文章目录
- @[TOC](文章目录)
- 前言
- 一、MoviesLens数据集
- 二、美国1880-2010年的婴儿名字
- 三、美国农业部视频数据库
- 四、2012年联邦选举委员会数据库
- 总结
文章目录
- @[TOC](文章目录)
- 前言
- 一、MoviesLens数据集
- 二、美国1880-2010年的婴儿名字
- 三、美国农业部视频数据库
- 四、2012年联邦选举委员会数据库
- 总结
前言
本篇文章出自于《利用Python进行数据分析》示例数据
请结合提供的示例数据,分析代码的功能,并进行数据分析与可视化拓展。本篇文章通过四个例子,通过MoviesLens数据集、美国1880-2010年的婴儿名字、美国农业部视频数据库、2012年联邦选举委员会数据库来进行着重讲解。
一、MoviesLens数据集
GroupLens实验室提供了一些从MoviesLens用户那里收集的20世纪90年代末到21世纪初的电影评分数据的集合。浙西数据提供了电影的评分、流派、年份和观众数据(年龄、邮编、性别、职业)。
MovisLens1M数据集包含6000个用户对4000部电影的100万个评分。数据分布在三个表格之中:分别包含评分、用户信息和电影信息。
(1) 首先载入一些python数据分析的库,并且给予它们简称。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
(2)
unames = ["user_id", "gender", "age", "occupation", "zip"]
users = pd.read_table("datasets/movielens/users.dat", sep="::",
header=None, names=unames, engine="python")
rnames = ["user_id", "movie_id", "rating", "timestamp"]
ratings = pd.read_table("datasets/movielens/ratings.dat", sep="::",
header=None, names=rnames, engine="python")
mnames = ["movie_id", "title", "genres"]
movies = pd.read_table("datasets/movielens/movies.dat", sep="::",
header=None, names=mnames, engine="python")
- unames代表用户信息
- rnames代表评分信息
- mnames代表电影信息
下面介绍一下pd.read_tablie的用法:
-
第一个参数是filepath_or_buffer(文件)
一般指读取文件的路径。比如读取csv文件。 -
第二个参数是sep(分隔符)
指定分隔符。如果不指定参数,默认逗号分隔 -
第三个参数是 header(表头)
表头即列名,默认第0行数据为表头 -
第四个参数是names(列名)
用于原始数据无表头,又想设置列名的情况。 -
第五个参数是engine(引擎)
pandas解析数据时用的引擎。pandas 目前的解析引擎提供两种:c、python,默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。如果使用 c 引擎没有的特性时,会自动退化为 python 引擎。
当然,参数不止这些,但需要使用的话可搜索pandas文档。
分析功能:
- 用户信息表(users):这段代码从文件users.dat中读取用户信息数据,并创建了一个名为users的DataFrame对象。使用read_table函数指定了文件路径、分隔符为::,没有指定列名行,而是使用了自定义的列名列表unames。engine="python"参数指定使用Python解析引擎。数据中的列包括用户ID、性别、年龄、职业和邮编。
- 评分表(ratings):这段代码从文件ratings.dat中读取评分数据,并创建了一个名为ratings的DataFrame对象。同样,使用了read_table函数指定了文件路径、分隔符为::,没有指定列名行,而是使用了自定义的列名列表rnames。数据中的列包括用户ID、电影ID、评分和时间戳。
- 电影信息表(movies):这段代码从文件movies.dat中读取电影信息数据,并创建了一个名为movies的DataFrame对象。同样,使用了read_table函数指定了文件路径、分隔符为::,没有指定列名行,而是使用了自定义的列名列表mnames。数据中的列包括电影ID、标题和流派。
(3)
users.head(5)
ratings.head(5)
movies.head(5)
ratings
输出结果:
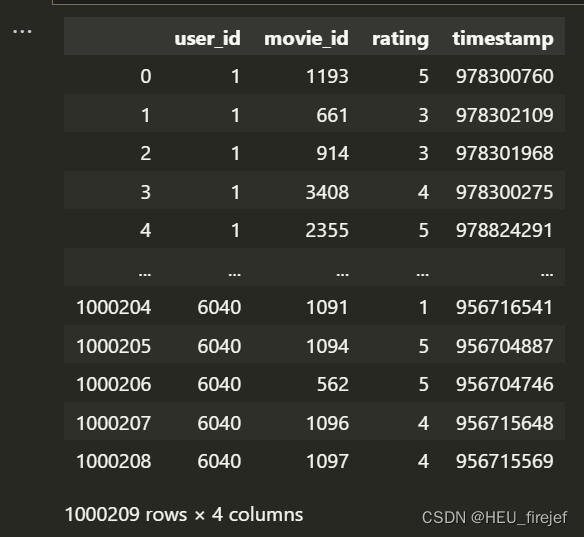
分析功能:
- 上述代码将打印出users、ratings和movies的前5行数据,并显示ratings的整个DataFrame。
(4)
data = pd.merge(pd.merge(ratings, users), movies)
data
data.iloc[0]
输出结果:
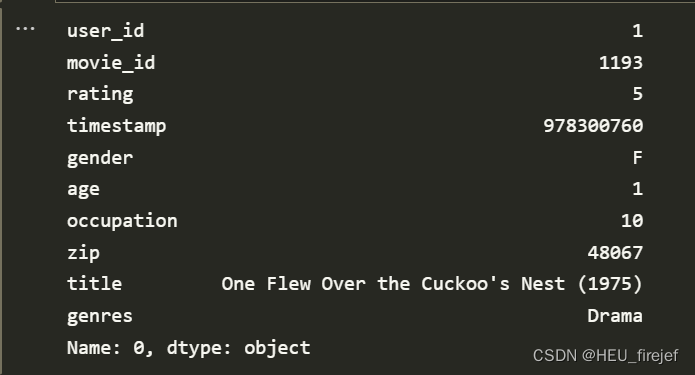
分析功能:
- 使用pd.merge()函数将ratings、users和movies三个DataFrame进行合并,并将结果存储在data中。接下来,使用data打印了整个DataFrame和第一行的数据。
(5)
mean_ratings = data.pivot_table("rating", index="title",
columns="gender", aggfunc="mean")
mean_ratings.head(5)
输出结果:
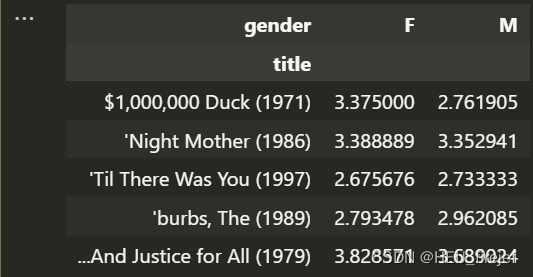
分析功能:
- pivot_table()函数以data作为数据源,通过指定"rating"作为值列(要计算的列)、"title"作为行索引列(要进行分组的列)以及"gender"作为列索引列(要进行分组的列),并使用"mean"作为聚合函数,计算了不同电影在不同性别下的平均评分。
- 通过执行mean_ratings.head(5),可以查看前5行的结果。
(6)
ratings_by_title = data.groupby("title").size()
ratings_by_title.head()
active_titles = ratings_by_title.index[ratings_by_title >= 250]
active_titles
输出结果:

分析功能:
- 首先使用groupby()函数对data进行分组,按照电影标题(“title”)进行分组,并使用size()函数计算每个电影标题对应的评分数量。
- 接下来,使用head()函数查看了前几行的结果,其中每一行代表一个电影标题,对应的值表示该电影标题的评分数量。
- 然后,根据评分数量筛选出活跃的电影标题,通过使用index属性获取评分数量大于等于250的电影标题索引。这样得到的active_titles是一个包含活跃电影标题的索引列表。
(7)
mean_ratings = mean_ratings.loc[active_titles]
mean_ratings
输出结果:
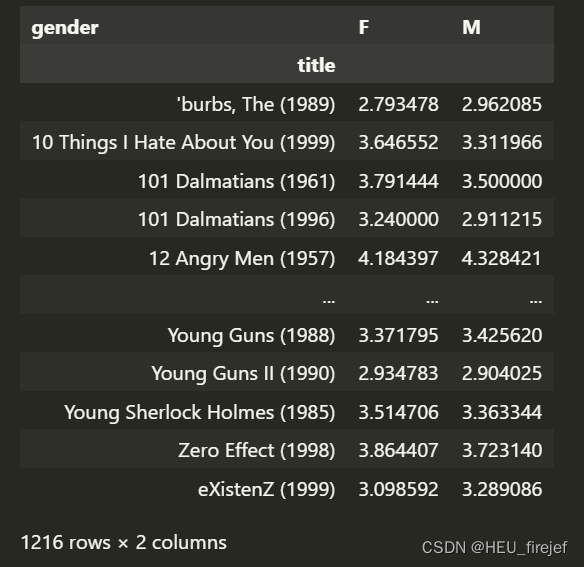
分析功能:
- 使用loc索引器将mean_ratings数据框筛选为只包含活跃电影标题的部分。active_titles是一个索引列表,代表了活跃电影标题的索引。
(8)
mean_ratings = mean_ratings.rename(index={"Seven Samurai (The Magnificent Seven) (Shichinin no samurai) (1954)":
"Seven Samurai (Shichinin no samurai) (1954)"})
功能分析:
- 使用rename()函数将索引中的一个电影标题修改为新的标题。具体来说,将索引中的 “Seven Samurai (The Magnificent Seven) (Shichinin no samurai) (1954)” 修改为 “Seven Samurai (Shichinin no samurai) (1954)”。
(9)
top_female_ratings = mean_ratings.sort_values("F", ascending=False)
top_female_ratings.head()
输出结果:
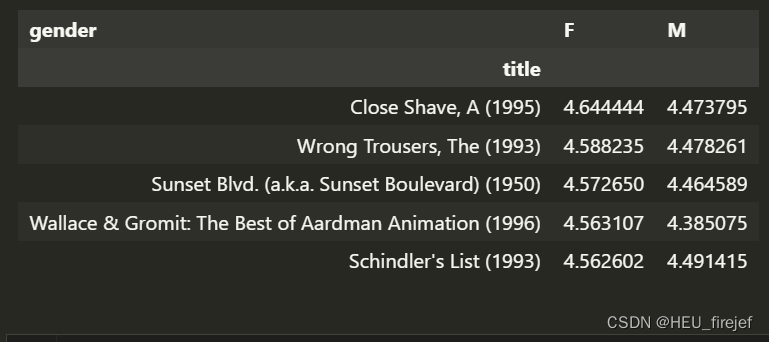
分析功能:
- 使用sort_values()函数根据女性观众的平均评分对mean_ratings进行降序排序。
- 通过top_female_ratings.head(),可以查看排序后的前几行结果。
(10)
mean_ratings["diff"] = mean_ratings["M"] - mean_ratings["F"]
分析功能:
- 首先,代码使用mean_ratings[“M”] - mean_ratings[“F”]计算了男性和女性用户对每部电影的平均评分之差。
- 然后,使用赋值语句将结果存储在mean_ratings的新列"diff"中。
- 最终,mean_ratings 多了一列"diff",表示男性和女性用户对每部电影的平均评分之差。
(11)
sorted_by_diff = mean_ratings.sort_values("diff")
sorted_by_diff.head()
输出结果:
