目录
- 前言
- 一、3D 关键点可视化
- 二、使用步骤
- 1.300W-LP转为YOLO数据格式
- 2.修改数据入口
- 3.开始训练
- 总结
前言
300WLP数据集提供来丰富的人脸线索,包括2D或3D的关键点信息,Head Angle和3DMM的参数等.它可以用于2/3D的人脸关键点检测,以及头部姿态检测等任务.这里,我们尝试去实现端到段的3D人脸关键点检测.
一、3D 关键点可视化

如左图所示,其3D特征点其实是在相机平面上的二维投影,并非真正的含有深度信息的.
二、使用步骤
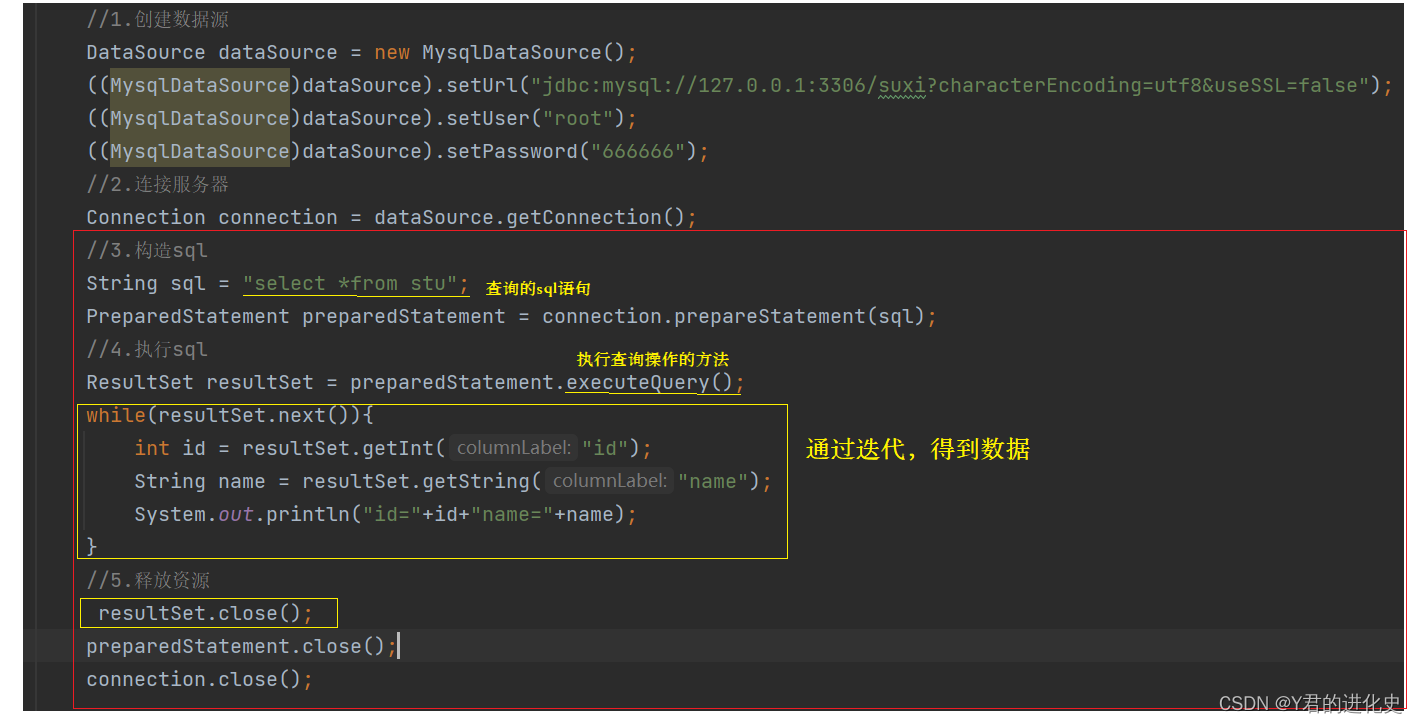
1.300W-LP转为YOLO数据格式
代码如下(示例):
import os, cv2
import hdf5storage
import numpy as np
import sys
import scipy.io as sio
def process_300WLP(root_folder, folder_name, image_name, label_name, target_size):
#modify by WQT, referring from PIPNet
image_path = os.path.join(root_folder, folder_name, image_name)
label_path = os.path.join(root_folder, 'landmarks', folder_name, label_name)
with open(label_path, 'r') as ff:
C = sio.loadmat(label_path)
anno = C['pts_3d']
# anno = ff.readlines()[3:-1]
# anno = [x.strip().split() for x in anno]
# # anno = [[int(float(x[0])), int(float(x[1]))] for x in anno]
# anno = [[float(x[0]), float(x[1])] for x in anno]
anno_x = [x[0] for x in anno]
anno_y = [x[1] for x in anno]
# anno_x = anno[0, :]
# anno_y = anno[-1, :]
bbox_xmin = min(anno_x)
bbox_ymin = min(anno_y)
bbox_xmax = max(anno_x)
bbox_ymax = max(anno_y)
bbox_width = bbox_xmax - bbox_xmin + 1
bbox_height = bbox_ymax - bbox_ymin + 1
image = cv2.imread(image_path)
image_height, image_width, _ = image.shape
bbox_xcenter = bbox_xmin + bbox_width/2
bbox_ycenter = bbox_ymin + bbox_height/2
padding = 2 # to enlarge the face box
isCrowdAndXYWH = [0, bbox_xcenter/image_width, bbox_ycenter/image_height, (bbox_width+padding)/image_width, (bbox_height+padding)/image_height]
anno = [[x/image_width, y/image_height, 2] for x,y in anno]
return image, isCrowdAndXYWH, anno
def gen_meanface(root_folder, data_name):
with open(os.path.join(root_folder, data_name, 'train2yolo.txt'), 'r') as f:
annos = f.readlines()
annos = [x.strip().split()[1:] for x in annos]
annos = [[float(x) for x in anno] for anno in annos]
annos = np.array(annos)
meanface = np.mean(annos, axis=0)
meanface = meanface.tolist()
meanface = [str(x) for x in meanface]
with open(os.path.join(root_folder, data_name, 'meanface.txt'), 'w') as f:
f.write(' '.join(meanface))
def convert_wflw(root_folder, data_name):
with open(os.path.join('../data/WFLW/test.txt'), 'r') as f:
annos = f.readlines()
annos = [x.strip().split() for x in annos]
