认识priority_queue
1、priority_queue(优先级队列)是一种容器适配器,底层是一个完全二叉树的大堆(堆总是一颗完全二叉树,根结点最大的堆叫做大堆;根结点最小的堆叫做小堆),头文件在queue中,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。不按照先进先出,优先级高的先出,默认数字大的优先级高。
2、类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
3、优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,priority_queue提供一组特定的成员函数来访问其元素。元素从特定容器的尾部弹出,其称为优先队列的顶部。
4、底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
- empty():检测容器是否为空
- size():返回容器中有效元素个数
- front():返回容器中第一个元素的引用
- push_back():在容器尾部插入元素
- pop_back():删除容器尾部元素
5、标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
6、需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。
priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意:默认情况下priority_queue是大堆。
容器适配器都是不支持遍历的,不支持范围for。
| 函数声明 | 接口说明 |
|---|---|
| priority_queue()/priority_queue(first, last) | 构造一个空的优先级队列 |
| empty( ) | 检测优先级队列是否为空,是返回true,否则返回 false |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(val) | 在优先级队列中插入元素val |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
库中priority_queue的定义:
template <class T, class Container = vector<T>, class Compare = less<typename Container::value_type> > class priority_queue;
默认使用vector作为底层容器。
使用:
#include <queue>
#include <iostream>
using namespace std;
int main()
{
priority_queue<int> pq;
//默认数字大的优先级高,即默认大堆
//也可以通过指定模板参数从而让数字小的优先级高,即变成小堆
//priority_queue<int, vector<int>, greater<int>> pq;
for (int i = 0; i < 10; i++)
{
pq.push(i);
}
cout << pq.size() << endl;//输出队列中元素个数 10
while (!pq.empty())//判断是否为空
