微信公众号访问链接:java后端接口API性能优化技巧
推荐文章:
1、springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表;
2、SpringBoot用线程池ThreadPoolTaskExecutor异步处理百万级数据;
3、SpringBoot用线程池ThreadPoolExecutor处理百万级数据;
4、SpringBoot+MyBatis流式查询,处理大规模数据,提高系统的性能和响应能力
一、概述
要想成为一名优秀的java后端程序员,编写出高性能的后端服务接口是一个重要指标。针对公司项目,做了些降本增效的事情,其中发现接口耗时过长的问题,就集中搞了一次接口性能优化,顺便整理了这份文章,希望给大家在日后的项目工作中提供一丝帮助。

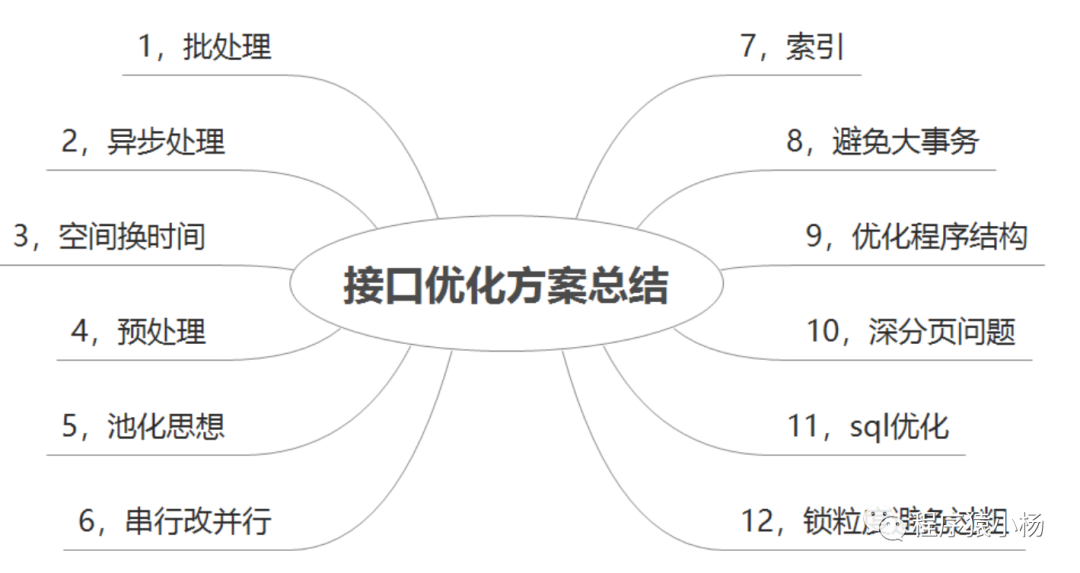
二、接口性能优化方案总结
2.1、async异步执行
思想:针对一些耗时较长且不影响主要业务的逻辑,可以采用异步执行,能降低接口耗时,来提升性能。具体可参考:SpringBoot使用@Async实现多线程异步。
常见的异步实现:线程池、消息队列MQ、Spring注解@Async、异步框架CompletableFuture、Spring ApplicationEvent事件。
2.2、批量入库
思想:批量数据插入数据库时,可以在批处理执行完成后一次性插入或更新数据库,避免多次 IO。具体使用可参考文章:springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表。
//for循环单笔入库list.stream().forEatch(msg->{insert();});//使用批量入库代替上面的for循环入库batchInsert();
2.3、池化技术
思想:池化技术最常见的是线程池、数据库连接池,解决的问题就是避免重复创建对象或创建连接,可重复利用,避免不必要损耗,毕竟创建回收也会占用时间。
例如:线程池使用:若你每次需要用到线程,都去创建,就会有增加一定的耗时,线程池可以重复利用线程,避免不必要的耗时,让任务并行处理。
具体案例参考:SpringBoot用线程池ThreadPoolTaskExecutor异步处理百万级数据。
2.4、索引
思想:数据库加索引能大大提高数据查询效率,但索引是否生效?索引设计是否合理?这些问题也需要我们同时去考虑。注意:在数据量很大的表中创建索引,最好选择在业务不繁忙时间段,避免影响线上业务正常使用。
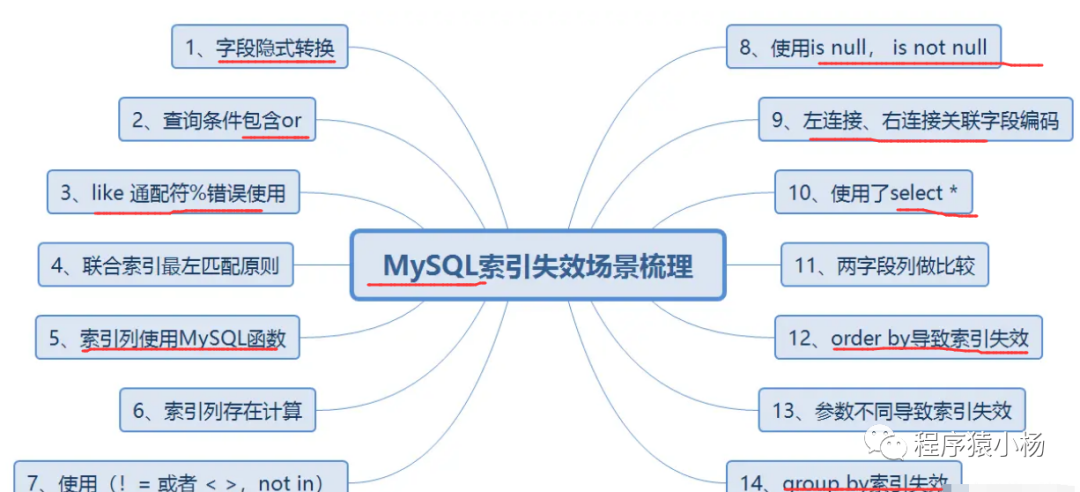
2.4.1、索引不生效场景
有时候虽然添加了索引,但是索引可能会失效,失效场景如下:

2.4.2、索引设计是否合理?
索引不是设计越多越好,设计必须要合理:
1、优先考虑设计联合索引,适当使用覆盖索引;
2、索引个数尽量不要超过5个;
3、索引最好选择数据区分度较高的字段(最好是唯一字段),如:血型太多重复字段就不适合创建索引。
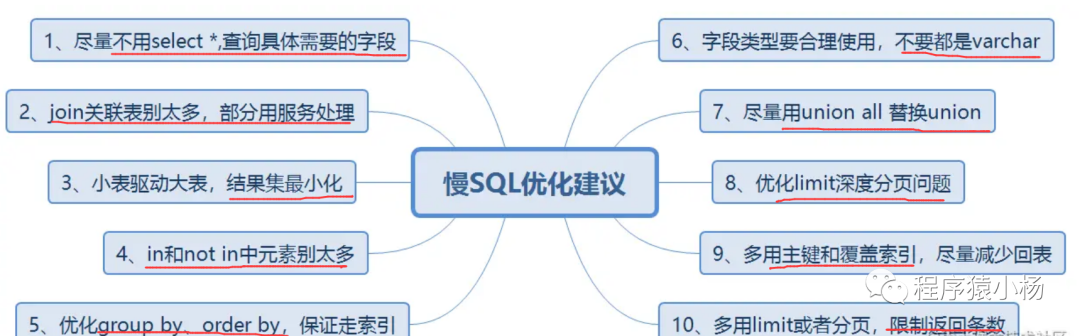
2.5、慢SQL优化
