VQA评测分多种,这里提几种,代码参考来自lavis和mmpretrain。
一、gqa评测(只有一个answer)
数据集下载及格式:
blip中json地址
图片下载
# gqa格式已重新整理,特点是每个question对应的gt_answers只有一个
[{'image': 'n161313.jpg',
'gt_answers': ['no'],
'question': 'Is it overcast?',
'question_id': 201307251},
{'image': 'n235859.jpg',
'gt_answers': ['women'],
'question': 'Who is wearing the dress?',
'question_id': 201640614},
……]
评测代码:
# 参考:https://github.com/salesforce/LAVIS/blob/main/lavis/tasks/vqa.py
vqa_tool = VQAEval()
acc = []
for res in results:
pred = res["pred_answer"]
gt_ans = res["gt_answers"]
if type(pred) is list:
pred = pred[0]
# 如果是生成式语言模型生成答案,会对答案进行对齐处理,如three处理成3。
# 这里的处理各评测不一,BLIP对pred做了处理。mmpretrain对pred和gt均做了处理。
# all responses are made lowercase, numbers converted to digits, and punctuation & articles removed.
if self.inference_method == "generate":
pred = vqa_tool.processPunctuation(pred)
pred = vqa_tool.processDigitArticle(pred)
vqa_acc = 1 if [pred] == gt_ans else 0
acc.append(vqa_acc)
overall_acc = sum(acc) / len(acc) * 100
对预测结果的处理如下:
class VQAEval:
def __init__(self,):
self.contractions = {
"aint": "ain't",
"arent": "aren't",
"cant": "can't",
"couldve": "could've",
"couldnt": "couldn't",
"couldn'tve": "couldn't've",
"couldnt've": "couldn't've",
"didnt": "didn't",
"doesnt": "doesn't",
"dont": "don't",
"hadnt": "hadn't",
"hadnt've": "hadn't've",
"hadn'tve": "hadn't've",
"hasnt": "hasn't",
"havent": "haven't",
"hed": "he'd",
"hed've": "he'd've",
"he'dve": "he'd've",
"hes": "he's",
"howd": "how'd",
"howll": "how'll",
"hows": "how's",
"Id've": "I'd've",
"I'dve": "I'd've",
"Im": "I'm",
"Ive": "I've",
"isnt": "isn't",
"itd": "it'd",
"itd've": "it'd've",
"it'dve": "it'd've",
"itll": "it'll",
"let's": "let's",
"maam": "ma'am",
"mightnt": "mightn't",
"mightnt've": "mightn't've",
"mightn'tve": "mightn't've",
"mightve": "might've",
"mustnt": "mustn't",
"mustve": "must've",
"neednt": "needn't",
"notve": "not've",
"oclock": "o'clock",
"oughtnt": "oughtn't",
"ow's'at": "'ow's'at",
"'ows'at": "'ow's'at",
"'ow'sat": "'ow's'at",
"shant": "shan't",
"shed've": "she'd've",
"she'dve": "she'd've",
"she's": "she's",
"shouldve": "should've",
"shouldnt": "shouldn't",
"shouldnt've": "shouldn't've",
"shouldn'tve": "shouldn't've",
"somebody'd": "somebodyd",
"somebodyd've": "somebody'd've",
"somebody'dve": "somebody'd've",
"somebodyll": "somebody'll",
"somebodys": "somebody's",
"someoned": "someone'd",
"someoned've": "someone'd've",
"someone'dve": "someone'd've",
"someonell": "someone'll",
"someones": "someone's",
"somethingd": "something'd",
"somethingd've": "something'd've",
"something'dve": "something'd've",
"somethingll": "something'll",
"thats": "that's",
"thered": "there'd",
"thered've": "there'd've",
"there'dve": "there'd've",
"therere": "there're",
"theres": "there's",
"theyd": "they'd",
"theyd've": "they'd've",
"they'dve": "they'd've",
"theyll": "they'll",
"theyre": "they're",
"theyve": "they've",
"twas": "'twas",
"wasnt": "wasn't",
"wed've": "we'd've",
"we'dve": "we'd've",
"weve": "we've",
"werent": "weren't",
"whatll": "what'll",
"whatre": "what're",
