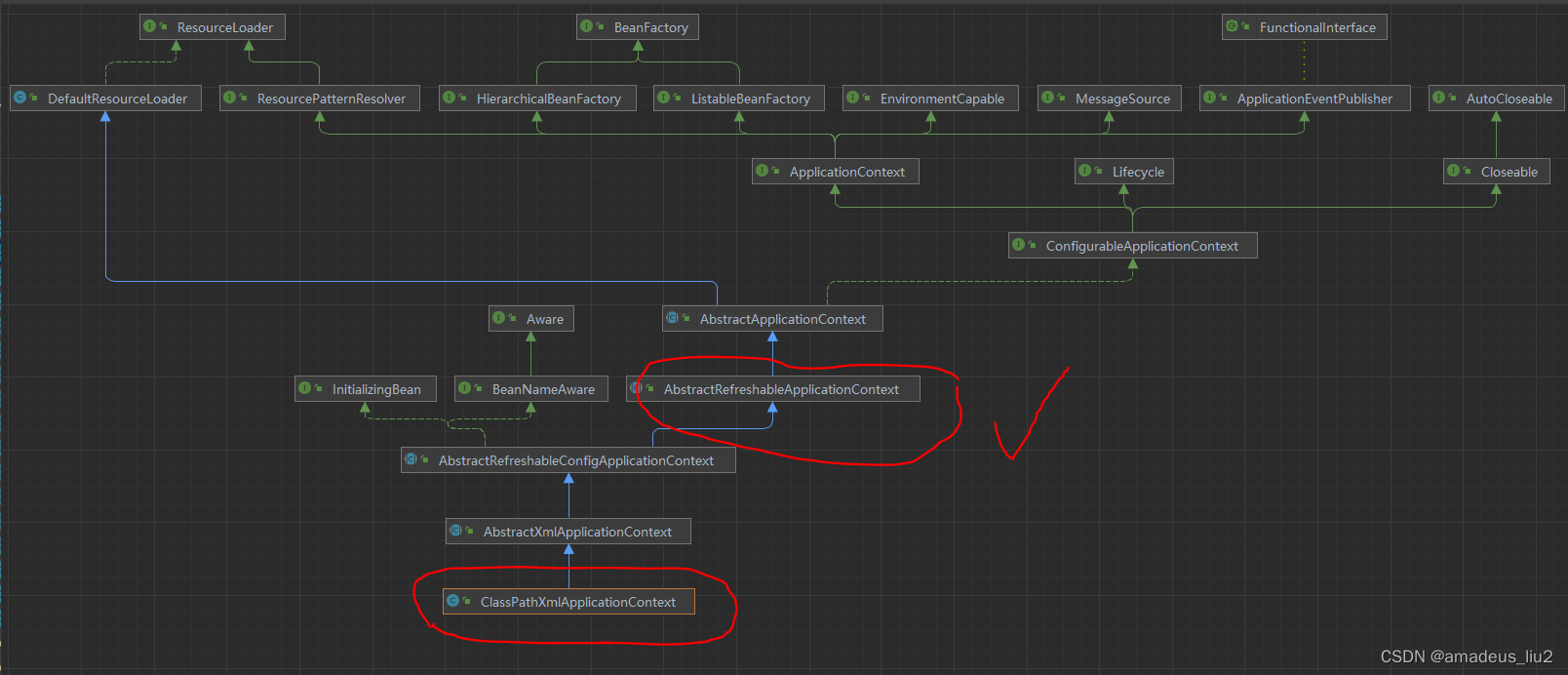
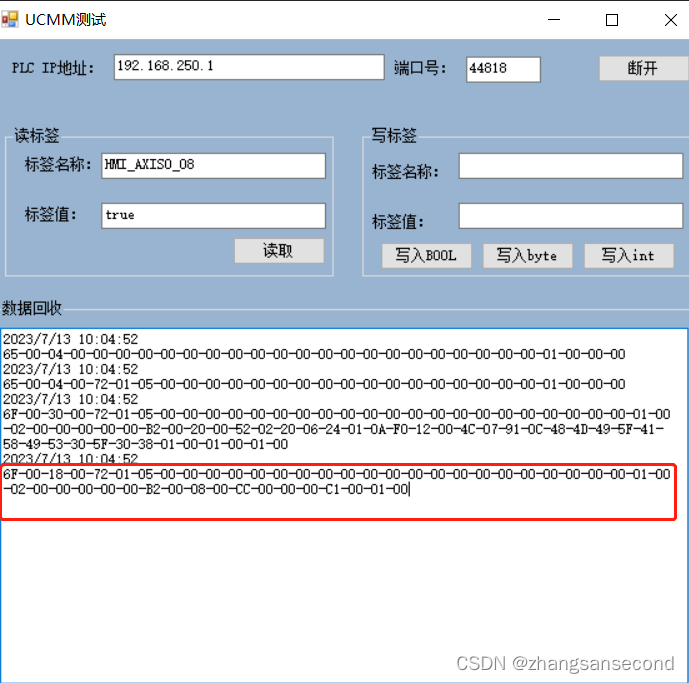
前言
- 本文简要介绍
Scaling law的主要结论 - 原文地址:Scaling Laws for Neural Language Models
- 个人认为不需要特别关注公式内各种符号的具体数值,而更应该关注不同因素之间的关系,比例等
Summary
-
Performance depends strongly on scale, weakly on model shape
- scale: 参数量 N N N, 数据量 D D D, 计算量 C C C
- shape: 模型深度,宽度,self-attention head数目等
-
Smooth power laws: N , D , C N, D, C N,D,C 三个因素中,当其他两个不受限制时,模型性能与任意一个因素都有
power-law relationship
-
Universality of overfitting:只要我们一起增大 N N N 和 D D D, 性能就会可预测得提高。但是当其中一个被固定,另一个在增加时,性能就会下降。二者比例关系大致为 N 0.74 / D N^{0.74}/D N0.74/D,这意味着,每次将模型增大8倍,只需要将数据量增大6倍来避免性能下降(过拟合)