{
cout << pq.top() << " ";//队头的元素
pq.pop();//队头元素出队列
}
//输出9 8 7 6 5 4 3 2 1 0
//如果用小堆实现输出0 1 2 3 4 5 6 7 8 9
return 0;
}
如果想要使优先级队列中小的优先级更高,则可以借助仿函数**greater<int>**,包含在头文件functional中。
priority_queue<int, vector<int>, greater<int>> pq;
仿函数
仿函数都需要重载一个()。仿函数就是重载了一个(),让对象可以像函数一样去使用。
我们来定义一个仿函数:
template<class T>
struct Less {
bool operator()(const T& l1, const T& l2)
{
return l1 < l2;
}
};
在Less类中我们重载了(),使其成为了能够比较大小的一个运算符:
#include <iostream>
using namespace std;
template<class T>
struct Less {
bool operator()(const T& l1, const T& l2)
{
return l1 < l2;
}
};
int main()
{
Less<int> LessFunc;
cout << LessFunc(2, 3) << endl;//输出1
return 0;
}
如果只看cout << LessFunc(2, 3) << endl,我们可能会认为LessFunc是一个函数或者函数指针,但是LessFunc是个Less<int>类型的对象,所以我们叫做仿函数。对象可以像函数一样去使用,本质是调用了operator(),运算符重载。
仿函数是为了解决函数指针void(*ptr)()太复杂的问题。
greater<int>和less<int>都是库里面写好的,priority_queue默认使用的是less<int>。
堆算法
**堆的底层是一个数组,**我们先认识两种堆的算法:向上调整法和向下调整法。
向上调整法
向上调整法基本思想(以大堆为例):
将插入结点作为目标结点,将目标结点和其父结点比较,如果目标结点的值比父结点的值大,则交换目标结点和父结点的位置,交换之后目标结点就变为父结点,然后继续向上调整;如果目标结点的值比父结点的值小,停止调整说明此时该完全二叉树已经是大堆了。
例:我们在下面的大堆最后位置插入数据100,通过向上调整法调整之后使其仍然是一个大堆:
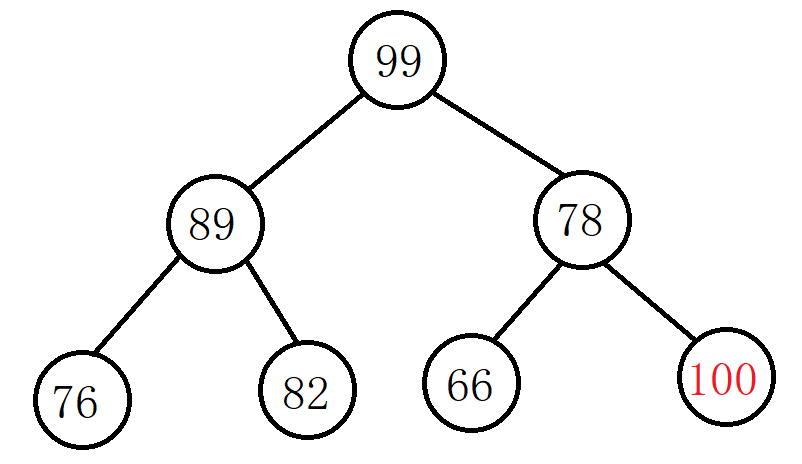
此时目标结点就是刚插入的结点,值为100,比父结点值大,所以要将目标结点和父结点交换位置:
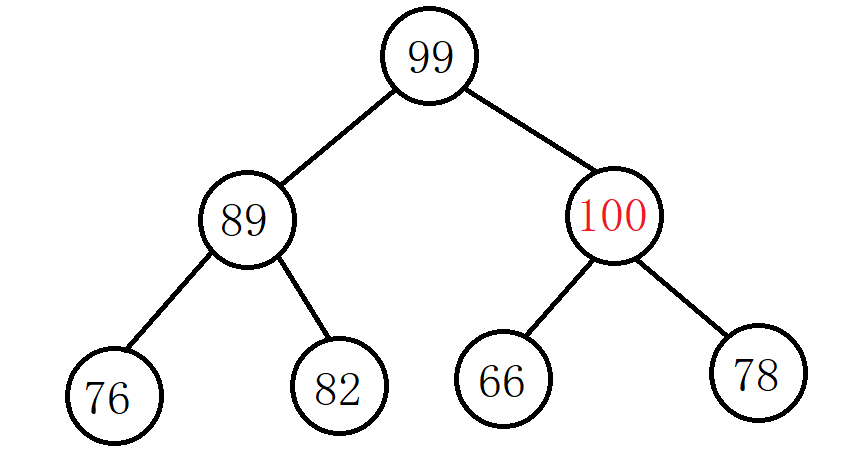
继续比较并调整,此时目标结点值为100,比父结点值大,交换两者位置:
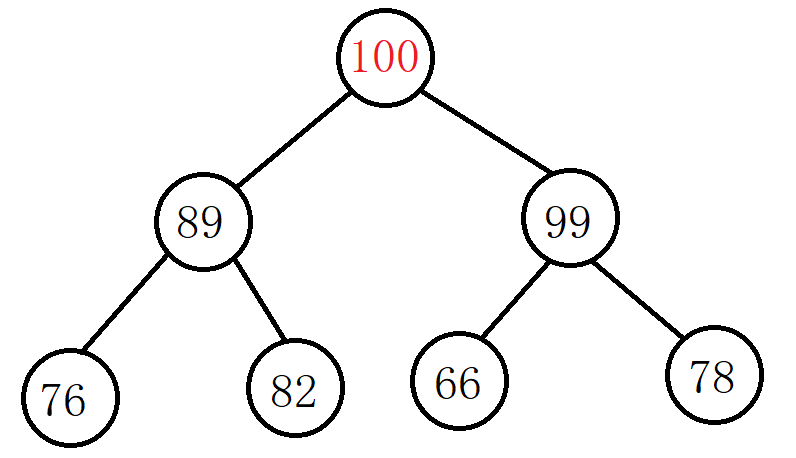
此时调整完成,该树已经调整成大堆了。
向上调整代码如下:
//大堆的向上调整法
void adjust_up(vector<int>& v, int child)
{
//找出父结点
int parent = (child - 1) / 2;
//当child大于0时一直循环,当child = 0时说明已经调整完
while (child > 0)
{
