A Comprehensive Survey on Segment Anything Model for Vision and Beyond
Abstract
本文是SAM的第一篇综述
讲述了SAM的发展历史、进展、在不同任务、不同数据类型下的应用
首先介绍专有名词和背景知识
其次介绍SAM再图像处理等应用中的优点和局限
以及SAM未来展望
git链接:https://github.com/liliu-avril/Awesome-Segment-Anything
foundation model:基于大模型和自监督学习 从而可以迁移到不同领域/下游任务
大模型的分类:
语言大模型LLM
LLM有GPT系列,bert,T5
视觉大模型LVM
LVM有CLIP,ALIGN,Florence,VLBERT,X-LXMERT,DALL-E多模态学习文本、图像、video的通用表征
1-大模型like ViT-G,ViT-22B,Swin TransformerV2,VideoMAE-V2
2-多模态 CLIP,ALIGN text+image encoder用于图文生成等
当前LVM聚焦泛化性 基于预训练好的foundation model用于各种下游任务基于prompt learning。
SAM
SAM则是一个提示型模型,基于提示分割在一千一百万长图上获得一百万mask 具有zero-shot的泛化能力 称之为CV届的gpt-3。
目前SAM用于医学图像分割、图像修复、图像修改、风格迁移、缺陷检测等。
代表性工作有:
**Seggpt:**将不同分割模型整合进一个in-context 学习框架具有zero-shot能力
**SEEM:**引入比SAM更多不同的prompt(image/text/reference)
图像分割:目前已有统一的框架同时支持语义分割、实例分割和全景分割
Interactive segmentation存在和人的交互
SAM:主要是因为分割图像训练集不够,基于这一问题, 尝试各种prompts如location/range/mask/text
SAM分成3部分:Task,Model,Data 使用data-engine实现train-annotate loop
SAM的终极目标是训练一个模型可以快速适应各种任务 如边缘检测、实例分割 并且是zero-shot迁移到新额数据分布 使用prompt engineering实现预训练和下游任务
promptable task的一大特性是返回一个valid seg mask当给定任意seg prompt
即使prompt具有二义性也能返回一个seg mask
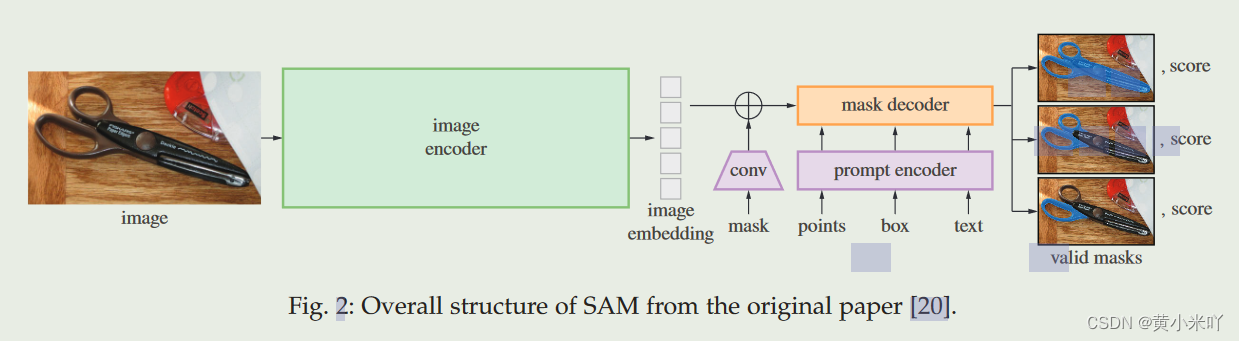
Fig 2展示了SAM的模型结构 包含3部分
image encoder(MAE Pre-trained ViT)
prompt encoder(sparse input用CLIP text encoder处理, dense input用卷积处理)
mask decoder(基于SA和CA的transformer decoder结构)
但输入有歧义网络会根据置信度对mask进行排名
训练使用的损失函数有focalloss和dice loss
Data
由于训练数据有限 SAM使用data engine迭代进行训练-标注任务 整个分成3阶段
stage 1:人工辅助阶段 SAM首先使用公开数据集人工专业标注进行训练, image encoder的size会不断增大 120Kimages+4.3M masks
stage 2:半自动阶段 为了增加mask多样性 首先预先填能生成高置信度预测的mask然后要求annotator来标注没被填充的部分 这一阶段一张image能提供72张mask
stage 3:全自动阶段 本阶段已经有足够的mask SAM在SA-1B数据集上进行续联 SAM已经是个ambiguity-aware模型 每张图在32x32 grid获得prompt points有歧义的prompt,model会返回整个part或者sub-part 然后根据置信度对mask排序 本阶段数据集包含11Mimage+1.1B masks
