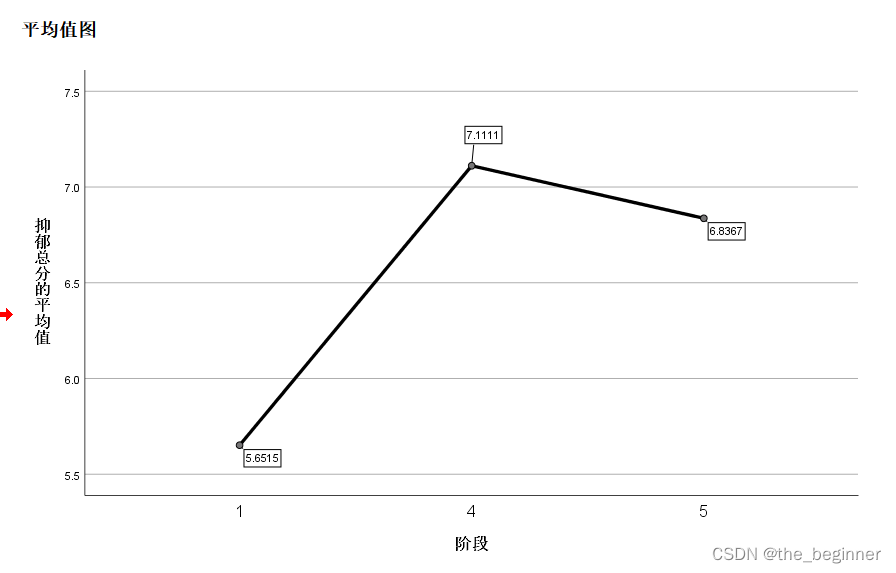
DolphinScheduler 如果是在3.0.5 及之前的版本,没办法支持 S3 的协议的
当你按照文档配置之后,运行启动之后,在master 和 worker 节点,都会出现 缺包的依赖问题。
那这个问题在什么版本修复了呢?
3.0.6...
那 3.0.6 按照文档中描述的配置,可以启动资源中心么?
答案是否定的,因为文档中的配置信息和代码压根对应不上,为此我去翻了下源码,查了大概1个小时,看明白版本迭代后带来的变化了
笔者主要是采用的 K8S 的方式进行部署的,配置文件则需要依据 K8S部署的标准进行处理,主要可以参考官方的文档的一些要求。
对于资源中心这块的配置,按照以前的文档,则会是这样的一个版本:
3.0.5 之前的版本,核心配置:
resource.storage.type: S3
fs.defaultFS: s3a://dolphinscheduler
aws.access.key.id: flink_minio_root
aws.secret.access.key: flink_minio_123456
aws.region: us-east-1
aws.endpoint: http://10.233.7.78:9000conf:
common:
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path: /tmp/dolphinscheduler
# resource storage type: HDFS, S3, NONE
resource.storage.type: S3
# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.upload.path: /dolphinscheduler
# whether to startup kerberos
hadoop.security.authentication.startup.state: false
# java.security.krb5.conf path
java.security.krb5.conf.path: /opt/krb5.conf
# login user from keytab username
login.user.keytab.username: hdfs-mycluster@ESZ.COM
# login user from keytab path
login.user.keytab.path: /opt/hdfs.headless.keytab
# kerberos expire time, the unit is hour
kerberos.expire.time: 2
# resource view suffixs
#resource.view.suffixs: txt,log,sh,bat,conf,cfg,py,java,sql,xml,hql,properties,json,yml,yaml,ini,js
# if resource.storage.type: HDFS, the user must have the permission to create directories under the HDFS root path
hdfs.root.user: hdfs
# if resource.storage.type: S3, the value like: s3a://dolphinscheduler; if resource.storage.type: HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
fs.defaultFS: s3a://dolphinscheduler
aws.access.key.id: flink_minio_root
