参考教程:
https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html?highlight=amp
https://pytorch.org/docs/stable/amp.html
https://arxiv.org/pdf/1710.03740.pdf
https://zhuanlan.zhihu.com/p/79887894
文章目录
- 原理
- float 32
- float 16
- 混合精度
- 代码实现
- torch.amp
- torch.autocast
- torch.cuda.amp.GradScaler
- GradScaler with penalty
原理
float 32
参考资料:wikipedia/float32

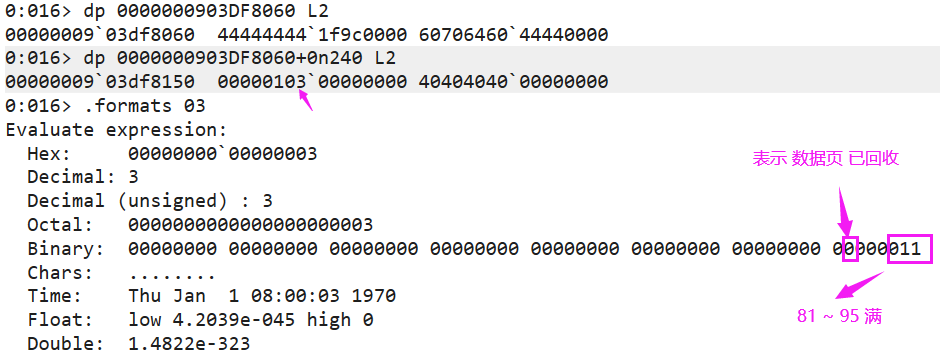
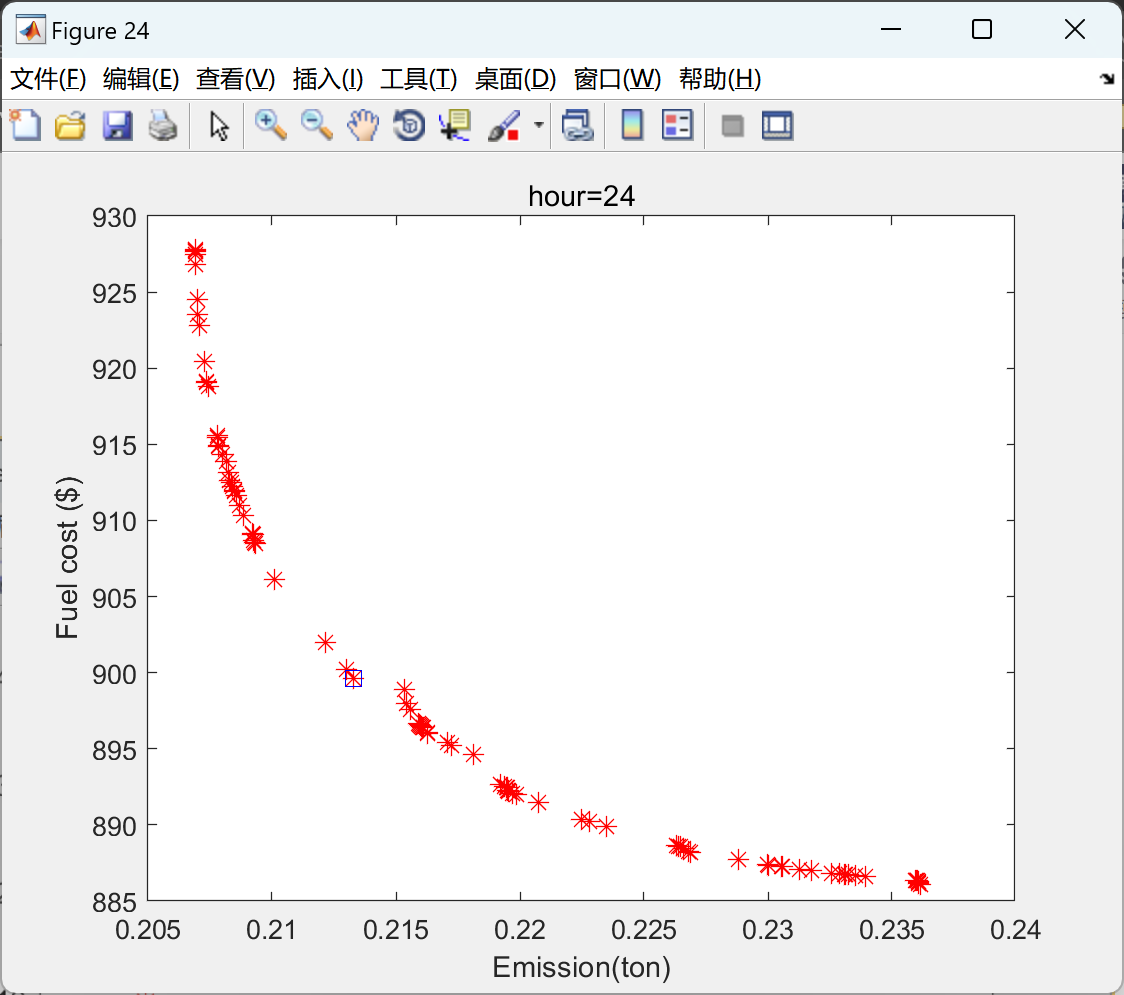
float32的格式如上图。一共三十二位。
- 蓝色区域占一位:表示sign。
- 绿色区域占八位:表示exponent。
- 红色区域占23位:表示fraction。
它的计算规则如下:
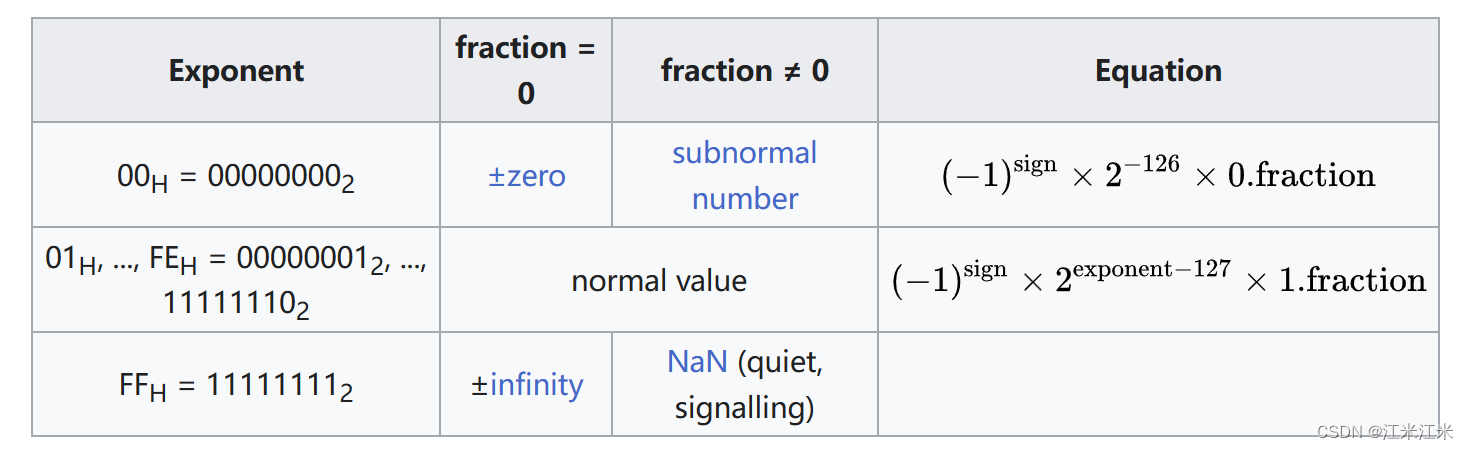
假如你的 Exponent位全为0,那么fraction位有两种情况。
- fraction全为0,则最终结果为0。
- fraction不为0,则表示一个subnormal numbers,也就是一个非规格化的浮点数。
( − 1 ) s i g n × 2 − 126 × ( f r a c t i o n 2 23 ) (-1)^{sign} \times2^{-126} \times(\frac{fraction}{2^{23}}) (−1)sign×2−126×(223fraction)
假如你的Exponent位全为1,那么fraction位有两种情况。
- fraction全为0, 则最终结果为inf。
- fraction不为0,则最终结果为NaN。
假如你的Exponent是其他的情况,那么数据的计算公式为:
(
−
1
