文章目录
- 一、相关实际问题
- 二、跨机网络通信过程
- 1)跨机数据发送
- 2)跨机数据接收
- 3)跨机网络通信汇总
- 三、本机发送过程
- 1)网络层路由
- 2)网络设备子系统
- 3)驱动程序
- 四、本机接收过程
- 五、问题解答
系列文章:
- 深入理解Linux网络——内核是如何接收到网络包的
- 深入理解Linux网络——内核与用户进程协作之同步阻塞方案(BIO)
- 深入理解Linux网络——内核与用户进程协作之多路复用方案(epoll)
- 深入理解Linux网络——内核是如何发送网络包的
前面的章节深度分析了网络包的接收,也拆分了网络包的发送,总之收发流程算是闭环了。不过还有一种特殊的情况没有讨论,那就是接收和发送都在本机进行。而且实践中这种本机网络IO出现的场景还不少,而且还有越来越多的趋势。例如LNMP技术栈中的nginx和php-fpm进程就是通过本机来通信的,还有流行的微服务中sidecar模式也是本机网络IO。
一、相关实际问题
- 127.0.0.1本机网络IO需要经过网卡吗
- 数据包在内核中是什么走向,和外网发送相比流程上有什么差别
- 访问本机服务时,使用127.0.0.1能比本机IP(例如192.168.x.x)快吗
二、跨机网络通信过程
在开始讲述本机通信过程之前,先回顾前面的跨机网络通信。
1)跨机数据发送
-
应用层:send/sendto
-
系统调用:(send=>)sendto
- 构造msghdr并赋值(用户待发送数据的指针、数据长度、发送标志等)
- sock_sendmsg => __sock_sendmsg_nosec => sock->ops->sendmsg
-
协议栈:inet_sendmsg(AF_INET协议族对socck->ops->sendmsg的实现)
-
传输层
- sk->sk_prot->sendmsg
- tcp_sendmsg(tcp协议对sk->sk_prot->sendmsg的实现):数据拷贝到发送队列的skb
- tcp_write_xmit:拥塞控制、滑动窗口、包分段
- tcp_transmit_skb:拷贝skb、封装TCP头、调用网络层发送
-
网络层
- ip_queue_xmit:查找socket缓存的路由表,没有则查找路由项并缓存,为skb设置路由表,封装IP头并发送
- ip_local_out => __ip_local_out => nf_hook:netfilter过滤
- skb_dst(skb)->output(skb):找到skb路由表的dst条目,调用output方法
- ip_output:简单的统计,再次执行netfilter过滤,回调ip_finish_output
- ip_finish_output:校验数据包的长度,如果大于MTU,就会执行分片
- ip_finish_output2:调用邻居子系统定义的方法
-
-
邻居子系统
-
rt_nexthop:获取路由下一跳的IP信息
-
__ipv4_neigh_lookup_noref:根据下一条IP信息在arp缓存中查找邻居项
-
__neigh_create:创建一个邻居项,并加入邻居哈希表
-
dst_neigh_output => neighbour->output(实际指向neigh_resolve_output):
- 封装MAC头(可能会先触发arp请求)
- 调用dev_queue_xmit发送到下层
-
-
网络设备子系统
- dev_queue_xmit:选择发送队列,获得排队规则,存在队列则调用__dev_xmit_skb
- __dev_xmit_skb:根据qdisc状态执行不同逻辑
- q->enqueue:入队
- __qdisc_run:开始发送
- qdisc_restart => sch_direct_xmit => dev_hard_start_xmit:从队列取出一个skb并发送
- dev->netdev_ops->ndo_start_xmit:调用驱动里的发送回调函数,将数据包传给网卡设备
-
驱动程序:igb_xmit_frame
- igb_xmit_frame_ring:获取发送环形数组队列下一个可用的缓冲区,挂上skb
- igb_tx_map:获取下一个描述符指针,将skb数据映射到网卡可访问的内存DMA区域