aws.secret.access.key: flink_minio_123456
aws.region: us-east-1
aws.endpoint: http://10.233.7.78:9000下段的公共配置信息,
RESOURCE_STORAGE_TYPE: "S3"
RESOURCE_UPLOAD_PATH: "/dolphinscheduler"
FS_DEFAULT_FS: "s3a://dolphinscheduler"
FS_S3A_ENDPOINT: "http://10.233.7.78:9000"
FS_S3A_ACCESS_KEY: "flink_minio_root"
FS_S3A_SECRET_KEY: "flink_minio_123456"common:
## Configmap
configmap:
DOLPHINSCHEDULER_OPTS: ""
DATA_BASEDIR_PATH: "/tmp/dolphinscheduler"
RESOURCE_STORAGE_TYPE: "S3"
RESOURCE_UPLOAD_PATH: "/dolphinscheduler"
FS_DEFAULT_FS: "s3a://dolphinscheduler"
FS_S3A_ENDPOINT: "http://10.233.7.78:9000"
FS_S3A_ACCESS_KEY: "flink_minio_root"
FS_S3A_SECRET_KEY: "flink_minio_123456"
HADOOP_SECURITY_AUTHENTICATION_STARTUP_STATE: "false"
JAVA_SECURITY_KRB5_CONF_PATH: "/opt/krb5.conf"
LOGIN_USER_KEYTAB_USERNAME: "hdfs@HADOOP.COM"
LOGIN_USER_KEYTAB_PATH: "/opt/hdfs.keytab"
KERBEROS_EXPIRE_TIME: "2"
HDFS_ROOT_USER: "hdfs"
RESOURCE_MANAGER_HTTPADDRESS_PORT: "8088"
YARN_RESOURCEMANAGER_HA_RM_IDS: ""
YARN_APPLICATION_STATUS_ADDRESS: "http://ds1:%s/ws/v1/cluster/apps/%s"
YARN_JOB_HISTORY_STATUS_ADDRESS: "http://ds1:19888/ws/v1/history/mapreduce/jobs/%s"
DATASOURCE_ENCRYPTION_ENABLE: "false"
DATASOURCE_ENCRYPTION_SALT: "!@#$%^&*"
SUDO_ENABLE: "true"
# dolphinscheduler env
HADOOP_HOME: "/opt/soft/hadoop"
HADOOP_CONF_DIR: "/opt/soft/hadoop/etc/hadoop"
SPARK_HOME1: "/opt/soft/spark1"
SPARK_HOME2: "/opt/soft/spark2"
PYTHON_HOME: "/usr/bin/python"
JAVA_HOME: "/usr/local/openjdk-8"
HIVE_HOME: "/opt/soft/hive"
FLINK_HOME: "/opt/soft/flink"
DATAX_HOME: "/opt/soft/datax/bin/datax.py"以上的配置信息,如果从3.0.6 的src 中的配置文件,去查阅相关的 values.yaml 配置信息,发现是一模一样!
但是,当你部署后,开始启动,就报错了,会告知你,无法启动资源中心服务,因为 空指针...
嗯,到这里,我也懵了,啥都是按照文档配置的,为毛会出现空指针?