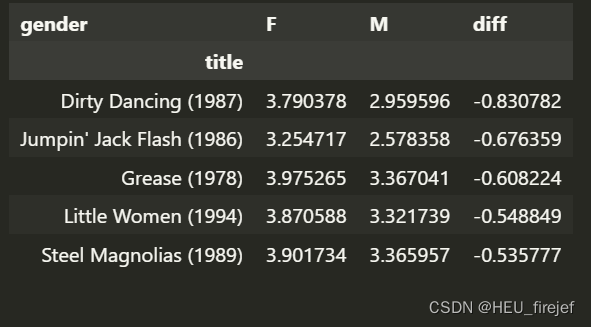
分析功能:
- 这段代码使用sort_values函数对mean_ratings按照"diff"列进行排序。sort_values函数的第一个参数是要排序的列名,这里是"diff"。由于没有指定ascending参数,所以默认按升序排序。
- 最终生成一个新的DataFrame对象,命名为sorted_by_diff。然后,代码使用.head()函数显示了sorted_by_diff的前五行数据。
(12)
sorted_by_diff[::-1].head()
输出结果:
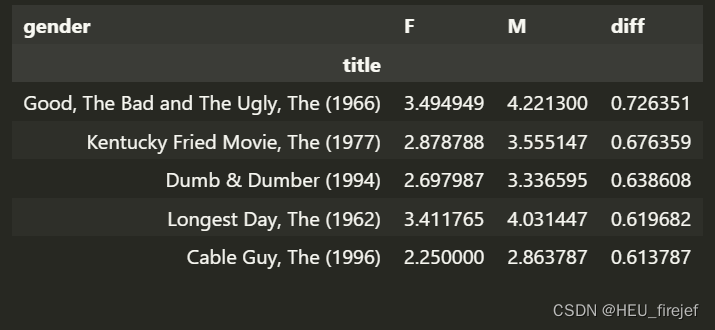
分析功能:
- 这段代码使用切片语法[::-1]来翻转sorted_by_diff的顺序,然后使用.head()函数显示了翻转后的前五行数据。
(13)
rating_std_by_title = data.groupby("title")["rating"].std()
rating_std_by_title = rating_std_by_title.loc[active_titles]
rating_std_by_title.head()
输出结果:
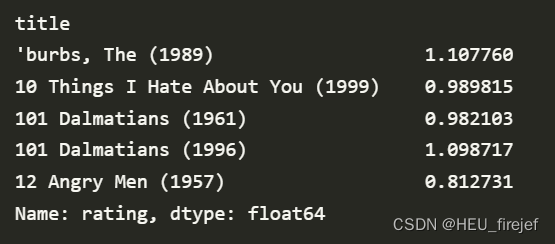
分析功能:
- 这段代码首先使用 groupby 函数对 data 按照 “title” 列进行分组,然后使用 std 函数计算每组的标准差,也就是每部电影的评分标准差。最终生成一个新的 Series 对象,命名为 rating_std_by_title。
- 接下来,代码使用 .loc[] 选择器来选择 rating_std_by_title 中行索引在 active_titles 中的行。最终,rating_std_by_title 只包含了评分数量大于等于 250 的电影的评分标准差数据。
- 然后,代码使用 .head() 函数显示了 rating_std_by_title 的前五行数据。
(14)
rating_std_by_title.sort_values(ascending=False)[:10]
输出结果:
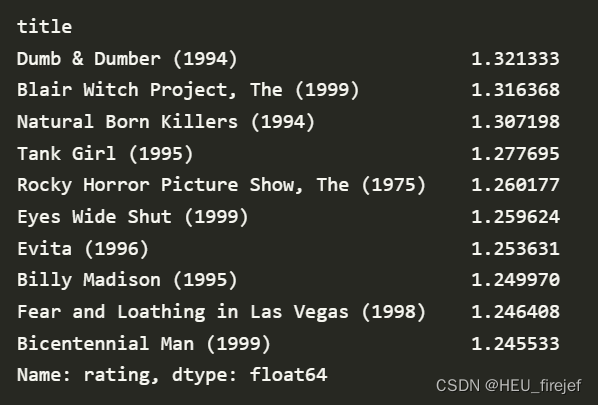
分析功能:
- 这段代码使用 sort_values 函数对 rating_std_by_title 进行排序。sort_values 函数的第一个参数 ascending=False 表示按降序排序。然后,使用切片语法 [:10] 来选择排序后的前十行数据。
(15)
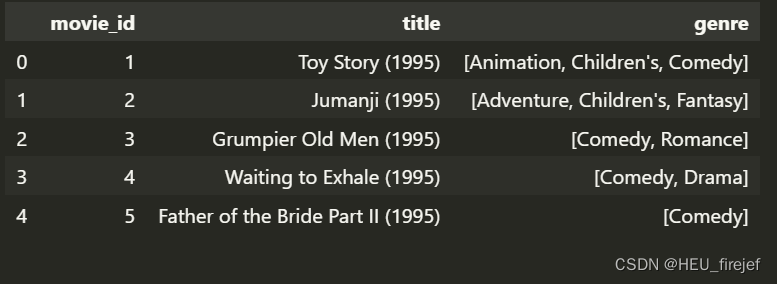
movies["genres"].head()
movies["genres"].head().str.split("|")
movies["genre"] = movies.pop("genres").str.split("|")
movies.head()
输出结果:
分析功能:
- 这段代码首先使用 .head() 函数显示了 movies 的 “genres” 列的前五行数据。
- 接下来,代码使用 .str.split(“|”) 函数来分割 “genres” 列中的字符串。.str.split(“|”) 函数会将每个字符串按照 “|” 分隔符分割成一个列表。然后,代码使用 .head() 函数显示了分割后的前五行数据。
- 然后,代码使用 pop 函数弹出了 movies 的 “genres” 列,并将其分割后的结果存储在新列 “genre” 中。pop 函数会从 DataFrame 对象中弹出指定的列,并返回该列的数据。
- 最后,代码使用 .head() 函数显示了更新后的 movies 的前五行数据。现在,movies 多了一列 “genre”,表示电影类型的列表。
(16)
movies_exploded = movies.explode("genre")
movies_exploded[:10]
输出结果:
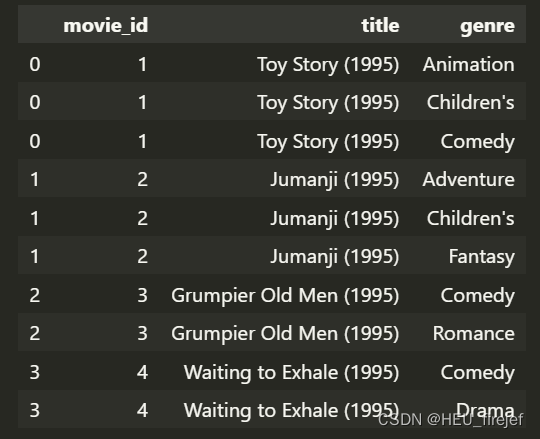
分析功能;
- 这段代码使用 explode 函数将 movies 的 “genre” 列拆分成多行。explode 函数会将指定列中的列表拆分成多行,每行包含列表中的一个元素。
- 最终生成一个新的 DataFrame 对象,命名为 movies_exploded。然后,代码使用切片语法 [:10] 来选择前十行数据。
(17)
ratings_with_genre = pd.merge(pd.merge(movies_exploded, ratings), users)
ratings_with_genre.iloc[0]
genre_ratings = (ratings_with_genre.groupby(["genre", "age"])
["rating"].mean()
.unstack("age"))
genre_ratings[:10]
输出结果:
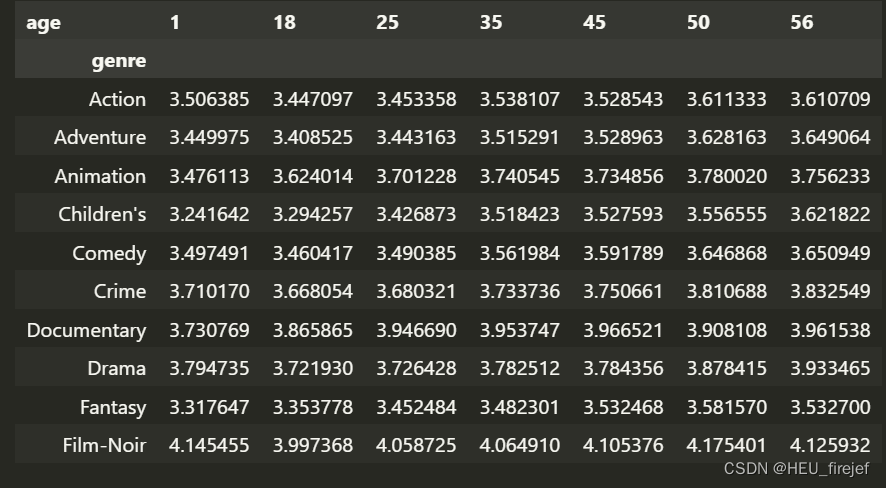
分析功能:
- 这段代码首先使用 pd.merge() 函数将 movies_exploded、ratings 和 users 三个 DataFrame 对象合并在一起。最终生成一个新的 DataFrame 对象,命名为 ratings_with_genre。
- 接下来,代码使用 .iloc[0] 选择器来获取 ratings_with_genre 的第一行数据。
- 然后,代码使用 groupby 函数对 ratings_with_genre 按照 “genre” 和 “age” 列进行分组,然后使用 mean 函数计算每组的平均值,也就是每个类型和年龄段的平均评分。最后使用 unstack 函数将 “age” 列拆分成多列。
- 最终生成一个新的 DataFrame 对象,命名为 genre_ratings。然后,代码使用切片语法 [:10] 来选择前十行数据。
二、美国1880-2010年的婴儿名字
美国社会保障局(SSA)提供了从1880年至现在的婴儿姓名频率的数据。可以使用这些数据做很多事情:
根据给定的名字对婴儿名字随时间的比例进行可视化
确定一个名字的相对排位
确定每年最受欢迎的名字,或者流行程度最高或最低的名字
(1)
!head -n 10 datasets/babynames/yob1880.txt
分析功能:
- 这段代码使用了Python中的pandas库来读取一个名为"yob1880.txt"的CSV文件。该文件包含了1880年的婴儿名字相关的数据,包括"姓名"、“性别"和"出生数"等列。通过在names参数中指定"姓名”、"性别"和"出生数"这些列的名称,可以将适当的列标签赋予DataFrame。
(2)
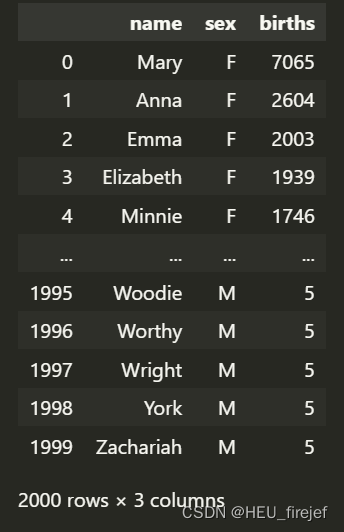
names1880 = pd.read_csv("datasets/babynames/yob1880.txt",
names=["name", "sex", "births"])
names1880
输出结果:
分析功能:
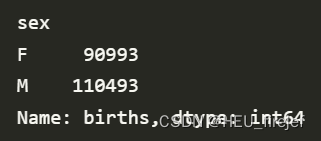
- 首先,groupby(“sex”) 将数据按照 “sex” 列的不同取值进行分组。这将创建两个组,一个是男性 (“M”),另一个是女性 (“F”)。
- 然后,[“births”] 选择了分组后的每个组中的 “births” 列。
- 最后,.sum() 对选定的 “births” 列进行求和操作,计算每个组中的出生数总和。
- 总结起来,这行代码的作用是计算在名为 names1880 的 DataFrame 中,按照性别分组后,每个组的出生数总和。
(3)
names1880.groupby("sex")["births"].sum()
输出结果:
分析功能:
- 首先,创建了一个空列表pieces来存储每年的DataFrame。
- 然后,通过循环从1880年到2010年(不包括2011年),构建每个年份对应的文件路径。文件路径中的年份是通过{year}的方式动态插入到字符串中的。
- 接下来,使用pd.read_csv函数读取每个文件,并指定列名为[“name”, “sex”, “births”],将每个年份的数据读取为一个DataFrame。
- 随后,通过添加一个名为"year"的列来为每个DataFrame增加一个年份信息,该列的值为当前循环的年份。
- 每次循环,将读取的DataFrame追加到pieces列表中。
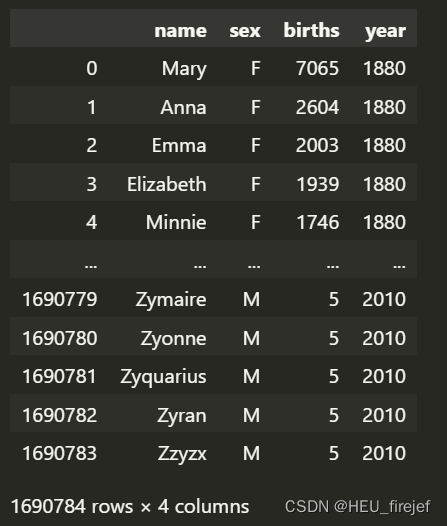
- 循环结束后,使用pd.concat函数将所有的DataFrame连接成一个单一的DataFrame,设置ignore_index=True参数来重置索引,确保索引是连续的。
- 最终得到的names DataFrame 包含了从1880年到2010年的所有婴儿名字数据,其中每一行表示一个特定年份的婴儿名字数据。
(4)
pieces = []
for year in range(1880, 2011):
path = f"datasets/babynames/yob{year}.txt"
frame = pd.read_csv(path, names=["name", "sex", "births"])
# Add a column for the year
frame["year"] = year
pieces.append(frame)
# Concatenate everything into a single DataFrame
names = pd.concat(pieces, ignore_index=True)
names
输出结果:
