文章目录
- 介绍
- PixelCNN论文简读
- 模型介绍
- 自回归模型
- PixelCNN
- 模型结构
- 基础知识回顾
- 参考连接
- 代码实现
- PixelConvLayer
- 具体运行过程
- 卷积模块
- 整体网络结构
- 模型执行效果
- Colab代码本子介绍
- Introduction介绍
- 获取数据
- 创建模型需要两个类
介绍
-
在上一篇就是介绍了矢量量化变分模型的具体实现,就是一个编码器和解码器,只能生成和原来图片一样的图片,没啥意义。这里需要生成一个新的码字序列,解码器能够接受这部分数据,然后解码成对应的新的图片。
-
作者使用PixelCNN去训练这些码本
- pixelCNN的论文链接
- 代码样例
-
PixelCNN是一个自回归模型,根据已有的序列生成下一个位置的值。在这个任务里,就是生辰新的码字序列,然后使用训练好的解码器生成对应的新的图片。
PixelCNN论文简读
- Abstract
- 这篇文章主要讲的是根据PixelCNN按照条件生成图片。这个模型可以根据向量,描述性的符号或者标记,甚至是别的网络模型生成的潜在embedding来生成新的图片。这个模型可以根据ImageNet中数据的类别标记,生成逼真并且完全不同的图片。如果输入模型的是一个其他卷积网络生成的embedding,并且这个embedding是表示人脸的,他会自动生成具有不同面部表情、姿势和光照条件的,同一个人的不同的各种新的画像。PixelCNN在图片自编码器中,也可以当作一个强大的图片解码器使用。
- Introduction
- 图片生成应用广泛,常见的比如说降噪、去模糊、修复、超分辨和着色都是使用图片生成技术,他们都需要根据不完整的图片或者带有噪声的图片来生成原始的图片。
- 这篇文章改良PixelRNN中的卷积变量实现的,基本的思路是使用自回归链接逐个像素对图片进行建模,将联合图像分布,分解成条件概率分布的乘积。原文中主要有两个变种,分别是PixelRNN,是使用LSTM进行预测,PixelCNN是使用卷积进行预测。
- 我们还引入了门控PixelCNN(条件PixelCNN)的条件变体,它允许我们在给定潜在向量嵌入的情况下对自然图像的复杂条件分布进行建模。我们表明,通过简单地对类的 one-hot 编码进行条件调节,可以使用单个条件 PixelCNN 模型从狗、草坪扇和珊瑚礁等不同类别的图像生成图像。类似地,可以使用捕获图像高级信息的嵌入来生成具有各种具有相似特征的图像。这让我们深入了解嵌入中编码的不变性——例如,我们可以根据单个图像生成同一个人的不同姿势。相同的框架也可用于分析和解释深度神经网络中的不同层和激活。
模型介绍
- 本来是想读论文的,一看已经是2016年的文章了,网上已经有很多相关的介绍了。
- PixelCNN是通过链式法则,将概率密度转成一系列条件概率之积,然后通过网络来估计条件分布。
自回归模型
-
