要从CSV文件中访问数据,我们需要一个函数read_csv(),它以数据帧的形式检索数据。
read_csv() 语法:
pd.read_csv(filepath_or_buffer, sep=’ ,’ , header=’infer’, index_col=None, usecols=None, engine=None, skiprows=None, nrows=None)
参数:
filepath_or_buffer: 它是要使用此函数检索的文件的位置。它接受文件的任何字符串路径或URL。
sep: 它代表分隔符,默认值为’,',如CSV(逗号分隔值)。
header: 它接受int、int的列表、用作列名的行号以及数据的开始。 如果没有传递名称,即, header=None,则第一列显示为0,第二列显示为1,依此类推。
usecols: 它仅用于从CSV文件中检索选定的列。
nrows: 它表示要从数据集中显示的行数。
index_col: 在默认为None的时候,pandas会自动将第一列作为索引,并额外添加一列。所以大多我们会使用index_col=0,直接将第一列作为索引,不额外添加列。
skiprows: 跳过新数据框中传递的行。
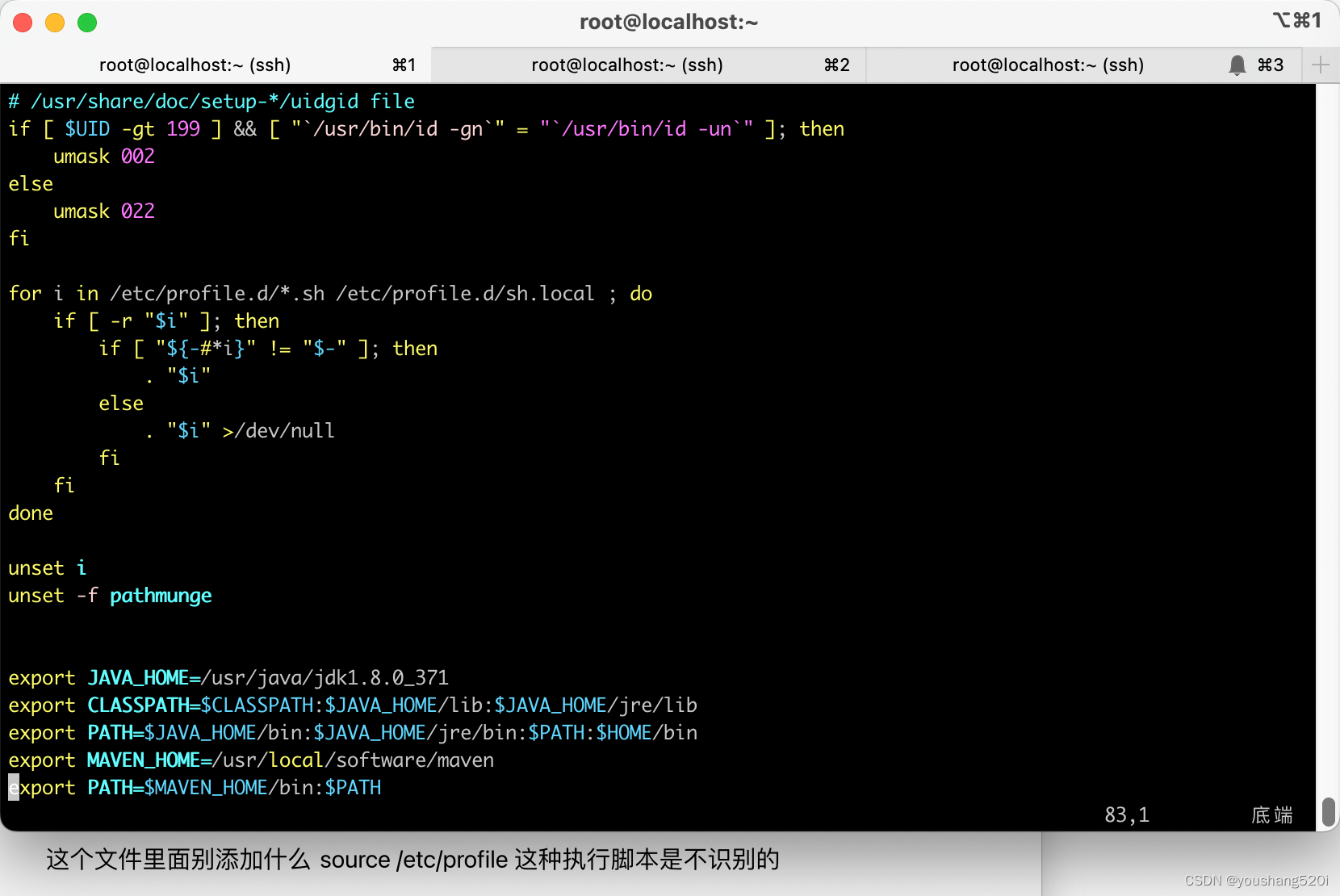
使用read_csv 读取csv文件
# Import pandas
import pandas as pd
# reading csv file
pd.read_csv("example1.csv")
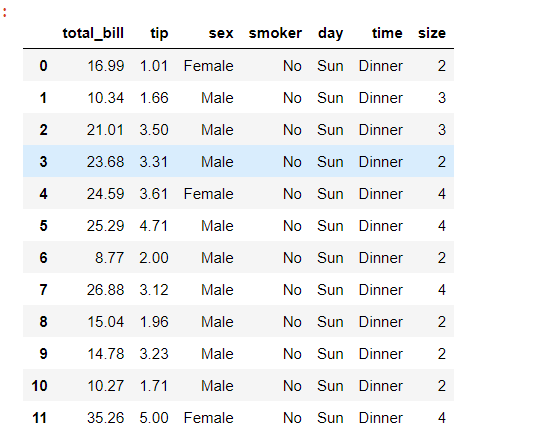
使用sep
# headbrain1 = "totalbill_tip, sex:smoker, day_time, size
# 16.99, 1.01:Female|No, Sun, Dinner, 2
# 10.34, 1.66, Male, No|Sun:Dinner, 3
# 21.01:3.5_Male, No:Sun, Dinner, 3
#23.68, 3.31, Male|No, Sun_Dinner, 2
# 24.59:3.61, Female_No, Sun, Dinner, 4
# 25.29, 4.71|Male, No:Sun, Dinner, 4"
# Importing pandas library
import pandas as pd