分析功能:
- 首先,total_births是通过使用pivot_table函数计算得到的。该函数用于创建数据透视表,其中"births"列被用作值,"year"列作为行索引,"sex"列作为列索引。聚合函数sum被应用于"births"列,以计算每个年份和性别的出生总数。这样,total_births是一个新的DataFrame,其中的行表示年份,列表示性别,单元格的值是每个年份和性别的出生总数。
- 接下来,total_births.tail()用于显示total_births DataFrame 的最后几行,这将输出最近几年的数据。
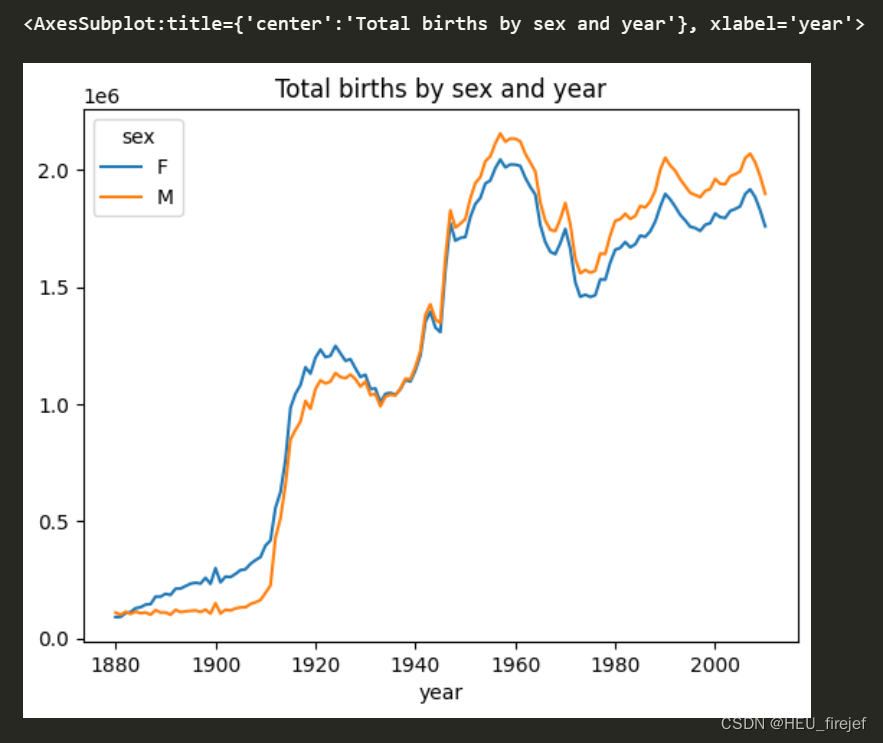
- 最后,total_births.plot(title=“Total births by sex and year”)用于将total_births DataFrame 的数据绘制成一个图表。图表的标题为"Total births by sex and year",横轴表示年份,纵轴表示出生总数。图表的形式可以根据数据的分布和趋势进行进一步的分析和可视化。
(5)
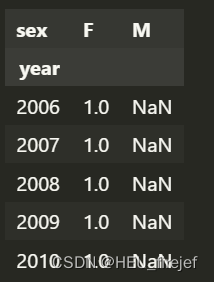
total_births = names.pivot_table("births", index="year",
columns="sex", aggfunc=sum)
total_births.tail()
total_births.plot(title="Total births by sex and year")
输出结果:
分析功能:
- 函数add_prop接受一个分组(group)作为输入,并对该分组进行操作。在这种情况下,分组是根据"year"和"sex"两列进行的。在函数内部,通过计算每个分组中的"births"列占该分组总出生数的比例,将结果保存在一个名为"prop"的新列中。这是通过将"births"列除以该分组中"births"列的总和来实现的。最后,函数返回被操作后的分组。
- 接下来,names DataFrame 被按照"year"和"sex"两列进行分组,并通过groupby函数进行分组操作。group_keys=False参数表示不将分组的键作为索引。
- 然后,apply函数将add_prop函数应用于每个分组。这将在每个分组上执行add_prop函数中定义的操作,即计算每个分组中"births"列的比例,并将结果保存在"prop"列中。
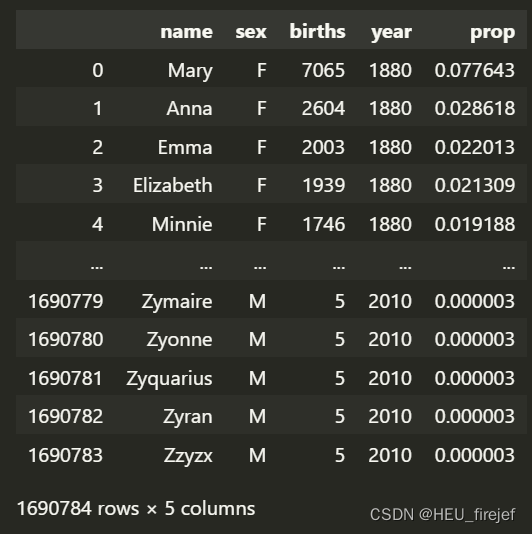
- 最终,返回一个新的DataFrame names,其中包含添加了"prop"列的每个分组的数据。这使得我们可以分析每个年份和性别中每个名字在其所在组中的比例。
(6)
def add_prop(group):
group["prop"] = group["births"] / group["births"].sum()
return group
names = names.groupby(["year", "sex"], group_keys=False).apply(add_prop)
names
输出结果:
分析功能:
- 首先,groupby([“year”, “sex”]) 将数据按照 “year” 和 “sex” 两列进行分组。这将创建一个多级索引,其中第一级索引为 “year”,第二级索引为 “sex”。
- 然后,[“prop”] 选择了分组后的每个组中的 “prop” 列。这是在之前的步骤中使用 add_prop 函数计算并添加到 DataFrame 中的比例列。
- 最后,.sum() 对选定的 “prop” 列进行求和操作,计算每个组中的比例总和。
(7)
names.groupby(["year", "sex"])["prop"].sum()
输出结果:
分析功能:
- get_top1000 函数接受一个分组(group)作为输入,并根据"births"列的值降序排序该分组。然后,返回排序后的前1000行数据。这样,该函数返回每个分组中出生数最高的1000个记录。
- 接下来,names DataFrame 被按照 “year” 和 “sex” 两列进行分组,并使用 groupby 函数进行分组操作。这将创建一个分组对象 grouped
- 然后,apply 函数将 get_top1000 函数应用于每个分组。这将在每个分组上执行 get_top1000 函数中定义的操作,即按出生数降序排序,并返回每个分组中的前1000行数据。
- 最后,将返回的结果赋值给 top1000,它将是一个包含每个年份和性别组合中出生数最高的1000个记录的新 DataFrame。
(8)
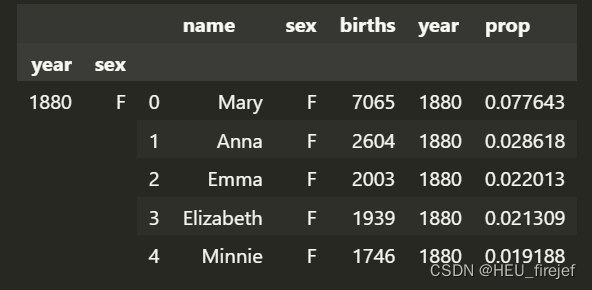
def get_top1000(group):
return group.sort_values("births", ascending=False)[:1000]
grouped = names.groupby(["year", "sex"])
top1000 = grouped.apply(get_top1000)
top1000.head()
输出结果:
分析功能:
- 首先,top1000.reset_index(drop=True) 用于重置 top1000 DataFrame 的索引。设置 drop=True 参数表示重置索引时不保留原有的索引列。通过重置索引,可以将索引重新设置为连续的整数序列。
- 然后,top1000.head() 用于显示重置索引后的 top1000 DataFrame 的前几行数据。这将输出重置索引后的 DataFrame 的前几行,以便查看数据。
- 总结起来,这段代码的作用是将 top1000 DataFrame 的索引重置为连续的整数序列,并显示重置索引后的 DataFrame 的前几行数据。这样做可以更方便地访问和处理数据,并确保索引的一致性
(9)
top1000 = top1000.reset_index(drop=True)
(10)
top1000.head()
输出结果:
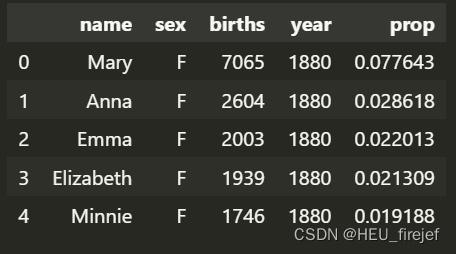
分析功能:
- 首先,boys = top1000[top1000[“sex”] == “M”] 用于从 top1000 DataFrame 中筛选出性别为男性的记录。这将创建一个新的 DataFrame boys,其中包含了所有性别为男性的记录。
- 接下来,girls = top1000[top1000[“sex”] == “F”] 用于从 top1000 DataFrame 中筛选出性别为女性的记录。这将创建一个新的 DataFrame girls,其中包含了所有性别为女性的记录。
- 然后,total_births = top1000.pivot_table(“births”, index=“year”, columns=“name”, aggfunc=sum) 通过使用 pivot_table 函数,计算每个年份和姓名组合的出生总数。该函数以 “births” 列作为值,“year” 列作为行索引,“name” 列作为列索引。聚合函数 sum 被应用于 “births” 列,以计算每个年份和姓名组合的出生总数。这样,total_births 是一个新的 DataFrame,其中的行表示年份,列表示姓名,单元格的值是每个年份和姓名组合的出生总数。
- 接下来,total_births.info() 用于显示 total_births DataFrame 的相关信息,包括每列的数据类型和非空值的数量等。
- 然后,subset = total_births[[“John”, “Harry”, “Mary”, “Marilyn”]] 从 total_births DataFrame 中筛选出特定的姓名列,包括 “John”、“Harry”、“Mary” 和 “Marilyn”。这将创建一个新的 DataFrame subset,其中只包含这些特定姓名的列。
- 最后,subset.plot(subplots=True, figsize=(12, 10), title=“Number of births per year”) 用于将 subset DataFrame 的数据绘制成一个图表。每个姓名列将显示在不同的子图中,子图的排列方式为垂直布局。图表的大小为 (12, 10),标题为 “Number of births per year”。图表可以用来观察每个姓名随时间的出生数变化情况。
(11)
boys = top1000[top1000["sex"] == "M"]
girls = top1000[top1000["sex"] == "F"]
(12)
total_births = top1000.pivot_table("births", index="year",
columns="name",
aggfunc=sum)
(13)
total_births.info()
subset = total_births[["John", "Harry", "Mary", "Marilyn"]]
subset.plot(subplots=True, figsize=(12, 10),
title="Number of births per year")
输出结果:
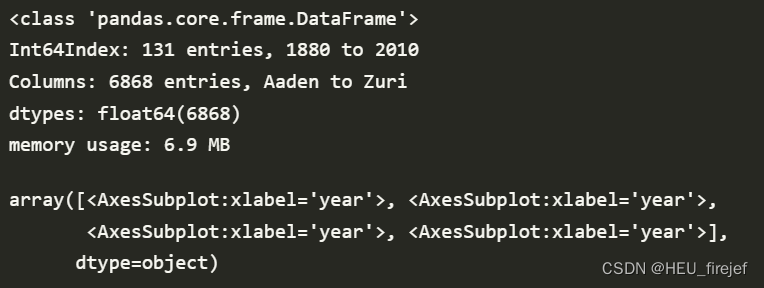
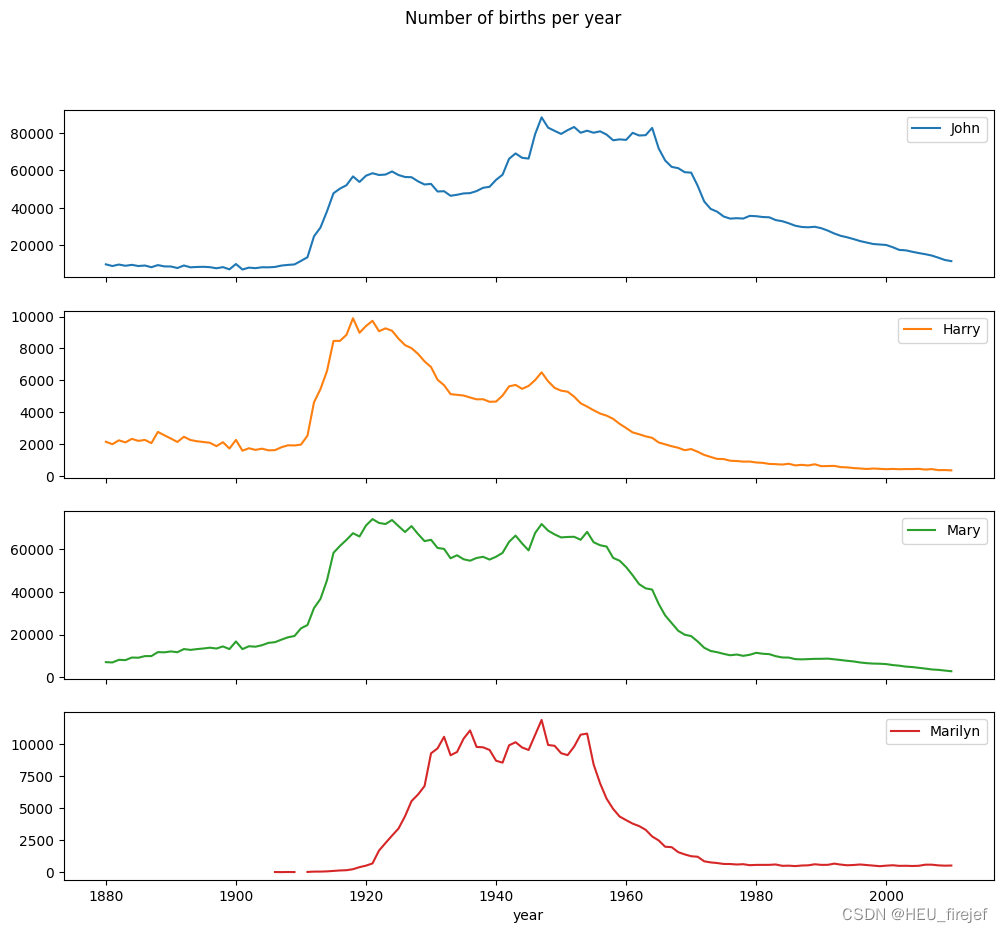
(14)
plt.figure()
输出结果:
分析功能:
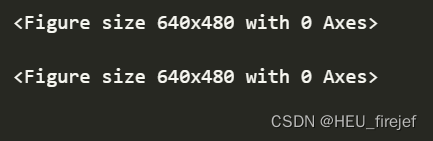