SAM的应用
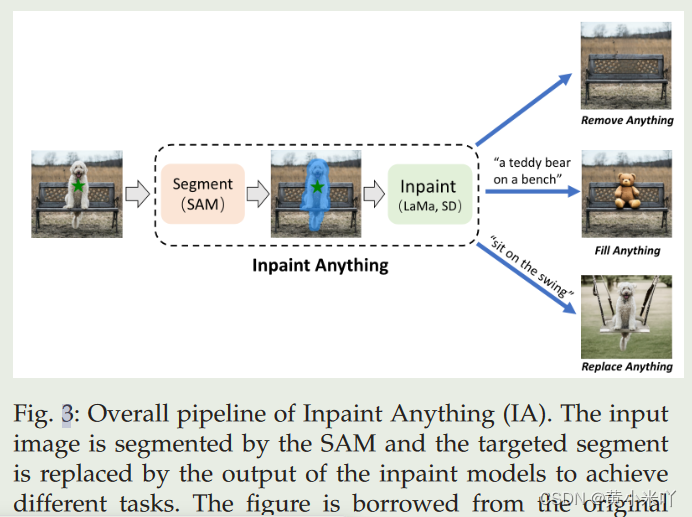
Inpaint Anything:
借助SAM基于prompt做分割 结合其他模型(如image inpainters)可以实现图像填充,具体pipeline参见Fig 3.将第二步替换为AIGC模型还能实现图像生成,就是将第一步选择出的object替换为text prompts生成的object.
Edit Everything:
Edit Everything的流程也是先通过SAM将图像进行分割,此时没有prompts;然后将分数最高的部分作为目标进行替换。主要在中文prompts以及生成图像的逼真程度上得到了提升。
Style Transfer:
常规的风格迁移 只能生成style ,image的纹理不太灵活
Any-to-Any Style Transformer则使得用户可以选择具体的风格区域 整体流程为:
1-预训练VGG-19对style image和content image进行编码 同时计算content-style注意力图
2-SAM获得style mask和content mask
3-通过mask-controlling融合最后一步的注意力图
4-计算风格迁移后的图
真实场景的应用
现实场景
1-目标检测 、移除目标、目标计数
有文章研究了SAM在自然图像、农业图像、遥感、医疗等的性能,发现自然图像泛化性好,低对比度时效果不好,复杂场景需要先验知识。
(1)比如SAM+UNet做分割 检测裂纹 发现SAM在检测纵向裂纹效果优于UNet。
(2)SAM进行圆形的检测效果更好-主要用于行星检测、计数 找到这些圆形十分费时 现有的工作依赖于特定的数据格式
sam的流程是:首先分割输入图像 不限分辨率和数据结构 然后将非圆形封闭区域进行填充 最后做后处理 去除重影缺陷假阳等
(3)少样本目标计数 现实生活中需要借助少量bbox就对没见过的某种object进行检测+计数 SAM强大的泛化能力大有可为
主要就是取bbox作为prompts生成参考样本的mask 然后将大于阈值的座位检测出的object
(4)MOS移动目标检测
十分重要比如自动驾驶领域
目前主要是RGB图或者雷达video无法提供足够的信息理解动态的场景
DSEC-MOS中主要用SAM生成大量mask作为移动object预检测的结果
复杂场景的应用
复杂场景有 低对比度场景、热红外成像、俯视图(空中图像)
低对比度场景(伪装号的动物、工业缺陷、医学损伤) 发现SAM在上述场景没那么有效需要提供特定领域的先验知识
案例1:
比如专门做土豆叶子检测 分四步
1-SAM 识别leaf object
2-找到绿色mask
3-移除IoU小于90%的mask
4-y移除所有找到的树叶
案例2:
SAM+做异常检测 主要用复合hybrid prompt进行regularization 提升模型的适应性
案例3:
热红外图像
热红外图像是另一种复杂场景 因为图片往往比较黑 难以标注
大量无标签的数据被浪费 实际模型的精度差强人意 因此[128]借助SAM来生成label 从而建立一个大型的热红外图像分割数据集-SATIR,SATIR进行热红外分割的三部曲 1-SAM简历数据集 2-预训练模型 3-微调模型
在识别chick用SAM还是发现了局限性,比如对于chicken tail不能很好的识别
其他应用有: 医学图像分析、Video、data annotation
此外还有3D重建、机器人、视频字母生成
医学图像分析的应用
Part 1 Medical Imaging
TransUNet,Swin-UNet,DAE-Former都是transformer用于医学图像分割 但局限于特定任务
SAM可以决绝多种分割任务在同一框架中
SAM做医学图像分割有6类:CT,MRI,HE染色,多模态数据、结肠镜图以及其他相关论文有:
MPLits-CT图
SAMed:SAM+LoRA ft策略 CT图
MRI图:
paper [128]则是 SAM用于FSL Brain tumor segmentation
Polyp-SAM:结肠镜SAM