if (v[parent] < v[child])//当parent值小于child值时调整
{
swap(v[parent], v[child]);//交换父结点和子结点位置
child = parent;//此时child等于parent
parent = (child - 1) / 2;//重新求父结点
}
//此时说明已经是大堆了,不需要调整了
else
{
break;
}
}
}
向下调整法
使用堆的向下调整算法有一个前提条件:待向下调整的结点的左子树和右子树都必须为大堆。
向下调整法基本思想(以大堆为例):
将目标结点与自己较大的子结点进行比较,如果目标结点的值比它较大的子结点的值小,则交换目标结点与其较大的子结点的位置,并将较大子结点当作新的目标结点继续向下调整;如果目标结点的值比它较大子结点的值大,则停止向下调整,说明该树已经是大堆。
例:使用向下调整法将下面的完全二叉树调整成大堆(根结点的左右子树已经是大堆)。
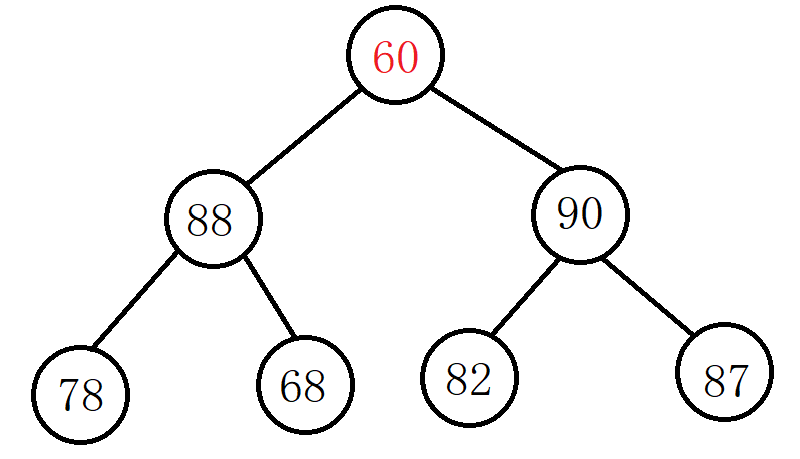
通过上图我们可以看出其根结点小于右孩子,所以将根结点和右孩子交换:
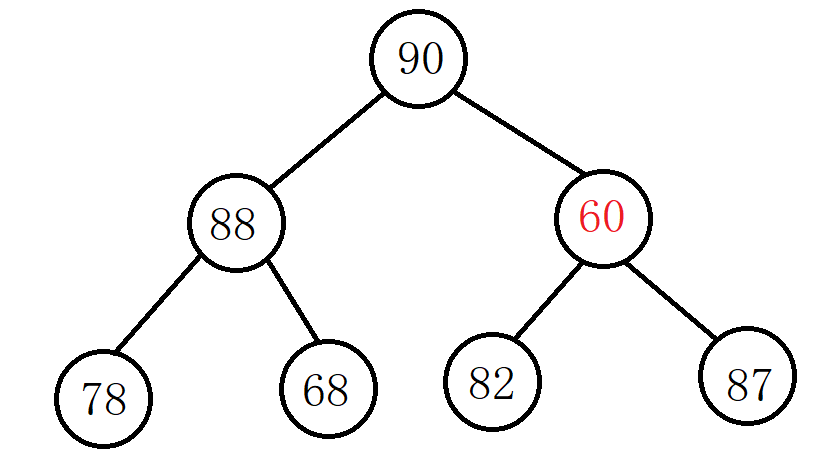
经过上次交换之后,值为60的结点还是小于自己的右孩子,再交换:
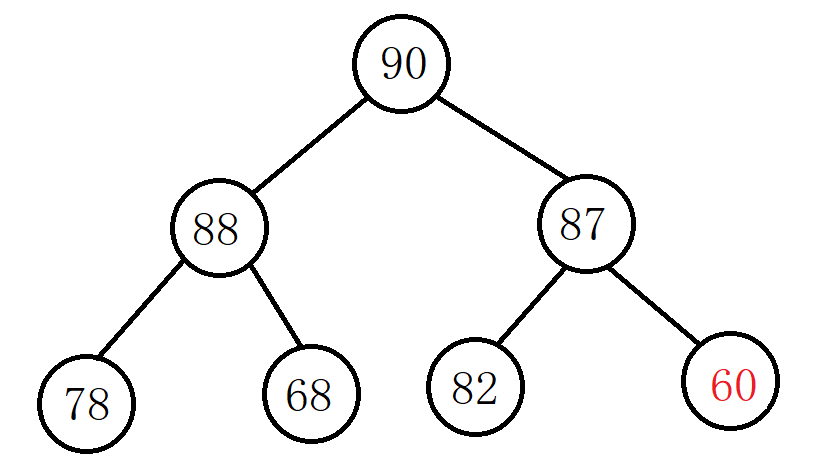
此时已经调整为大堆。
向下调整法的代码:
//大堆的向下调整
void adjust_down(vector<int>& v,int n,int parent)
{
int child = (parent * 2) + 1;//求出左孩子
while (child < n)
{
//找到最大孩子结点且保证child合法
if (child + 1 < n && v[child + 1] > v[child])
{
child++;
}
if (v[child] > v[parent])//判断孩子结点是否大于父结点
{
swap(v[child], v[parent]);//交换结点位置
parent = child;//重新赋值
child = (parent * 2) + 1;//重新求出孩子结点
}
//已经是大堆
else
{
break;
}
}
}
模拟实现priority_queue
优先级队列默认给的容器vector,大堆,数字大的优先级高。
优先级队列底层实际上就是堆结构,通过堆算法实现优先级,堆的底层是一个数组。
我们知道了堆算法的实现,那么priority_queue的模拟实现就变得简单了,其他的操作直接复用容器的函数就可以实现,模拟实现代码如下:
namespace Niu {
template<class T,class Container = vector<T>>
class priority_queue {
public:
//大堆的向上调整法
void adjust_up(int child)
{
//找出父结点
int parent = (child - 1) / 2;
//当child大于0时一直循环,当child = 0时说明已经调整完
while (child > 0)
{
if (_con[parent] < _con[child])//当parent值小于child值时调整
{
swap(_con[parent], _con[child]);//交换父结点和子结点位置