- 首先,table = top1000.pivot_table(“prop”, index=“year”, columns=“sex”, aggfunc=sum) 使用 pivot_table 函数计算每个年份和性别组合中的比例总和。该函数以 “prop” 列作为值,“year” 列作为行索引,“sex” 列作为列索引。聚合函数 sum 被应用于 “prop” 列,以计算每个年份和性别组合中的比例总和。这样,table 是一个新的 DataFrame,其中的行表示年份,列表示性别,单元格的值是每个年份和性别组合中的比例总和。
- 接下来,table.plot(title=“Sum of table1000.prop by year and sex”, yticks=np.linspace(0, 1.2, 13)) 用于将 table DataFrame 的数据绘制成一个图表。图表的标题为 “Sum of table1000.prop by year and sex”。横轴表示年份,纵轴表示比例总和。yticks=np.linspace(0, 1.2, 13) 参数用于设置纵轴上的刻度值,np.linspace(0, 1.2, 13) 生成了一个从 0 到 1.2 之间的 13 个均匀间隔的刻度值。这样可以确保纵轴的刻度范围适合数据的取值范围。图表可以用来观察每个年份和性别组合中的比例总和随时间的变化情况。
(15)
table = top1000.pivot_table("prop", index="year",
columns="sex", aggfunc=sum)
table.plot(title="Sum of table1000.prop by year and sex",
yticks=np.linspace(0, 1.2, 13))
输出结果:
分析功能:
- 首先,df = boys[boys[“year”] == 2010] 从 boys DataFrame 中筛选出 “year” 列等于 2010 的记录。这将创建一个新的 DataFrame df,其中包含了性别为男性且年份为2010的记录。
(16)
df = boys[boys["year"] == 2010]
df
输出结果:
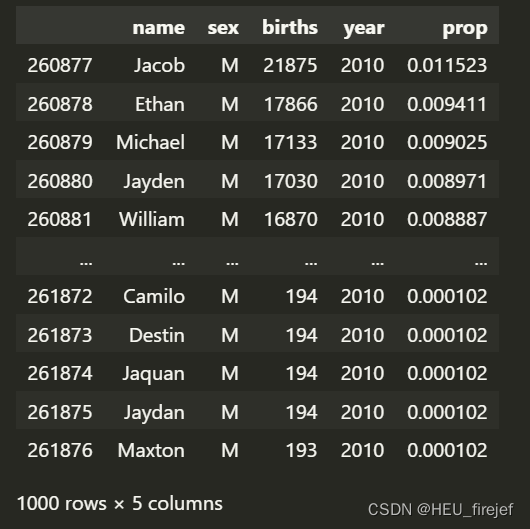
分析功能:
- 首先,prop_cumsum = df[“prop”].sort_values(ascending=False).cumsum() 用于对 df DataFrame 的 “prop” 列进行降序排序,并计算其累积和。这将创建一个新的 Series prop_cumsum,其中的每个元素是根据 “prop” 列降序排序后的累积和。
- 然后,prop_cumsum[:10] 用于显示 prop_cumsum Series 的前10个元素。这将输出累积和排序后的前10个值,用于查看对应的比例累积。
- 最后,prop_cumsum.searchsorted(0.5) 使用 searchsorted 函数来查找累积和达到或超过0.5的第一个位置。这将返回一个整数,表示第一个累积和超过或等于0.5的索引位置。
(17)
prop_cumsum = df["prop"].sort_values(ascending=False).cumsum()
prop_cumsum[:10]
prop_cumsum.searchsorted(0.5)
分析功能:
- 首先,df = boys[boys.year == 1900] 从 boys DataFrame 中筛选出 “year” 列等于 1900 的记录。这将创建一个新的 DataFrame df,其中包含了性别为男性且年份为 1900 的记录。
- 然后,in1900 = df.sort_values(“prop”, ascending=False).prop.cumsum() 对 df DataFrame 按 “prop” 列进行降序排序,并计算该列的累积和。这将创建一个新的 Series in1900,其中每个元素是根据 “prop” 列降序排序后的累积和。
- 接下来,in1900.searchsorted(0.5) + 1 使用 searchsorted 函数查找累积和达到或超过 0.5 的第一个位置,并将结果加上 1。这将返回一个整数,表示在 1900 年男性名字中需要多少个名字才能使累积比例超过或等于 0.5。
(18)
df = boys[boys.year == 1900]
in1900 = df.sort_values("prop", ascending=False).prop.cumsum()
in1900.searchsorted(0.5) + 1
分析功能:
- 首先,定义了一个名为 get_quantile_count 的函数。该函数接受一个分组(group)作为输入,并可选地指定一个分位数(默认为 0.5)。在函数内部,对分组按照 “prop” 列的值进行降序排序。然后,计算 “prop” 列的累积和,并使用 searchsorted 函数找到累积和达到或超过指定分位数的第一个位置。最后,返回这个位置加 1,表示达到该分位数所需的数量。
- 接下来,diversity = top1000.groupby([“year”, “sex”]).apply(get_quantile_count) 对 top1000 DataFrame 进行分组操作。按照 “year” 和 “sex” 两列进行分组,并应用 get_quantile_count 函数。这将在每个分组上执行 get_quantile_count 函数,计算每个年份和性别组合中达到指定分位数的名字数量。
- 然后,diversity = diversity.unstack() 使用 unstack 函数将多级索引的 Series 转换为 DataFrame。这将将 “year” 列和 “sex” 列的层级索引转换为列,得到一个新的 DataFrame diversity。其中的行表示年份,列表示性别,单元格的值表示每个年份和性别组合中达到指定分位数的名字数量。
(19)
def get_quantile_count(group, q=0.5):
group = group.sort_values("prop", ascending=False)
return group.prop.cumsum().searchsorted(q) + 1
diversity = top1000.groupby(["year", "sex"]).apply(get_quantile_count)
diversity = diversity.unstack()
(20)
fig = plt.figure()
输出结果:

分析功能:
- 首先,diversity.head() 用于显示 diversity DataFrame 的前几行数据。这将输出 DataFrame 的前几行,用于查看每个年份和性别组合中达到指定分位数的名字数量。
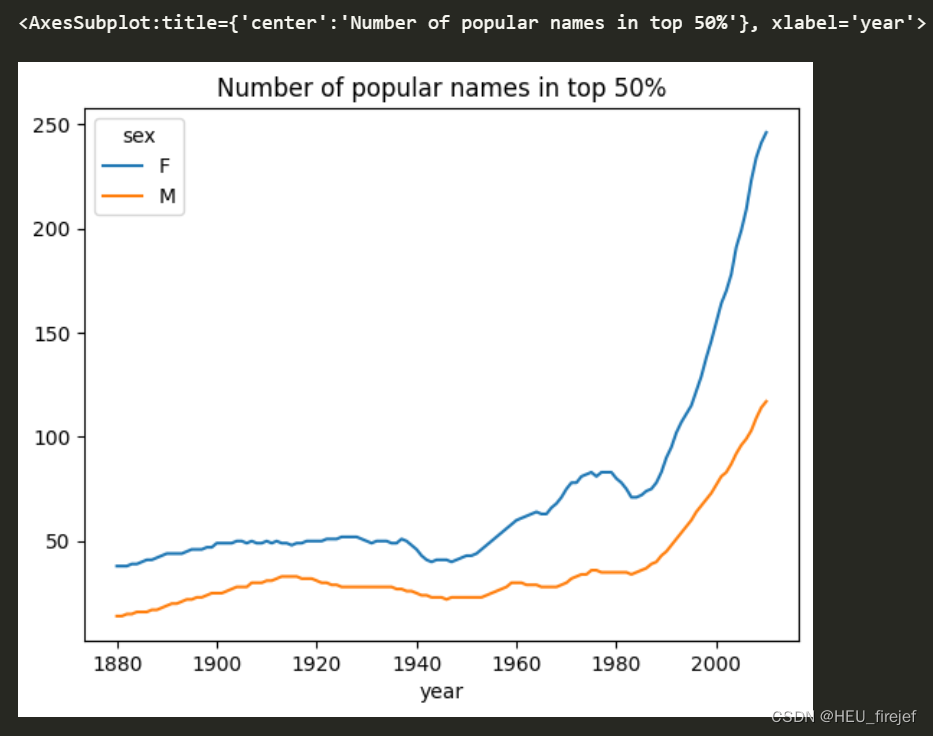
- 接下来,diversity.plot(title=“Number of popular names in top 50%”) 用于将 diversity DataFrame 的数据绘制成一个图表。图表的标题为 “Number of popular names in top 50%”。横轴表示年份,纵轴表示达到指定分位数的名字数量。图表可以用来观察每个年份和性别组合中达到指定分位数的名字数量的变化情况。
(21)
diversity.head()
diversity.plot(title="Number of popular names in top 50%")
输出结果:
分析功能:
- 首先,定义了一个名为 get_last_letter 的函数。该函数接受一个字符串作为输入,并返回该字符串的最后一个字母。
- 然后,last_letters = names[“name”].map(get_last_letter) 使用 map 函数将 get_last_letter 函数应用于 names[“name”] 列中的每个元素,以获取每个名字的最后一个字母。这将创建一个新的 Series last_letters,其中的每个元素是对应名字的最后一个字母。
- 接下来,last_letters.name = “last_letter” 为 last_letters Series 设置名称为 “last_letter”,以便更好地标识该列。
- 最后,table = names.pivot_table(“births”, index=last_letters, columns=[“sex”, “year”], aggfunc=sum) 使用 pivot_table 函数创建一个数据透视表。该函数以 “births” 列作为值,last_letters 列作为行索引,[“sex”, “year”] 列作为列索引。聚合函数 sum 被应用于 “births” 列,以计算每个最后一个字母、性别和年份组合的出生总数。这样,table 是一个新的 DataFrame,其中的行表示最后一个字母,列表示性别和年份组合,单元格的值是每个组合的出生总数。
(22)
def get_last_letter(x):
return x[-1]
last_letters = names["name"].map(get_last_letter)
last_letters.name = "last_letter"
table = names.pivot_table("births", index=last_letters,
columns=["sex", "year"], aggfunc=sum)
分析功能:
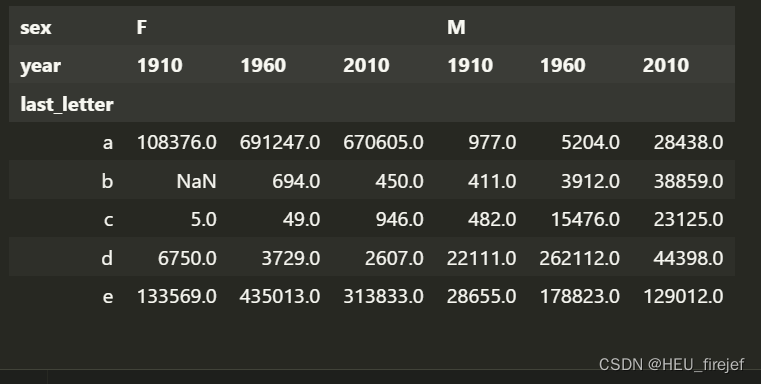