annos_new = []
for anno in annos:
annos_new.append([])
# name
annos_new[-1].append(anno[0])
anno = anno[1:]
# jaw
for i in range(17):
annos_new[-1].append(anno[i*2*2])
annos_new[-1].append(anno[i*2*2+1])
# left eyebrow
annos_new[-1].append(anno[33*2])
annos_new[-1].append(anno[33*2+1])
annos_new[-1].append(anno[34*2])
annos_new[-1].append(str((float(anno[34*2+1])+float(anno[41*2+1]))/2))
annos_new[-1].append(anno[35*2])
annos_new[-1].append(str((float(anno[35*2+1])+float(anno[40*2+1]))/2))
annos_new[-1].append(anno[36*2])
annos_new[-1].append(str((float(anno[36*2+1])+float(anno[39*2+1]))/2))
annos_new[-1].append(anno[37*2])
annos_new[-1].append(str((float(anno[37*2+1])+float(anno[38*2+1]))/2))
# right eyebrow
annos_new[-1].append(anno[42*2])
annos_new[-1].append(str((float(anno[42*2+1])+float(anno[50*2+1]))/2))
annos_new[-1].append(anno[43*2])
annos_new[-1].append(str((float(anno[43*2+1])+float(anno[49*2+1]))/2))
annos_new[-1].append(anno[44*2])
annos_new[-1].append(str((float(anno[44*2+1])+float(anno[48*2+1]))/2))
annos_new[-1].append(anno[45*2])
annos_new[-1].append(str((float(anno[45*2+1])+float(anno[47*2+1]))/2))
annos_new[-1].append(anno[46*2])
annos_new[-1].append(anno[46*2+1])
# nose
for i in range(51, 60):
annos_new[-1].append(anno[i*2])
annos_new[-1].append(anno[i*2+1])
# left eye
annos_new[-1].append(anno[60*2])
annos_new[-1].append(anno[60*2+1])
annos_new[-1].append(str(0.666*float(anno[61*2])+0.333*float(anno[62*2])))
annos_new[-1].append(str(0.666*float(anno[61*2+1])+0.333*float(anno[62*2+1])))
annos_new[-1].append(str(0.666*float(anno[63*2])+0.333*float(anno[62*2])))
annos_new[-1].append(str(0.666*float(anno[63*2+1])+0.333*float(anno[62*2+1])))
annos_new[-1].append(anno[64*2])
annos_new[-1].append(anno[64*2+1])
annos_new[-1].append(str(0.666*float(anno[65*2])+0.333*float(anno[66*2])))
annos_new[-1].append(str(0.666*float(anno[65*2+1])+0.333*float(anno[66*2+1])))
annos_new[-1].append(str(0.666*float(anno[67*2])+0.333*float(anno[66*2])))
annos_new[-1].append(str(0.666*float(anno[67*2+1])+0.333*float(anno[66*2+1])))
# right eye
annos_new[-1].append(anno[68*2])
annos_new[-1].append(anno[68*2+1])
annos_new[-1].append(str(0.666*float(anno[69*2])+0.333*float(anno[70*2])))
annos_new[-1].append(str(0.666*float(anno[69*2+1])+0.333*float(anno[70*2+1])))
