转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn]
目录
背景介绍
未来改进
参考代码
背景介绍
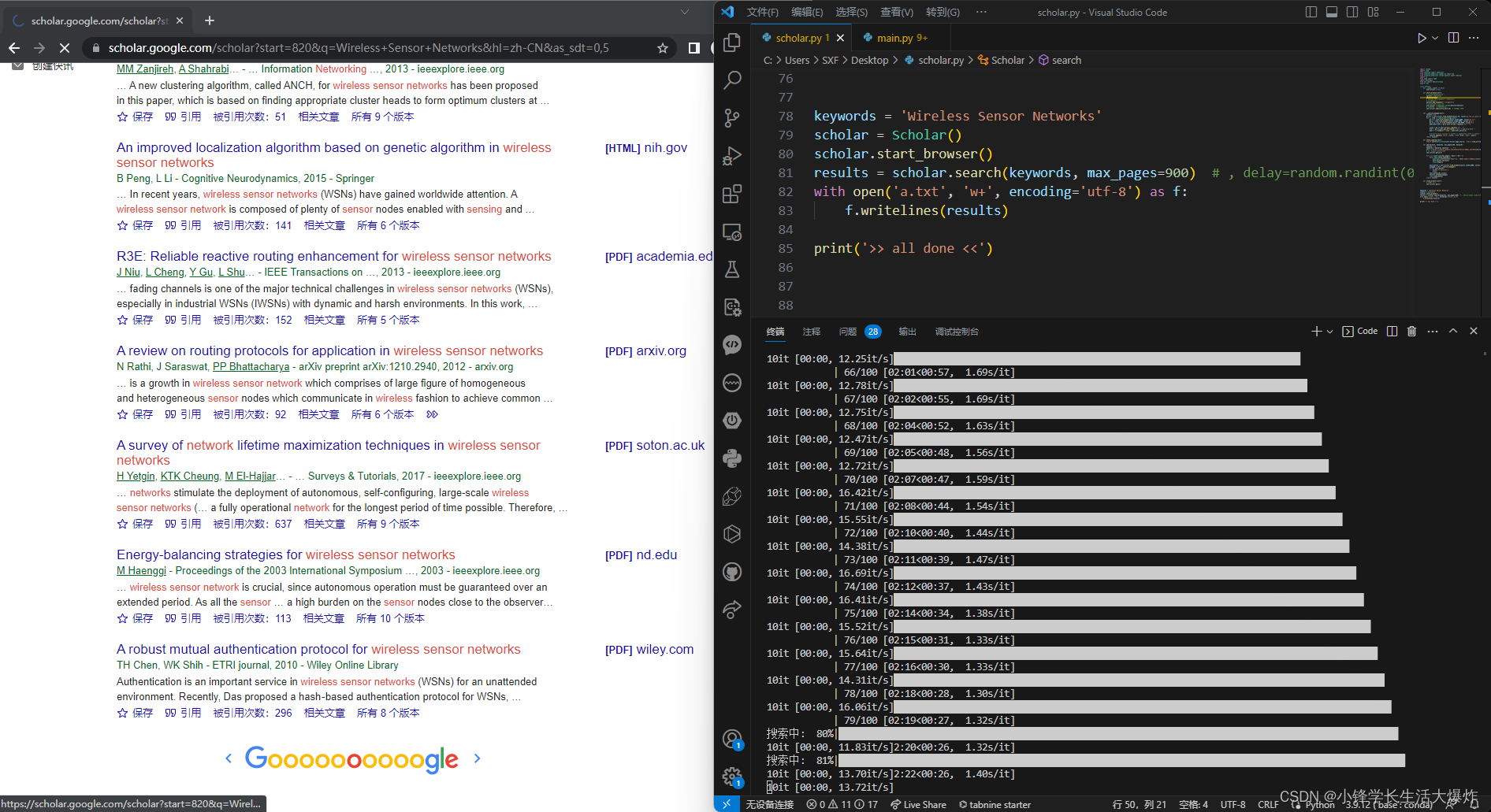
- 通过自动点击页面来抓取文章信息。这个脚本对于用来看某个关键词在近几年的研究趋势很有用~
- 半自动:当遇到谷歌人机验证,需要手动完成。
- 注意将selenium升级到最新版本,他会自动下载chrome内核。
- 可对脚本修改,来抓取更多数据、或者统计更多信息。
- 注释非常详细;
未来改进
- 抓取一页,写入一页,免得中途崩溃数据全没;
- 更多异常页面检测(目前很少遇到);
- 抓取和整理更多信息;
- 记录坐标,断点续抓;
- 更换ip;
参考代码
import random
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import re
from tqdm import tqdm
import pyautogui
from bs4 import BeautifulSoup
import lxml
import pandas as pd
from enum import Enum
class Errors(Enum):
SUCCESS = '成功'
SERVER_ERROR = '服务器错误'
class Scholar:
def __init__(self) -> None:
self.driver = None
self.results = []
def start_browser(self, wait_time=10):
# 创建ChromeOptions对象
options = Options()
# 启用无头模式
# options.add_argument("--headless")
# 启用无痕模式
options.add_argument("--incognito")
options.add_argument("--disable-domain-reliability")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-client-side-phishing-detection")
options.add_argument("--no-first-run")
options.add_argument("--use-fake-device-for-media-stream")
options.add_argument("--autoplay-policy=user-gesture-required")
options.add_argument("--disable-features=ScriptStreaming")
options.add_argument("--disable-notifications")
options.add_argument("--disable-popup-blocking")
options.add_argument("--disable-save-password-bubble")
options.add_argument("--mute-audio")
options.add_argument("--no-sandbox")
options.add_argument("--disable-gpu")
options.add_argument("--disable-extensions")
options.add_argument("--disable-software-rasterizer")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-webgl")
options.add_argument("--allow-running-insecure-content")
options.add_argument("--no-default-browser-check")
options.add_argument("--disable-full-form-autofill-ios")
options.add_argument("--disable-autofill-keyboard-accessory-view[8]")
options.add_argument("--disable-single-click-autofill")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--disable-infobars")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-blink-features")
# 禁用实验性QUIC协议
options.add_experimental_option("excludeSwitches", ["enable-quic"])
