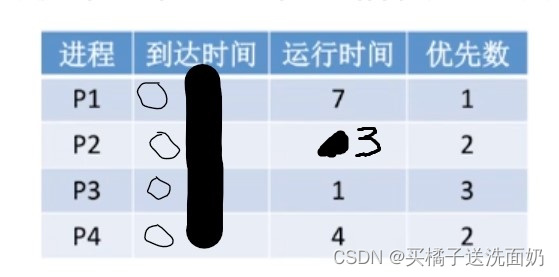
第二章编程模型
本章描述了程序员模型。它包含以下部分:
- 关于2-2页的程序员模型。
- 2-3页的操作和执行方式。
- 指令集摘要见第2-4页。
- 系统地址映射在2-5页。
- 2-8页的独家监视器。
- 处理器核心寄存器在第2-9页。
- 例外情况见第2-10页。
2.1关于编程模型
本章概述了描述实现定义选项的Cortex-M7处理器程序员模型。此外:
- 第三章总结了编程模型的系统控制特性。
- 第六章总结了编程模型的MPU特点。
- 第七章总结了编程模型的NVIC特征。
- 第8章总结了编程模型的FPU特性。
- 第9章总结了编程模型的调试特性。
- 第10章总结了编程模型的CTI特征。
- 第11章总结了编程模型的DWT特性。
- 第12章总结了编程模型的ITM特性。
2.2操作和执行方式
本节简要介绍Cortex-M7处理器的操作和执行模式。有关更多信息,请参阅Arm v7-M架构参考手册。
2.2.1操作模式
处理器支持Thread模式和Handler模式两种操作模式:
- 处理器在复位或异常返回时进入线程模式。特权和非特权代码可以在线程模式下运行。
- 处理器由于出现异常而进入Handler模式。所有代码都享有特权演技时尚。
2.2.2操作状态
处理器可以在两种工作状态下工作:
- 拇指的状态。这是运行16位和32位半字对齐Thumb指令的正常执行。
- 调试状态。这是处理器停止调试时的状态。
2.2.3特权访问和非特权用户访问
代码可以以特权或非特权的方式执行。非特权执行限制或排除对某些资源的访问。特权执行可以访问所有资源。处理程序模式总是特权的。线程模式可以是特权模式或非特权模式。
2.3指令集汇总
处理器实现了ARMv7-M指令集和ARMv7E-M架构配置文件提供的特性。有关ARMv7-M指令的更多信息,请参阅《Arm v7-M架构参考手册》。
2.3.1与其他Cortex处理器的二进制兼容性、
该处理器与其他Cortex-M配置文件处理器中实现的指令集和功能具有二进制兼容性。您不能将软件从Cortex-M7处理器移动到:
- Cortex-M3处理器,如果它包含浮点运算或指令,是DSP扩展的一部分,如SADD16。
- Cortex-M4处理器,如果它包含双精度浮点操作。
- Cortex-M0或Cortex-M0+处理器,因为它们是ARM6-M架构的实现。
为Cortex-M3和Cortex-M4处理器设计的代码与Cortex-M7处理器兼容,只要它不依赖于比特带。
为了确保将软件迁移到Cortex-M7处理器时的平稳过渡,Arm建议设计用于在Cortex-MO、MO+、M3和M4处理器上运行的代码遵循以下规则,并适当配置配置和控制寄存器(CCR):
- 使用字传输只访问NVIC和系统控制空间(SCS)中的寄存器。
- 将处理器上所有未使用的SCS寄存器和寄存器字段视为不修改。
- 请在CCR中配置以下字段:
- STKALIGN位到1。
- UNALIGN_TRP位为1。
- 在CCR寄存器中保留所有其他位的原始值。
2.4系统地址映射
处理器包含一个内部总线矩阵,它仲裁处理器和外部AHBD存储器对外部存储器系统以及内部sc和调试组件的访问。
优先级总是给予处理器,以确保任何调试访问都尽可能是非侵入性的。
系统地址映射如图2-1所示。
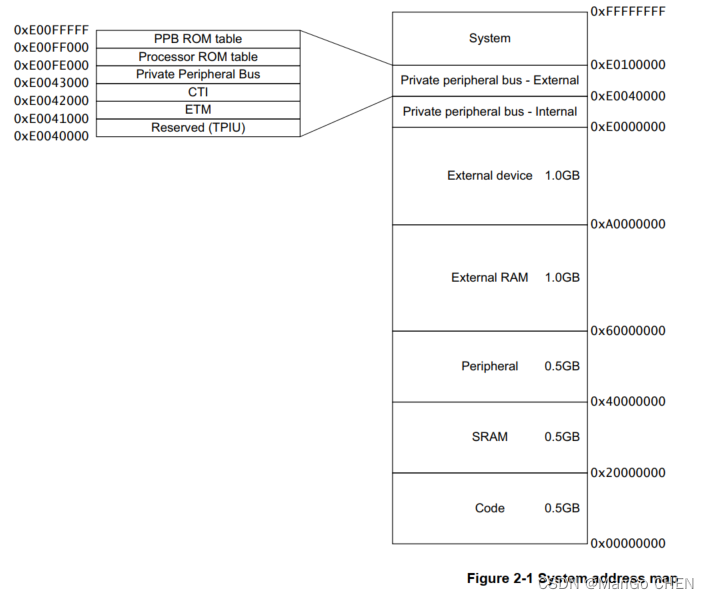
表2-1显示了由不同内存映射区域寻址的处理器接口。

2.4.1专用外围总线
内部PPB接口提供以下访问:
- 仪表跟踪宏单元(ITM)。
- 数据观察点和跟踪(DWT)。
- 断点单元(FPB)。
- SCS,包括MPU,指令和数据缓存,以及嵌套矢量中断控制器(NVIC)。
- 处理器和PPB ROM表。
外部PPB接口提供访问:
- 嵌入式跟踪宏单元(ETM)。
- CTI (Cross Trigger Interface)接口。
- CoreSight调试和跟踪外部系统中的组件。
2.4.2跨区域的非对齐访问
Cortex-M7处理器支持ARMv7非对齐访问,并将所有访问作为单个非对齐访问执行。它们在内部被转换成两个或多个对齐的访问,并在处理器的外部接口上执行。
请注意:
所有Cortex-M7处理器外部访问都是对齐的。
未对齐支持仅适用于加载/存储单(LDR, LDRH, STR, STRH)。加载/存储双精度已支持字对齐访问,但不允许其他未对齐访问。
如果尝试这样做,就会产生错误。
跨内存映射边界的未对齐访问在体系结构上是不可预测的。处理器行为依赖于边界。不支持对PPB空间的不对齐访问,所以PPB访问不存在跨界情况。
2.5独家监控
Cortex-M7处理器实现了一个本地独占监视器。有关信号量和本地独占监视器的更多信息,请参阅Arm*v7-M架构参考手册。
处理器中的本地监视器被构造成不包含任何物理地址。相反,它将任何访问视为匹配前一个LDREX指令的地址。这意味着实现的独占保留颗粒(ERG)是整个内存地址范围。
2.6处理器核心寄存器
处理器有以下32位寄存器:
- 13个通用寄存器,RO-R12。
- 堆栈指针(SP), R13银行寄存器的别名,SP_process和SP_main。
- 链接寄存器(Link Register, LR), R14。程序计数器(PC), R15。
- 专用程序状态寄存器(xPSR)。
有关处理器寄存器集的更多信息,请参阅Arm*v7-M架构参考手册。
2.7异常
处理器和NVIC优先处理所有异常。处理异常时:
- 所有异常都以Handler模式处理。
- 处理器状态在异常时自动存储到堆栈中,并在中断服务程序(ISR)结束时自动从堆栈中恢复。
- 矢量与状态保存并行获取,从而实现高效的中断进入。
处理器支持尾链,它支持背靠背中断,而不需要状态保存和恢复的开销。
在实现过程中,您可以配置中断的数量和中断优先级级别。软件可以选择只启用中断配置数量的一个子集,并可以选择使用多少个配置优先级。
请注意
EPSR。T位支持Arm架构互连模型,但是,由于ARMv7-M只支持执行Thumb指令,因此必须始终将其值保持为1。这意味着所有异常向量必须设置位[0]。如果在异常项上相关向量表项的位[0]被设置为0,则执行第一条指令会导致INVSTATE UsageFault。如果在重置时发生这种情况,则会升级为HardFault,因为在重置时禁用了UsageFault。
2.7.1异常处理
无论是TCM接口、AXIM接口还是AHB接口的外部读错误,都会在处理器中产生同步异常。外部写错误在处理器中产生异步异常。
处理器实现了高级异常和中断处理,如Arm*v7-M架构参考手册中所述。
除了架构定义的行为之外,处理器异常模型还具有以下实现定义的行为:
从HardFault到NMI锁定在NMI优先级上的堆叠异常。
从NMI解除堆叠到HardFault锁定的异常,优先级为HardFault。
为了最小化中断延迟,处理器可以在识别中断时放弃正在执行的大部分多周期指令。唯一的例外是来自Device或强排序内存的加载,或者在AXI接口上启动的共享存储独占操作。当中断被识别时,所有正常的内存事务将被放弃。
处理器从中断返回时重新启动任何被放弃的操作。处理器还实现了可中断-可持续位,允许加载和存储多个可中断和可持续。在这些情况下,处理器在最后一次完成传输后恢复这些指令的执行,而不是从头开始。有关可中断可持续位和密钥限制的更多信息,请参阅Arm v7-M架构参考手册。
具体来说,在Cortex-M7处理器上,这些指令总是重新启动而不是继续:
- 指令错误。
- 该指令位于If-Then (IT)块中。
- 该指令是一个加载倍数,在列表中有基寄存器,并且已经加载了基寄存器。
- 该指令是一个负载倍数,并受到ECC错误的影响。