自回归创建一个显式密度模型,该模型学习训练数据的最大似然。但是处理多个维度\特征的数据时,需要完整如下的步骤
- 首先,输入空间需要为其特征确定顺序,对于图像而言,通过像素的空间位置,来定义顺序,左侧像素在右侧像素之前,顶部像素在底部像素之前等。
- 其次,自回归模型需要将特征的联合分布p(x)转换为条件分布的乘积,以对数据观察中的特征的联合分布进行精确建模。
- 给定先前特征的值,自回归模型使用每一个特征的条件定义联合分布
-
图像中某一个像素具有特定强度值的概率由先前像素的值确定
-
图像的概率(所有像素的联合分布)是其所有像素的概率的组合
-
因此,自回归模型使用链式法则,将数据样本x的可能性分解成一维分布的乘积,将联合建模问题变成了序列问题,学习了在给定所有先前像素的情况下,预测下一个像素的过程。

PixelCNN
- PixelCNN是生成神经网络,一次生成一个像素,并且使用之前已经训练好的像素去生成下一个像素,类似于根据一个序列,去预测下一个像素点的值。如下图,是使用蓝色的像素块,来预测红色的像素块。
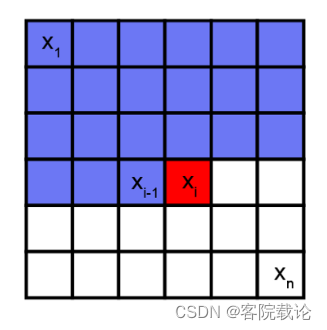
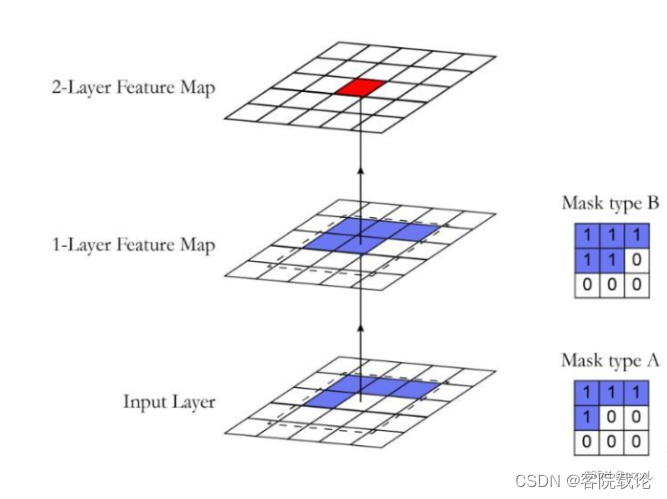
- 因为常规的卷积是计算周围所有的像素点,和PixelCNN的预测方式不同,所以这里出现了掩码卷积,来控制没有被预测的像素点。主要有两类掩码卷积类型,分别如下
- Mask Type A仅仅是用于第一层卷积,中间值被屏蔽,因为没有预测过
- Mask Type B可以用于出第一层以外的所有的层卷积,除了第一层,后续每一层的自身值都是被预测过的。
模型结构
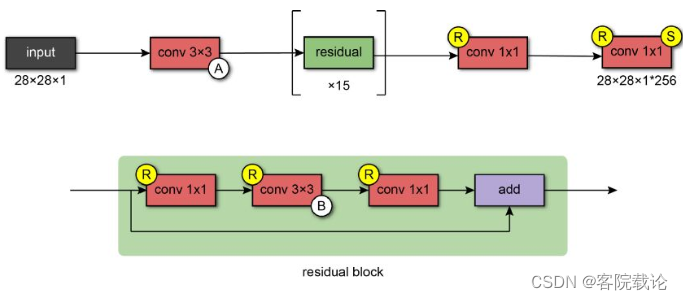
- 第一层使用77的A类型掩码卷积模块,然后使用15个残差模块。每一個残拆模块的构成图如下,使用33的B类型的掩码卷积模块,首尾两个1*1的卷积模块。
-
经历过残差序列模块的处理之后,经过两个带有relu的1*1的卷积层,然后经过softmax进行输出,预测像素所有可能的预测值。模型的输出是具有与输入图像大小相同的格式乘以可能值的数量。
基础知识回顾
- 极大似然:利用已知样本结果信息,反推最具有可能导致当前样本结果的模型参数值。相当于数据的样本是已经知道的,对应的模型分布类型不知道,缺的是对应类型的模型参数,所以是根据样本估计模型参数。
- 概率和统计
- 概率:已知模型和参数,推断数据的分布。
- 统计:已知数据的具体内容,推断具体模型和参数。
- 联合概率和条件概率
- 联合概率:同一个时间,两个独立事件同时发生的可能性,事件相交的概率
- 条件概率:P(B|A)事件B在事件A发生的情况下,B发生的概率。两个相依事件的联合概率变为P(A 和B)= P(A)P(B | A)
- 贝叶斯公式
- 后验概率等于先验概率乘以似然比
- P(H|E)=P(H)P(E|H)/P(E)
- 先验概率和后颜概率
- 后验概率:所有证据被采用之后,事件发生的概率