还可以进一步优化慢SQL语句,如:
2.6、使用缓存
思想:在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。缓存其实就是一种空间换时间的思想,就是你把要查的数据,提前放好到缓存里面,需要时,直接查缓存,而避免去查数据库或者计算的过程。常见的缓存包括:Redis缓存(推荐),JVM本地缓存,memcached,或者Map等。注意:缓存数据的一致性。常把一些变化频率不高的或不会发生变化的数据放入缓存中。具体使用可参考文章:springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表。
2.7、串行改并行
思想:串行:当前执行逻辑必须等上一个执行逻辑结束之后才执行,并行:两个执行逻辑互不干扰。所以并行相对来说就比较节省时间,当然是建立在没有结果参数依赖的前提下。
例如:串行:

并行:
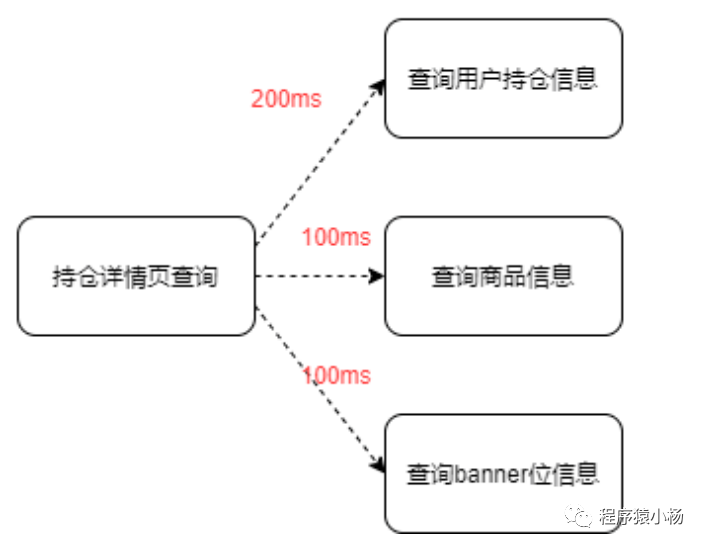
具体代码如下:可以使用CompletableFuture 并行调用提高性能,类似也可以使用多线程异步处理。
// 查询获奖经历LambdaQueryWrapper<RewardExp> rewardExpQuery1 = new LambdaQueryWrapper<RewardExp>().eq(RewardExp::getResumeId, resume.getId()).eq(RewardExp::getDelFlag, NORMAL).orderByDesc(RewardExp::getDate);CompletableFuture<List<RewardExp>> rewardExpFuture1 = CompletableFuture.supplyAsync(() ->rewardExpMapper.selectList(rewardExpQuery1));// 查询资格证书LambdaQueryWrapper<Credential> credentialQuery1 = new LambdaQueryWrapper<Credential>().eq(Credential::getResumeId, resume.getId()).eq(Credential::getDelFlag, NORMAL).orderByDesc(Credential::getDate);CompletableFuture<List<Credential>> credentialFuture1 = CompletableFuture.supplyAsync(() ->credentialMapper.selectList(credentialQuery1));// 查询岗位信息LambdaQueryWrapper<ResumeJobs> jobsQuery1 = new LambdaQueryWrapper<ResumeJobs>().eq(ResumeJobs::getResumeId, resume.getId()).eq(ResumeJobs::getDelFlag, NORMAL);CompletableFuture<List<ResumeJobs>> jobsFuture1 = CompletableFuture.supplyAsync(() ->resumeJobsMapper.selectList(jobsQuery1));//合并结果CompletableFuture.allOf(rewardExpFuture1, credentialFuture1, jobsFuture1).join();