- 首先,subtable = table.reindex(columns=[1910, 1960, 2010], level=“year”) 使用 reindex 函数重新索引 table DataFrame 的列。在这里,指定了要保留的列为 [1910, 1960, 2010],且指定了要重新索引的级别为 “year”。这将创建一个新的 DataFrame subtable,其中的列仅包含指定的年份 [1910, 1960, 2010],而其他年份的列将被删除。
- 然后,subtable.head() 用于显示 subtable DataFrame 的前几行数据。这将输出 DataFrame 的前几行,用于查看指定年份的数据。
(23)
subtable = table.reindex(columns=[1910, 1960, 2010], level="year")
subtable.head()
输出结果:
分析功能:
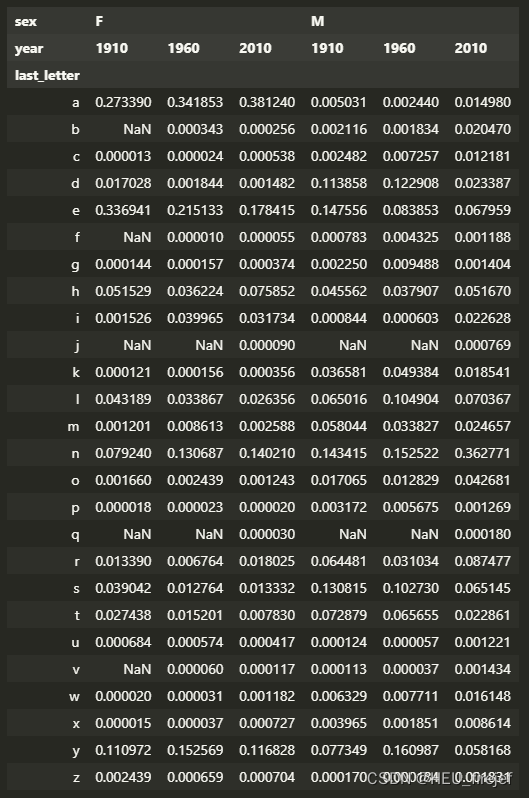
- 首先,subtable.sum() 对 subtable DataFrame 进行求和操作。这将计算每个最后一个字母、性别和指定年份组合的出生总数。结果是一个 Series,其中每个元素是对应组合的出生总数。
- 然后,letter_prop = subtable / subtable.sum() 对 subtable DataFrame 进行除法操作,除以先前计算得到的出生总数。这将计算每个组合的出生数量在对应年份中的比例。结果是一个新的 DataFrame letter_prop,其中的每个单元格的值表示对应组合在指定年份中的比例。
(24)
subtable.sum()
letter_prop = subtable / subtable.sum()
letter_prop
输出结果:
分析功能:
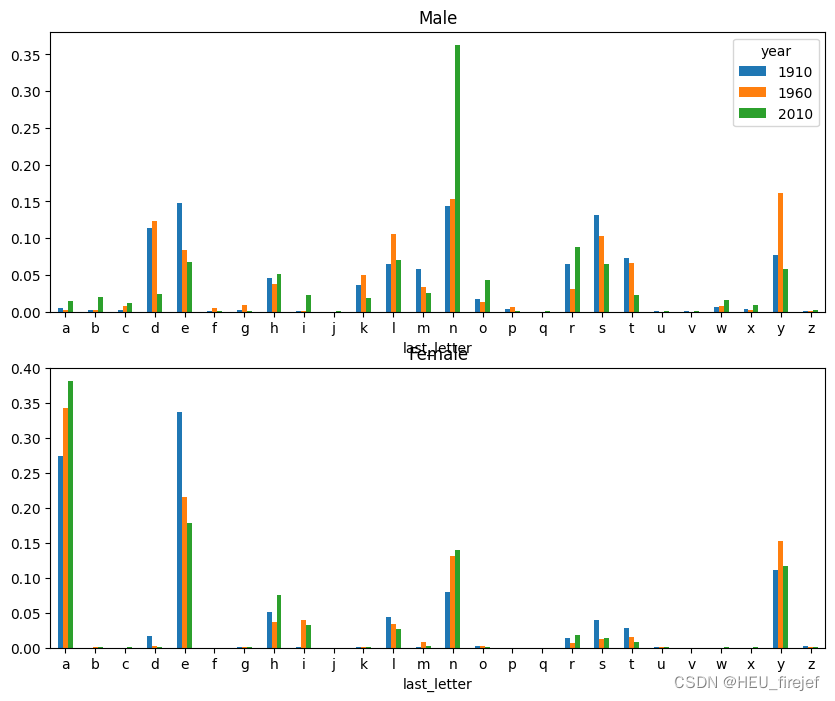
- 首先,fig, axes = plt.subplots(2, 1, figsize=(10, 8)) 创建了一个包含两个子图的图表对象。2, 1 参数表示图表为两行一列的布局,即两个子图垂直排列。figsize=(10, 8) 参数指定了图表的尺寸为宽度 10 英寸、高度 8 英寸。
- 然后,letter_prop[“M”].plot(kind=“bar”, rot=0, ax=axes[0], title=“Male”) 在第一个子图中绘制了名为 “M” 的组合的比例数据。kind=“bar” 参数表示绘制柱状图,rot=0 参数表示 x 轴刻度标签不旋转,ax=axes[0] 参数指定了绘制在第一个子图中,title=“Male” 参数设置了子图的标题为 “Male”。
- 接下来,letter_prop[“F”].plot(kind=“bar”, rot=0, ax=axes[1], title=“Female”, legend=False) 在第二个子图中绘制了名为 “F” 的组合的比例数据。参数设置与前一个子图相似,只是标题为 “Female”,并且 legend=False 参数表示不显示图例。
(25)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
letter_prop["M"].plot(kind="bar", rot=0, ax=axes[0], title="Male")
letter_prop["F"].plot(kind="bar", rot=0, ax=axes[1], title="Female",
legend=False)
输出结果:

(26)
plt.subplots_adjust(hspace=0.25)
输出结果:

(27)
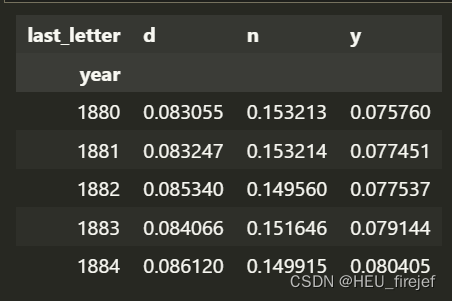
letter_prop = table / table.sum()
dny_ts = letter_prop.loc[["d", "n", "y"], "M"].T
dny_ts.head()
输出结果:
(28)
fig = plt.figure()
输出结果:
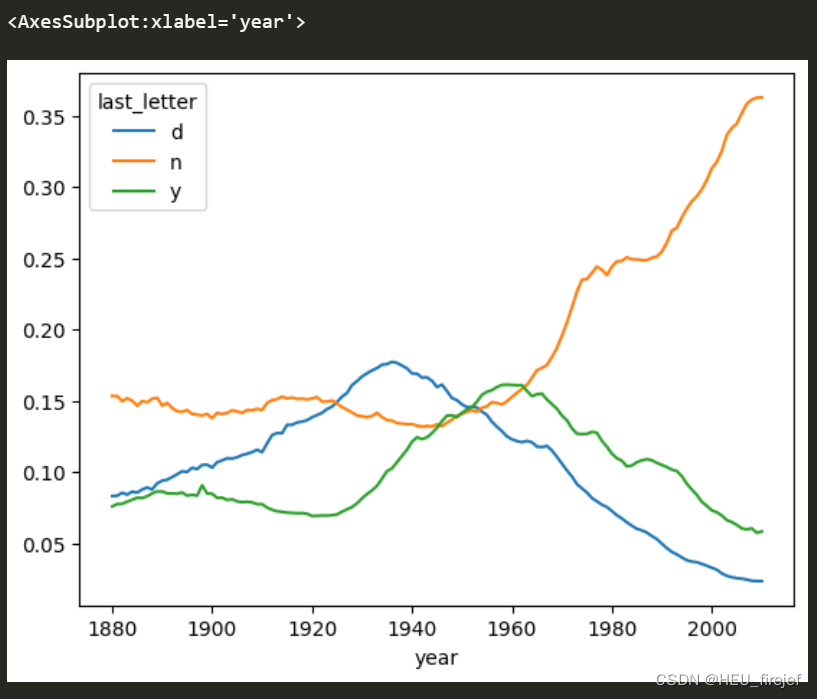
(29)
dny_ts.plot()
输出结果:
分析功能:
- 首先,all_names = pd.Series(top1000[“name”].unique()) 创建了一个包含所有独特(唯一)名字的 Series all_names。它从 top1000 DataFrame 的 “name” 列中提取所有唯一的名字,并将它们作为元素创建为一个 Series。
- 接下来,lesley_like = all_names[all_names.str.contains(“Lesl”)] 通过使用 str.contains 方法,筛选出在 all_names Series 中包含 “Lesl” 的名字。这将创建一个新的 Series lesley_like,其中包含与 “Lesl” 相关的名字。
(30)
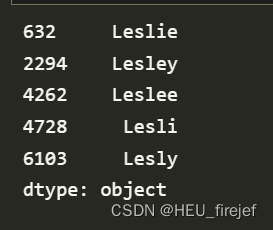
all_names = pd.Series(top1000["name"].unique())
lesley_like = all_names[all_names.str.contains("Lesl")]
lesley_like
输出结果:
分析功能:
- 首先,filtered = top1000[top1000[“name”].isin(lesley_like)] 使用 isin 方法筛选出 top1000 DataFrame 中 “name” 列包含在 lesley_like Series 中的记录。这将创建一个新的 DataFrame filtered,其中包含与 lesley_like 相关的记录。
- 然后,filtered.groupby(“name”)[“births”].sum() 对 filtered DataFrame 进行分组操作,根据 “name” 列对数据进行分组,并计算每个名字对应的出生总数。这将返回一个新的 Series,其中每个元素是每个名字对应的出生总数。
(31)
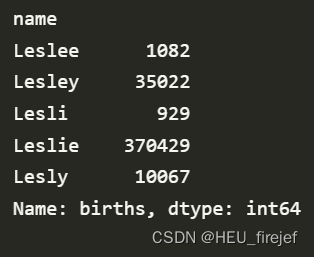
filtered = top1000[top1000["name"].isin(lesley_like)]
filtered.groupby("name")["births"].sum()
输出结果:
分析功能:
- 首先,table = filtered.pivot_table(“births”, index=“year”, columns=“sex”, aggfunc=“sum”) 使用 pivot_table 函数创建一个数据透视表。该函数以 “births” 列作为值,“year” 列作为行索引,“sex” 列作为列索引。聚合函数 “sum” 被应用于 “births” 列,以计算每个年份和性别组合的出生总数。这样,table 是一个新的 DataFrame,其中的行表示年份,列表示性别,单元格的值是每个年份和性别组合的出生总数。
- 然后,table = table.div(table.sum(axis=“columns”), axis=“index”) 对 table DataFrame 进行除法操作,用每个年份的出生总数对应行的总和来标准化数据。table.sum(axis=“columns”) 计算每个年份的出生总数,table.div(…, axis=“index”) 通过行索引对每个单元格的值进行除法操作,将每个值除以对应行的出生总数。
- 最后,table.tail() 用于显示 table DataFrame 的最后几行数据。这将输出 DataFrame 的最后几行,用于查看标准化后的数据。
(32)
table = filtered.pivot_table("births", index="year",
columns="sex", aggfunc="sum")
table = table.div(table.sum(axis="columns"), axis="index")
table.tail()
输出结果:
(33)
fig = plt.figure()
输出结果:

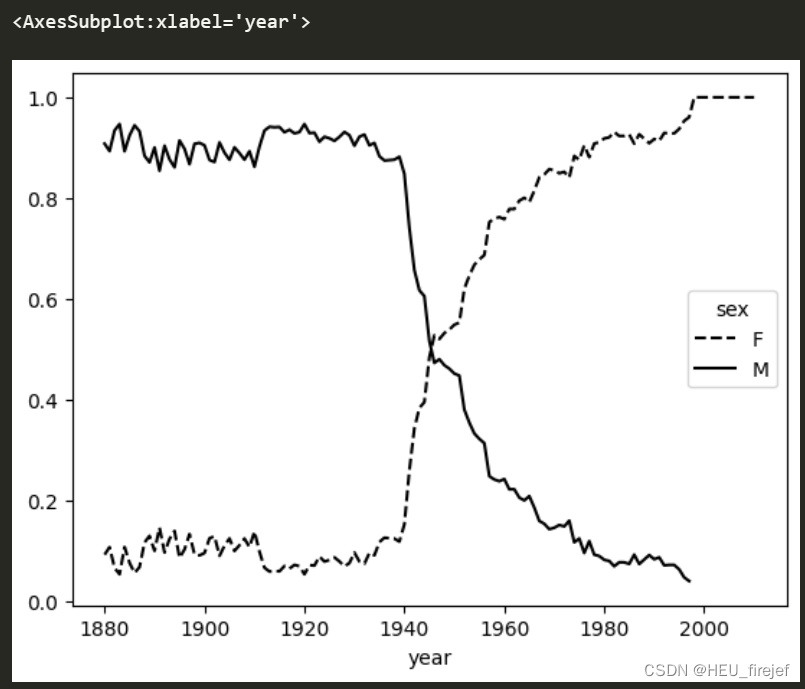
(34)
table.plot(style={"M": "k-", "F": "k--"})
输出结果:
三、美国农业部视频数据库
美国农业部提供了食物营养信息数据库。每种事务都有一些识别属性以及两份营养元素和营养比例的列表。这种形式的数据不适合分析,所以需要做一些工作将数据转换成更好的形式。
分析功能:
- 首先,json.load(open(“datasets/usda_food/database.json”)) 打开名为 “database.json” 的文件,并使用 json.load 函数将文件内容加载为 Python 中的数据结构。这将返回一个包含文件内容的数据对象,通常是字典、列表或其他组合的形式。
- 然后,len(db) 用于计算加载后的数据对象 db 中的元素数量。这将返回 db 中的元素数量,表示数据对象中的项数。
- 总结起来,这段代码的作用是加载一个 JSON 文件并将其转换为 Python 中的数据结构。然后,通过计算加载后的数据对象中的元素数量,获取数据对象中的项数。
(1)
import json
db = json.load(open("datasets/usda_food/database.json"))
len(db)
输出结果:
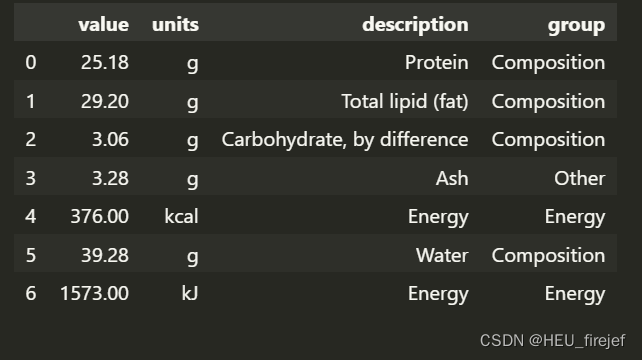
分析功能:
- 首先,db[0].keys() 获取了 db 中第一个元素(字典)的键。这将返回该元素中所有键的列表,用于查看字典中的键。