- 先验概率:未采用证据之前,事件发生的概率,经验性概率
- 后验概率= (可能性*先验)/证据
- 最大似然估计
- 根据样本,也就是数据,来估计模型的参数,使得似然函数的值最大
参考连接
- 参考并引用下述文章的内容
- 生成模型之PixelCNN
- 什么是PixelCNN
- 自回归模型–PixelCNN
代码实现
PixelConvLayer
- 这部分就是掩码卷积,通过之前已经预测的点的概率,来预测当前的点。在原来的卷积上,增加了一个掩码的部分。
- 主要是两类,差别在于A类中心点的坐标并没有标记,B类的中心点已经被预测过的,具体看上面的图。
# 掩码卷积
class PixelConvLayer(Layer):
"""
掩码卷积层,分别是两种类型,A类和B类
"""
def __init__(self,mask_type,**kwargs):
super().__init__()
self.mask_type = mask_type
self.conv = Conv2D(**kwargs)
self.mask = None
def build(self,input_shape):
# 创建二维卷积层,并初始化对应的卷积核权重参数
self.conv.build(input_shape)
kernel_shape = self.conv.kernel.get_shape()
# 生成同等大小的掩码层,用来抑制没有预测的卷积层
self.mask = np.zeros(shape = kernel_shape)
self.mask[:kernel_shape[0] // 2,...] = 1.0
self.mask[kernel_shape[0] // 2,:kernel_shape[1] // 2,...] = 1.0
if self.mask_type == "B":
self.mask[kernel_shape[0] // 2,kernel_shape[1]//2,...] = 1.0
def call(self,inputs):
# 根据掩码层,来修改更正卷积层的结果
self.conv.kernel.assign(self.conv.kernel * self.mask)
return self.conv(inputs)
具体运行过程
- 这里用一个33的掩码卷积作为样例,对一个88的图片,进行A类型的掩码卷积,然后使用的padding模式是same.这里并不是完全的使用之前所有的已经预测过的标记点,进行预测当前的标记点,是根据卷积核中的已经预测过的点进行预测,具体过程如下:
- 第一次预测红框中心的点
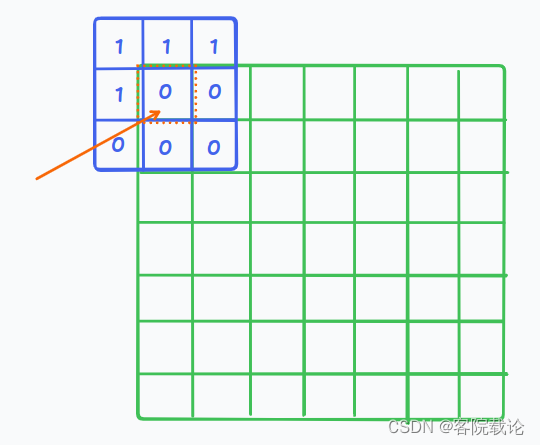
- 后续,第一个位置已经被预测过了,就会考虑到第一个点的预测结果
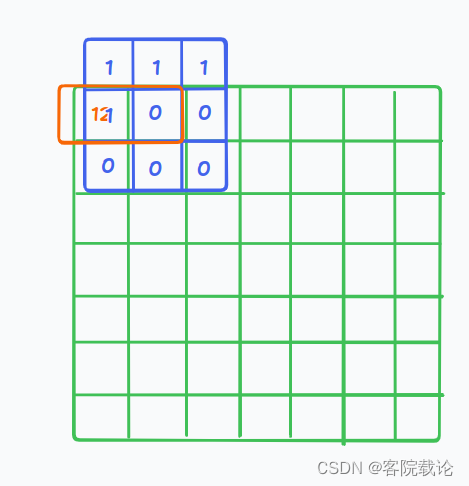
