- 作者:20岁爱吃必胜客(坤制作人),近十年开发经验, 跨域学习者,目前于海外某世界知名高校就读计算机相关专业。
- 荣誉:
阿里云博客专家认证、腾讯开发者社区优质创作者,在CTF省赛校赛多次取得好成绩。跨领域学习,喜欢摄影、弹吉他、咏春拳。文章深入浅出、语言风趣;爱吃必胜客社区创立者,旨在“发现美 欣赏美
- 🏆 学习系列专栏
。🏅 Python学习宝库
。🏅 网络安全学习宝库

文章目录
- ⭐️查询字符串 / 参数
- 🌟 做什么
- 🌟 URL 编码 (URL Encoding)
- ☀️例子
- ☀️中文url编码
- ⭐️做法
- 🌟 用curl发起请求
- ☀️例子
- ⭐️安全的 HTTP(HTTPS)
- 🌟 TLS加密
- 会话劫持( Session Hijacking )
- 会话劫持的对策
- 跨站脚本攻击 (XSS)
- 跨站脚本攻击的解决方案
⭐️查询字符串 / 参数
一个查询字符串或者参数是 URL 的一部分并且通常都包含一些要发往至服务器的各种类型的数据。一个简单的带查询字符串的 URL 长这样:
http://www.example.com?search=ruby&results=10
让我们拆开来看看:
查询字符串组件 描述
? 这是个保留字,标识着查询字符串的开始
search=ruby 这是一个参数的键/值对儿
& 这是个保留字,需要给查询字符串添加参数时使用
results=10 这也是一个参数的键/值对儿
现在我们再来看一个例子。假设我们有下面这个 URL:
http://www.phoneshop.com?product=iphone&size=32gb&color=white
🌟 做什么
