1.简述
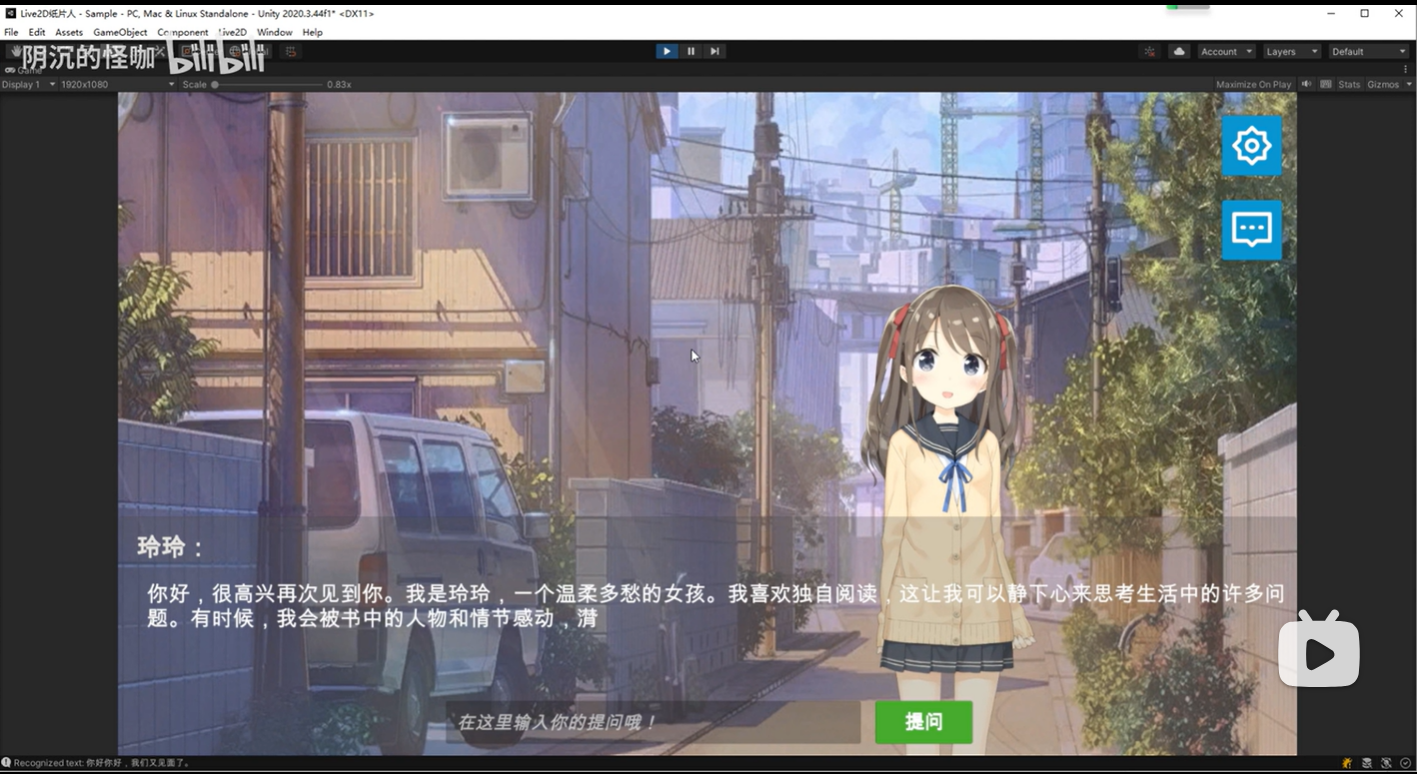
如题所述,这个小项目是在unity引擎端,使用了chatgpt+微软azure的一个AI二次元女友对话的项目,实现原理也比较简单,即在unity端实现AI二次元女友的交互界面,接入chatgpt-3.5-turbo的api接口,借助chatgpt的自然语言生成能力,作为这个项目的聊天引擎。聊天功能也比较简单,通过接入微软Azure的语音识别api,在unity客户端接入麦克风采集说话的声音,调用语音识别api返回识别的文本,再通过拼接prompt,调用chatgpt接口,得到回复信息文本之后,再调用azure的语音合成接口,得到音频,最后播放出来,关联live2d模型的口型同步,这样基本上就实现了我希望的效果。这个项目我已经在Gitee开源有一段时间了,本来也有计划要写一些相关文档的,一直没有时间,这次就抽时间把项目里涉及到的Azure语音服务部分的代码整理成文档,也方面想学习这个小伙伴一个参考。
2.微软Azure
微软 Azure是微软基于云计算的操作系统,是微软“软件和服务”技术的名称。Windows Azure的主要目标是为开发者提供一个平台,帮助开发可运行在云服务器、数据中心、Web和PC上的应用程序。 说这么多,其实Azure就是微软提供给开发者各种云服务,其中就包括了AI相关的服务,比如语音服务。
Azure地址传送门:
云计算服务 | Microsoft Azure
关于Azure服务的使用,需要首先申请一个Azure的账号,申请账号成功之后,就可以申请使用Azure的各种服务了。Azure提供了不少免费的服务,对于白嫖党来说简直就是福利。但是这里有一点需要说明了,就是申请Azure账号的时候,需要填写一个visa或万事达的信用卡账号,如果没有的话,就申请不了账号了,这个可能会是一个门槛。注册成功之后,微软会给你的账号赠送200美元的体验金,这个有效期有一年的时间,也算是一个相当好的福利了,就是信用卡的问题,必须解决,这里算是一个经验提示吧。
在申请语音服务的订阅过程,第一个月可以申请试用的订阅,有效期是一个月的时间,可以免费提供50万字的语音合成额度,基本上自己用完全无压力。到第二个月就需要更新订阅了,更新完订阅,语音服务依然可以选择免费的F0订阅,享受50万字每月的额度。
3.Azure语音合成的代码实现
在Azure语音的代码实现方面,微软官方实际上提供有sdk,其中也有适用unity的插件包可用,插件的传送门如下:
安装语音 SDK - Azure Cognitive Services | Microsoft Learn
不过本文所介绍的代码实现并不是使用上述插件的代码实现,主要是因为之前我用这个sdk发现发布到webgl就不可用了,只能windows使用,这个有点坑,所以就查阅了Azure的官方文档,找到了restful api的实现方式,所以就实现了调用restful api实现语音识别和语音合成的代码,在这边文章做一下记录和分享,下面,分享一下具体的代码实现。
3.1.Azure语音识别
实现语音识别这部分功能,首先在unity端是有获取麦克风声音的接口,可以直接获取电脑接入的麦克风,采集声音信息的功能的,所以只需要关注如何使用restful api调用Azure语音识别api的方法就可以了。
Azure语音识别的api地址:
https://{region}.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=zh-CN
这里面,region的值就是你在Azure语音服务里订阅的地区码,比如我订阅的是东亚地区的,所以这个地区码就是“eastasia”。
public string subscriptionKey = string.Empty;//服务令牌
public string serviceRegion = string.Empty;//地区码
public string language = string.Empty;//语言