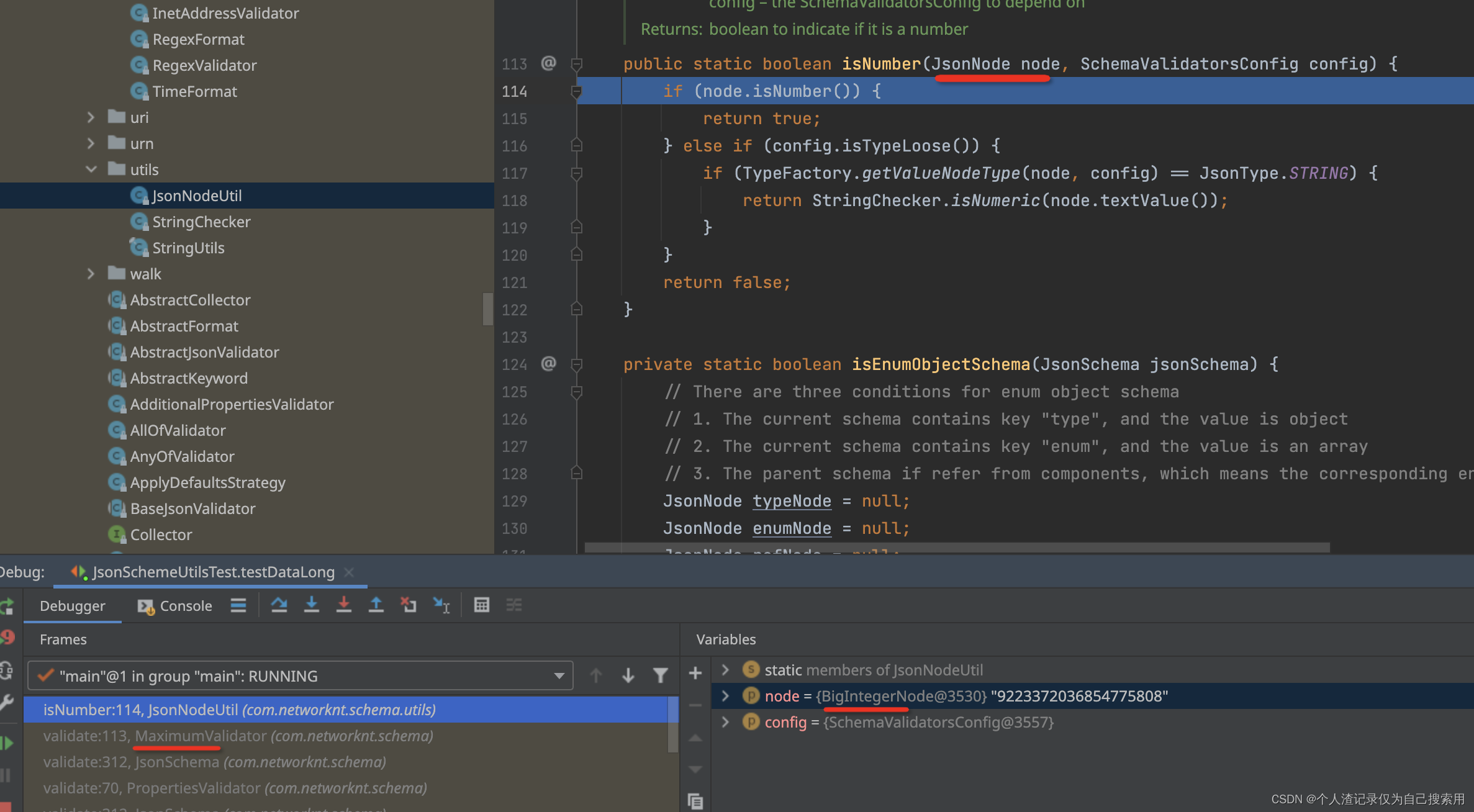
- 以此类推,不断向后迭代
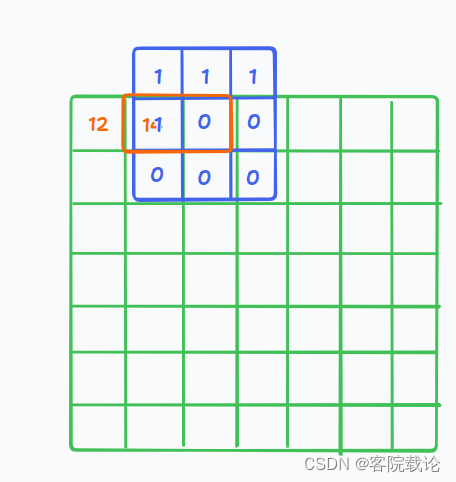
- 最多的情况下,就是考虑了四个点的情况
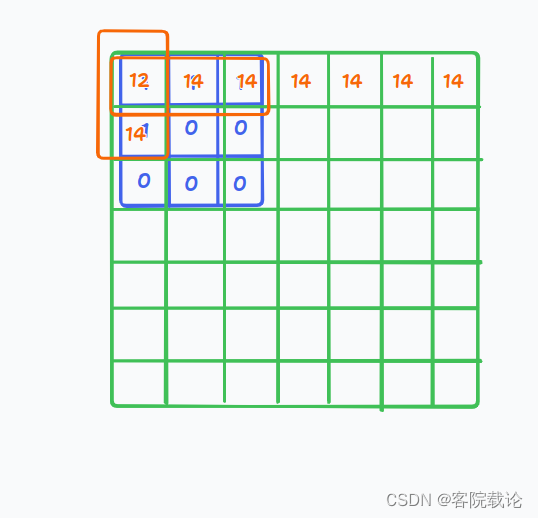
- 代码主要有两部分构成,分别是掩码和前向传播的实际计算
# 掩码卷积
class PixelConvLayer(Layer):
"""
掩码卷积层,分别是两种类型,A类和B类
"""
def __init__(self,mask_type,**kwargs):
super().__init__()
self.mask_type = mask_type
self.conv = Conv2D(**kwargs)
self.mask = None
def build(self,input_shape):
# 创建二维卷积层
self.conv.build(input_shape)
kernel_shape = self.conv.kernel.get_shape()
# 将卷积层改成,掩码卷积,这里是生成掩码层
self.mask = np.zeros(shape = kernel_shape)
self.mask[:kernel_shape[0] // 2,...] = 1.0
self.mask[kernel_shape[0] // 2,:kernel_shape[1] // 2,...] = 1.0
if self.mask_type == "B":
self.mask[kernel_shape[0] // 2,kernel_shape[1]//2,...] = 1.0
def call(self,inputs):
self.conv.kernel.assign(self.conv.kernel * self.mask)
return self.conv(inputs)
卷积模块
- 这部分就是在原来的基础上,使用残差网络将B类的掩码卷积套在残差模块中,具体形成如下
- 首尾分别是两个1*1的卷积
- 中间是3*3的B类掩码卷积
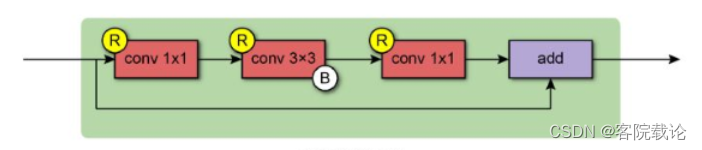
class ResidualBlock(Layer):
"""
基于掩码卷积层的残差模块
"""
def __init__(self,filters,**kwargs):
super().__init__()
# 第一个卷积模块
self.conv1 = Conv2D(
filters = filters,kernel_size = 1,activation="relu"
)
# 中间的B类掩码卷积,进行概率估计
self.pixel_conv = PixelConvLayer(
mask_type="B",
kernel_size = 3,
activation = "relu",
padding = "same",