在上面这个例子里,键/值对儿product=iphone,size=32gb,color=white 通过 URL 传给了服务器。这个请求告诉www.phoneshop.com的服务器,把要请求的资源条件限制在产品 iphone,大小 32gb和颜色白色。服务器怎么样使用这些参数取决于服务端的应用的处理逻辑。
另一个经常见到查询字符串的情况是当你在搜索引擎上搜索东西的时候。因为查询字符串是通过 URL 传递的,他们仅使用 HTTP 的 GET 请求。在本书后面的章节里我们会讨论不同的 HTTP 请求,但是现在你所需要知道的是,当你不论什么时候在浏览器的地址栏里输入网址进行浏览的时候,你就是在发起 HTTP 的 GET 请求。大部分超链接都是 HTTP 的 GET 请求,偶尔会有一些例外。
🌟 URL 编码 (URL Encoding)
URL 在设计的时候就默认只接受 ASCII 码。因此,不安全的或者不是 ASCII 码的字符就要进行转义或者编码来适应这个格式。URL 编码的原理是将不符合格式的字符替换成%开头后面跟着两个十六进制数字代表的 ASCII 码的一串字符。

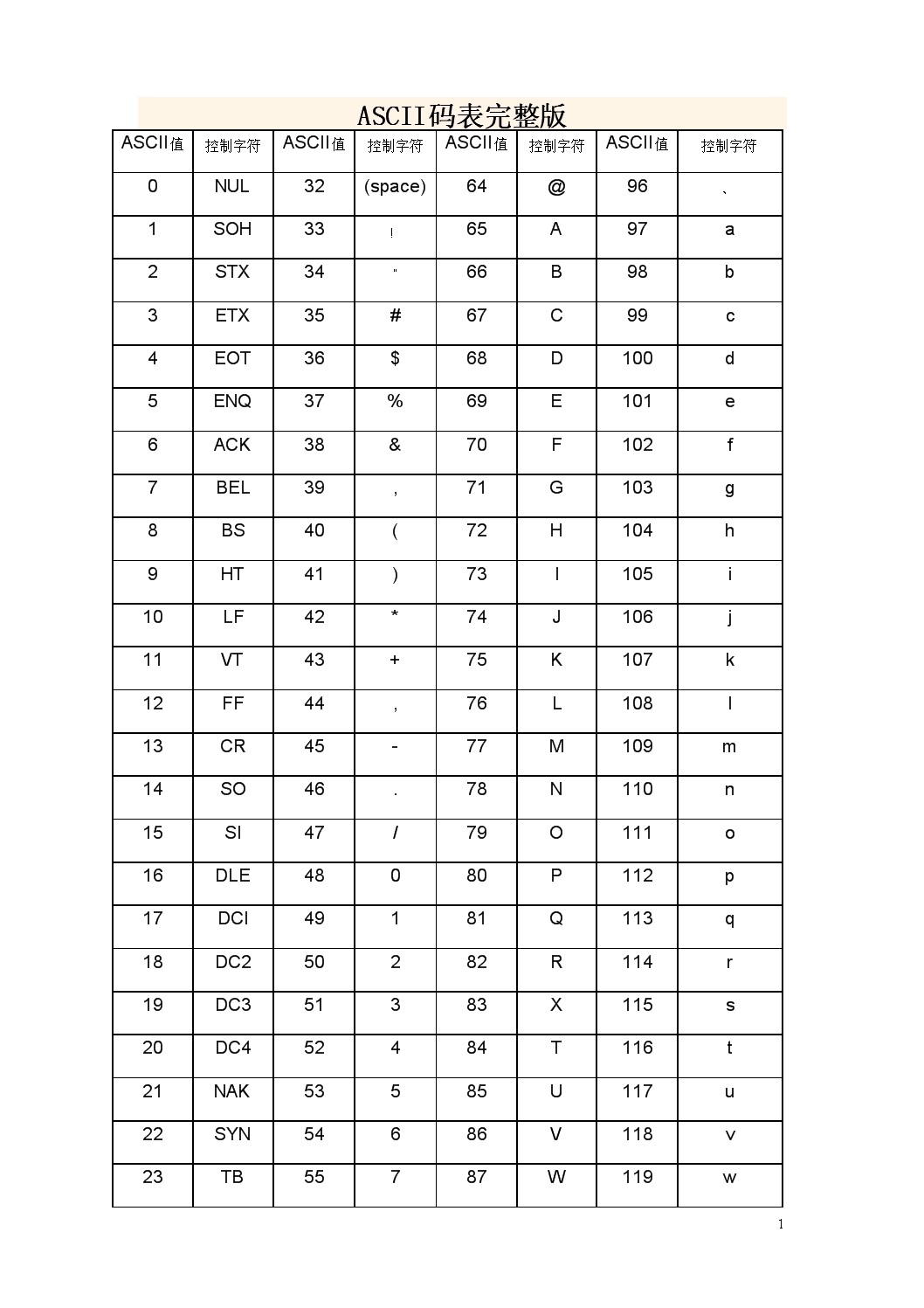
下面是一些常见的 URL 编码和实例 URL:
字符 ASCII 码 URL
注意⚠️16进制
1. + -> URL 中+表示空格 十六进制: %2B
2. 空格 -> URL中的空格可以用+号或者编码 十六进制 : %20
3. / -> 分离目录和子目录 十六进制 : %2F
4. ? -> 分离实际的URL和参数 十六进制: %3F
5. % -> 特殊字符 十六进制: %25