-
硬件发送
- 发送完毕触发硬中断通知CPU
- igb_msix_ring => napi_schedule => __raise_softirq_irqoff:硬中断处理,发起软中断
- net_rx_action => igb_poll:软中断处理
- igb_clean_tx_irq:释放skb,清除tx_buffer,清理DMA
2)跨机数据接收
-
硬件
- 网卡把帧DMA到内存
- 发起硬中断通知CPU
-
驱动程序
- igb_msix_ring => napi_schedule => __raise_softirq_irqoff:硬中断处理,发起软中断
- net_rx_action => igb_poll:软中断处理
- igb_clean_rx_irq:从RingBuffer取出数据包进行初步处理、检查完整性等,并将其封装为sk_buff添加到网络接收队列
-
网络设备子系统:netif_receive_skb
- __netif_receive_skb_core:遍历ptype_all链表处理数据包(tcp_dump抓包点),遍历ptype_base哈希表处理数据包
- deliver_skb:根据上述遍历到的协议,传递给对应协议处理函数进行进一步的处理。例如IP数据包(ptype_base中)则将其传递给IP协议处理模块。
-
网络协议栈处理:pt_prev->func
-
网络层
- ip_rcv:通过Netfilter进行进一步处理,比如网络地址转换(NAT)、防火墙过滤等操作
- ip_rcv_finish => ip_local_deliver_finish:使用inet_protos拿到协议的函数地址,根据包中的协议类型选择分发。在这里skb包将会进一步被派送到更上层的协议中,UDP或TCP
-
传输层
- tcp_v4_rcv:获取tcp头和ip头,拿到目的ip地址和端口,找到对应的socket
- tcp_v4_do_rcv => tcp_rcv_established:将接收到的数据放到socket的接收队列尾部,并调用sk_data_ready来唤醒在socket上等待的用户进程
- sock_def_readable =>autoremove_wake_function => default_wake_function:唤醒进程
-
-
用户进程
- 系统调用recv => sock_recvmsg ==> __sock_recvmsg ==> __sock_recvmsg_nosec
- sock->ops->recvmsg:在AF_INET中其指向的是inet_recvmsg
- inet_recvmsg => sk->sk_prot->recvmsg:在SOCK_STREAM中它的实现是tcp_recvmsg
- tcp_recvmsg:遍历接收队列,如果数据量不满足则阻塞进程
- sk_wait_data:定义了一个等待队列项wait,在这个新的等待队列项上注册了回调函数autoremove_wake_function,并把当前进程描述符current关联到其.private成员上,让出cpu进入睡眠
- 睡眠===
- 唤醒后继续遍历队列接收数据
3)跨机网络通信汇总
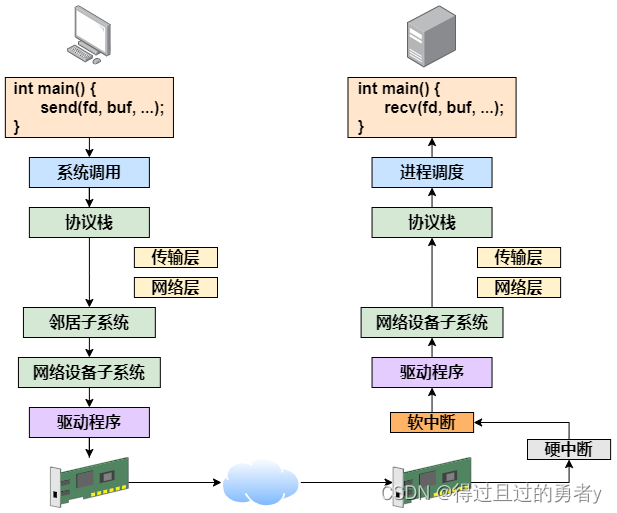
三、本机发送过程
上面主要介绍了跨机时整个网络的发送过程, 而在本机网络IO过程中,会有一些差别。主要的差异有两部分,分别是路由和驱动程序。
1)网络层路由
发送数据进入协议栈到达网络层的时候,网络层入口函数是ip_queue_xmit。在网络层里会进行路由选择,路由选择完毕再设置一些IP头,进行一些Netfilter的过滤,数据包分片等操作,然后将包交给邻居子系统。
对于本机网络IO来说,特殊之处在于在local路由表中就可以找到路由项,对应的设备都是用loopback网卡,也就是常说的lo设备。
我们重新回到之前网络层查找路由项的部分代码:
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
// 检查socket中是否有缓存的路由表
rt = (struct rtable*)__sk_dst_check(sk, 0);
......
