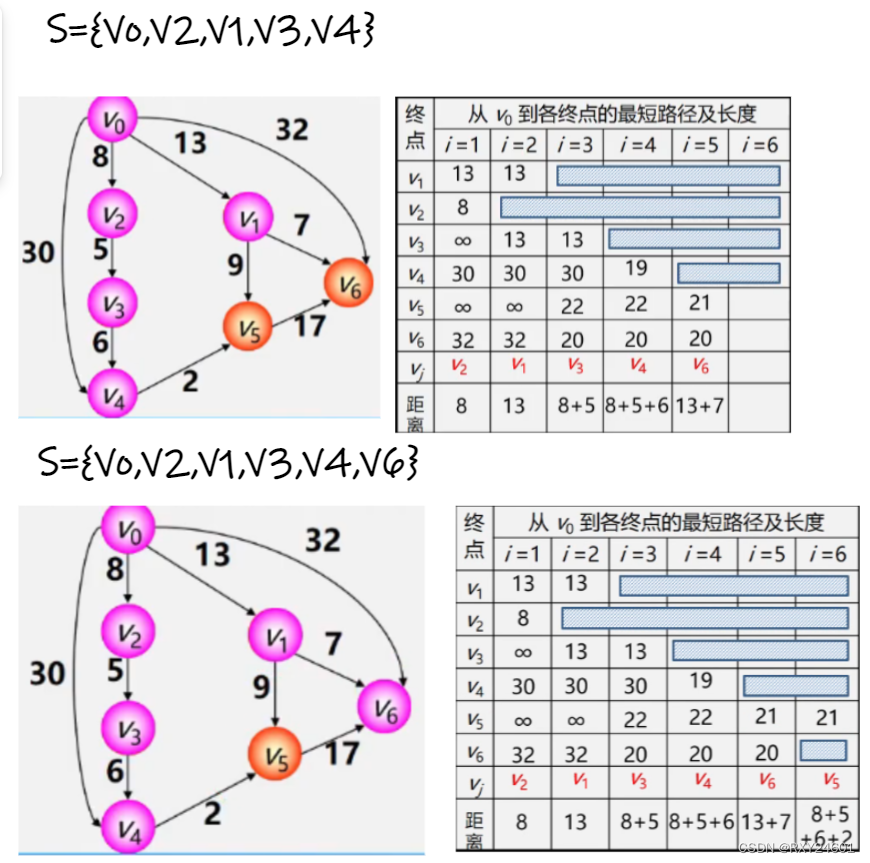
2.单源最短路径问题
①初始化:先找出源点Vo到各个终点Vk的直达路径(Vo,Vk),即通过一条边到达的路径
②选择:从这些路径中,找出一条长度最短的路径(Vo,U)
③更新:对其余各条路径进行适当调整
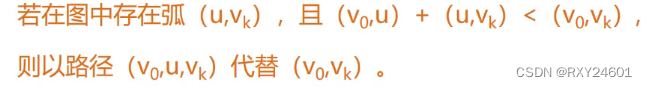
D[i]用于表示从Vo到Vi边的权值,如果不存在用∞表示
D[j]=Min{D[i]}
代码实现:
//迪杰斯特拉算法
#include"MGraph.h"
#define INFETY 32767
int Choose(int* d, int* s, int n)
{
MGDataType min;
min = INFETY;
int minpos = -1;
for (int i = 0; i < n; i++)
{
if (d[i] < min && !s[i])
{
min = d[i];
minpos = i;
}
}
return minpos;
}
bool Dijkstra(int v, MGDataType* d, int* path, MGraph mg)
{
if (v<0 || v>mg.vertex - 1)
{
printf(" error\n");
exit(-1);
}
int* s = (int*)malloc(sizeof(int) * mg.vertex);
for (int i = 0; i < mg.vertex; i++)
{
s[i] = 0;
d[i] = mg.a[v][i];
if (1 != v && d[i] < INFETY)
{
path[i] = v;
}
else
{
path[i] = -1;
}
}
s[v] = 1;
d[v] = 0;
for (int i = 0; i < mg.vertex - 1; i++)
{
int k = Choose(d, s, mg.vertex);
if (k == 1)
{
continue;
}
s[k] = 1;
printf("%d ", k);
for (int w = 0; w < mg.vertex; w++)
{
if (!s[w] && d[k] + mg.a[k][w] < d[w])
{
d[w] = d[k] + mg.a[k][w];
path[w] = k;
}
}
}
for (int i = 0; i < mg.vertex; i++)
{