ok,以下就是我翻阅源码的过程
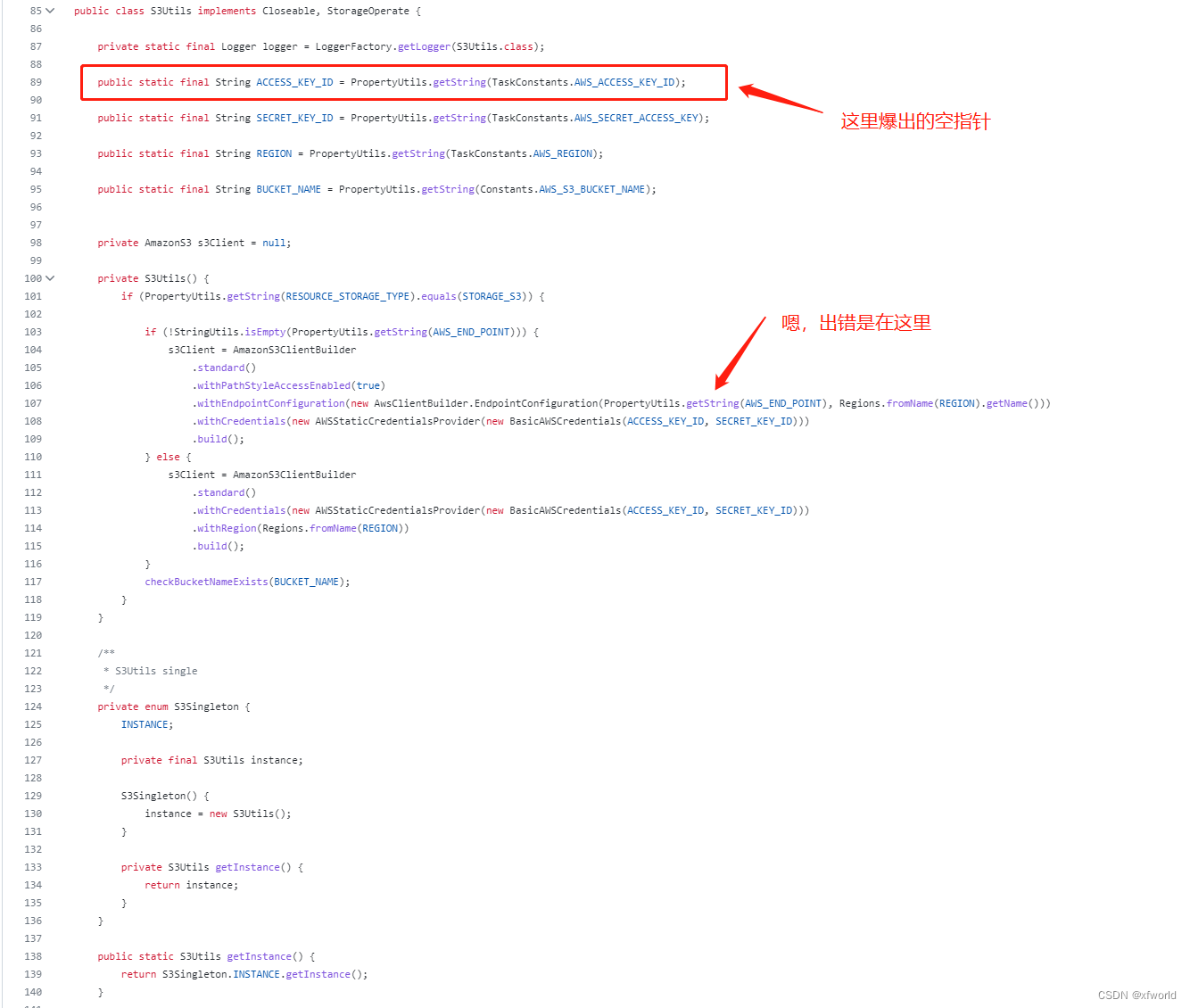
然后翻阅这个常量信息
常量路径
dolphinscheduler/dolphinscheduler-task-plugin/dolphinscheduler-task-api/src/main/java/org/apache/dolphinscheduler/plugin/task/api/TaskConstants.java
主要配置:
/**
* aws config
*/
public static final String AWS_ACCESS_KEY_ID = "resource.aws.access.key.id";
public static final String AWS_SECRET_ACCESS_KEY = "resource.aws.secret.access.key";
public static final String AWS_REGION = "resource.aws.region";发现和文档完全对不上,咋办?参数都不一样了....
没什么好办法,继续找文档支持
新款的配置信息,很容易就看到,支持了一堆
源码地址:
https://github.com/apache/dolphinscheduler/blob/7973324229826d1b9c7db81e14c89c8b5d621c28/deploy/kubernetes/dolphinscheduler/values.yaml#L152
- S3
- OSS
- GCS
- ABS
conf:
common:
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path: /tmp/dolphinscheduler
# resource storage type: HDFS, S3, OSS, GCS, ABS, NONE
resource.storage.type: S3
# resource store on HDFS/S3 path, resource file will store to this base path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path: /dolphinscheduler
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id: minioadmin
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key: minioadmin
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region: ca-central-1
# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name.