"whats": "what's",
"whatve": "what've",
"whens": "when's",
"whered": "where'd",
"wheres": "where's",
"whereve": "where've",
"whod": "who'd",
"whod've": "who'd've",
"who'dve": "who'd've",
"wholl": "who'll",
"whos": "who's",
"whove": "who've",
"whyll": "why'll",
"whyre": "why're",
"whys": "why's",
"wont": "won't",
"wouldve": "would've",
"wouldnt": "wouldn't",
"wouldnt've": "wouldn't've",
"wouldn'tve": "wouldn't've",
"yall": "y'all",
"yall'll": "y'all'll",
"y'allll": "y'all'll",
"yall'd've": "y'all'd've",
"y'alld've": "y'all'd've",
"y'all'dve": "y'all'd've",
"youd": "you'd",
"youd've": "you'd've",
"you'dve": "you'd've",
"youll": "you'll",
"youre": "you're",
"youve": "you've",
}
self.manualMap = {
"none": "0",
"zero": "0",
"one": "1",
"two": "2",
"three": "3",
"four": "4",
"five": "5",
"six": "6",
"seven": "7",
"eight": "8",
"nine": "9",
"ten": "10",
}
self.articles = ["a", "an", "the"]
self.periodStrip = re.compile("(?!<=\d)(\.)(?!\d)")
self.commaStrip = re.compile("(\d)(,)(\d)")
self.punct = [
";",
r"/",
"[",
"]",
'"',
"{",
"}",
"(",
")",
"=",
"+",
"\\",
"_",
"-",
">",
"<",
"@",
"`",
",",
"?",
"!",
]
def processPunctuation(self, inText):
outText = inText
for p in self.punct:
if (p + " " in inText or " " + p in inText) or (
re.search(self.commaStrip, inText) != None
):
outText = outText.replace(p, "")
else:
outText = outText.replace(p, " ")
outText = self.periodStrip.sub("", outText, re.UNICODE)
return outText
def processDigitArticle(self, inText):
outText = []
tempText = inText.lower().split()
for word in tempText:
word = self.manualMap.setdefault(word, word)
if word not in self.articles:
outText.append(word)
else:
pass
for wordId, word in enumerate(outText):
if word in self.contractions:
outText[wordId] = self.contractions[word]
outText = " ".join(outText)
return outText
二、aokvqa评测(10个answer,使用普遍)
数据集下载:
json
图片:可以从coco官网下载(2014/2017均可),也可以从aokvqa官网下载
# 如果是生成式,direct_answers为gt;如果是选择,choices和correct_choice_idx为gt。
[{'split': 'train',
'image_id': 299207,
'question_id': '22MexNkBPpdZGX6sxbxVBH',
'question': 'What is the man by the bags awaiting?',
'choices': ['skateboarder', 'train', 'delivery', 'cab'],
'correct_choice_idx': 3,
'direct_answers': ['ride',
'ride',
'bus',
'taxi',
'travelling',
'traffic',
'taxi',
'cab',
'cab',
'his ride'],
'difficult_direct_answer': False,
'rationales': ['A train would not be on the street, he would not have luggage waiting for a delivery, and the skateboarder is there and not paying attention to him so a cab is the only possible answer.',
'He has bags as if he is going someone, and he is on a road waiting for vehicle that can only be moved on the road and is big enough to hold the bags.',
'He looks to be waiting for a paid ride to pick him up.'],
'image': 'val2014/COCO_val2014_000000299207.jpg',
'dataset': 'aokvqa'}]
评测代码:
aokvqa论文中提到,这种评测方式参考《VQA: Visual Question Answering》

an answer is deemed 100% accurate if at least 3 workers provided that exact answer. Before comparison, all responses are made lowercase, numbers converted to digits, and punctuation & articles removed.