# Load the data of csv
df = pd.read_csv('headbrain1.csv',
sep='[:, |_]',
engine='python')
# Print the Dataframe
df
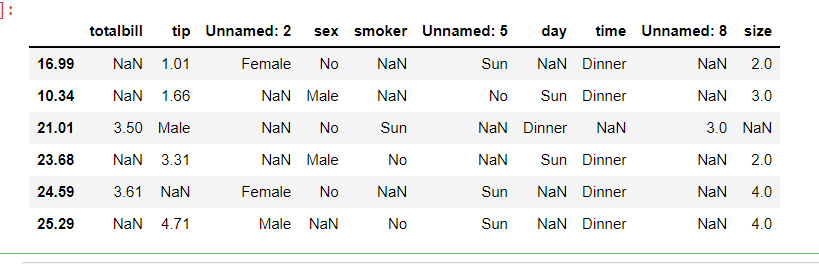
使用usecols
df = pd.read_csv('example1.csv',
header=0,
usecols=["tip", "sex", "time"])
df
使用index_col
df = pd.read_csv('example1.csv',
header=0,
index_col=["sex", "tip"],
usecols=["tip", "sex", "time"])
df
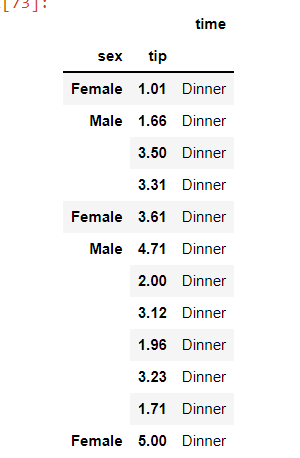
使用nrows
df = pd.read_csv('example1.csv',
header=0,
index_col=["tip", "sex"],
usecols=["tip", "sex", "time"],
nrows=5)
df
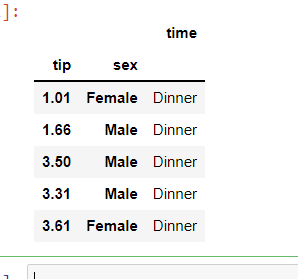
使用skiprows
pd.read_csv("example1.csv", skiprows = [1,12])
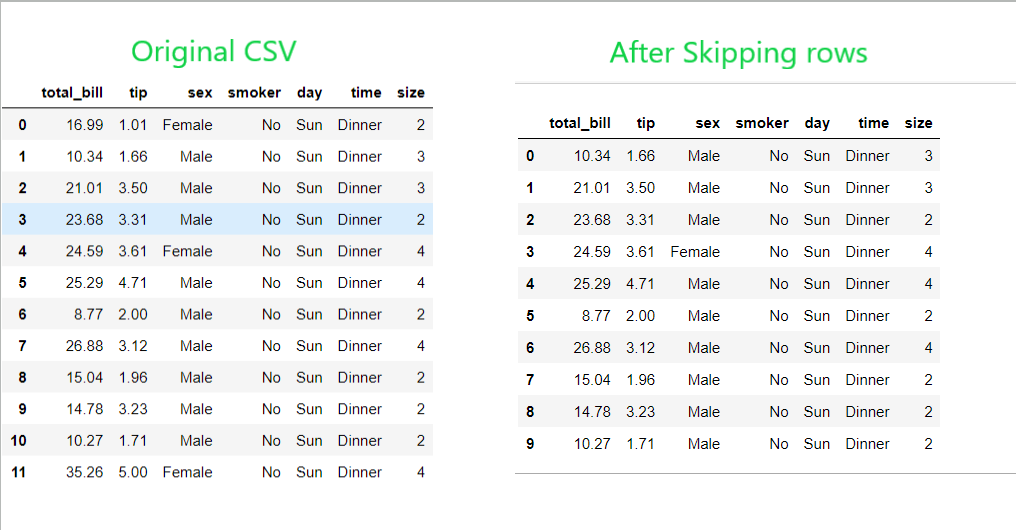
导出dataframe数据到csv
假设你正在做一个数据科学项目,你要处理其中一个最重要的任务,即数据清理。 数据清理后,您不希望丢失清理后的数据框,因此希望将清理后的数据框另存为CSV。 让我们看看如何将Pandas DataFrame导出为CSV文件。 Pandas使我们能够通过其内置的to_csv()函数做到这一点。
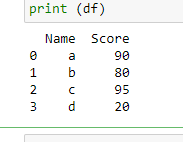
首先,让我们创建一个示例数据框
# importing the module
import pandas as pd