6. # -> 表示书签 十六进制: %23
7. & -> URL中指定参数间的分隔符 十六进制: %26
8. = -> URL中指定参数的值 十六进制:%3D
符合下列条件的字符都要进行编码处理:
没有对应的 ASCII 码。
字符的使用是不安全的。比如%就是不安全的,因为它经常用于对其它字符进行转义。
字符是有特殊用途的 URL 模式保留字。有些字符用于保留字是有着特殊的意义;它们在 URL 中的存在具有特殊用途。比如/,?,:,和&,都是需要进行编码的保留字。
比如&被保留用于查询字符串的分隔符。:也被保留用于分隔主机/端口号和用户名/密码。
那么什么样的字符能在 URL 里安全地使用呢?
只有字母表里的和$-_.+!'(),"这些字符可以。如果保留字符被用于它应有的特殊用途,那么是可以不用编码的,不然也是必须要编码的。
☀️例子
> encodeURIComponent("http://www.bugchao.com/?api=接口/")
"http%3A%2F%2Fwww.bugchao.com%2F%3Fapi%3D%E6%8E%A5%E5%8F%A3%2F"
> decodeURIComponent("http%3A%2F%2Fwww.bugchao.com%2F%3Fapi%3D%E6%8E%A5%E5%8F%A3%2F")
"http://www.bugchao.com/?api=接口/"
☀️中文url编码
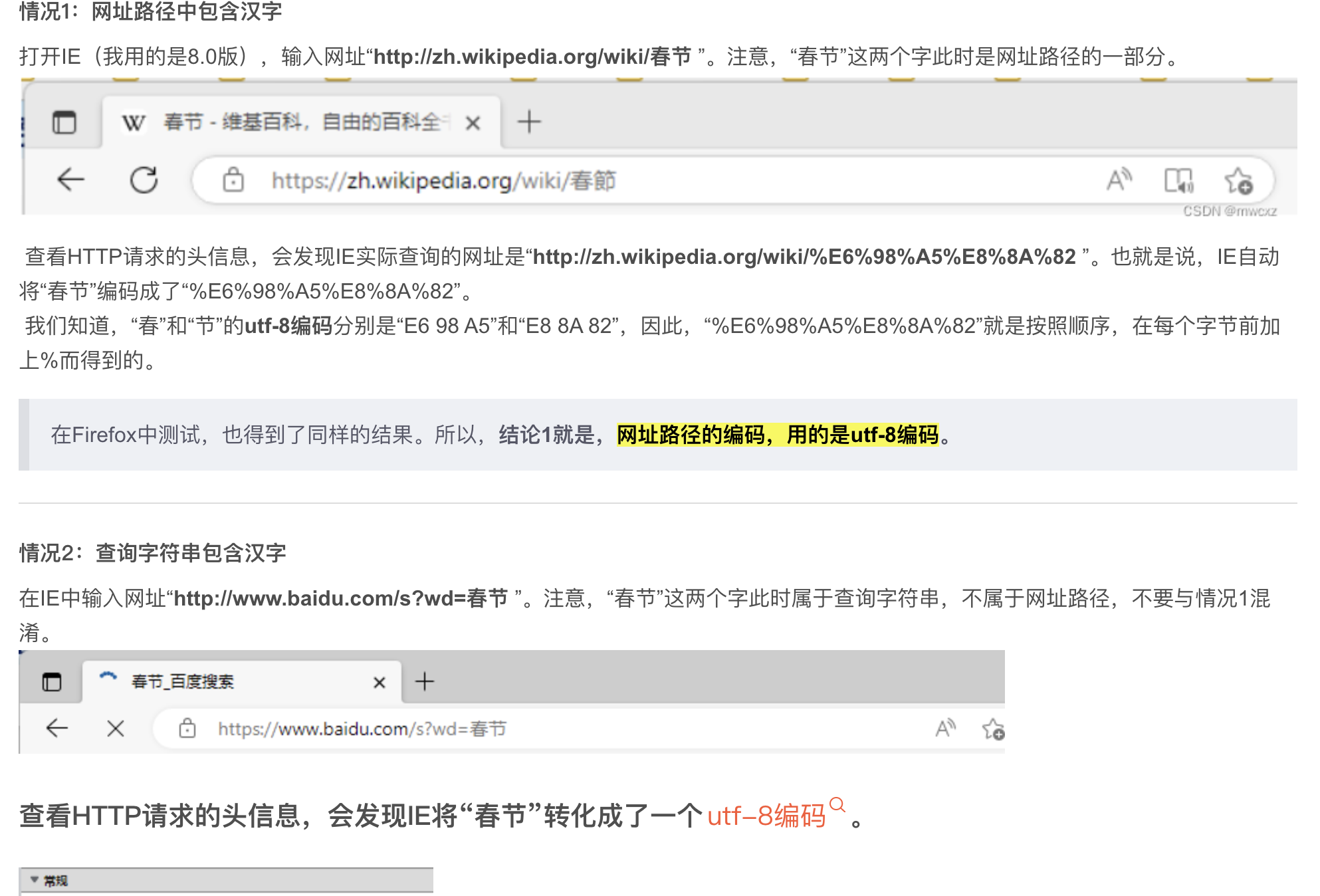
打开IE(我用的是8.0版),输入网址“http://zh.wikipedia.org/wiki/春节 ”。注意,“春节”这两个字此时是网址路径的一部分。