/// <summary>
/// 识别语音
/// </summary>
/// <param name="audioData"></param>
/// <param name="_callback"></param>
/// <returns></returns>
private IEnumerator SendAudioData(byte[] audioData, Action<string> _callback)
{
// Construct the request URL
string url = "https://" + serviceRegion + ".stt.speech.microsoft.com/speech/recognition/" +
mode + "/cognitiveservices/v1?language=" + language;
// Create the request object
UnityWebRequest request = UnityWebRequest.Post(url, "application/octet-stream");
request.SetRequestHeader("Ocp-Apim-Subscription-Key", subscriptionKey);
request.SetRequestHeader("Content-Type", "audio/wav; codec=audio/pcm; samplerate=44100");
// Attach the audio data to the request
request.uploadHandler = new UploadHandlerRaw(audioData);
request.uploadHandler.contentType = "application/octet-stream";
// Send the request and wait for the response
yield return request.SendWebRequest();
// Check for errors
if (request.result != UnityWebRequest.Result.Success)
{
Debug.LogError("Speech recognition request failed: " + request.error);
yield break;
}
// Parse the response JSON and extract the recognition result
string json = request.downloadHandler.text;
SpeechRecognitionResult result = JsonUtility.FromJson<SpeechRecognitionResult>(json);
string recognizedText = result.DisplayText;
// Display the recognized text in the console
Debug.Log("Recognized text: " + recognizedText);
_callback(recognizedText);
}用到的工具类:
[System.Serializable]
public class SpeechRecognitionResult
{
public string RecognitionStatus;
public string DisplayText;
}using UnityEngine;
using System.IO;
public static class WavUtility
{
/// <summary>
/// Converts an AudioClip to a byte array containing a WAV file.
