诗意书香,宋风雅韵,宋代的文人们或婉约,或豪放,为后世留下了不朽的文学遗产 —— 宋词。宋词本质上是用于合乐的歌词,词人在填词时用的曲调名即为词牌。各位读者在中学时期一定对“水调歌头”、“念奴娇”这些词牌名耳熟能详。根据统计,存世的宋词当中出现的词牌名约有1400余个。那么,哪些词牌名最受词人追捧?这种枯燥重复的统计工作,正是计算机所擅长的。
本文引用自作者编写的下述图书; 本文允许以个人学习、教学等目的引用、讲授或转载,但需要注明原作者"海洋饼干叔
叔";本文不允许以纸质及电子出版为目的进行抄摘或改编。
1.《Python编程基础及应用》,陈波,刘慧君,高等教育出版社。免费授课视频 Python编程基础及应用
2.《Python编程基础及应用实验教程》, 陈波,熊心志,张全和,刘慧君,赵恒军,高等教育出版社Python编程基础及应用实验教程
3. 《简明C及C++语言教程》,陈波,待出版书稿。免费授课视频
在随书源代码的CH6目录下,有个名为songci.json的文件,该文件以JSON保存了21050首存世宋词。关于何为JSON格式,以及如何存取JSON格式文件,我们在第8章中讨论。
在Visual Studio Code中打开文件songci.json,可见如下内容:
[
... #此处有大量节略
{
"author": "晏殊",
"paragraphs": [
"一曲新词酒一杯。", "去年天气旧亭台。", "夕阳西下几时回。",
"无可奈何花落去,似曾相识燕归来。", "小园香径独徘徊。"
],
"rhythmic": "浣溪沙"
},
{
"author": "李清照",
"paragraphs": [
"常记溪亭日暮。", "沈醉不知归路。", "兴尽晚回舟,误入藕花深处。",
"争渡。", "争渡。", "惊起一滩鸥鹭。"
],
"rhythmic": "如梦令"
}
... #此处大量节略
]
songci.json中的文本内容如果按Python语法,可以理解为一个列表,该列表包含21050个字典。每个字典包含一首宋词,其由至少三个键值对构成,其中”author”对应作者姓名,”paragraphs”对应宋词正文,”rhythmic”则对应词牌名。
#songrhythm.py
f = open("songci.json","rt",encoding="utf-8")
ci = eval(f.read())
f.close()
rhythmic = {}
for x in ci:
r = x["rhythmic"]
rhythmic[r] = rhythmic.get(r,0) + 1
from wordcloud import WordCloud
wc = WordCloud( font_path="PuHuiTi.ttf",
width = 1500, height = 1000,
background_color='white', colormap="Paired" )
wc.generate_from_frequencies(rhythmic)
from matplotlib import pyplot as plt
plt.imshow(wc)
plt.axis("off")
plt.subplots_adjust(0,0,1.0,1.0,0,0)
plt.show()
#本程序中的宋词数据库引用自开源项目Chinese-poetry
#受限于版权,本演示程序使用了免费的开源字体
🚩第2 ~ 4行:打开当前工作路径下的文件songci.json,将其中的内容按字符串形式读出,并借由eval()函数进行转换,并将转换结果赋值给ci。关于文件读写的详细方法,我们在第8章里讨论。根据songci.json的文件内容可知,上述代码执行后,ci应为一个列表,其中包含21050个字典。
🚩第6 ~ 9行:从宋词列表ci统计各词牌名的出现次数,结果存储于rhythmic字典中。第7行的for循环逐一遍历列表ci中的子字典x,其中的值对象x[“rhythmic”]即为词牌名r。对于每个遇到的词牌名r,均将其在rhythmic字典中的出现次数加1。请读者留意rhythmic.get(r,0)的应用,当某个词牌名,比如”点绛唇”第一次被for循环发现时,其在rhythmic字典中尚不存在,get()函数的应用可以避免程序出错并返回指定的默认值0。
🚩第11 ~ 15行:使用第三方库wordcloud生成词云。Wordcloud第三方库的安装方法请参见1.6.3节。
🚩第12行:WordCloud是由第三方库wordcloud所定义的类型名,其同名函数WordCloud()用于生成一个词云对象。关键字参数font_path指明了生成词云时所用的字体文件。对于Windows操作系统而言,这些字体文件可以在C:/Windows/Fonts目录中找到。为方便读者,作者复制了开源的阿里巴巴普惠体字体文件PUHUITI.ttf,并放置在了随书代码的CH6子目录下。
🚩第14行:关键字参数background_color用于指定词云的背景色,colormap则指定了颜色映射表。本行代码中用到的颜色映射表”Paired”是由matplotlib定义的。
🚩第15行:词云对象wc的generate_from_frequencies()成员函数进行已有的词频统计结果生成词云。对本例而言,rhythmic字典提供了相应的词频统计结果。那些出现次数多的词牌名将在词云中被突出显示。
🚩第17 ~ 21行:在matplotlib里绘制图云并显示出来。
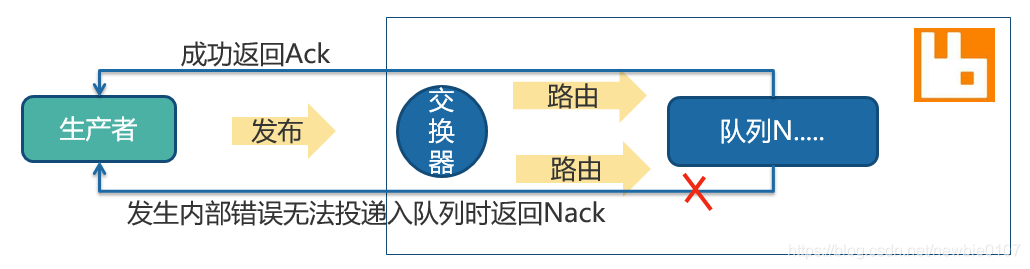
运行上述程序songrhythm.py,将得到如图所示的词云。从中可以看出,在宋代,最受追捧的词牌名是“浣溪沙”,然后是“水调歌头”和“鹧鸪天”。