查看HTTP请求的头信息,会发现IE实际查询的网址是“http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82 ”。也就是说,IE自动将“春节”编码成了“%E6%98%A5%E8%8A%82”。
我们知道,“春”和“节”的utf-8编码分别是“E6 98 A5”和“E8 8A 82”,因此,“%E6%98%A5%E8%8A%82”就是按照顺序,在每个字节前加上%而得到的。
在Firefox中测试,也得到了同样的结果。所以,结论1就是,网址路径的编码,用的是utf-8编码。
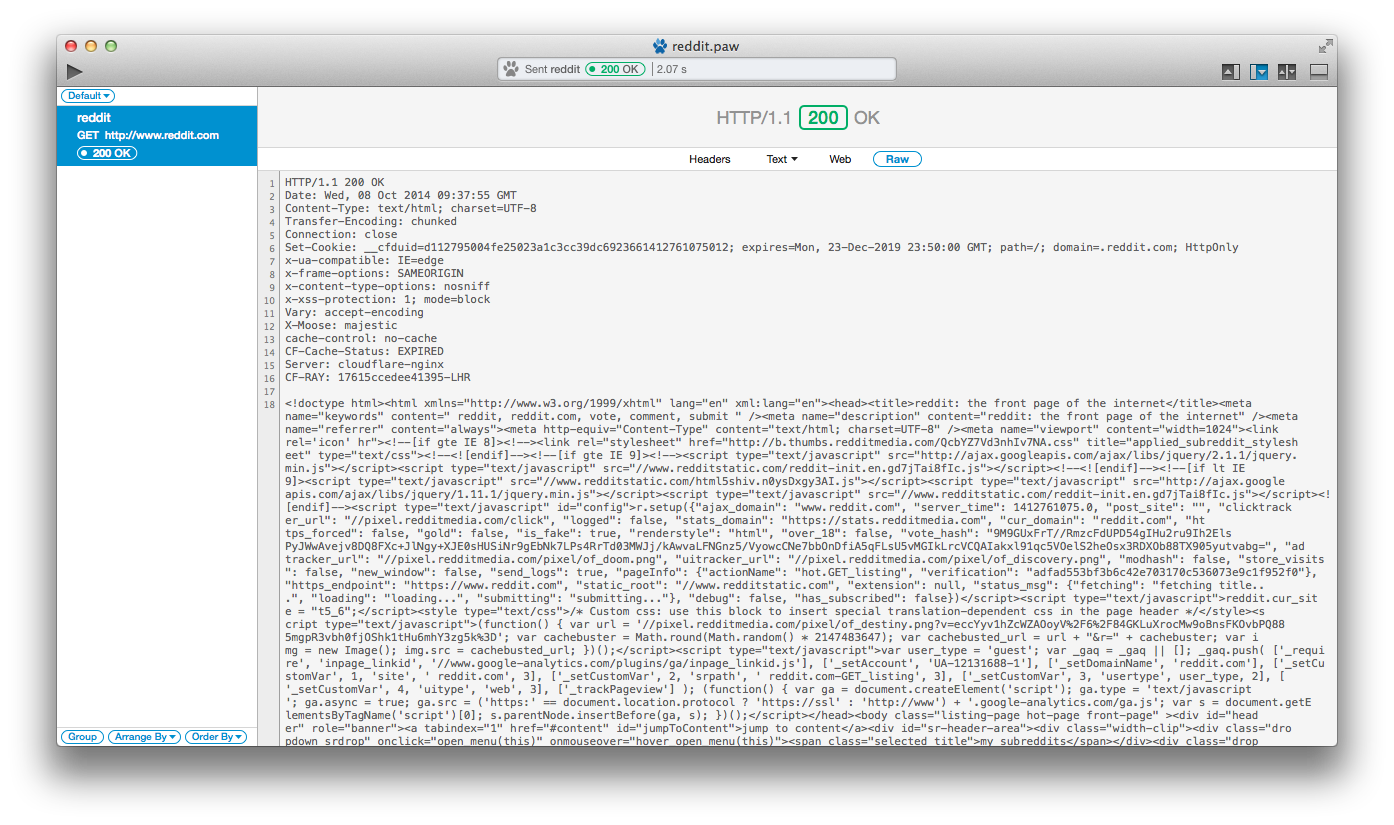
⭐️做法
用paw这个软件打开
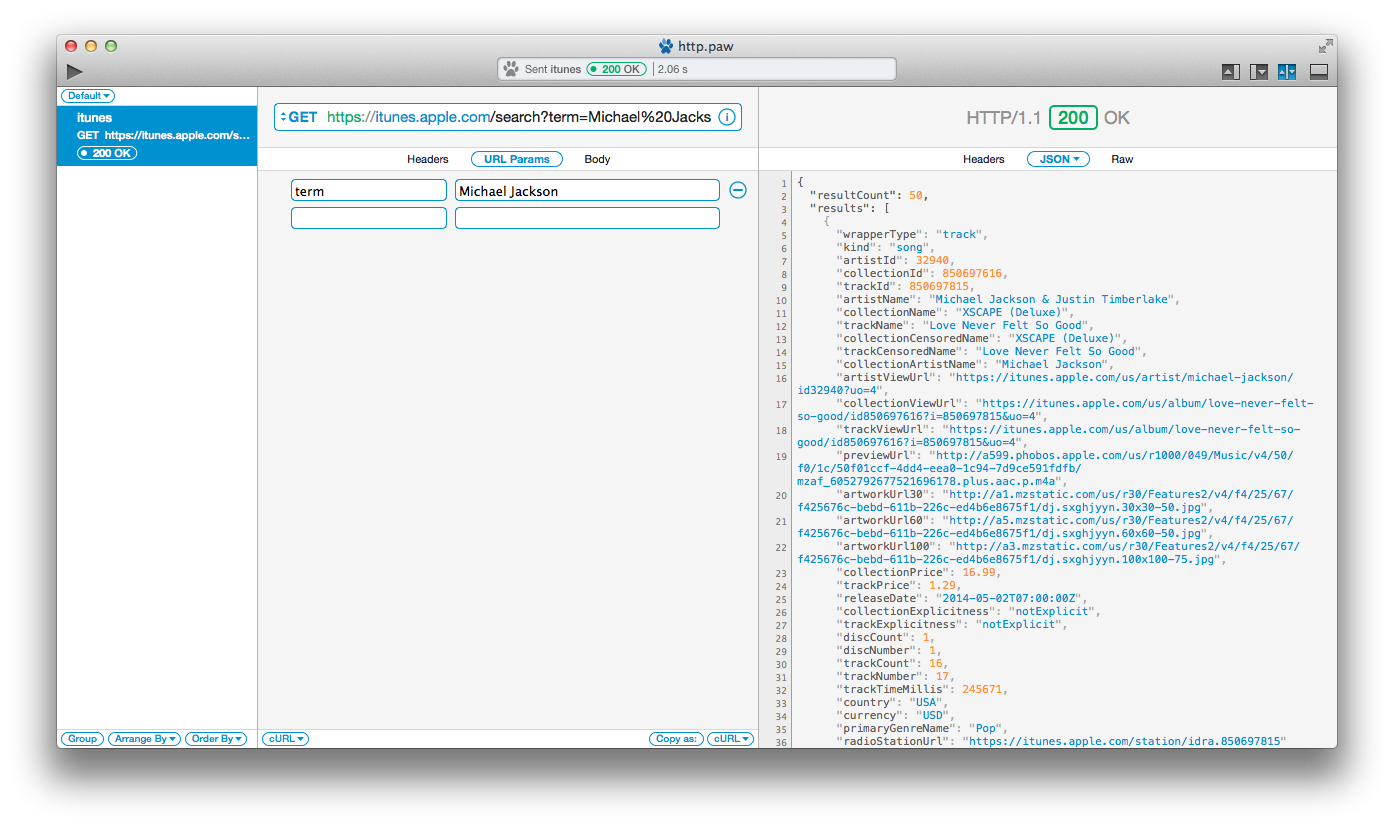
🌟 用curl发起请求
为什么会出现这些额外的响应,谁发起的这些请求? 事情是这样的,当我们请求资源的时候,最初的对于www.reddit.com的请求,返回了一些 HTML。 这些 HTML 里又引用了其他的资源比如图片,CSS 文件,javascript 文件等等。你的浏览器,很聪明也很给力。它明白,为了展示出一个能够给人看的网页,它必须去把这些引用到的资源也一并拿来. 因此浏览器就会对得到的初次响应里的每一个资源再一一发起请求。当你在_Network_ 标签里往下滚动页面,你就能看到所有的相关资源。这些其他的请求保证了这个网页和其他一些东西能正常良好的显示在你的屏幕上.整体来看,浏览器的审查器对于相关的引用资源给你了一个良好的体验.另一方面,一个纯粹的 HTTP 工具,只会返回一个巨大的响应数据并不会自动拉取引用的资源.一个用curl发起的请求可以这样写:
$ curl -X GET "http://www.reddit.com/" -m 30 -v
然后你看到的应该只是一个请求,一个响应包含着 HTML,但是没有那些你在浏览器里看到的自动发起的额外请求。
☀️例子
⭐️安全的 HTTP(HTTPS)
这就意味着服务器必须非常辛勤的工作,来模拟这个有状态的用户体验。每一个请求都会有一个独立的响应,哪怕这次的响应跟前一个响应没有任何区别。举个例子,如果你登录到 Facebook 上,服务器会给你一个响应,生成你看到的主页。这个响应是一个十分复杂的 HTML 页面。Facebook 的服务器会把页面上所有照片和留言的赞和评论都组合起来,然后显示在你的时间线上。生成这样一个页面的成本非常高。现在,如果你点了某个照片下面的” 赞 “链接,理论上,Facebook 会重新生成整个页面,它会把你赞过的照片的被赞数加 1,然后把整个 HTML 作为响应返回给你,尽管除了这个赞数以外大部分内容都没有改变。 庆幸的是,实际中 Facebook 使用 Ajax 代替了全页面刷新。不然的话,刷新一个页面会花费很长时间。
正如我们在这本书中反复指出的, HTTP 的特性让它不容易被居心叵测的人控制,但是同样使得让 http 变得非常安全变得富于挑战性。现在你知道 Web 应用如何优雅的解决了 HTTP 无状态的问题,但是也可想而知还是有一些安全问题需要注意。举个例子,如果有人把我浏览器里的会话 id 偷走,他是不是就能用我身份登陆了?或者当我访问别的网站的时候,它们会不会窥视我 Reddit 和 Facebook 的 cookie 里存储的一些信息,比如会话 id ?本章我们就来讨论一下常见的 HTTP 安全问题。