- 接下来,db[0][“nutrients”][0] 获取了 db 中第一个元素字典中键为 “nutrients” 的值的第一个元素。这将返回 “nutrients” 键对应的列表中的第一个元素,用于查看该元素的内容。
- 然后,nutrients = pd.DataFrame(db[0][“nutrients”]) 创建了一个 DataFrame nutrients,该 DataFrame 使用 db 中第一个元素字典中键为 “nutrients” 的值作为数据源。这样,nutrients DataFrame 将包含 “nutrients” 列表中的所有元素,每个元素将成为 DataFrame 中的一行。
- 最后,nutrients.head(7) 用于显示 nutrients DataFrame 的前 7 行数据。这将输出 DataFrame 的前 7 行,用于查看数据的内容。
(2)
db[0].keys()
db[0]["nutrients"][0]
nutrients = pd.DataFrame(db[0]["nutrients"])
nutrients.head(7)
输出结果:
分析功能:
- 首先,info_keys = [“description”, “group”, “id”, “manufacturer”] 定义了一个包含特定键的列表 info_keys。这些键用于从 db 中的每个元素(字典)中提取相应的值。
- 然后,info = pd.DataFrame(db, columns=info_keys) 使用 pd.DataFrame 函数创建一个 DataFrame info,该 DataFrame 使用 db 数据对象作为数据源,并使用 info_keys 列表中的键作为列名。这样,info DataFrame 将包含来自 db 中每个元素字典中指定键的值,每个元素将成为 DataFrame 中的一行。
- 接下来,info.head() 用于显示 info DataFrame 的前几行数据。这将输出 DataFrame 的前几行,用于查看数据的内容。
- 最后,info.info() 用于显示关于 info DataFrame 的相关信息,包括每列的数据类型和非空值的数量等。
(3)
info_keys = ["description", "group", "id", "manufacturer"]
info = pd.DataFrame(db, columns=info_keys)
info.head()
info.info()
输出结果:
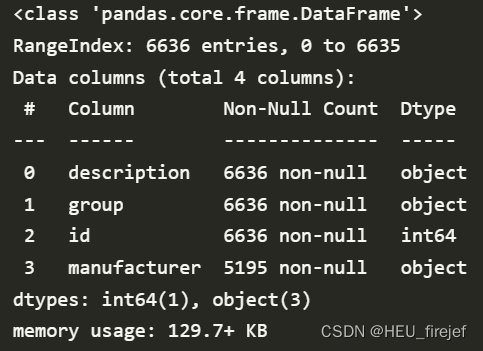
分析功能:
- info[“group”] 选择了 info DataFrame 中的 “group” 列,然后 pd.value_counts() 函数对该列的值进行频数统计。[:10] 表示取统计结果的前 10 项。
- 最后,pd.value_counts(info[“group”])[:10] 将返回一个 Series,其中包含了 “group” 列中出现频率最高的前 10 个值及其对应的频数。
(4)
pd.value_counts(info["group"])[:10]
输出结果:

分析功能:
- 首先,创建了一个空列表 nutrients,用于存储每个元素中的 “nutrients” 数据。
- 然后,使用 for 循环遍历 db 中的每个元素。对于每个元素,将其字典中的 “nutrients” 键的值转换为 DataFrame fnuts。同时,在 fnuts DataFrame 中添加一个名为 “id” 的列,并将其设置为当前元素的 “id” 值。
- 接下来,将 fnuts DataFrame 添加到 nutrients 列表中。
- 最后,使用 pd.concat() 函数将 nutrients 列表中的所有 DataFrame 进行连接,创建一个包含所有 “nutrients” 数据的 DataFrame。ignore_index=True 参数表示忽略原始索引,并重新生成新的连续索引。
(5)
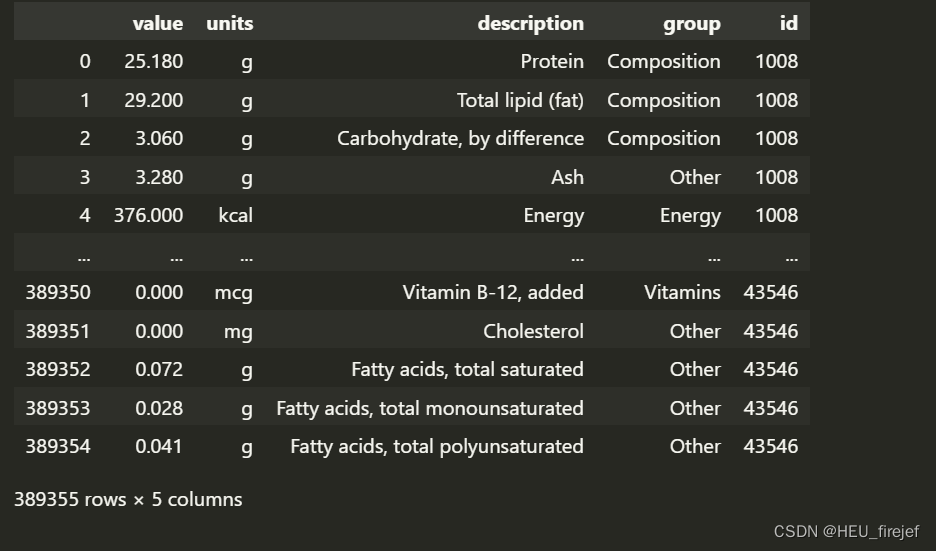
nutrients = []
for rec in db:
fnuts = pd.DataFrame(rec["nutrients"])
fnuts["id"] = rec["id"]
nutrients.append(fnuts)
nutrients = pd.concat(nutrients, ignore_index=True)
nutrients
输出结果:
分析功能:
- 首先,nutrients.duplicated().sum() 使用 duplicated 函数检测 nutrients DataFrame 中的重复行,并通过 sum 函数计算重复行的数量。这将返回重复行的数量。
- 然后,nutrients = nutrients.drop_duplicates() 使用 drop_duplicates 函数从 nutrients DataFrame 中删除重复行。这将更新 nutrients DataFrame,移除其中的重复行。
- 接下来,col_mapping = {“description” : “food”, “group” : “fgroup”} 定义了一个字典 col_mapping,用于指定需要重命名的列名映射关系。
- 然后,info = info.rename(columns=col_mapping, copy=False) 使用 rename 函数根据 col_mapping 字典中的映射关系,重命名 info DataFrame 中的列名。这将更新 info DataFrame,将 “description” 列重命名为 “food”,将 “group” 列重命名为 “fgroup”。
- 接着,info.info() 显示更新后的 info DataFrame 的相关信息,包括每列的数据类型和非空值的数量等。
- 最后,col_mapping = {“description” : “nutrient”, “group” : “nutgroup”} 定义了一个字典 col_mapping,用于指定需要重命名的列名映射关系。
(6)
nutrients.duplicated().sum() # number of duplicates
nutrients = nutrients.drop_duplicates()
(7)
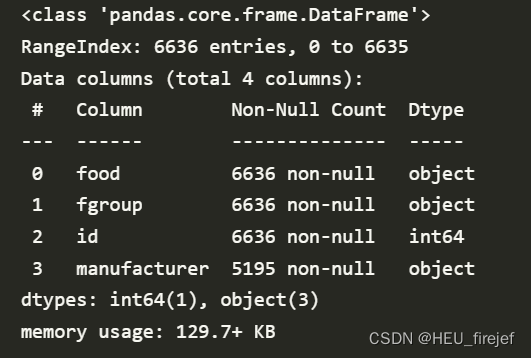
col_mapping = {"description" : "food",
"group" : "fgroup"}
info = info.rename(columns=col_mapping, copy=False)
info.info()
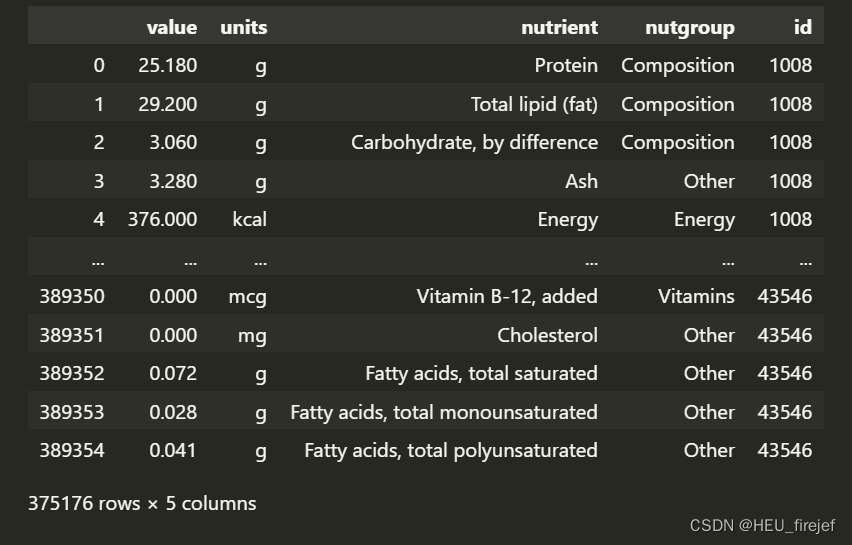
col_mapping = {"description" : "nutrient",
"group" : "nutgroup"}
nutrients = nutrients.rename(columns=col_mapping, copy=False)
nutrients
输出结果:
分析功能:
- 首先,ndata = pd.merge(nutrients, info, on=“id”) 使用 merge 函数根据 “id” 列将 nutrients DataFrame 和 info DataFrame 进行合并。这将创建一个新的 DataFrame ndata,其中包含了两个 DataFrame 中具有相同 “id” 值的行的合并结果。
- 接下来,ndata.info() 显示关于 ndata DataFrame 的相关信息,包括每列的数据类型和非空值的数量等。
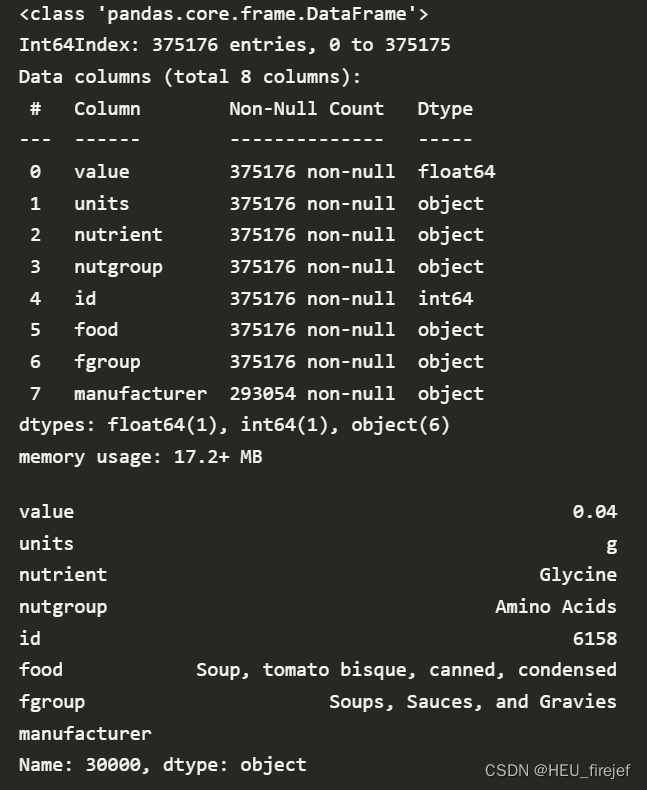
- 最后,ndata.iloc[30000] 通过索引选取 ndata DataFrame 中索引为 30000 的行,并返回该行的数据。这可以用于查看特定行的数据内容。
(8)
ndata = pd.merge(nutrients, info, on="id")
ndata.info()
ndata.iloc[30000]
输出结果:
(9)
fig = plt.figure()
输出结果:

分析功能:
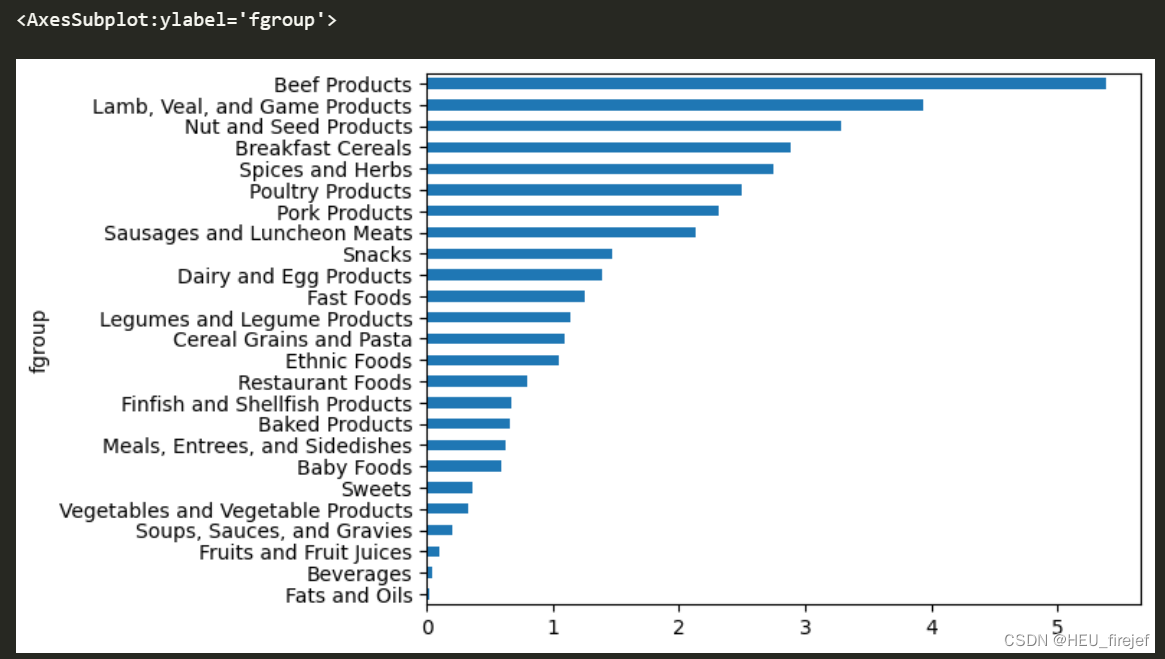
- 首先,result = ndata.groupby([“nutrient”, “fgroup”])[“value”].quantile(0.5) 对 ndata DataFrame 进行分组操作。根据 “nutrient” 和 “fgroup” 列进行分组,并计算 “value” 列的分位数,指定为 0.5。这将返回一个包含每个组合的分位数值的 Series result。
- 然后,result[“Zinc, Zn”] 从 result Series 中选择键为 “Zinc, Zn” 的项,这是指定营养素的名称。这将返回一个包含相应营养素分位数的 Series。
- 接下来,result[“Zinc, Zn”].sort_values() 对所选的 Series 进行排序,按分位数值进行升序排序。
- 最后,.plot(kind=“barh”) 以水平条形图的形式绘制排序后的结果。这将生成一个条形图,其中营养素的名称在 y 轴上,对应的分位数值在 x 轴上。
(10)
result = ndata.groupby(["nutrient", "fgroup"])["value"].quantile(0.5)