)
s
i
g
n
×
2
(
e
x
p
o
n
e
n
t
−
127
)
×
(
1
+
f
r
a
c
t
i
o
n
2
23
)
(-1)^{sign}\times2^{(exponent-127)}\times(1+\frac{fraction}{2^{23}})
(−1)sign×2(exponent−127)×(1+223fraction)
因此float32能取到的最小正数是
2
−
126
2^{-126}
2−126,最大正数是
2
2
8
−
2
−
127
×
(
1
+
2
23
−
1
2
23
)
2^{2^8-2-127}\times(1+\frac{2^{23}-1}{2^{23}})
228−2−127×(1+223223−1)
值得一提的是,float16表示的数是不均匀的,也就是不同的区间范围有着不一样的精度。具体的例子可以从wikipedia/float32上看。下面只给出一点点例子。
| Min | Max | Interval |
|---|---|---|
| 1 | 2 2 2 | 2 − 23 2^{-23} 2−23 |
| 2 22 2^{22} 222 | 2 23 2^{23} 223 | 2 − 1 2^{-1} 2−1 |
| 2 127 2^{127} 2127 | 2 128 2^{128} 2128 | 2 104 2^{104} 2104 |
float 16
参考资料:wikipedia/float16
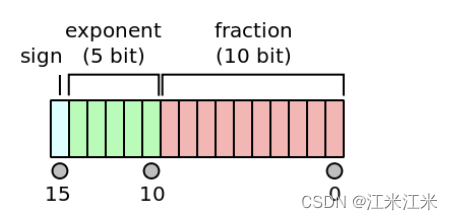
float16的格式如上图。一共十六位。
- 蓝色区域占一位:表示sign。
- 绿色区域占五位:表示exponent。
- 红色区域占十位:表示fraction。
它的计算规则如下:

假如你的 Exponent位全为0,那么fraction位有两种情况。
- fraction全为0,则最终结果为0。
- fraction不为0,则表示一个subnormal numbers,也就是一个非规格化的浮点数。