# making the data
scores = {'Name': ['a', 'b', 'c', 'd'],
'Score': [90, 80, 95, 20]}
# creating the DataFrame
df = pd.DataFrame(scores)
# displaying the DataFrame
print(df)
# converting to CSV file
df.to_csv("your_name.csv")

如果你得到一个UnicodeEncodeError,只需要传递带有’utf-8’值的编码参数。
# converting to CSV file
df.to_csv("your_name.csv", encoding = 'utf-8')
可自定义参数
1.包括索引
您可以选择是否要添加自动索引。 默认值为True。 将其设置为False。
# converting to CSV file
df.to_csv('your_name.csv', index = False)

2.仅导出选定的列
如果只想导出几个选定的列,可以将其作为’columns = [“col1”,“col2”]传递给_csv()
# converting to CSV file
df.to_csv("your_name.csv", columns = ['Name'])
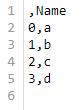
3.导出标题
您可以通过将header参数设置为True或False来选择是否要导出列名。 默认值为True。
# converting to CSV file
df.to_csv('your_name.csv', header = False)
4.处理NaN
如果数据框具有NaN值,则可以选择将其替换为其他字符串。 默认值为“”。
# converting to CSV file
df.to_csv("your_name.csv", na_rep = 'nothing')
5.用别的东西分开
如果不是用逗号分隔值,我们可以使用自定义值来分隔它。
# converting to CSV file
# separated with tabs
df.to_csv("your_name.csv", sep ='\t')