filters = filters // 2
)
# 最后一个卷积模块
self.conv2 = Conv2D(
filters = filters,kernel_size = 1,activation="relu"
)
def call(self,inputs):
# 前向传播中,数据传播的方式
x = self.conv1(inputs)
x = self.pixel_conv(x)
x = self.conv2(x)
# 残差模块中的直连
res = add([inputs,x])
return res
整体网络结构
- 具体网络结构如下图,但是教程的代码实现起来最后做了修改,我是觉得如果使用11的掩码卷积其实和常规的11的卷积是一个效果

class PixelCNN:
"""
PixelCNN:像素卷积模型
功能:用于生成新的码本序列
"""
def __init__(self,
input_shape,
num_residual_blocks,
num_pixelcnn_layers,
num_embeddings
):
self.input_shape = input_shape
self.num_residual_blocks = num_residual_blocks
self.num_pixelcnn_layers = num_pixelcnn_layers
self.num_embeddings = num_embeddings
# 定义不同的层
self.model = None
# 构建模型
self._build()
def _build(self):
"""
网络结构为:Aconv3*3,residual815,Rconv,Rconv,Softmax
:return:
"""
PixelCNN_Input = Input(shape = self.input_shape,name = "PixelCNN input")
x = PixelConvLayer(mask_type="A",
filters = 128,
kernel_size = 7,
strides = 1,
activation = "relu",
padding = "same"
)(PixelCNN_Input)
# 添加卷积模块
for i in range(self.num_residual_blocks):
x = ResidualBlock(filters = 128)(x)
# 添加后续的像素卷积层
for i in range(self.num_pixelcnn_layers):
x = PixelConvLayer(
mask_type="B",
filters = 128,
kernel_size = 1,
strides = 1,
activation = "relu",
padding = "valid"
)(x)
out = Conv2D(
filters=1,
kernel_size=1,