resource.aws.s3.bucket.name: dolphinscheduler
# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn
resource.aws.s3.endpoint: http://minio:9000
# alibaba cloud access key id, required if you set resource.storage.type=OSS
resource.alibaba.cloud.access.key.id: <your-access-key-id>
# alibaba cloud access key secret, required if you set resource.storage.type=OSS
resource.alibaba.cloud.access.key.secret: <your-access-key-secret>
# alibaba cloud region, required if you set resource.storage.type=OSS
resource.alibaba.cloud.region: cn-hangzhou
# oss bucket name, required if you set resource.storage.type=OSS
resource.alibaba.cloud.oss.bucket.name: dolphinscheduler
# oss bucket endpoint, required if you set resource.storage.type=OSS
resource.alibaba.cloud.oss.endpoint: https://oss-cn-hangzhou.aliyuncs.com
# if resource.storage.type=HDFS, the user must have the permission to create directories under the HDFS root path
resource.hdfs.root.user: hdfs
# if resource.storage.type=S3, the value like: s3a://dolphinscheduler; if resource.storage.type=HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
resource.hdfs.fs.defaultFS: hdfs://mycluster:8020
# whether to startup kerberos
hadoop.security.authentication.startup.state: false
# java.security.krb5.conf path
java.security.krb5.conf.path: /opt/krb5.conf
# login user from keytab username
login.user.keytab.username: hdfs-mycluster@ESZ.COM
# login user from keytab path
login.user.keytab.path: /opt/hdfs.headless.keytab
# kerberos expire time, the unit is hour
kerberos.expire.time: 2
# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port: 8088
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarn.resourcemanager.ha.rm.ids: 192.168.xx.xx,192.168.xx.xx
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
yarn.application.status.address: http://ds1:%s/ws/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address: http://ds1:19888/ws/v1/history/mapreduce/jobs/%s
# datasource encryption enable
datasource.encryption.enable: false
# datasource encryption salt
datasource.encryption.salt: '!@#$%^&*'
# data quality option
data-quality.jar.name: dolphinscheduler-data-quality-dev-SNAPSHOT.jar
# Whether hive SQL is executed in the same session
support.hive.oneSession: false
# use sudo or not, if set true, executing user is tenant user and deploy user needs sudo permissions; if set false, executing user is the deploy user and doesn't need sudo permissions
sudo.enable: true
# development state
development.state: false
# rpc port
alert.rpc.port: 50052
# set path of conda.sh
conda.path: /opt/anaconda3/etc/profile.d/conda.sh
# Task resource limit state
task.resource.limit.state: false
# mlflow task plugin preset repository
ml.mlflow.preset_repository: https://github.com/apache/dolphinscheduler-mlflow
# mlflow task plugin preset repository version
ml.mlflow.preset_repository_version: "main"
# way to collect applicationId: log, aop
appId.collect: log未发布的文档片段
https://github.com/apache/dolphinscheduler/blob/7973324229826d1b9c7db81e14c89c8b5d621c28/docs/docs/zh/guide/resource/configuration.md?plain=1#L40

以上的这些信息并不代表3.0.6的版本支持了,只代表了新版的能够支持,继续寻找对应版本可以支持的参数,终于在配置列表中找到了
https://github.com/apache/dolphinscheduler/blob/3.0.6-release/docs/docs/zh/architecture/configuration.md?plain=1

于是按照以上寻到的各种配置,叠加在一起后,就变成下面的样子:
conf:
common:
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path: /dolphinscheduler/tmp