🥇操作技巧
在运行songrhythm.py时,读者一定要确保文件songrhythm.py、songci.json、PuHuiTi.ttf均位于当前工作路径之下。否则,程序会因为无法找到需要的文件而运行出错。关于当前工作路径的解释,请参见1.5.2节。
将前述程序略作修改,便可以将统计对象由词牌名改为作者。我们也根据存世作品的数量绘制了宋代词人的词云,如图6-x所示。相应代码文件为songpoet.py,可在随书代码的CH6目录下找到。如图所见,宋代词人存世作品最多的是辛弃疾,然后是苏轼和刘辰翁。

#songpoet.py
f = open("songci.json","rt",encoding="utf-8")
ci = eval(f.read())
f.close()
authors = {}
for x in ci:
r = x["author"]
authors[r] = authors.get(r,0) + 1
from wordcloud import WordCloud
wc = WordCloud( font_path="PuHuiTi.ttf",
width = 1500, height = 1000,
background_color='white', colormap="Paired" )
authors.pop("无名氏")
wc.generate_from_frequencies(authors)
from matplotlib import pyplot as plt
plt.imshow(wc)
plt.axis("off")
plt.subplots_adjust(0,0,1.0,1.0,0,0)
plt.show()
#本程序中的宋词数据库引用自开源项目Chinese-poetry
#受限于版权,本演示程序使用了免费的开源字体
为了帮助更多的年轻朋友们学好编程,作者在B站上开了两门免费的网课,一门零基础讲Python,一门零基础C和C++一起学,拿走不谢!
简洁的C及C++

Python编程基础及应用

如果你觉得纸质书看起来更顺手,目前Python有两本,C和C++在出版过程中。
Python编程基础及应用
Python编程基础及应用实验教程