( − 1 ) s i g n × 2 − 14 × ( f r a c t i o n 1024 ) (-1)^{sign} \times2^{-14} \times(\frac{fraction}{1024}) (−1)sign×2−14×(1024fraction)
假如你的Exponent位全为1,那么fraction位有两种情况。
- fraction全为0, 则最终结果为inf。
- fraction不为0,则最终结果为NaN。
假如你的Exponent为是其它情况,则进行正常的计算。
(
−
1
)
s
i
g
n
×
2
(
e
x
p
o
n
e
n
t
−
15
)
×
(
1
+
f
r
a
c
t
i
o
n
1024
)
(-1)^{sign} \times2^{(exponent-15)} \times(1+\frac{fraction}{1024})
(−1)sign×2(exponent−15)×(1+1024fraction)
因此float16能取到的最小正数是 2 − 14 2^{-14} 2−14,最大数是 2 30 − 15 × ( 1 + 1023 1024 ) = 65504 2^{30-15}\times(1+\frac{1023}{1024}) = 65504 230−15×(1+10241023)=65504。
值得一提的是,float16表示的数是不均匀的,也就是不同的区间范围有着不一样的精度。具体的例子可以从wikipedia/float16上看。下面只给出一点点例子。
| Min | Max | Interval |
|---|---|---|
| 0 | 2 − 13 2^{-13} 2−13 | 2 − 24 2^{-24} 2−24 |
| 2 − 9 2^{-9} 2−9 | 2 − 9 2^{-9} 2−9 | 2 − 19 2^{-19} 2−19 |
| 2 − 5 2^{-5} 2−5 | 2 − 4 2^{-4} 2−4 | 2 − 15 2^{-15} 2−15 |
混合精度
增大神经网络的规模,往往能带来效果上的提升。但是模型规模的增大也意味着更多的内存和计算量需求。综合来说,你的模型表现受到三个方面的限制:
- arithmetic bandwidth.
- memory bandwidth.
- latency.