printf("%d ", d[i]);
}
return true;
}3.所有顶点之间的最短路径
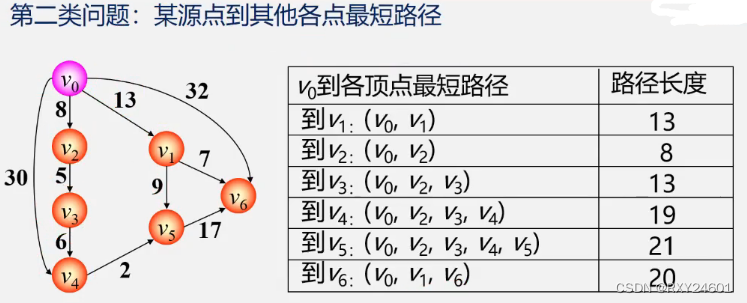
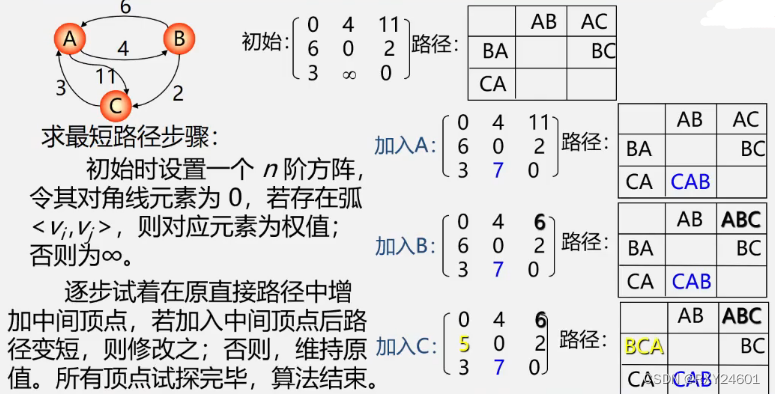
方法一:每次以一个顶点为源点,重复执行迪杰斯特拉算法N次
方法二:弗洛伊德算法
代码实现:
//弗洛伊德算法
#include"MGraph.h"
#define INFTY 32767
void Floyd(MGraph mg)
{
MGDataType** d = (MGDataType**)malloc(mg.vertex * sizeof(MGDataType*));
int** p = (int**)malloc(sizeof(int) * mg.vertex);
for (int i = 0; i < mg.vertex; i++)
{
d[i] = (MGDataType*)malloc(mg.vertex * sizeof(MGDataType));
p[i] = (int*)malloc(mg.vertex * sizeof(int));
for (int j = 0; j < mg.vertex; j++)
{
d[i][j] = mg.noEdge;
p[i][j] = 0;
}
}
for (int i = 0; i < i < mg.vertex; i++)
{
for (int j = 0; j < mg.vertex; j++)
{
d[i][j] = mg.a[i][j];
if (i != j && mg.a[i][j] < INFTY)
{
p[i][j] = i;
}
else
{
p[i][j] = 0;
}
}
}
for (int k = 0; k < mg.vertex; k++)
{
for (int i = 0; i < mg.vertex; i++)
{
for (int j = 0; j < mg.vertex; j++)
{
if (d[i][k] + d[k][j] < d[i][j])
{
d[i][j] = d[i][k] + d[k][j];
p[i][j] = p[k][j];
}
}
}
}
for (int i = 0; i < mg.vertex; i++)
{
for (int j = 0; j < mg.vertex; j++)
{
printf("%d ", d[i][j]);
}
printf("\n");
}
}