HE染色图: paper156 SAM做zero-shot seg 用于tumor seg 目前的局限性在于: 图像分辨率、多尺度、prompt的选择以及模型如何微调。
SkinSAM: SAM做皮肤癌分割
SAM的优势在于可以:分割多种格式的医学图像,SAM这方面的代表性工作有:
SAMM:SAM做3D Slicer;还有训练可学习的prompt可以从每一层transformer layer提取knowledge.
SAM-Adapter:使用adapter减轻对领域相关知识、visual prompt的以来做份
PromptUNet:拓展了Prompt的类型 加了Supportive Prompt和Eface Prompt
Video的应用
Video领域
VOT: video Object tracking 和video segmentation是两个重要切相互独立的任务 需要在每一帧定位object位置然后再后续视频中进行跟踪
TAM: tracking anything model 结合了SAM和XMem 具体流程参见Fig 11 SAM是一个强大的分割模型,XMen则是一个半监督的VOS模型 二者结合做VOS
SAM-Track:做video seg 流程参见Fig 12主要将GroundingDINO,DeAOT和SAM结合
VSR:SAM还可以用于提升video分辨率 参见SEEM Fig13展示的流程
在数据标注方面的应用
许多数据集尤其是像素级别的label比较少 SAM就可以来帮忙
SAMText:SAM标注video scene
SAMRD:SAM标注图像分割数据集,目标的种类、位置、实例信息等
WS-SAM:用sam提供高质量的pseudo-labels
此外,在Beyond Vision如3D重建、机器人、视频文本识别、多模态视觉以及交互分割均有SAM的应用
SAM目前的局限性
3D重建的问题主要是: 计算复杂度和内存需求 基于NeRF的方法 目前只能用于small scene
借助SAM的分割能力就可以帮忙进行目标检测和图像合成 但还不能直接用于3D场景的理解。
SA3D: 可以对3D场景进行分割 然后使用inverse rendering+cross-view self-prompting technique将2D Mask投影到3D Mask grid
OR-Nerf:则是基于SAM做object removing 3D的 主要借助SAM预测mask减少所需的时间
3D重建未来的方向:
1-提升NerF方法的效率 减少计算成本和memory需求
2-包含更丰富的输入模态比如depth map,surface normals
3-将3D重建与其他3D感知任务结合 比如3D目标检测、场景识别、姿态识别
4-拓展应用范围 比如SA3D拓展到机器人、AR\VR等
SAM在Robotics的应用
SAM在机器人领域 Instuct2Act
用SAM进行object的识别,CLIP来分类
SAM在非欧几里得域的应用
GNN 由于GNN的异构复杂度 简历通用的图分析的foundation model十分有挑战性
之前的研究有GCN,SAGE,GAT
有研究表示SAM这种基于prompt的框架可以用于通用的图像分析 因此提出使用SAN 简历图分析的foundation model
SNA引入动态激活、失活层
在视频文本识别的应用
包含定位和识别text
传统的依赖于text的目标检测bbox 但是对异常的形状、不规则的方向效果不好
SAM可以获得像素级别的分割mask可以更好的进行细粒度text的分割
SAMText 参见Fig 18 通过计算最小的藏方形获得水平方向的HBB 然后作为input prompt用来生成masklabel; SAM则是一个分割模型在自然图像上预训练然后再COCO_Text上进行微调。
获得每一个text的mask后 在进行后处理。主要是处理连通性。
然后通过光溜估计来提升mask的精确程度。
SAMText提供未来进行视频文本提取的标准流程
SAM在视觉和语言交互处理上的应用:
InternGPT 支持point动作用SAM分割object