# 参考:https://github.com/salesforce/LAVIS/blob/main/lavis/tasks/vqa.py
# VQAEval()见gqa部分代码
vqa_tool = VQAEval()
acc = []
for res in results:
pred = res["answer"]
gt_ans = res["gt_answers"]
if type(pred) is list:
pred = pred[0]
# 这里blip是对pred做了处理,最新代码中已删除
# mmpretrain对pred和gt_ans均做了处理
# all responses are made lowercase, numbers converted to digits, and punctuation & articles removed.
if self.inference_method == "generate":
pred = vqa_tool.processPunctuation(pred)
pred = vqa_tool.processDigitArticle(pred)
num_match = sum([pred == gt for gt in gt_ans])
vqa_acc = min(1.0, num_match / 3.0)
acc.append(vqa_acc)
accuracy = sum(acc) / len(acc) * 100
三、VQAv2(10个answer)
数据集下载:
- json文件下载
- 图片:coco2014,可以从coco或vqa官网下载
[{'question_id': 262148000,
'question': 'Where is he looking?',
'answer': ['down',
'down',
'at table',
'skateboard',
'down',
'table',
'down',
'down',
'down',
'down'],
'image': 'val2014/COCO_val2014_000000262148.jpg',
'dataset': 'vqa'},
……]
评测代码(10个answer)
We introduce a new evaluation metric which is robust to inter-human variability in phrasing the answers:
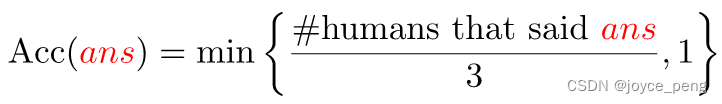
In order to be consistent with ‘human accuracies’, machine accuracies are averaged over all 10 choose 9 sets of human annotators.
(这里处理不同,比较复杂,对于一个q,先剔除gt第一个,使pred_a和9个gt计算acc1,再剔除gt第二个,使pred_a和9个gt计算acc2,以此往复,得到10个acc,做平均,即得到这个q的平均acc。具体见代码)
Before evaluating machine generated answers, we do the following processing:
● Making all characters lowercase
● Removing periods except if it occurs as decimal
● Converting number words to digits
● Removing articles (a, an, the)
● Adding apostrophe if a contraction is missing it (e.g., convert “dont” to “don’t”)
● Replacing all punctuation (except apostrophe and colon) with a space character. We do not remove apostrophe because it can incorrectly change possessives to plural, e.g., “girl’s” to “girls” and colons because they often refer to time, e.g., 2:50 pm. In case of comma, no space is inserted if it occurs between digits, e.g., convert 100,978 to 100978. (This processing step is done for ground truth answers as well.)
# 参考https://github.com/salesforce/LAVIS/blob/main/lavis/tasks/vqa.py#L259
vqa_tool = VQAEval()
accQA = []
for pred_ann in resfile:
resAns = pred_ann['answer']
if type(resAns) is list:
resAns = resAns[0]
resAns = resAns.replace("\n", " ")
resAns = resAns.replace("\t", " ")
resAns = resAns.strip()
resAns = vqa_tool.processPunctuation(resAns)
resAns = vqa_tool.processDigitArticle(resAns)
gtAnswers = []
gtAcc = []
for ansDic in pred_ann["gt_answers"]:
gtAnswers.append(vqa_tool.processPunctuation(ansDic))
for gtAnsDatum in gtAnswers:
otherGTAns = copy.deepcopy(gtAnswers)
otherGTAns.remove(gtAnsDatum)
matchingAns = [item for item in otherGTAns if item == resAns]
acc = min(1, float(len(matchingAns)) / 3)
gtAcc.append(acc)
if gtAcc:
avgGTAcc = float(sum(gtAcc)) / len(gtAcc)
accQA.append(avgGTAcc)
else:
accQA.append(0)
overall_acc = round(100 * float(sum(accQA)) / len(accQA), 2)
四、ScienceQA(有选项)
数据集下载:
下载地址:https://scienceqa.github.io/
评测方式:
可以参考https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/evaluation/metrics/scienceqa.py