在神经网络训练中,通常使用的数据类型都是float32,也就是单精度。而所谓的半精度,也就是float16。通过使用半精度,可以解决上面的两个限制。
- arithmetic bandwidth。在GPU上,半精度的吞吐量可以达到单精度的2到8倍。
- memory bandwidth。 半精度的内存占用是单精度的一半。
看起来半精度和单精度相比很有优势,当然,半精度也有半精度自身的问题。
以下部分参考自:https://zhuanlan.zhihu.com/p/79887894
- 溢出错误: float16的范围比float32的范围要小,所以也更容易溢出,更容易出现’NaN’的问题。
- 舍入误差: 当前更新的梯度过小时,即更新的梯度达不到区间间隔的大小时,可能会出现梯度更新失败的情况。
在论文中为了在使用float16的训练的同时又能保证模型的准确性,采用了以下三个方法:
- single-precision master weights and update。
在训练过程在,weights,activation,gradients等数据都用float16存储,同时拷贝一个float32的weights,用来更新。这样float16的梯度在更新是又转为了float32,避免了舍入误差的问题。 - loss-scaling。
为了解决梯度过小的问题,一个比较高效的方法是对计算出的loss进行scale。在更新梯度的时候,只要将梯度转为float32再将scale去掉就可以了。 - accumulation。
网络中的数学计算可以分为以下三类:vector dot-products, reductions and point-wise opeartions。有的运算为了维持精度,必须使用float32,有的则可以使用float16。
代码实现
torch.amp
torch.amp提供了很方便的混合精度方法,一些计算会使用float32的类型而另一些则会用半精度float16。混合精度会尝试给每个操作旋转比较合适的类型。
在实现自动半精度训练时,通常会用到torch.autocast和torch.cuda.amp.GradScaler两个方法。
torch.autocast可以在保证模型表现的情况下,为不同的操作旋转合适的精度。
torch.cuda.amp.GradScaler和它的名字一样,帮助进行梯度的缩放,帮助使用flaot16的网络收敛。就像我们之前说的一样,可以减少溢出的问题。
torch.autocast
autocast提供了两种api。
torch.autocast(“cuda”, args…) is equivalent to torch.cuda.amp.autocast(args…).
torch.autocast(“cpu”, args…) is equivalent to torch.cpu.amp.autocast(args…).
autocast可以以上下文管理器context manager或者装饰器decorator的形式使用。允许你的这部分代码以混合精度的形式运行。
torch.autocast(device_type, dtype=None, enabled=True, cache_enabled=None)
传入参数包括:
- device_type: 当前设备类型,一般是cuda和cpu,也有xpu和hpu。
- dtype:如果你指定了dtype的类型,那么就会使用这个类型作为target dtype,如果没有的话就是按设备获取。
- enabled默认是True,假如你的dtype类型不支持或者device_type不对的时候,enabled就会被改为False,表示不可以使用autocast。
现在来看一下autocast的两种用法,第一种是当作context manger。
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
在这个范围内的model的forward和loss的计算都会以半精度的形式进行。
第二种是当作decorator来使用。你可以直接用它来修饰你的模型的forward()过程。
class AutocastModel(nn.Module):
...
@autocast()
def forward(self, input):
...
这里要注意的是,在autocast范围内的计算结果得到的tensor可能会是float16的类型,当你想用这个结果在autocast的范围外进行别的计算时,要注意把它变回float32。
pytorch tutorial中给出了这样一个例子。
在下面这个例子中,a,b,c,d在创建时的类型都是float32,然后在autocast的范围内进行了torch.mm的计算,torch.mm是矩阵乘法,支持float16的半精度,所以这时你得到的结果e和f都是float16的类型。
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")
with autocast():
