引言
本文的目的为记录stable diffusion的风格迁移,采用diffusers example中的text_to_image和textual_inversion目录
2023.7.11

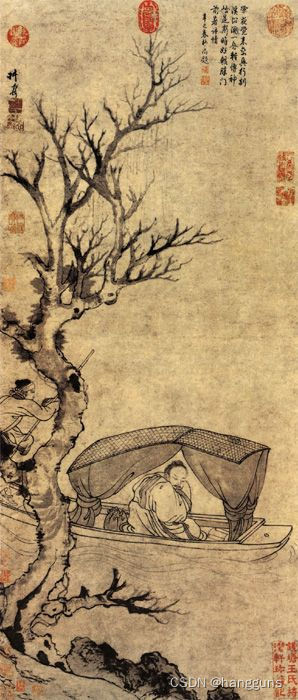
收集了6张水墨画风格的图片,采用textual_inversion进行训练,以"The street of Paris, in the style of "作为模板,第369轮的图片如下

第500轮的模型用于生成飞机,猫,狗


然而生成草莓,香蕉却无法生成,顶多是更改了背景

这让我怀疑模型并不能很好的学习到其中的风格
2023.7.12
在昨天注意到textual inversion只能迁移风格到一些模型已有的内容中,对于一些位置的物体无法进行风格迁移后,我将目光再次转向了LoRA,在参考了这篇文章之后,我开始着手训练,LoRA需要使用较多的图片,因此我将图片的数量增加到了20张,并且使用stable-diffusion-webui进行数据预处理,具体为将图片裁剪为512*512大小之后,使用danbooru提供图片的描述词,然后使用train_text_to_image_lora.py进行训练,我的设置如下,在之前的理解中,我认为random_flip和center_crop数据增强应该对图像生成是没有用的,这篇文章中也是这么说的,但是我又想到数据量这么小,虽然可能没有提升,但是也不会更差,于是就加上吧,同时我将train_batch_size从计算机最大可以使用的6改为4,玄学认为4的倍数训练模型更加好
export MODEL_NAME="/home/zxa/ps/pretrain_models/stable-diffusion-v1-5/"
export DATASET_NAME="/home/zxa/ps/open_data/material_tags_copy/"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora_my_version.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir $DATASET_NAME --caption_column="text" \
--random_flip --center_crop\
--dataloader_num_workers=0 \
--resolution=512 \
--gradient_accumulation_steps=1 \
--train_batch_size=4 \
--max_grad_norm=1 \
--checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-model-lora-v1.5-ink" \
--report_to="wandb" \
--enable_xformers_memory_efficient_attention \
--validation_prompt="strawberry" \
--num_validation_image=4 \
--validation_epochs=100 \
--max_train_steps=15000 \
然而,我训练了1500轮的图片,却出现了我不想要的文字信息,甚至还出现了过拟合情况,即我想要生成草莓,却生成的不是草莓,如下


这让我意识到是我训练的数据存在错误了,于是我开始采用手动裁剪的方式,使用windows自带的照片软件中的裁剪功能,选择正方形,选择没有文字的地方裁剪出来,效果如下




出现过拟合的情况,很有可能是因为danbooru给出的图片描述词与图片根本不符,因此我删掉了danbooru的描述词,全部自己手写生成,例如A yellow tiger with its mouth open, standing on a mountain,A man wearing a cap and coir raincoat with his mouth closed and holding a bowl,将图片和文字全部处理好之后,重新开始训练,训练效果如下


这是模型运行2000轮的效果


这是模型运行3000轮的效果,可见我们的猜想是正确的,模型在训练到过拟合后,也没有丢失文字信息,生成的都是和文字描述匹配的草莓的效果,但是3000轮已经过拟合了,图片开始失真了,因此2000轮已经是不错的选择了

![关于SpringBoot、Nginx 请求参数包含 [] 特殊符号 返回400状态](https://img-blog.csdnimg.cn/7efd894b6f054017a7d2c48b475f4d51.png)