# 创建Chrome浏览器实例
self.driver = webdriver.Chrome(options=options)
# 等待页面加载完成
self.driver.implicitly_wait(wait_time)
def __search_onepage(self):
"""爬取当前页面文章的的信息"""
results = []
if not self.check_element_exist(check_type='ID', value='gs_res_ccl_mid'):
print('>> 当前页面不存在文章列表')
return []
gs_scl = self.driver.find_element(by=By.ID, value='gs_res_ccl_mid').find_elements(by=By.CLASS_NAME, value='gs_scl')
for i, item in tqdm(enumerate(gs_scl)):
gs_rt = item.find_element(by=By.CLASS_NAME, value='gs_rt')
gs_a = item.find_element(by=By.CLASS_NAME, value='gs_a')
gs_rt_a = gs_rt.find_element(by=By.TAG_NAME, value='a') if self.check_element_exist(check_type='TAG_NAME', value='a', source=gs_rt.get_attribute('innerHTML')) else None
publisher_info = gs_a.text.strip().replace('\n', '')
# 论文标题
title = gs_rt.text.strip().replace('\n', '').split(']')[-1].strip()
# 论文链接
href = gs_rt_a.get_attribute('href') if gs_rt_a else ''
# 发表年份
year = re.findall(r'\d{4}', publisher_info)[-1]
# print(f'[{i}] {title} => {href} => {publisher_info} => {year}')
results.append({'title': title, 'href':href, 'year': year})
return results
def check_element_exist(self, value, check_type='CLASS_NAME', source=None) -> bool:
"""检查页面是否存在指定元素"""
page_source = source if source else self.driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
if check_type == 'ID':
return len(soup.find_all(id=value)) != 0
elif check_type == 'CLASS_NAME':
return len(soup.find_all(class_=value)) != 0
elif check_type == 'TAG_NAME':
return len(soup.find_all(value)) != 0
elif check_type == 'FULL':
return value in page_source
else:
print(f'>> 检查条件[{check_type}]不对')
return False
def check_captcha(self) -> bool:
"""检查是否需要人机验证;一个是谷歌学术的、一个是谷歌搜索的"""
return self.check_element_exist(check_type='ID', value='gs_captcha_f') or \
self.check_element_exist(check_type='ID', value='captcha-form')
def process_error(self, error: Errors) -> bool:
"""尽可能尝试解决错误"""
success = False
if error == Errors.SERVER_ERROR:
pass
return success
def check_error(self, try_solve = True) -> Errors:
"""检查当前页面是否出错"""
error = Errors.SUCCESS
if self.check_element_exist(check_type='FULL', value='服务器错误'):
error = Errors.SERVER_ERROR