child = parent;//此时child等于parent
parent = (child - 1) / 2;//重新求父结点
}
//此时说明已经是大堆了,不需要调整了
else
{
break;
}
}
}
//大堆的向下调整
void adjust_down(int parent)
{
int child = (parent * 2) + 1;//求出左孩子
while (child < _con.size())
{
//找到最大孩子结点且保证child合法
if (child + 1 < _con.size() && _con[child + 1] > _con[child])
{
child++;
}
if (_con[parent] < _con[child])//判断孩子结点是否大于父结点
{
swap(_con[child], _con[parent]);//交换结点位置
parent = child;//重新赋值
child = (parent * 2) + 1;//重新求出孩子结点
}
//已经是大堆
else
{
break;
}
}
}
//插入元素
void push(const T& val)
{
_con.push_back(val);//尾插
adjust_up(_con.size() - 1);//向上调整
}
//删除元素
void pop()
{
swap(_con[0],_con[_con.size() - 1]);//交换第一个和最后一个结点位置
_con.pop_back();//尾删,删除优先级最高的结点
adjust_down(0);//向下调整
}
//返回优先级最高的元素
const T& top()
{
return _con[0];
}
//返回数据个数
size_t size()
{
return _con.size();
}
//判断是否为空
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
测试:
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
#include "priority_queue.h"
int main()
{
Niu::priority_queue<int> pq;
//默认数字大的优先级高,即默认大堆
for (int i = 0; i < 10; i++)
{
pq.push(i);
}
cout << pq.size() << endl;//输出队列中元素个数 10
while (!pq.empty())//判断是否为空
{
cout << pq.top() << " ";//队头的元素
pq.pop();//队头元素出队列
}
//输出9 8 7 6 5 4 3 2 1 0
//如果用小堆实现输出0 1 2 3 4 5 6 7 8 9
return 0;
}
数值大的优先级高,priority_queue是一个适配器,当我们将底层模板参数更改为deque<T>仍然能运行。
template<class T,class Container = deque<T>>
那此时默认的是数值大的优先级高,如果想让数值小的优先级高可以通过仿函数实现。
注意仿函数定义时>是小堆,<是大堆,定义仿函数的时候运算符要和类名保持一致。
在下面的代码中定义了两个仿函数,同时将向上调整法和向下调整法中的大小比较通过仿函数实现(还可以传一个匿名对象调用仿函数):
namespace Niu {