annos_new[-1].append(str(0.666*float(anno[71*2])+0.333*float(anno[70*2])))
annos_new[-1].append(str(0.666*float(anno[71*2+1])+0.333*float(anno[70*2+1])))
annos_new[-1].append(anno[72*2])
annos_new[-1].append(anno[72*2+1])
annos_new[-1].append(str(0.666*float(anno[73*2])+0.333*float(anno[74*2])))
annos_new[-1].append(str(0.666*float(anno[73*2+1])+0.333*float(anno[74*2+1])))
annos_new[-1].append(str(0.666*float(anno[75*2])+0.333*float(anno[74*2])))
annos_new[-1].append(str(0.666*float(anno[75*2+1])+0.333*float(anno[74*2+1])))
# mouth
for i in range(76, 96):
annos_new[-1].append(anno[i*2])
annos_new[-1].append(anno[i*2+1])
with open(os.path.join(root_folder, data_name, 'test.txt'), 'w') as f:
for anno in annos_new:
f.write(' '.join(anno)+'\n')
def gen_data(root_folder, data_name, target_size):
if not os.path.exists(os.path.join(root_folder, data_name, 'images_train2yolo')):
os.mkdir(os.path.join(root_folder, data_name, 'images_train2yolo'))
if not os.path.exists(os.path.join(root_folder, data_name, 'images_test2yolo')):
os.mkdir(os.path.join(root_folder, data_name, 'images_test2yolo'))
#这是为了把cropped的人脸存入新文件夹,由于我们不需要此步,即可省掉也行
################################################################################################################
if data_name == '300W_LP':
# folders_train = ['AFW', 'HELEN', 'IBUG', 'LFPW']
folders_train = ['HELEN', 'LFPW']
annos_train = {}
for folder_train in folders_train:
all_files = sorted(os.listdir(os.path.join(root_folder, data_name, folder_train)))
image_files = [x for x in all_files if '.mat' not in x]
# label_files = [x for x in all_files if '.mat' in x]
label_files = [x.split('.')[0]+'_pts.mat' for x in all_files if '.mat' in x]
assert len(image_files) == len(label_files)
for image_name, label_name in zip(image_files, label_files):
image_crop, isCrowdAndXYWH, anno = process_300WLP(os.path.join(root_folder, '300W_LP'), folder_train, image_name, label_name, target_size)
image_crop_name = image_name
cv2.imwrite(os.path.join(root_folder, data_name, 'images', 'train', image_crop_name), image_crop)
annos_train[image_crop_name] = isCrowdAndXYWH, anno
with open(os.path.join(root_folder, data_name, 'train2yolo.txt'), 'w') as f:
for image_crop_name, anno in annos_train.items():