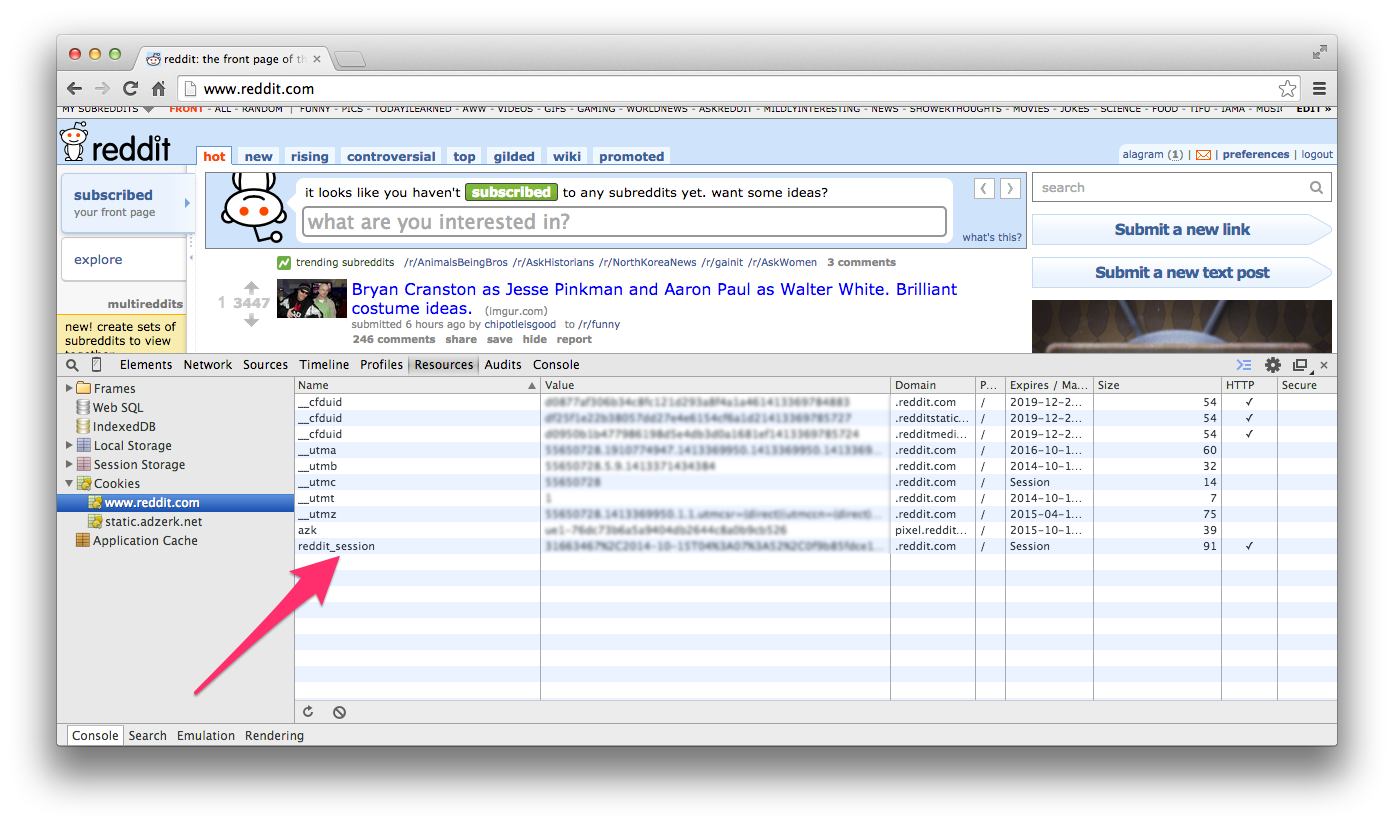
在客户端和服务器互相发送请求和响应的时候,所有的请求和响应里的信息都是通过明文字符串发送的。如果一个恶意的黑客连接到同一网络,他就可以利用数据包嗅探技术来读取来回发送的消息。正如我们已知道的,请求可以包含会话 id ,它唯一地标识你到服务器之间的联系,所以如果别人复制了这个会话 id ,他们可以手动创建到服务器的请求,伪装成你的客户端,甚至都不需要你的用户名和密码就可以自动登陆。
这种情况就需要安全的 HTTP 也就是 HTTPS 来帮忙啦。通过 HTTPS 访问资源的时候,通常以 https:// 开头而不是 http:// ,而且通常在边上都会有个小锁子的图标:
🌟 TLS加密
通过 HTTPS 发送的请求和响应在发送前都会被加密。这意味着如果一个恶意的黑客监听 HTTP 通信,他得到的信息都是加密的和无用的。HTTPS 通过一个叫做 TLS 的加密协议来加密消息。在 TLS 开发完成前,早期 HTTPS 使用 SSL ( Secure Sockets Layer )。这些加密协议在加密数据之前,需要先使用证书来与远程服务器进行通信来交换安全密钥。你可以点击 https:// 前面那个小锁子的图标来查看这些证书:certificates
会话劫持( Session Hijacking )
我们已经知道,会话在维持 HTTP 的状态上扮演着重要的角色。我们也知道会话 id 作为一个唯一的令牌来唯一标识一个会话。通常,会话 id 是作为 cookie 存储在计算机上的一个随机字符串. 会话 id 随着每一个到服务器的请求被送往服务器用于唯一标识这个会话。事实上,这也就是很多 web 应用的用户认证系统所在做的事情,当用户的用户名和密码匹配之后,会话 id 会存储在用户的浏览器里,这样他们的下一个请求就不用重新认证了。