if(rt == null) {
// 没有缓存则展开查找路由项并缓存到socket中
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
}
查找路由项的函数时ip_route_output_ports,它经过层层调用,来到关键的部分——fib_lookup
static inline int fib_lookup(struct net *net, const struct flowi4 *flp, struct fib_result *res)
{
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
if(!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
// 查找与给定流(由flp指定)匹配的路由项,并将查找结果存储在res中。FIB_LOOKUP_NOREF是传递给此函数的标志,用于指定查找行为的一些细节。
// 查找成功返回0
return 0;
table = fib_get_table(net, RT_TABLE_MAIN);
if(!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
return -ENETUNREACH;
}
在fib_lookup中将会对local和main两个路由表展开查询,并且先查询local后查询main。我们在Linux上使用ip命令可以查看到这两个路由表,这里只看local路由表(因为本机网络IO查询到整个表就结束了)
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel host src 127.0.0.1
从上述结果可以看出127.0.0.1的路由在local路由表中就能够找到。
上面路由表中10.143.x.y dev eth0是本机的局域网IP,虽然写的是dev eth0,但是其实内核在初始化local路由表的时候,把local路由表里所有的路由项都设置为了RTN_LOCAL。所以即使本机IP不用环回地址,内核在路由项查找的时候判断类型是RTN_LOCAL,仍然会使用net->loopback_dev,也就是lo虚拟网卡。
此处可以使用tcpdump -i eht0 port 8888以及telnet 10.143.x.y 8888进行验证,telnet后tcpdump并不会收到网络请求,因为发给的是lo。
之后fib_lookup的工作完成,返回上一层__ip_route_output_key函数继续执行。
struct rtable *ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
if(fib_lookup(net, fl4, &res) {
}
if(res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
......
}
......
}
对于本机的网络请求,设备将全部使用net->loopback_dev,也就是lo虚拟网卡。接下来的网络层仍然和跨机网络IO一样(所以本机网络IO如果skb大于MTU仍然会进行分片,不过lo虚拟网卡(65535)的MTU(1500)比Ethernet大得多),最终会经过ip_finish_output,进入邻居子系统的入口函数dst_neigh_output。
在邻居子系统函数中经过处理后,进入网络设备子系统(入口函数是dev_queue_xmit)
2)网络设备子系统
网络设备子系统的入口函数是dev_queue_xmit,其中会判断是否有队列。对于有队列的物理设备,该函数进行了一系列复杂的排队等处理后,才调用dev_hard_start_xmit,从这个函数在进入驱动程序igb_xmit_frame来发送。在这个过程中还可能触发软中断进行发送。
但是对于启动状态的回环设备(q->enqueue判断为false)来说就简单多了,它没有队列的问题,直接进入dev_hard_start_xmit。
int dev_queue_xmit(struct sk_buff *skb)
{
q = rcu_dereference_bh(txq_qdisc);
if(q->enqueue) { // 回环设备这里返回false
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
// 开始回环设备处理
if(dev->flags & IFF_UP) {
dev_hard_start_xmit(skb, dev, txq, ...);
......
}
}
在dev_hard_start_xmit函数中还将调用设备驱动的操作函数,对于回环设备的而言,其“设备驱动”的操作函数ops->ndo_start_xmit指向的是loopback_xmit(不同于正常网络设备的igb_xmit_frame)。
3)驱动程序
static netdev_tx_t loopback_xmit(struct sk_buff *skb, struct net_device *dev)
{
// 剥离掉和源socket的联系
skb_orphan(skb);
// 调用netif_rx
if(likely(netif_rx(skb) == NET_RX_SUCCESS) {}
}
loopback_xmit中首先调用skb_orphan先把skb上的socket指针去掉了,接着调用netif_tx,在该方法中最终会执行到enqueue_to_backlog。
在本机IO发送的过程中,传输层下面的skb就不需要释放了,直接给接收方传过去就行。不过传输层的skb就节约不了,还是需要频繁地申请和释放。
static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail)
{
sd = &per_cpu(softnet_data, cpu);
......