# torch.mm is on autocast's list of ops that should run in float16.
# Inputs are float32, but the op runs in float16 and produces float16 output.
# No manual casts are required.
e_float16 = torch.mm(a_float32, b_float32)
# Also handles mixed input types
f_float16 = torch.mm(d_float32, e_float16)
# After exiting autocast, calls f_float16.float() to use with d_float32
g_float32 = torch.mm(d_float32, f_float16.float())
你想用float16类型的f和float32类型的d进行乘法运算是不行的,所以需要先把f变回float32。
pytorch中还给出了在autocast-enabled region的局部禁止使用autocast的例子,就是在代码内再次套一个emabled=False的autocast。
with autocast():
e_float16 = torch.mm(a_float32, b_float32)
with autocast(enabled=False):
# Calls e_float16.float() to ensure float32 execution
# (necessary because e_float16 was created in an autocasted region)
f_float32 = torch.mm(c_float32, e_float16.float())
torch.cuda.amp.GradScaler
在更新的梯度过小时,可能会超出float16数字的边界,导致下溢出或者无法更新的情况。gradient scaling就是为了解决这个问题。
它在神经网络的loss上乘以一个缩放因子,这个缩放因子会随着反向传播传递,使得各个层的梯度都不至于过小。
torch.cuda.amp.GradScaler(init_scale=65536.0, growth_factor=2.0, backoff_factor=0.5, growth_interval=2000, enabled=True)
传入参数包括:
- init_scale:初始的缩放因子。
- growth_factor:你的缩放因子不是固定的,假如在训练过程中又发现了为NaN或inf的梯度,那么这个缩放因子是会按照growth_factor进行更新的。
- backoff_factor:我理解的是和growth_factor相反的过程。
- growth_interval:假如没有出现NaN/inf,也会按照interval进行scale的更新。
来看一下GradScaler的用法。
scaler = torch.cuda.amp.GradScaler()
for epoch in range(0): # 0 epochs, this section is for illustration only
for input, target in zip(data, targets):
with torch.autocast(device_type=device, dtype=torch.float16):
output = net(input)
loss = loss_fn(output, target)
# Scales loss. Calls ``backward()`` on scaled loss to create scaled gradients.
scaler.scale(loss).backward()
# ``scaler.step()`` first unscales the gradients of the optimizer's assigned parameters.
# If these gradients do not contain ``inf``s or ``NaN``s, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(opt)
# Updates the scale for next iteration.
scaler.update()
opt.zero_grad() # set_to_none=True here can modestly improve performance
我们来看一下在这个过程中GradScaler()都做了什么。
首先,在计算得到loss之后,出现了。
scaler.scale(loss).backward()
用我们的scaler中的scale方法对得到的loss进行缩放后,再进行backward()。scale方法也比较简单,返回的结果可以直接理解为我们的loss和缩放因子scale_factor的乘积。
然后会进行scaler.step(opt),这里的opt是我们的optimizer。我们常用的应该是opt.step()。也就是说在这里optimizer的step()梯度更新的步骤被放到scaler里完成了。
def step(self, optimizer, *args, **kwargs):它的作用是这样的。它首先会确认一下梯度里面是否存在Inf和NaN的情况,如果有的话,optimizer.step()这个步骤就会被跳过去,避免引发一些错误;如果没有的话,就会用unscale过的梯度来进行optimizer.step()。
最后呢则是 scaler.update(),也就是其中的scale的更新过程。
简而言之,scaler总共做了三件事:
- 对loss进行scale,这样在backward的时候防止梯度的underflow。
- 对梯度进行unscale,用于更新。
- 更新scaler中的scale factor。
GradScaler with penalty
tutorial中还额外提到了到penalty的情况。
在你没有使用混合精度的情况下,你的grad penalty是这样计算的。以L2 loss为例:
for input, target in data:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# Creates gradients
grad_params = torch.autograd.grad(outputs=loss, inputs=model.parameters(), create_graph=True)
# Computes the penalty term and adds it to the loss
grad_norm = 0
for grad in grad_params:
grad_norm += grad.pow(2).sum()
grad_norm = grad_norm.sqrt()
loss = loss + grad_norm
loss.backward()
# clip gradients here, if desired
optimizer.step()
对于grad_params中的每一项,都求他的平方和,最后对grad_norm开根号,作为loss和我们的模型的预测损失组合在一起使用。起到了一种gradient regularization的作用。
当你要使用scaler时,因为你的loss是scale过的,所以你的梯度也都受到了影响,你应该把它们先变回去unscale的状态,再进行计算。
scaled_grad_params = torch.autograd.grad(outputs=scaler.scale(loss), inputs=model.parameters(), create_graph=True)
注意看这里用的是scale过的loss,得到的grad也是scale过的,所以你需要自己手动计算来得到unscale的grad和penalty loss。
inv_scale = 1./scaler.get_scale()
# scale_factor是缩放倍数,我们要unscale所以用1/scale_factor
grad_params = [p * inv_scale for p in scaled_grad_params]
之后就是正常的计算过程:
# Computes the penalty term and adds it to the loss
with autocast(device_type='cuda', dtype=torch.float16):
grad_norm = 0
for grad in grad_params:
grad_norm += grad.pow(2).sum()
grad_norm = grad_norm.sqrt()
loss = loss + grad_norm
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()