/// </summary>
public static byte[] FromAudioClip(AudioClip clip)
{
// Create a new WAV file
MemoryStream stream = new MemoryStream();
BinaryWriter writer = new BinaryWriter(stream);
// Write the WAV header
writer.Write(new char[4] { 'R', 'I', 'F', 'F' });
writer.Write(36 + clip.samples * 2);
writer.Write(new char[4] { 'W', 'A', 'V', 'E' });
writer.Write(new char[4] { 'f', 'm', 't', ' ' });
writer.Write(16);
writer.Write((ushort)1);
writer.Write((ushort)clip.channels);
writer.Write(clip.frequency);
writer.Write(clip.frequency * clip.channels * 2);
writer.Write((ushort)(clip.channels * 2));
writer.Write((ushort)16);
writer.Write(new char[4] { 'd', 'a', 't', 'a' });
writer.Write(clip.samples * 2);
// Write the audio data
float[] samples = new float[clip.samples];
clip.GetData(samples, 0);
int intMax = 32767; // max value for a 16-bit signed integer
for (int i = 0; i < clip.samples; i++)
{
writer.Write((short)(samples[i] * intMax));
}
// Clean up
writer.Close();
byte[] wavBytes = stream.ToArray();
stream.Close();
return wavBytes;
}
}
3.2.Azure语音合成
Azure语音合成部分的功能,需要将合成的文本,POST到Azure语音合成的restful api服务即可实现语音的合成功能,代码示例如下:
public string subscriptionKey = string.Empty;//服务令牌
public string serviceRegion = string.Empty;//地区码
public string language = string.Empty;//语言
/// <summary>
/// 朗读的角色
/// </summary>
[Header("朗读声音设置")]
public string voiceName = "zh-CN-XiaomoNeural";
/// <summary>
/// 情绪
/// </summary>
[Header("朗读的情绪设置" +
"")]
public string style = "chat";//chat cheerful angry excited sad
/// <summary>
/// restful api语音合成
/// </summary>
/// <param name="_msg"></param>
/// <param name="_callback"></param>
/// <returns></returns>
private IEnumerator GetVoice(string _msg, Action<AudioClip> _callback)
{
string textToSpeechEndpoint = string.Format("https://{0}.tts.speech.microsoft.com/cognitiveservices/v1", serviceRegion);
//发送报文
string textToSpeechRequestBody = GenerateTextToSpeech(language, voiceName, style, 2, _msg);
using (UnityWebRequest speechRequest = new UnityWebRequest(textToSpeechEndpoint,"POST"))
{
byte[] data = System.Text.Encoding.UTF8.GetBytes(textToSpeechRequestBody);
speechRequest.uploadHandler = (UploadHandler)new UploadHandlerRaw(data);
speechRequest.downloadHandler = (DownloadHandler)new DownloadHandlerAudioClip(speechRequest.uri, AudioType.MPEG);
speechRequest.SetRequestHeader("Ocp-Apim-Subscription-Key", subscriptionKey);
speechRequest.SetRequestHeader("X-Microsoft-OutputFormat", "audio-16khz-32kbitrate-mono-mp3");
speechRequest.SetRequestHeader("Content-Type", "application/ssml+xml");
yield return speechRequest.SendWebRequest();
if (speechRequest.responseCode == 200)
{
AudioClip audioClip = DownloadHandlerAudioClip.GetContent(speechRequest);
_callback(audioClip);
}
else
{
Debug.LogError("语音合成失败: " + speechRequest.error);
}
}
}语音合成设置参数中,涉及到朗读的声音,具体的声音编码可已到Azure的官方文档查阅,有详细的介绍,这里需要注意,有些声音的选择需要同步修改语言编码,这个根据官方文档来就可以了。官方文档地址:
Text to speech overview - Speech service - Azure Cognitive Services | Microsoft Learn
4.结束语
本文介绍了一下微软Azure语音服务的restful api的使用代码示例。我在自己的开源项目AI二次元小姐姐聊天机器人里使用到了相关的技术,只停留在应用方面。当然在服务调用方法方面,官方也提供有多个不同语言的代码示例以及SDK,大家可以根据自己的实际需求选择技术方案。
上述的代码示例并不是完整可以直接执行的代码,我只是将我的项目代码中,涉及到微软语音服务的关键部分提取出来了,源码还有部分unity客户端的代码逻辑,所以上面的代码实现仅供有编码基础的朋友参考,不要直接丢到自己的项目里使用。
对我这个项目感兴趣的朋友,可以上我的B站号查看,我也做有详细的教程,相关源码可以在的哔哩哔哩主站找到相关视频,在视频介绍以及评论区获取。
【chatGPT+unity+Azure+VRoid】AI女友对话,源码分享,零基础手搓二次元妹子,打造专属的AI女友不是梦