result["Zinc, Zn"].sort_values().plot(kind="barh")
输出结果:
分析功能:
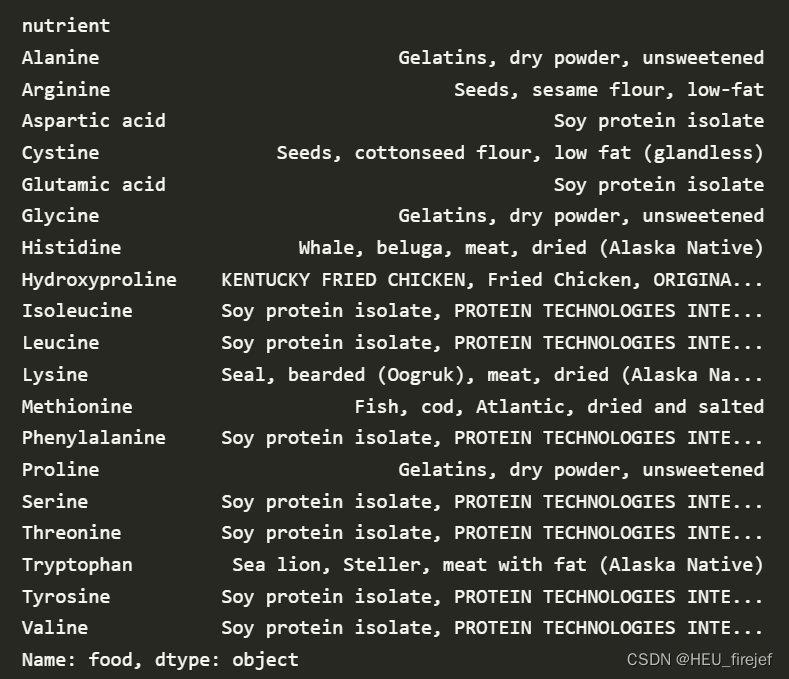
- 首先,by_nutrient = ndata.groupby([“nutgroup”, “nutrient”]) 使用 groupby 函数对 ndata DataFrame 进行分组操作。根据 “nutgroup” 和 “nutrient” 列进行分组,创建一个按营养素分组的对象 by_nutrient。
- 然后,def get_maximum(x): return x.loc[x.value.idxmax()] 定义了一个名为 get_maximum 的函数,它接受一个 DataFrame x 作为输入。该函数通过 value.idxmax() 找到 DataFrame x 中 “value” 列具有最大值的行的索引,并通过 loc 进一步选取对应的行。
- 接下来,max_foods = by_nutrient.apply(get_maximum)[[“value”, “food”]] 使用 apply 函数将 get_maximum 函数应用于每个分组,得到具有最大值的行,并选择其中的 “value” 和 “food” 列。这将创建一个新的 DataFrame max_foods,其中包含了每个营养素分组中具有最大值的行的 “value” 和 “food” 列。
- 最后,max_foods[“food”] = max_foods[“food”].str[:50] 将 max_foods DataFrame 中的 “food” 列的字符串内容截取为最多 50 个字符长度。这可以用来限制 “food” 列的字符串长度,使其更紧凑。
(11)
by_nutrient = ndata.groupby(["nutgroup", "nutrient"])
def get_maximum(x):
return x.loc[x.value.idxmax()]
max_foods = by_nutrient.apply(get_maximum)[["value", "food"]]
# make the food a little smaller
max_foods["food"] = max_foods["food"].str[:50]
分析功能:
- max_foods.loc[“Amino Acids”] 选择了索引标签为 “Amino Acids” 的行,其中包含了该营养素分组中具有最大值的行的 “value” 和 “food” 列。
- 最后,[“food”] 选择了上述选择行中的 “food” 列,以获取该营养素分组中具有最大值的食物的信息。
(12)
max_foods.loc["Amino Acids"]["food"]
输出结果:
四、2012年联邦选举委员会数据库
美国联邦选举委员会公布了有关政治运动贡献的数据。这些数据包括捐赠者姓名、职业和雇主、地址和缴费金额。你可以尝试做一下的分析:
按职业和雇主的捐赠统计
按捐赠金额统计
按州进行统计
(1)
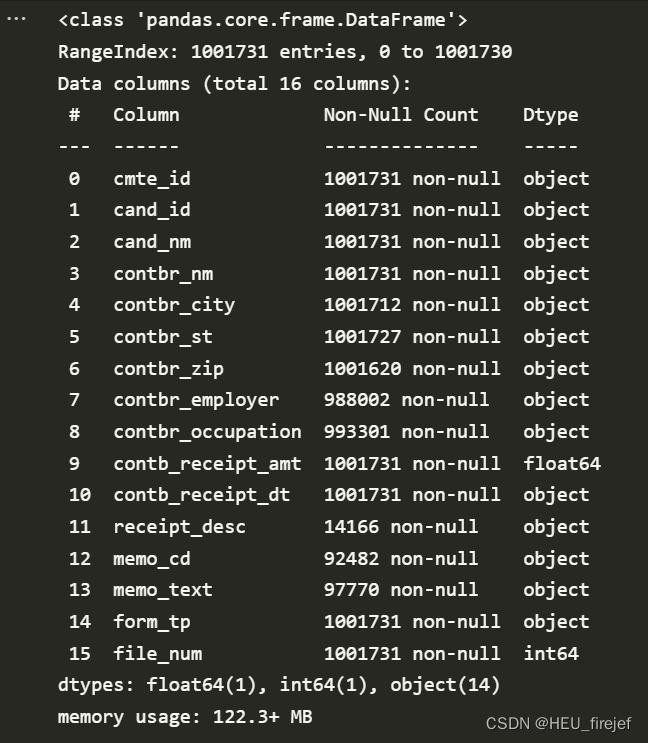
fec = pd.read_csv("datasets/fec/P00000001-ALL.csv", low_memory=False)
fec.info()
输出结果:
分析功能:
- 这段代码使用 pandas 库中的 read_csv 函数读取了一个名为 “datasets/fec/P00000001-ALL.csv” 的 CSV 文件,并将其存储在名为 fec 的变量中。low_memory=False 参数表示在读取过程中不使用低内存模式。
- 接下来,使用 info() 函数来显示有关 fec 数据帧的信息,包括索引数据类型和非空值的数量。
(2)
fec.iloc[123456]
输出结果:
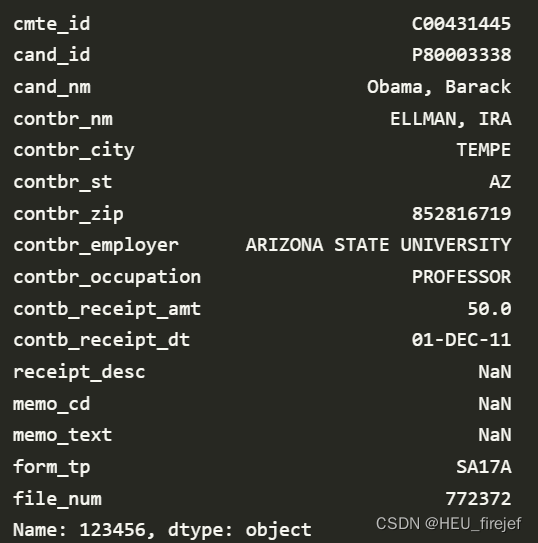
分析功能:
- 这行代码使用 iloc 属性来选择 fec 数据帧中索引为 123456 的行。iloc 是基于位置的索引,它允许你通过整数位置来选择数据帧中的行或列。
(3)
unique_cands = fec["cand_nm"].unique()
unique_cands
unique_cands[2]
输出结果:

分析功能:
- 这段代码首先使用 unique 函数获取 fec 数据帧中 “cand_nm” 列的唯一值,并将其存储在名为 unique_cands 的变量中。
- 接下来,它打印出 unique_cands 变量的值,显示所有唯一的候选人名称。
- 最后,它打印出 unique_cands 中索引为 2 的元素,即第三个唯一的候选人名称。
(4)
parties = {"Bachmann, Michelle": "Republican",
"Cain, Herman": "Republican",
"Gingrich, Newt": "Republican",
"Huntsman, Jon": "Republican",
"Johnson, Gary Earl": "Republican",
"McCotter, Thaddeus G": "Republican",
"Obama, Barack": "Democrat",
"Paul, Ron": "Republican",
"Pawlenty, Timothy": "Republican",
"Perry, Rick": "Republican",
"Roemer, Charles E. 'Buddy' III": "Republican",
"Romney, Mitt": "Republican",
"Santorum, Rick": "Republican"}
分析功能:
- 这段代码定义了一个名为 parties 的字典,其中包含了一些候选人的姓名和他们所属的政党。字典中的键是候选人的姓名,值是他们所属的政党。
(5)
fec["cand_nm"][123456:123461]
fec["cand_nm"][123456:123461].map(parties)
# Add it as a column
fec["party"] = fec["cand_nm"].map(parties)
fec["party"].value_counts()
输出结果:
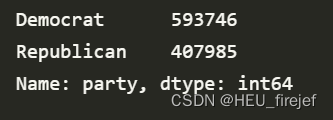
分析功能:
- 这段代码首先使用切片选择 fec 数据帧中 “cand_nm” 列的第 123456 到第 123460 行(不包括第 123461 行),并打印出这些行的值。
- 接下来,它使用 map 函数将这些行中的候选人姓名映射到他们所属的政党,并打印出映射后的结果。
- 然后,它使用 map 函数将 fec 数据帧中 “cand_nm” 列中的所有候选人姓名映射到他们所属的政党,并将结果存储在新的 “party” 列中。
- 最后,它使用 value_counts 函数计算 fec 数据帧中 “party” 列的值的频数分布,并打印出结果。
(6)
(fec["contb_receipt_amt"] > 0).value_counts()
输出结果:
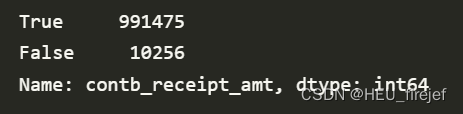
分析功能:
- 这行代码首先使用布尔索引选择 fec 数据帧中 “contb_receipt_amt” 列中大于 0 的值,然后使用 value_counts 函数计算这些值的频数分布。
(7)
fec = fec[fec["contb_receipt_amt"] > 0]
分析功能:
- 这行代码使用布尔索引选择 fec 数据帧中 “contb_receipt_amt” 列中大于 0 的行,并将这些行存储在 fec 变量中,从而更新了 fec 数据帧。
(8)
fec_mrbo = fec[fec["cand_nm"].isin(["Obama, Barack", "Romney, Mitt"])]
分析功能:
- 这行代码首先使用 isin 函数选择 fec 数据帧中 “cand_nm” 列中值为 “Obama, Barack” 或 “Romney, Mitt” 的行,然后将这些行存储在名为 fec_mrbo 的新变量中。
(9)
fec["contbr_occupation"].value_counts()[:10]
输出结果:
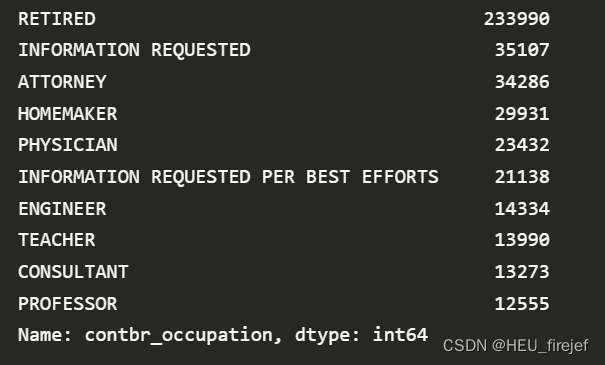
分析功能:
- 这行代码首先使用 value_counts 函数计算 fec 数据帧中 “contbr_occupation” 列的值的频数分布,然后使用切片选择前 10 个值并打印出来。
(10)
occ_mapping = {
"INFORMATION REQUESTED PER BEST EFFORTS" : "NOT PROVIDED",
"INFORMATION REQUESTED" : "NOT PROVIDED",
"INFORMATION REQUESTED (BEST EFFORTS)" : "NOT PROVIDED",
"C.E.O.": "CEO"
}
def get_occ(x):
# If no mapping provided, return x
return occ_mapping.get(x, x)
fec["contbr_occupation"] = fec["contbr_occupation"].map(get_occ)
分析功能:
- 这段代码首先定义了一个名为 occ_mapping 的字典,用于将一些职业名称映射到新的值。
- 接下来,它定义了一个名为 get_occ 的函数,该函数接受一个参数 x,并使用 occ_mapping 字典中的映射关系来返回新的值。如果 x 在字典中没有对应的键,则返回 x 本身。