2.8、优化程序逻辑
思想:优化程序逻辑、程序代码,是可以节省接口耗时的。比如:程序创建多不必要的对象、或者程序逻辑混乱,多次重复查数据库、又或者实现逻辑算法不是最高效的等等,在多人维护一个项目时比较多见。
解决思路:我们需要针对接口整体做重构,梳理清楚代码逻辑,评估每个代码块的作用和用途,检查是否存在不必要的对象创建、逻辑调用或者代码细节之类的,是否符合一些编码规范等。
2.9、深度分页问题
select id,name,sex from personwhere create_time> '2020-09-19'limit 100000,100;
limit 100000,100 意味着会扫描 100100 行,然后返回 100 行,丢弃掉前 100000 行。所以执行速度很慢。一般可以采用如下方式优化:
2.9.1、 标签记录法
就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到了。
select id,name,sex from personwhere id> 100000limit 100;
但是局限性是需要一个连续自增的字段,而且需要前端把上次最大值传给后端。
2.9.2、延迟关联法(个人推荐)
延迟关联法,就是把条件转移到主键索引树,然后减少回表。优化对比如下:(测试数据为100万)
#延迟关联法耗时0.040sSELECT s1.s_id,s1.student_name,s1.phoneFROM student s1INNER JOIN ( SELECT s.s_id FROM student s WHERE s.age > 20 LIMIT 100000, 100 ) AS s2ON s1.s_id = s2.s_id# 正常查询0.674sSELECT s1.s_id,s1.student_name,s1.phone FROM student s1WHERE s1.age > 20 LIMIT 100000, 100
优化思路:先通过idx_age二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
2.10、锁粒度避免过粗
锁一般是为了在高并发场景下保护共享资源采用的一种手段。但是若锁的粒度太粗,会很影响接口性能。
关于锁粒度:就是你要锁的范围有多大,无论是使用synchronized加锁还是redis分布式锁,只需要在共享临界资源加锁即可,不涉及共享资源的,就不必要加锁。例如:你在家里上卫生间,你只需要把卫生间锁住,而不用把家里的每个房间都锁住。参考案例如下:
误的加锁方式:
//非共享资源方法private void methodA(){}//共享资源方法private void methodB(){}//加锁private int wrong(){synchronized(this){methodA();methodB();}}
正确的加锁方式:
//非共享资源方法private void methodA(){}//共享资源方法private void methodB(){}//加锁private int right(){methodA(); //非共享资源方法synchronized(this){methodB(); //共享资源方法}}
2.11、避免长事务问题
所谓长事务问题,就是session运行时间较长的事务,期间可能伴随cpu、内存升高,严重者可导致DB服务端整体响应缓慢,导致在线应用无法使用,并且由于事务一致不提交,也会导致数据库连接被占用,影响到别的请求访问数据库,影响别的接口性能。所以在线高并发业务中应该尽量避免长事务的发生。产生长事务的原因,除了sql本身可能存在问题外,和应用层的事务控制逻辑也有很大的关系。
例如:直接使用@Transactional 注解,Spring的声明式事务,整个方法都在事务中,而且里面存在远程RPC调用,容易出现长事务问题。
@Transactionalpublic int createUser(User user){//保存用户信息userDao.save(user);//更新数据标识passCertDao.updateFlag(user.getPassId());// 该方法为远程RPC接口 发送邮件sendEmailRpc(user.getEmail());return user.getUserId();}
2.11.1、如何避免长事务问题?
1、RPC远程调用不要放到事务里面;
2、查询操作尽量放到事务之外;
3、事务中避免处理太多数据;
4、并发场景下,尽量避免使用@Transactional注解声明式事务粒度太大,使用TransactionTemplate的编程式事务灵活控制事务的范围。
2.12.2、如何解决长事务问题?
1、增加对长事务的监控,记录长事务的logId,根据logId能查询到整个请求调用链日志,可以明确是哪个服务的哪个接口的哪个方法产生的;
2、根据日志检查是否存在慢SQL;
3、检查对应服务是否存在RPC远程调用包裹在事务中;
4、检查是否接口中使用了@Transactional注解声明式事务。
三、总结
解决服务接口性能问题,是程序员进阶的必经之路。找到接口性能问题出现位置,更高一级思考问题,站在接口设计者的角度去开发需求,会避免很多这样的问题,再结合以上介绍的优化方案进行处理,也是降本增效的一种行之有效的方式。
更多详细资料,请关注个人微信公众号或搜索“程序猿小杨”添加。

参考文章:
https://blog.csdn.net/m0_71777195/article/details/131018507?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_71777195/article/details/130741662?spm=1001.2014.3001.5502
觉得有用,请点这里↓↓↓