不幸的是,如果一个攻击者拿到了这个会话 id ,他就会跟用户共享这一个会话,同时也就能访问这个 web 应用了。在会话劫持攻击中,用户根本意识不到一个攻击者甚至不用知道她的用户名和密码就可以访问她的会话了。
会话劫持的对策
一个比较流行的会话劫持防范措施是重置会话。也就是对于一个用户认证系统来说,一次成功的登录包括验证旧的会话 id 和生成一个新的会话 id 。完成此步骤后,在下一个请求里,会要求受害者进行身份验证。然后会话 id 就会改变,这样攻击者就无法访问到这个会话了。很多网站都采取这种办法,当用户在进行敏感操作的时候保证用户身份的正确性,比如给信用卡充值或者删除账户的时候。
另一个很有用的方法是给会话设置过期时间。那些不会过期的会话给了攻击者太多的时间去伪装成一个合法用户。如果设置了过期时间,比如 30 分钟,这样一来攻击者就不会那么从容的进行攻击了。
最后,其实我们已经讲过了,另一个办法就是整站使用 HTTPS 把攻击者能得到会话 id 的可能性降至最低。
跨站脚本攻击 (XSS)
我们最后要讨论的这个安全问题,对所有 web 开发者来说都很重要,叫做跨站脚本攻击或者 XSS 。当你允许用户输入的 HTML 和 javascript 在你自己的网站上直接显示的时候,就有可能遭受这种攻击。
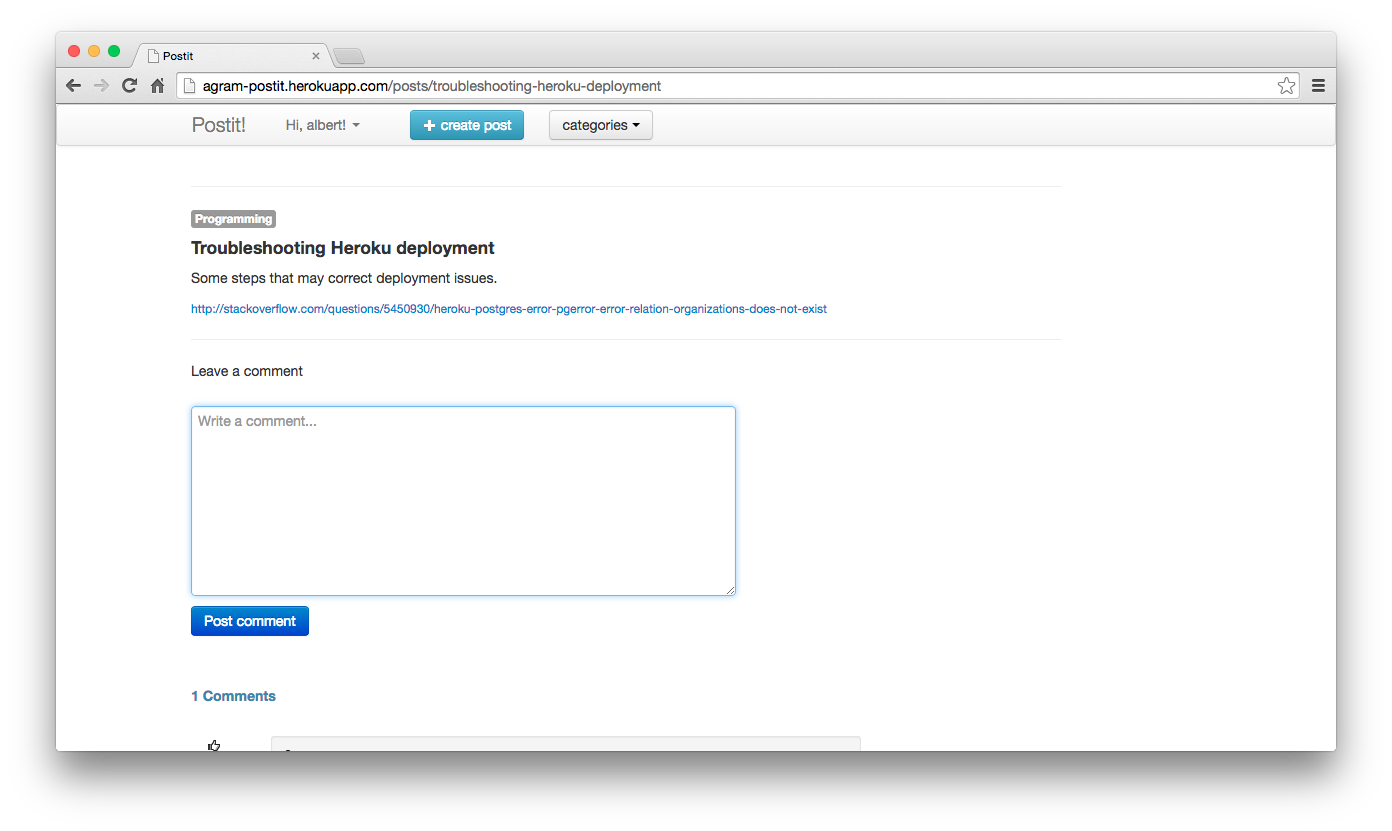
举个例子,下面这个表格允许你输入评论,然后把评论直接显示在网页上:xss