- 然后,它使用 map 函数将 fec 数据帧中 “contbr_occupation” 列中的值映射到新的值,并将结果存储回 “contbr_occupation” 列中。
(11)
emp_mapping = {
"INFORMATION REQUESTED PER BEST EFFORTS" : "NOT PROVIDED",
"INFORMATION REQUESTED" : "NOT PROVIDED",
"SELF" : "SELF-EMPLOYED",
"SELF EMPLOYED" : "SELF-EMPLOYED",
}
def get_emp(x):
# If no mapping provided, return x
return emp_mapping.get(x, x)
fec["contbr_employer"] = fec["contbr_employer"].map(get_emp)
分析功能:
- 这段代码首先定义了一个名为 emp_mapping 的字典,用于将一些雇主名称映射到新的值。
- 接下来,它定义了一个名为 get_emp 的函数,该函数接受一个参数 x,并使用 emp_mapping 字典中的映射关系来返回新的值。如果 x 在字典中没有对应的键,则返回 x 本身。
- 然后,它使用 map 函数将 fec 数据帧中 “contbr_employer” 列中的值映射到新的值,并将结果存储回 “contbr_employer” 列中。
(12)
by_occupation = fec.pivot_table("contb_receipt_amt",
index="contbr_occupation",
columns="party", aggfunc="sum")
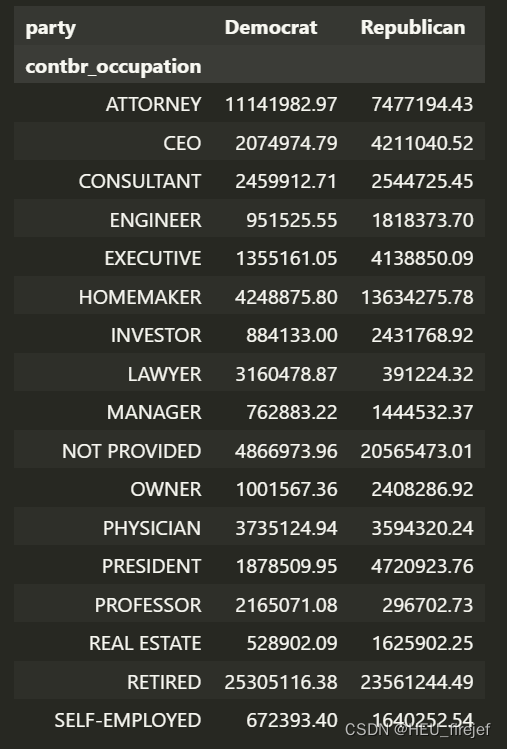
over_2mm = by_occupation[by_occupation.sum(axis="columns") > 2000000]
over_2mm
输出结果:
分析功能:
- 这段代码首先使用 pivot_table 函数创建一个透视表,其中行标签为 fec 数据帧中 “contbr_occupation” 列的值,列标签为 “party” 列的值,值为 “contb_receipt_amt” 列的总和。透视表中的每个单元格表示特定职业和特定政党的捐款总额。
- 接下来,它使用布尔索引选择透视表中行总和大于 2000000 的行,并将这些行存储在名为 over_2mm 的变量中。
- 最后,它打印出 over_2mm 变量的值,显示了捐款总额超过 2000000 的职业。
(13)
plt.figure()
输出结果:
分析功能:
- 这行代码使用 matplotlib 库中的 figure 函数创建了一个新的图形窗口
(14)
over_2mm.plot(kind="barh")
输出结果:
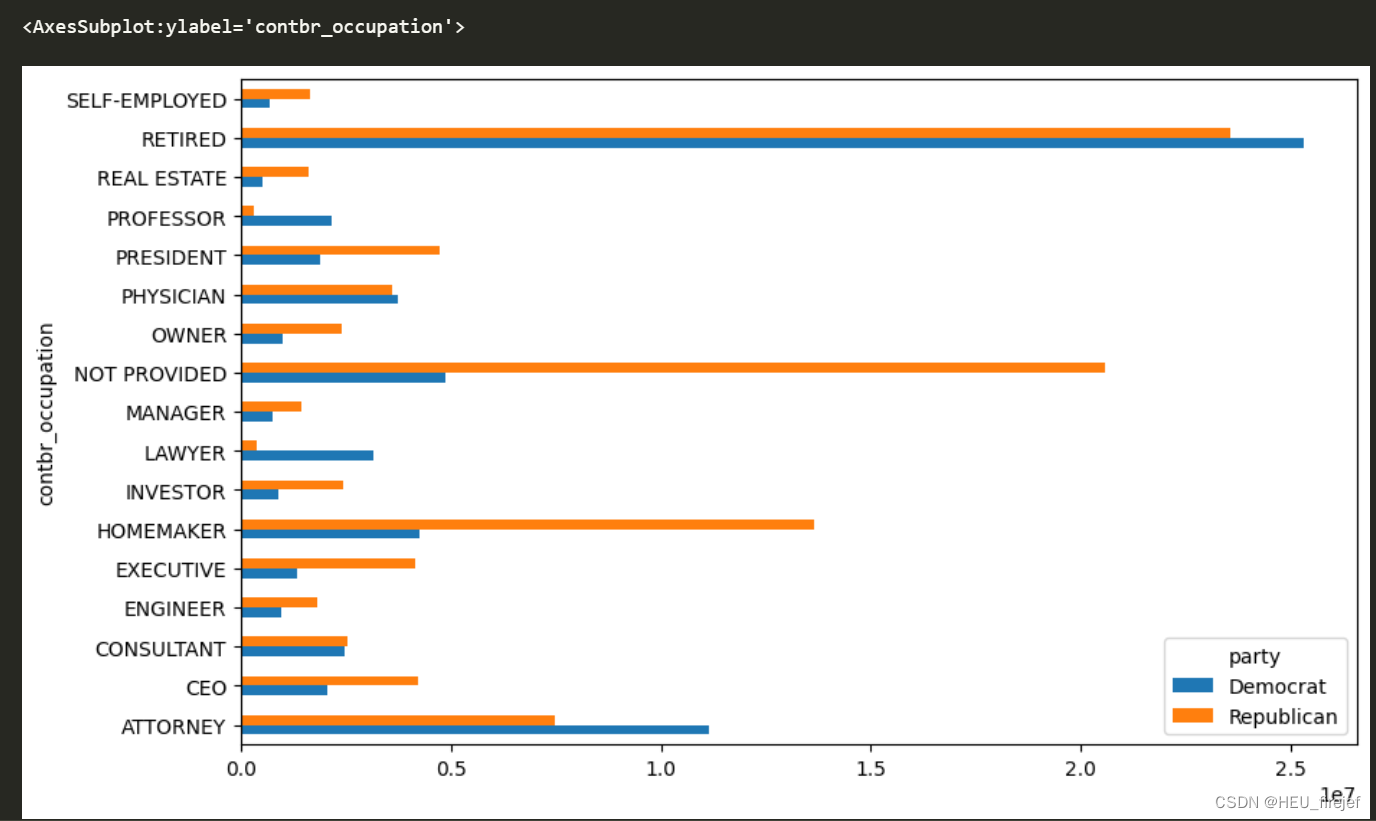
分析功能:
- 这行代码使用 plot 函数在当前图形窗口中绘制了一个水平柱状图,其中 x 轴表示捐款总额,y 轴表示职业。
(15)
def get_top_amounts(group, key, n=5):
totals = group.groupby(key)["contb_receipt_amt"].sum()
return totals.nlargest(n)
分析功能:
- 函数首先使用 groupby 函数按照 key 列对 group 数据帧进行分组,然后计算每个组中 “contb_receipt_amt” 列的总和。
- 接下来,它使用 nlargest 函数选择前 n 个最大值并返回。
(16)
grouped = fec_mrbo.groupby("cand_nm")
grouped.apply(get_top_amounts, "contbr_occupation", n=7)
grouped.apply(get_top_amounts, "contbr_employer", n=10)
输出结果:
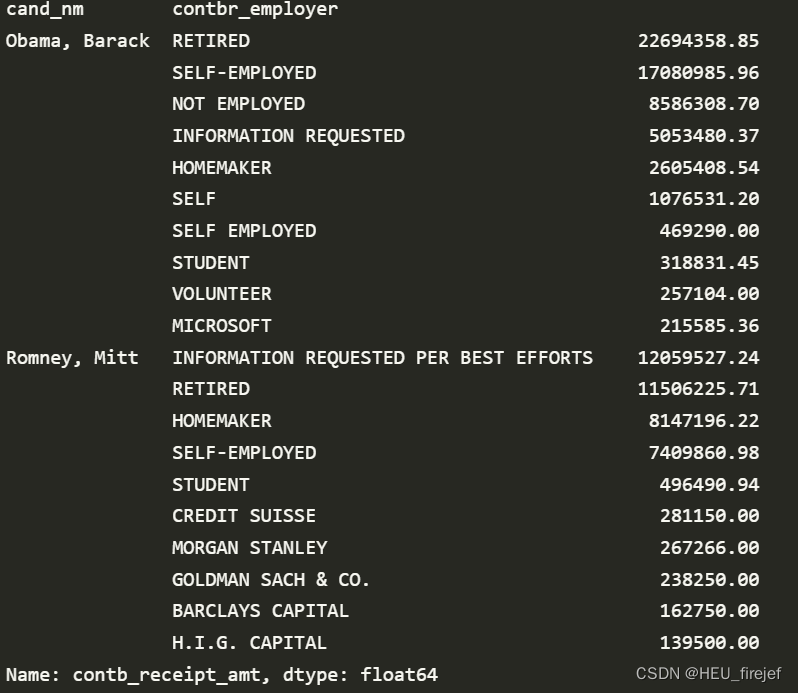
分析功能:
- 这段代码首先使用 groupby 函数按照 “cand_nm” 列对 fec_mrbo 数据帧进行分组,并将结果存储在名为 grouped 的变量中。
- 接下来,它使用 apply 函数对每个组应用 get_top_amounts 函数,计算每个组中 “contbr_occupation” 列的前 7 个最大值,并打印出结果。
- 然后,它再次使用 apply 函数对每个组应用 get_top_amounts 函数,计算每个组中 “contbr_employer” 列的前 10 个最大值,并打印出结果。
(17)
bins = np.array([0, 1, 10, 100, 1000, 10000,
100_000, 1_000_000, 10_000_000])
labels = pd.cut(fec_mrbo["contb_receipt_amt"], bins)
labels
输出结果:
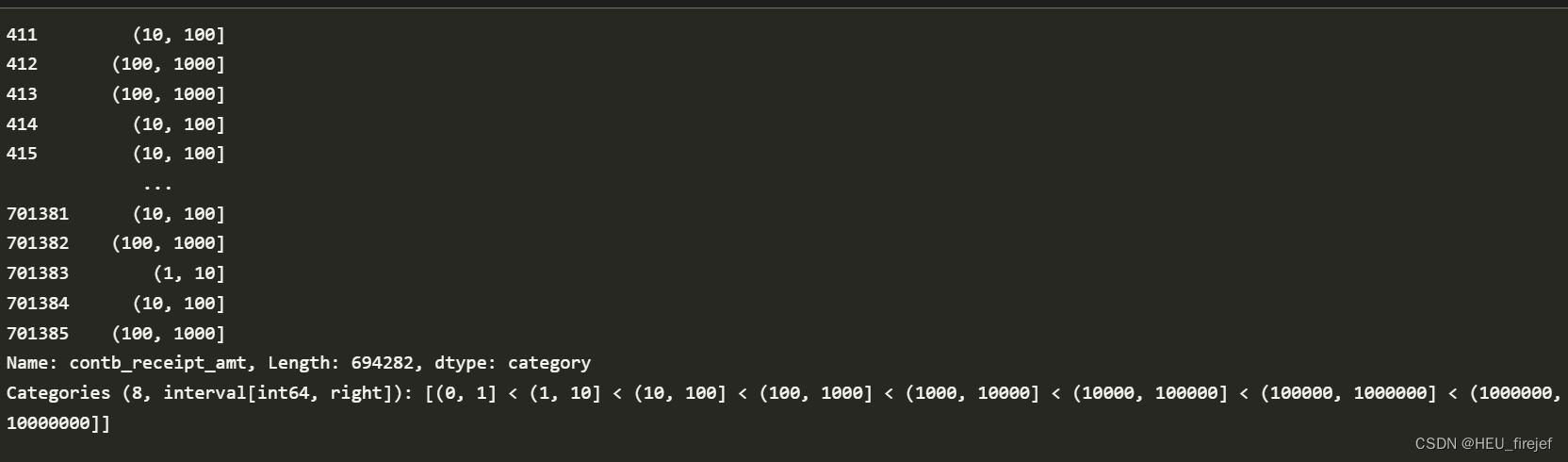
分析功能:
- 这段代码首先定义了一个名为 bins 的数组,表示用于分箱的边界值。
- 接下来,它使用 cut 函数将 fec_mrbo 数据帧中 “contb_receipt_amt” 列的值分箱,并将结果存储在名为 labels 的变量中。
- 最后,它打印出 labels 变量的值,显示了每个捐款金额所属的箱。
(18)
grouped = fec_mrbo.groupby(["cand_nm", labels])
grouped.size().unstack(level=0)
输出结果:
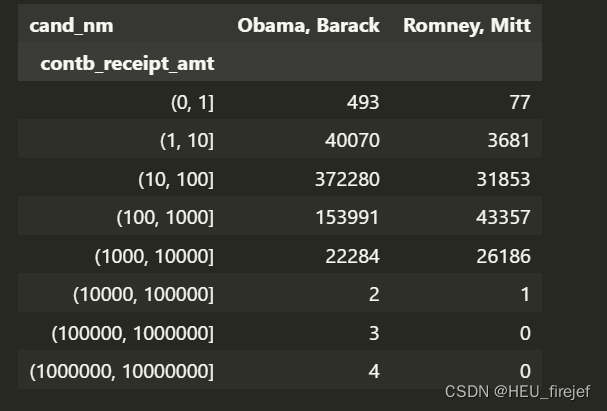
分析功能:
- 这段代码首先使用 groupby 函数按照 “cand_nm” 列和 labels 变量对 fec_mrbo 数据帧进行分组,并将结果存储在名为 grouped 的变量中。
- 接下来,它使用 size 函数计算每个组的大小,然后使用 unstack 函数将结果转换为数据帧,并打印出来。
(19)
plt.figure()
输出结果:
分析功能:
- 这行代码使用 matplotlib 库中的 figure 函数创建了一个新的图形窗口
(20)
bucket_sums = grouped["contb_receipt_amt"].sum().unstack(level=0)
normed_sums = bucket_sums.div(bucket_sums.sum(axis="columns"),
axis="index")
normed_sums
normed_sums[:-2].plot(kind="barh")
输出结果:
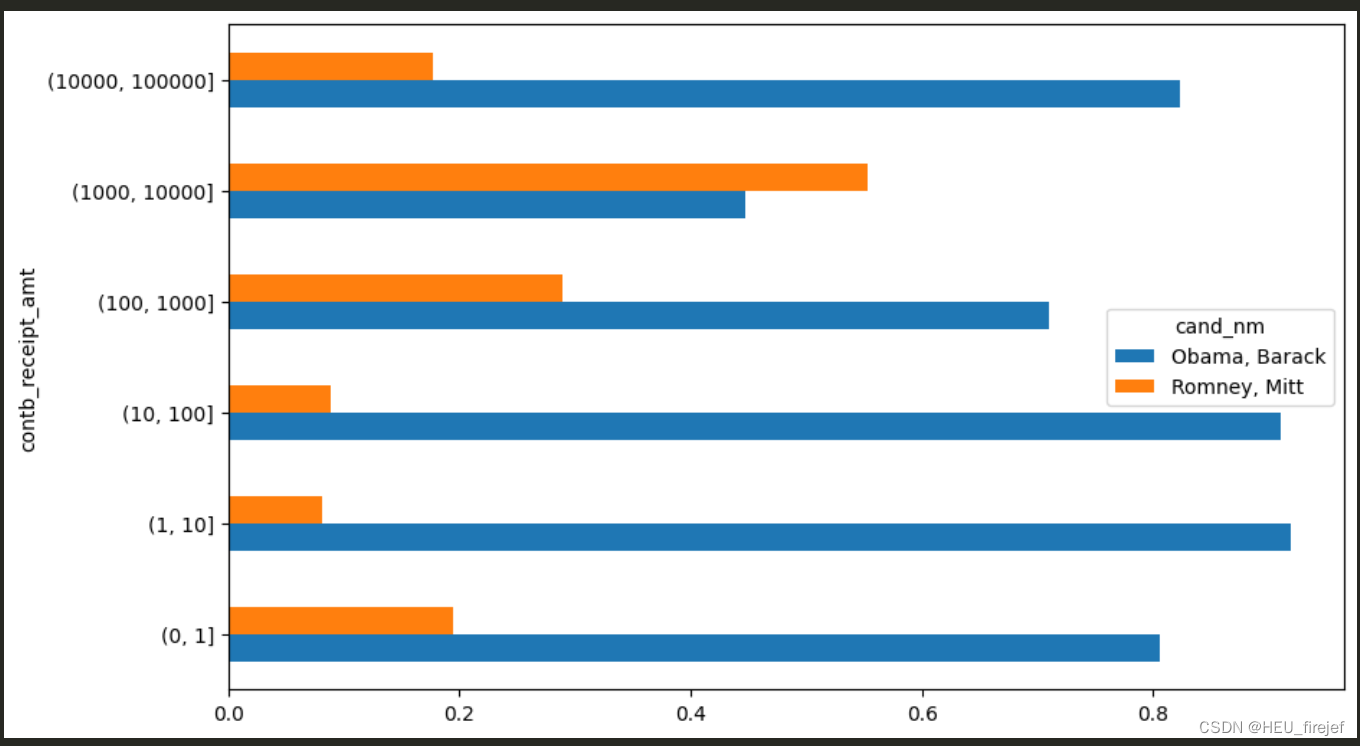
分析功能:
- 这段代码首先使用 sum 函数计算每个组中 “contb_receipt_amt” 列的总和,然后使用 unstack 函数将结果转换为数据帧,并将结果存储在名为 bucket_sums 的变量中。
- 接下来,它使用 div 函数将每个单元格的值除以行总和,然后将结果存储在名为 normed_sums 的变量中。
- 然后,它打印出 normed_sums 变量的值,显示了每个候选人在不同捐款金额区间内的捐款比例。
- 最后,它使用切片选择除了最后两行以外的所有行,然后使用 plot 函数在当前图形窗口中绘制一个水平柱状图,显示每个候选人在不同捐款金额区间内的捐款比例。
(21)
grouped = fec_mrbo.groupby(["cand_nm", "contbr_st"])
totals = grouped["contb_receipt_amt"].sum().unstack(level=0).fillna(0)
totals = totals[totals.sum(axis="columns") > 100000]
totals.head(10)
输出结果:
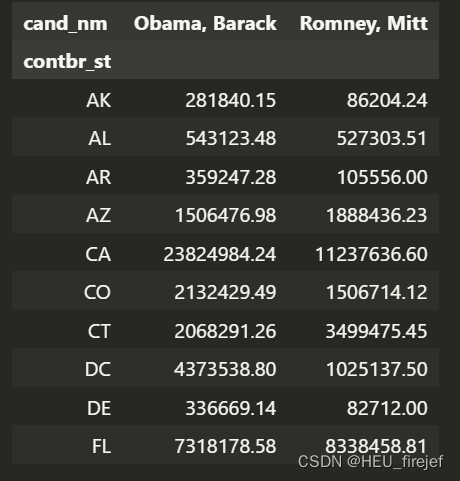
分析功能:
- 这段代码首先使用 groupby 函数按照 “cand_nm” 列和 “contbr_st” 列对 fec_mrbo 数据帧进行分组,并将结果存储在名为 grouped 的变量中。
- 接下来,它使用 sum 函数计算每个组中 “contb_receipt_amt” 列的总和,然后使用 unstack 函数将结果转换为数据帧。由于某些组可能没有数据,因此它使用 fillna 函数将缺失值填充为 0。
- 然后,它使用布尔索引选择行总和大于 100000 的行,并将这些行存储在 totals 变量中。
- 最后,它使用 head 函数选择前 10 行并打印出来。
(22)
percent = totals.div(totals.sum(axis="columns"), axis="index")
percent.head(10)
输出结果:
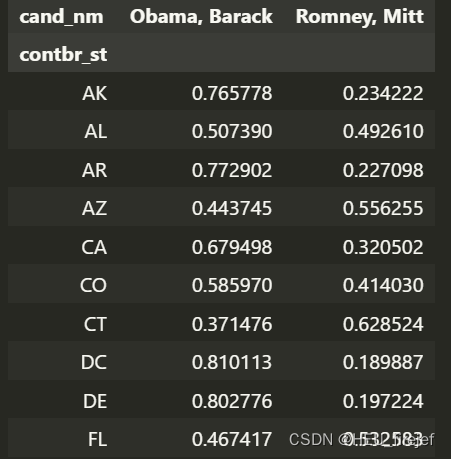
分析功能:
- 这段代码首先使用 div 函数将 totals 变量中每个单元格的值除以行总和,然后将结果存储在名为 percent 的变量中。
- 接下来,它使用 head 函数选择前 10 行并打印出来。
总结
不积跬步,无以至千里,不积细流,无以成江海。相信读者通过这片文章后,一定能够熟练掌握如何利用python进行数据分析,相信读者一定能够有所收获,在未来的学习或者工作生活中,能够大展身手!