# resource storage type: HDFS, S3, NONE
resource.storage.type: S3
# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.upload.path: /dolphinscheduler
# whether to startup kerberos
hadoop.security.authentication.startup.state: false
# java.security.krb5.conf path
java.security.krb5.conf.path: /opt/krb5.conf
# login user from keytab username
login.user.keytab.username: hdfs-mycluster@ESZ.COM
# login user from keytab path
login.user.keytab.path: /opt/hdfs.headless.keytab
# kerberos expire time, the unit is hour
kerberos.expire.time: 2
# resource view suffixs
#resource.view.suffixs: txt,log,sh,bat,conf,cfg,py,java,sql,xml,hql,properties,json,yml,yaml,ini,js
# if resource.storage.type: HDFS, the user must have the permission to create directories under the HDFS root path
hdfs.root.user: hdfs
# if resource.storage.type: S3, the value like: s3a://dolphinscheduler; if resource.storage.type: HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
resource.storage.upload.base.path: /dolphinscheduler
fs.defaultFS: s3a://dolphinscheduler
resource.aws.access.key.id: flink_minio_root
resource.aws.secret.access.key: flink_minio_123456
resource.aws.region: us-east-1
resource.aws.s3.bucket.name: dolphinscheduler
resource.aws.s3.endpoint: http://10.233.7.78:9000
# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port: 8088
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarn.resourcemanager.ha.rm.ids: 192.168.xx.xx,192.168.xx.xx
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
yarn.application.status.address: http://ds1:%s/ws/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address: http://ds1:19888/ws/v1/history/mapreduce/jobs/%s
# datasource encryption enable
datasource.encryption.enable: false
# datasource encryption salt
datasource.encryption.salt: '!@#$%^&*'
# data quality option
data-quality.jar.name: dolphinscheduler-data-quality-3.0.6.jar
#data-quality.error.output.path: /tmp/data-quality-error-data
common:
## Configmap
configmap:
DOLPHINSCHEDULER_OPTS: ""
DATA_BASEDIR_PATH: "/dolphinscheduler/tmp"
RESOURCE_STORAGE_TYPE: "S3"
RESOURCE_UPLOAD_PATH: "/dolphinscheduler"
FS_DEFAULT_FS: "s3a://dolphinscheduler"
FS_S3A_ENDPOINT: "http://10.233.7.78:9000"
FS_S3A_ACCESS_KEY: "flink_minio_root"
FS_S3A_SECRET_KEY: "flink_minio_123456"
HADOOP_SECURITY_AUTHENTICATION_STARTUP_STATE: "false"
JAVA_SECURITY_KRB5_CONF_PATH: "/opt/krb5.conf"
LOGIN_USER_KEYTAB_USERNAME: "hdfs@HADOOP.COM"
LOGIN_USER_KEYTAB_PATH: "/opt/hdfs.keytab"
KERBEROS_EXPIRE_TIME: "2"
HDFS_ROOT_USER: "hdfs"
RESOURCE_MANAGER_HTTPADDRESS_PORT: "8088"
YARN_RESOURCEMANAGER_HA_RM_IDS: ""
YARN_APPLICATION_STATUS_ADDRESS: "http://ds1:%s/ws/v1/cluster/apps/%s"
YARN_JOB_HISTORY_STATUS_ADDRESS: "http://ds1:19888/ws/v1/history/mapreduce/jobs/%s"
DATASOURCE_ENCRYPTION_ENABLE: "false"
DATASOURCE_ENCRYPTION_SALT: "!@#$%^&*"
SUDO_ENABLE: "true"
# dolphinscheduler env
HADOOP_HOME: "/opt/soft/hadoop"
HADOOP_CONF_DIR: "/opt/soft/hadoop/etc/hadoop"
SPARK_HOME1: "/opt/soft/spark1"
SPARK_HOME2: "/opt/soft/spark2"
PYTHON_HOME: "/usr/bin/python"
JAVA_HOME: "/usr/local/openjdk-8"
HIVE_HOME: "/opt/soft/hive"
FLINK_HOME: "/opt/soft/flink"
DATAX_HOME: "/opt/soft/datax"ok,完成以上的配置后,资源中心就可以正式开启了,而且也确定不会报错了,十分不容易
我只想说,DolphinScheduler 文档,代码这块的管理比较乱,PMC 的大佬们似乎没太多精力关心这个事情。但是,不管是参与者,还是初学者,都希望有一份靠谱的文档,让大家少走弯路....
希望 DolphinScheduler 的开源团队能加强这块的建设,引入更好的一些可以良性循环的机制,解决这个问题。