-
Universality of training:在模型参数量不变的情况下,模型的表现是可以预测的。通过对早期的训练曲线进行推断,就能粗略估计训练更长时间后模型的表现
-
Transfer improves with text performance:当在分布不同的文本上评估模型时,结果与在验证集上的结果密切相关,损失的偏移量大致恒定。这说明用验证集的结果来作为评估指标是合理的
-
Sample efficiency:大模型能在更少的step内,更少的数据(图4)上达到相同的性能

-
Convergence is inefficient:当计算量固定时,但是模型大小和数据量没有限制时,大模型在得到最佳性能时,还远远没有收敛。最大训练效率训练比训练小模型到收敛是更 sample efficient的,数据需求随着计算量增长比较慢 D ∼ C 0.27 D \sim C^{0.27} D∼C0.27
-
Optimal batch size: 最好的batch size与loss有
power-law关系,也受到梯度噪声规模的影响
总的来说,LLM的性能随着模型大小,数据量和计算量的增大平滑,可预测地提升
Summary of Scaling Laws
当性能只受除了embedding层之外的模型参数N, dataset size D, compute budgec C_min三者之一限制时,自回归的 Transformer 模型的 test loss是可以用一个 power-law预测的。
-
模型参数受限时:

-
数据量受限时:

-
计算量受限时:


power-law α N , α D , α C m i n \alpha_N, \alpha_D, \alpha_C^{min} αN,αD,αCmin 代表当我们增加模型参数,数据量,计算量时模型性能提升的程度(越大越好), N c , D c , C c m i n N_c, D_c, C_c^{min} Nc,Dc,Ccmin的具体值没有实际意义
- 这里看到,提升数据量提升最大,其次是模型参数,最后才是计算量
batch size与模型在测试集上的表现
L
L
L 之间有一个 power-law


-
模型参数和数据量的公式结合起来看,可知,当增大模型参数时,应该以 N α N α D ∼ N 0.74 N^{\frac{\alpha_N}{\alpha_D}} \sim N^{0.74} NαDαN∼N0.74 的比例增大数据量,这里有一个将二者结合的方程(图4.左):

-
在有限的更新步数 S S S 下,test loss与 N , S N,S N,S 的关系为(图4.右)

- S c ∼ 2.1 × 1 0 3 , α s ∼ 0.76 S_c \sim 2.1 \times 10^3, \alpha_s \sim 0.76 Sc∼2.1×103,αs∼0.76
- S m i n ( S ) S_{min}(S) Smin(S) 是最小的可能的优化步数
当计算量 C C C 有限,其他因素不受限时,最佳的 N , B , S , D N,B,S,D N,B,S,D 与 C C C 的关系是


- 计算量增大时,最应该增大的是模型大小,而不是训练时间和数据量,这也说明,当模型变大时,其更加 sample efficient(用没那么大的数据量可以训出很大的模型)
- 然而实际上,由于硬件限制,人们通常将小模型训练更长的时间而不是追求 compute-efficient