//定义大堆
template<class T>
struct less {
bool operator()(const T& a, const T& b)
{
return a < b;
}
};
//定义小堆
template<class T>
struct greater {
bool operator()(const T& a, const T& b)
{
return a > b;
}
};
template<class T,class Container = vector<T>,class Compare = less<T>>
class priority_queue {
public:
//大堆的向上调整法
void adjust_up(int child)
{
Compare com; //此时我们可以使用重载的运算符
//找出父结点
int parent = (child - 1) / 2;
//当child大于0时一直循环,当child = 0时说明已经调整完
while (child > 0)
{
//if (_con[parent] < _con[child])//当parent值小于child值时调整
if(com(_con[parent],_con[child]))
{
swap(_con[parent], _con[child]);//交换父结点和子结点位置
child = parent;//此时child等于parent
parent = (child - 1) / 2;//重新求父结点
}
//此时说明已经是大堆了,不需要调整了
else
{
break;
}
}
}
//大堆的向下调整
void adjust_down(int parent)
{
Compare com; //此时我们可以使用重载的运算符
int child = (parent * 2) + 1;//求出左孩子
while (child < _con.size())
{
//找到最大孩子结点且保证child合法
//if (child + 1 < _con.size() && _con[child + 1] > _con[child])
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
child++;
}
//if ( _con[parent] < _con[child])
if (com(_con[parent], _con[child]))//判断孩子结点是否大于父结点
//还可以传一个匿名对象调用if (com()(_con[parent] , _con[child]))
{
swap(_con[child], _con[parent]);//交换结点位置
parent = child;//重新赋值
child = (parent * 2) + 1;//重新求出孩子结点
}
//已经是大堆
else
{
break;
}
}
}
private:
Container _con;
};
}
测试:
int main()
{
//通过指定模板参数从而让数字小的优先级高,即变成小堆
Niu::priority_queue<int, vector<int>, greater<int>> pq;
for (int i = 0; i < 10; i++)
{
pq.push(i);
}
cout << pq.size() << endl;//输出队列中元素个数 10