# 尝试解决错误
if try_solve and error != Errors.SUCCESS:
error = Errors.SUCCESS if self.process_error(error) else error
return error
def __scroll2bottom(self):
# 将滚动条移动到页面的底部
self.driver.switch_to.default_content()
js = "var q=document.documentElement.scrollTop=100000"
self.driver.execute_script(js)
def search(self, keywords, max_pages=100, delay=0):
keywords = keywords.replace(' ', '+')
url = f'https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q={keywords}&btnG='
# 打开Google Scholar网站
self.driver.get(url)
for _ in tqdm(range(max_pages), desc='搜索中'):
while self.check_captcha():
pyautogui.alert(title='状态异常', text='请手动完成人机验证后,点击“已完成”', button='已完成')
self.driver.refresh()
time.sleep(2)
if self.check_error() != Errors.SUCCESS:
if pyautogui.confirm(text='请检查页面出现了什么问题;\n解决后,点击“确定”将会重试;\n否则,点击“取消”提前结束脚本;', title='状态异常', buttons=['确定', '取消']) == '取消':
print('>> 提前结束')
break
time.sleep(2)
onepage = self.__search_onepage()
if not onepage:
print('>> 当前页为空, 重试')
self.driver.refresh()
time.sleep(2)
continue
if not self.check_element_exist(check_type='CLASS_NAME', value='gs_ico_nav_next'):
print('>> 全部结束')
break
self.__scroll2bottom()
time.sleep(0.1)
self.driver.find_element(by=By.CLASS_NAME, value="gs_ico_nav_next").click()
self.results.extend(onepage)
time.sleep(delay)
return self.results
def close_browser(self):
# 关闭浏览器
self.driver.quit()
def save_file(self, filename='scholar.csv', nodup=False):
unique_data = self.results
if nodup:
# 根据href字段进行去重
unique_data = [dict(t) for t in {tuple(d.items()) for d in unique_data}]
print(f'>> 去重效果:{len(self.results)} => {len(unique_data)}')
pd.DataFrame(unique_data).to_excel(filename, index=False, encoding='utf-8')
def statistical_information(self):
pass
if __name__ == '__main__':
keywords = input('>> 请输入搜索关键词: ').strip() or 'Wireless Sensor Networks'
scholar = Scholar()
scholar.start_browser(wait_time=60)
results = scholar.search(keywords, max_pages=1, delay=random.randint(0, 0))
scholar.close_browser()
scholar.save_file(filename=f'output_{"_".join(keywords.split())}.xlsx', nodup=True)
print('>> all done <<')








![实战演练Python数据分析[pandas]](https://img-blog.csdnimg.cn/9776773e377f4440be714dda6e958b7d.png)