f.write('./images/train/' + image_crop_name) #./images/val2017/000000345356.jpg
# f.write(image_crop_name+' ')
# for x,y in anno:
# f.write(str(x)+' '+str(y)+' ')
f.write('\n')
base_txt = os.path.basename(image_crop_name.split('.')[0]) + ".txt"
save_txt_path = os.path.join(root_folder, data_name,'labels', 'train', base_txt)
with open(save_txt_path, 'w') as f_txt:
for xywh in anno[0]:
f_txt.write(str(xywh)+' ')
for x, y, z in anno[1]:
f_txt.write(str(x)+' '+str(y)+' '+str(z)+' ')
f_txt.write('\n')
folders_test = ['AFW', 'IBUG']
annos_test = {}
for folder_test in folders_test:
all_files = sorted(os.listdir(os.path.join(root_folder, data_name, folder_test)))
image_files = [x for x in all_files if '.mat' not in x]
# label_files = [x for x in all_files if '.mat' in x]
label_files = [x.split('.')[0]+'_pts.mat' for x in all_files if '.mat' in x]
assert len(image_files) == len(label_files)
for image_name, label_name in zip(image_files, label_files):
image_crop, isCrowdAndXYWH, anno = process_300WLP(os.path.join(root_folder, '300W_LP'), folder_test, image_name, label_name, target_size)
image_crop_name = image_name
cv2.imwrite(os.path.join(root_folder, data_name, 'images', 'test', image_crop_name), image_crop)
annos_test[image_crop_name] = isCrowdAndXYWH, anno
with open(os.path.join(root_folder, data_name, 'test2yolo.txt'), 'w') as f:
for image_crop_name, anno in annos_test.items():
f.write('./images/test/' + image_crop_name) #./images/val2017/000000345356.jpg
# f.write(image_crop_name+' ')
# for x,y in anno:
# f.write(str(x)+' '+str(y)+' ')
f.write('\n')
base_txt = os.path.basename(image_crop_name.split('.')[0]) + ".txt"
save_txt_path = os.path.join(root_folder, data_name,'labels', 'test', base_txt)
with open(save_txt_path, 'w') as f_txt:
for xywh in anno[0]:
f_txt.write(str(xywh)+' ')
for x, y, z in anno[1]:
f_txt.write(str(x)+' '+str(y)+' '+str(z)+' ')
f_txt.write('\n')
gen_meanface(root_folder, data_name)
elif data_name == 'LaPa':
pass
# TODO
else:
print('Wrong data!')
if __name__ == '__main__':
if len(sys.argv) < 2:
print('please input the data name.')
print('1. 300W_LP')
print('0. data_300W')
print('2. COFW')
print('3. WFLW')
print('4. AFLW')
print('5. LaPa')
exit(0)
else:
data_name = sys.argv[1]
gen_data('../', data_name, 256)
2.修改数据入口
修改ultrlytics/datasets/coco8-pose.yaml中的path.