Text2Seg:借助SAM做zero-shot分割
以text prompt作为输入,第一个网络是GroundingDINO 生成BBOx;然后第二步以text作为clip的输入,生成热图,对热图进行采样获得送入SAM的prompt;
最后用SAM生成分割图,CLIP用来计算分割图与text prompt之间的相似程度。
SAM用于图像字幕生成
图像字幕则是生成给定图像的文字描述 是机器人、图像检索等的基础任务。
CAT:Caption Anything 引入多模态控制图像字幕生成 基于人类依图的语言风格 包含segmenter+captioner+text refiner
segmenter:通过像素级别mask获得人类感兴趣的区域
captioner:生成原始的字幕 基于原图和提供的mask
text refiner:对申城的text进行精炼 修改文字风格
在CAT中借助SAM进行分割任务 在LLM和SAM的帮助下 这种视觉语言任务可能无需训练
【多模态视觉任务
虽然CLIP 可以实现多种视觉任务 无需额外的训练 但是CLIP的内部机制还没研究透】
SAM在音视频的应用
AVSAM Audio和Visual是两种模态 可以提供互补信息可以联合学习
AV-SAM 用于声音的定位和分割 主要就是用来预测video中声音源的空间位置
通过audio encoder对audio进行编码, 然偶image encoder 集合跨模态的表征;作为prompt送入SAM 生成最终分割的结果
SAM在交互式分割任务上
交互式分割 包含分割目标物体 基于用户的提示
SAM的demo中 可看到将手动的点完全替换为text input基于CLIP 这样提供像素级别的分解结果然后可以转换为SAM接受的point prompt
原始模型 包含q-k注意力计算 新的路径包含v-v自注意力 移除了FFN
new block的参数是old block参数直接复制过来
使用SAM的好处有:
1-只需要text input不需要人工标注点
2-point prompt比mask prompt效果号
3-text-to-point比text-to-boxex更好获得
并且也给CLIP的可解释性 可以可视化CLIP训练过程中的image-text对 理解CLIP的学习过程
SAM其他的应用方向有:
弱监督语义分割、对抗鲁棒性、one-shot学习AI可解释性
SAM做弱监督语义分割
SAM做WSSS的优势在于不需要微调模型就能获得较为满意的分割结果 比如paper209 借助SAM生成pseudo-label
SAM的问题在于语义模糊的情况无法得到较好的分割结果 需要层次化的结构设计以及better prompts
比如用CAM中较为粗糙的location就不能生成较好的结果
解决方法就是 选择相关的mask然后大标间 送入SAM生成高质量pseudo label(伪标签)
SAM做对抗鲁棒性
对抗攻击 包括adding minor,对输入加扰动导致视觉系统分类错误 在安防领域 比如自动驾驶、人脸视觉系统需要考虑
Attack-SAM:测试了SAM在对抗攻击中的鲁棒性 发现SAM对白盒攻击比较脆弱 黑盒攻击较为鲁邦
黑盒攻击-看不见模型参数
白盒攻击-能更改模型参数
SAM 对小物体鲁棒性更强,在黑盒攻击中主要是能给小目标区域施加的扰动少
BadSAM研究了对SAM模型进行back-door攻击
SAM在One-shot学习的应用
SAM的训练需要大规模数据集 但是在许多场景无法实现,如医学图像分割
SAM的优势在于通过给定image和粗略的mask就能指示一个具体的object
PerSAM:使用one-shot data无需训练获得个性化分割模型
SAM在AI可解释性的应用
pixel-level XAI , concept-level XAL
pixel是否精确 影响XAI的可靠性
EAC:借助SAM 在初始阶段将input iamge分割成一系列视觉概念 然后对每一个改建进行PIE
但是SAM误识别的地方会影响最终的决策
其他的foundation model还有GROUNDING DINO和CLIP 主要用来理解图像语义特征、生成visual prompt.