strides=1,
activation="sigmoid",
padding="valid"
)(x)
self.model = Model(PixelCNN_Input,out)
def summary(self):
self.model.summary()
def compile(self, learning_rate=0.0001):
""" 指定损失函数和优化器,并对模型进行优化 """
optimizer = Adam(learning_rate=learning_rate)
self.model.compile(
optimizer=optimizer,
loss="binary_crossentropy",
)
# 3.3 增加训练函数
def train(self, x_train, batch_size, num_epochs):
self.model.fit(
x_train,
x_train,
batch_size=batch_size,
epochs=num_epochs,
shuffle=True
)
模型执行效果
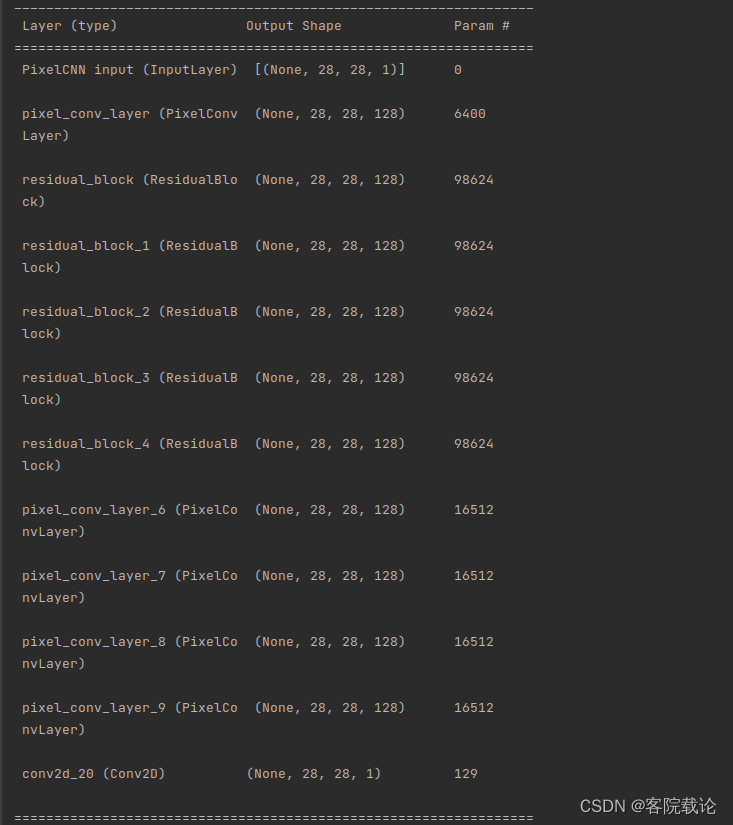
- 这里生成的模型比较简单,没有按照他的弄了几层
Colab代码本子介绍
Introduction介绍
- PixelCNN是生成模型,主要是根据输入向量迭代生成图像的模型,其原理是由之前的元素概率分布决定之后元素的概率分布。在后续的样例中,图片也是按照这种方式逐个元素生成的,主要是通过掩码卷积实现对过往数据的观察,来生成以后的数据。在推理过程中,网络的输入被看作是概率分布,新的数据是从这些概率中进行抽样生成的。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tqdm import tqdm
获取数据
- 这里用的是mnist手写数据集
# 模型和数据参数
num_classes = 10
input_shape = (28, 28, 1)
n_residual_blocks = 5
# 加载训练集和测试集
(x, _), (y, _) = keras.datasets.mnist.load_data()
# 将图片链接到一起
data = np.concatenate((x, y), axis=0)
# 对像素值进行二值化,对256进行三等分划分,并将数据转成float类型
data = np.where(data < (0.33 * 256), 0, 1)
data = data.astype(np.float32)
创建模型需要两个类
- PixelConvLayer:这部分是实现掩码卷积的类,主要有两类,分别是A和B,其中A不包括中心元素,B包括了中心元素。
- ResidualBlock:残差卷积层,这里主要是使用PixelConvLayer的掩码卷积替换之后的残差网络,和一般的残差卷积层差别不大。