while (!pq.empty())//判断是否为空
{
cout << pq.top() << " ";//队头的元素
pq.pop();//队头元素出队列
}
//输出0 1 2 3 4 5 6 7 8 9
return 0;
}
不是内置类型也可以用模板参数比较大小,但是我们要重载>和<运算符,方便在调用仿函数时调用,如下面的日期类代码:
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
friend ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
private:
int _year;
int _month;
int _day;
};
void test_priority_queue2()
{
// 大堆,需要用户在自定义类型中提供<的重载
priority_queue<Date> q1;
q1.push(Date(2018, 10, 29));
q1.push(Date(2018, 10, 28));
q1.push(Date(2018, 10, 30));
cout << q1.top() << endl;
}
我们实现了>和<运算符重载,这样在自定义类型的优先级队列中,当我们push时,在push函数中调用adjust_up函数,而在adjust_up函数中有仿函数的使用,仿函数中有类型比较,整个过程如下图:
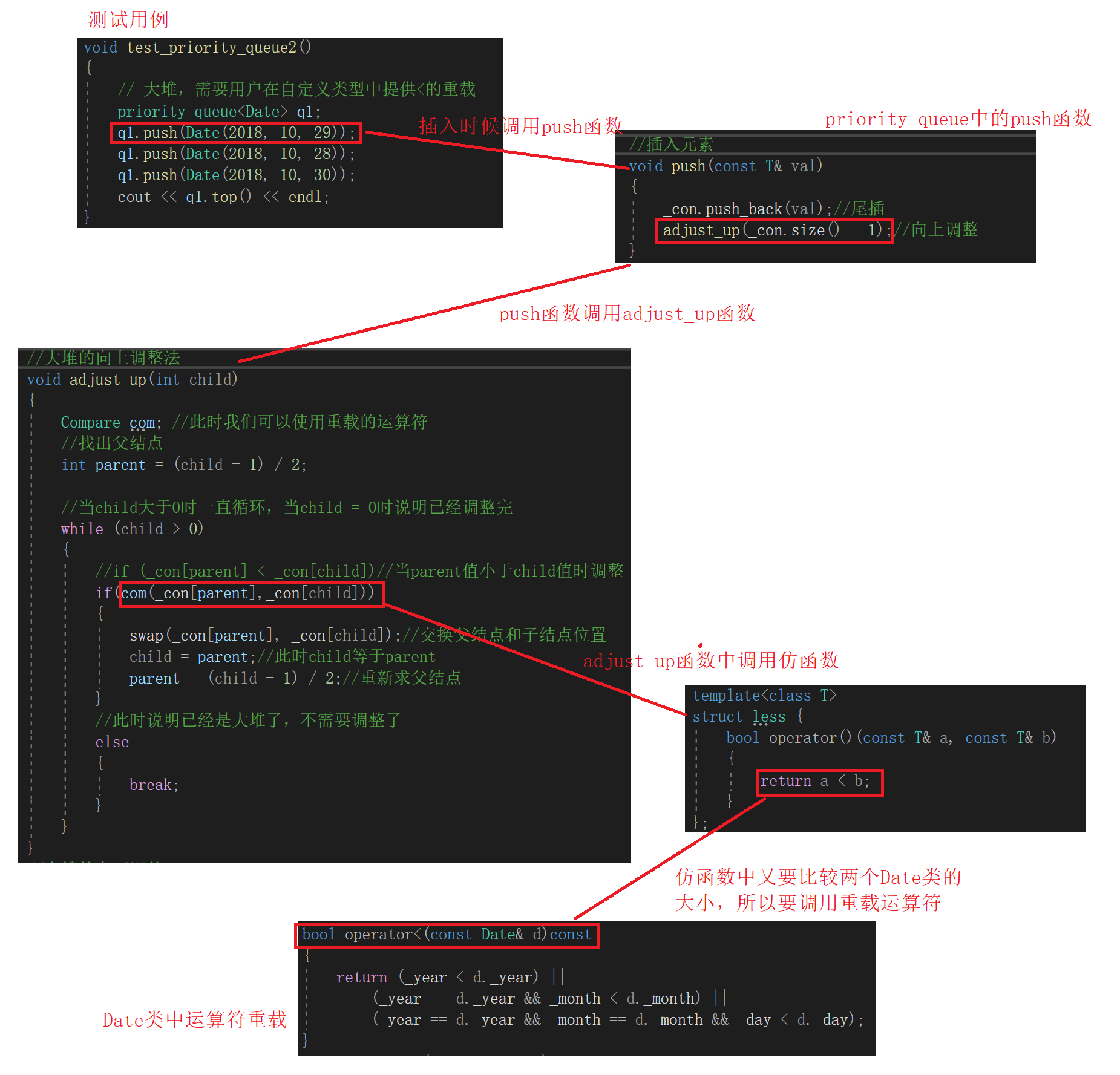
那此时如果我们想比较两个Date*类型所指向的日期大小我们应该怎么办呢?
Date*可以比较大小,但是不是我们想要的,new出来的地址没有先大先小的概念,完全没有规律。所以我们也可以通过仿函数来比较。
实现两个日期类指针的仿函数(注意要在日期类下面定义):
class PDateLess{
public:
bool operator()(const Date* p1, const Date* p2)
{
return *p1 < *p2;
}
};
class PDateGreater{
public:
bool operator()(const Date* p1, const Date* p2)
{
return *p1 > *p2;
}
};
测试:
void test_priority_queue2()
{
// 大堆,需要用户在自定义类型中提供<的重载
priority_queue<Date> q1;
q1.push(Date(2018, 10, 29));
q1.push(Date(2018, 10, 28));
q1.push(Date(2018, 10, 30));
cout << q1.top() << endl;
//输出2018-10-30
//priority_queue<Date*,vector<Date*>,PDateLess> q2;//大堆
priority_queue<Date*, vector<Date*>, PDateGreater> q2;//小堆
q2.push(new Date(2018, 10, 29));
q2.push(new Date(2018, 10, 28));
q2.push(new Date(2018, 10, 30));
cout << *(q2.top()) << endl;//返回值为日期指针类型,所以要解引用
//输出2018-10-28
}