__skb_queue_tail(&sd->input_pkt_queue, skb);
......
__napi_schedule(sd, &sd->backlog);
}
enqueue_to_backlog函数用于把要发送的skb插入softnet_data->input_pkt_queue队列
具体步骤如下:
- sd = &per_cpu(softnet_data, cpu):获取给定 CPU 的softnet_data结构。这个结构保存了这个 CPU 的一些网络处理状态和数据,比如input_pkt_queue。
- __skb_queue_tail(&sd->input_pkt_queue, skb):将数据包skb加入到input_pkt_queue队列的尾部。
- __napi_schedule(sd, &sd->backlog):调度该函数来触发软中断处理这个队列。
这里触发的软中断类型是NET_RX_SOFTIRQ,只有触发完软中断,发送过程才算完成了。
四、本机接收过程
发送过程触发软中断后,会进入软中断处理函数net_rx_action。
在跨机地网络包地接收过程中,需要经过硬中断,然后才能触发软中断。而在本机地网络IO过程中,由于并不真的过网卡,所以网卡地发送过程、硬中断就都省去了,直接从软中断开始。
对于igb网卡来说,软中断中轮询调用的poll函数指向的是igb_poll函数。而对于loopback网卡来说,poll函数是process_backlog。
static int process_backlog(struct napi_struct *napi, int quota)
{
while() {
while((skb = __skb_dequeue(&sd->process_queue)) {
__netif_receive_skb(skb);
}
// skb_queue_splice_tail_init()函数用来将链表a(输入队列)的元素链接到链表b(处理队列)上
// 形成一个新的链表b,并将原来a的头变成了空链表
qlen = skb_queue_len(&sd->input_pkt_queue);
if(qlen)
skb_queue_splice_tail_init(&sd->input_pkt_queue, &sd->process_queue);
}
}
}
这个函数用于反复处理队列中的数据包,直到队列为空或者处理的数据包数量达到了指定的配额(quota)。
在内层循环中,它使用 __skb_dequeue() 函数从 process_queue 中取出一个数据包,然后使用 __netif_receive_skb() 函数处理这个数据包。
在内层循环结束后,它检查 input_pkt_queue(输入数据包队列)是否还有剩余的数据包。如果有,它使用 skb_queue_splice_tail_init() 函数将 input_pkt_queue 中的数据包移动到 process_queue 中,然后在下一次内层循环中继续处理这些数据包。
__netif_receive_skb用于将数据送往协议栈,在此之后的调用过程就和跨机网络的IO又一致了:__netif_receive_skb => __netif_receive_skb_core => deliver_skb,然后再将数据送入ip_rcv中进行后续操作。
五、问题解答
-
127.0.0.1本机网络IO需要经过网卡吗
- 不需要经过网卡,即使网卡拔了也可以正常使用本机网络
-
数据包在内核中是什么走向,和外网发送相比流程上有什么差别
- 节约了驱动上的一些开销。发送数据不需要静茹RingBuffer的驱动队列,直接把skb传给接收协议栈。
- 其他组件,包括系统调用、协议栈、设备子系统都经过了,甚至驱动程序也运行了,所以还是有一定的开销的。
- 如果想要再本机网络IO上绕开协议栈的开销,可以动用eBPF,用eBPF的sockmap和sk redirect可以达到真正不走协议栈的目的。
-
访问本机服务时,使用127.0.0.1能比本机IP(例如192.168.x.x)快吗
- 本机IP和127.0.0.1没有差别,都是走的环回设备lo
- 这是因为内核在设置IP的时候,把所有的本机IP都初始化到了local路由表里,类型写死了是RTN_LOCAL。所以后面的路由项选择的时候发现类型是RTN_LOCAL就会选择lo设备。
参考资料:
《深入理解Linux网络》—— 张彦飞