因为这是一个普通的 HTML 文本框,所以用户可以在里面输入任何东西。也就意味着用户可以直接输入原始的 HTML 和 javascript 代码,并把它提交给服务器:raw
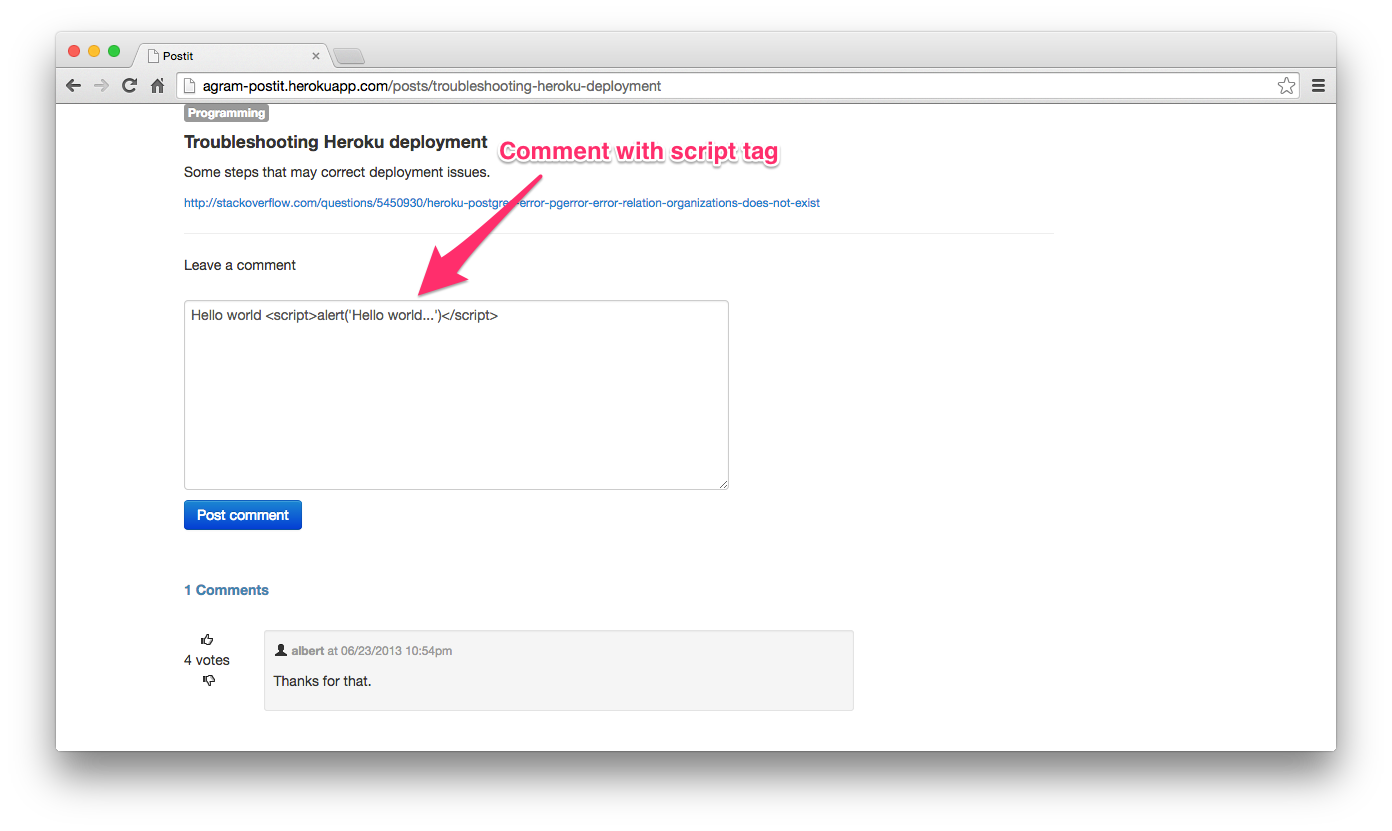
如果服务器端对于用户的输入不做任何无害处理的话,这些内容就会注入到网页的内容中去,然后浏览器就会解释执行这些 HTML 和 javascript 代码。在本例中会弹出一个警告框,这当然不是我们想要的结果。恶意用户可以使用 HTML 和 javascript 代码对服务器或者以后访问这个页面的用户发起毁灭性的攻击。举个例子,一个攻击者可以使用 javascript 代码去获取所有在他之后访问这个页面的用户的会话 id ,然后伪装成其他用户。而这一切都发生在受害者一无所知的情况下。而且要注意的是,这种攻击也能绕过同源策略,因为这段恶意代码是存在于当前这个网站上的。
跨站脚本攻击的解决方案
阻止此类攻击的一个办法就是总是对用户输入的内容做无害处理。消除有问题的输入,比如``标签,或者使用一个更安全的输入格式,比如 Markdown,这样就可以阻止 HTML 和 javascript 同时出现在用户的输入里。
第二个办法就是在显示之前转义用户输入的所有数据.如果你需要用户能够输入 HTML 和 javascript 代码,那么当你显示这些输入内容的时候要确保它们被正确转义,这样浏览器就不会把它们当做代码给执行了。











![Maven详见及在Idea中的使用方法[保姆级包学包会]](https://img-blog.csdnimg.cn/66e7a6798f244818821c0c358fe8cf83.png)