参考如下(示例):
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO8-pose dataset (first 8 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco8-pose.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8-pose ← downloads here (1 MB)
path:
/home/wqt/Datasets/300W-LP/300W_LP
# ../datasets/coco8-pose # dataset root dir
train:
train2yolo.txt
# data/video_68out/026_noglasses_mix_tired1/train2yolo.txt
# data/video_68out/WIN_20230417_15_51_51_Pro/train2yolo.txt
# images/train # train images (relative to 'path') 4 images
val:
test2yolo.txt
# images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Keypoints
kpt_shape: [68, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
flip_idx: [16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 27, 28, 29, 30, 35, 34, 33, 32, 31, 45, 44, 43, 42, 47, 46, 39, 38, 37, 36, 41, 40, 54, 53, 52, 51, 50, 49, 48, 59, 58, 57, 56, 55, 64, 63, 62, 61, 60, 67, 66, 65]
# Classes
names:
# 0: person #ori
0: face #wqt
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco8-pose.zip
3.开始训练
超参数设置
yolo/engine/trainer: task=pose, mode=train, model=/home/wqt/NewProjects/ultralyticsWholeBody/runs/pose/train10/weights/best.pt, data=coco8-pose.yaml, epochs=100, patience=50, batch=16, imgsz=640, save=True, save_period=20, cache=False, device=, workers=8, project=None, name=/home/wqt/NewProjects/ultralyticsFaceMark/runs/pose/train, exist_ok=False, pretrained=False, optimizer=SGD, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=0, resume=False, amp=True, fraction=1.0, profile=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, show=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, vid_stride=1, line_width=None, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, boxes=True, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0, cfg=None, v5loader=False, tracker=botsort.yaml, save_dir=/home/wqt/NewProjects/ultralyticsFaceMark/runs/pose/train2
Overriding model.yaml kpt_shape=[133, 3] with kpt_shape=[68, 3]
网络结构,参考yolo8
from n params module arguments
0 -1 1 928 ultralytics.nn.modules.conv.Conv [3, 32, 3, 2]
1 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
2 -1 1 29056 ultralytics.nn.modules.block.C2f [64, 64, 1, True]
3 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
4 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
5 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
6 -1 2 788480 ultralytics.nn.modules.block.C2f [256, 256, 2, True]
7 -1 1 1180672 ultralytics.nn.modules.conv.Conv [256, 512, 3, 2]
8 -1 1 1838080 ultralytics.nn.modules.block.C2f [512, 512, 1, True]
9 -1 1 656896 ultralytics.nn.modules.block.SPPF [512, 512, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 591360 ultralytics.nn.modules.block.C2f [768, 256, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
16 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 493056 ultralytics.nn.modules.block.C2f [384, 256, 1]
19 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 1 1969152 ultralytics.nn.modules.block.C2f [768, 512, 1]
22 [15, 18, 21] 1 5013031 ultralytics.nn.modules.head.Pose [1, [68, 3], [128, 256, 512]]
YOLOv8s-pose summary: 250 layers, 14032583 parameters, 14032567 gradients
训练集与测试集
Transferred 361/397 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 63 weight(decay=0.0), 73 weight(decay=0.0005), 72 bias
train: Scanning /home/wqt/Datasets/300W-LP/300W_LP/labels/train... 54232 images, 0 backgrounds, 0 corrupt: 100%|██████████| 54232/54232 [00:45<00:00, 1190.60it/s]
train: New cache created: /home/wqt/Datasets/300W-LP/300W_LP/labels/train.cache
val: Scanning /home/wqt/Datasets/300W-LP/300W_LP/labels/test... 6993 images, 0 backgrounds, 0 corrupt: 100%|██████████| 6993/6993 [00:06<00:00, 1127.92it/s]
val: New cache created: /home/wqt/Datasets/300W-LP/300W_LP/labels/test.cache
Plotting labels to /home/wqt/NewProjects/ultralyticsFaceMark/runs/pose/train2/labels.jpg...
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/NewProjects/ultralyticsFaceMark/runs/pose/train2
Starting training for 100 epochs...
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
1/100 4.58G 0.9736 7 0.6731 0.9241 1.464 34 640: 29%|██▉ | 992/3390 [04:26<10:48, 3.70it/s]
训练过程:

总结
期待好的结果!