开头言
- 学东西前总是爱问,这个学了有什么用,会用就行了么。能够回答你这个问题的人,都是学过的(只有学过才有资格告诉你有没有用),然而知识往往就是这样,学的人越多越没有用,我可以做的是学会后,在这个基础上创新,这个创新有没有用,也要等你创完了才知道,所以学习本身是有巨大的风险,要仔细的评估学习的价值,以及自己创新的能力,不要轻易付出时间白忙一场。
常见问题
-
1.Pytorch每一步梯度更新都不会清除梯度,这在tensorflow中没有,这种特性可以让我们用很小的显存实现较大batchsize的训练只要把积累的梯度取均值就可以在反向传播中参数:https://www.zhihu.com/question/303070254
- 但是batchsize太小对于BN层就没有效果了
-
2.为什么预测的时候要eval():https://zhuanlan.zhihu.com/p/356500543
-
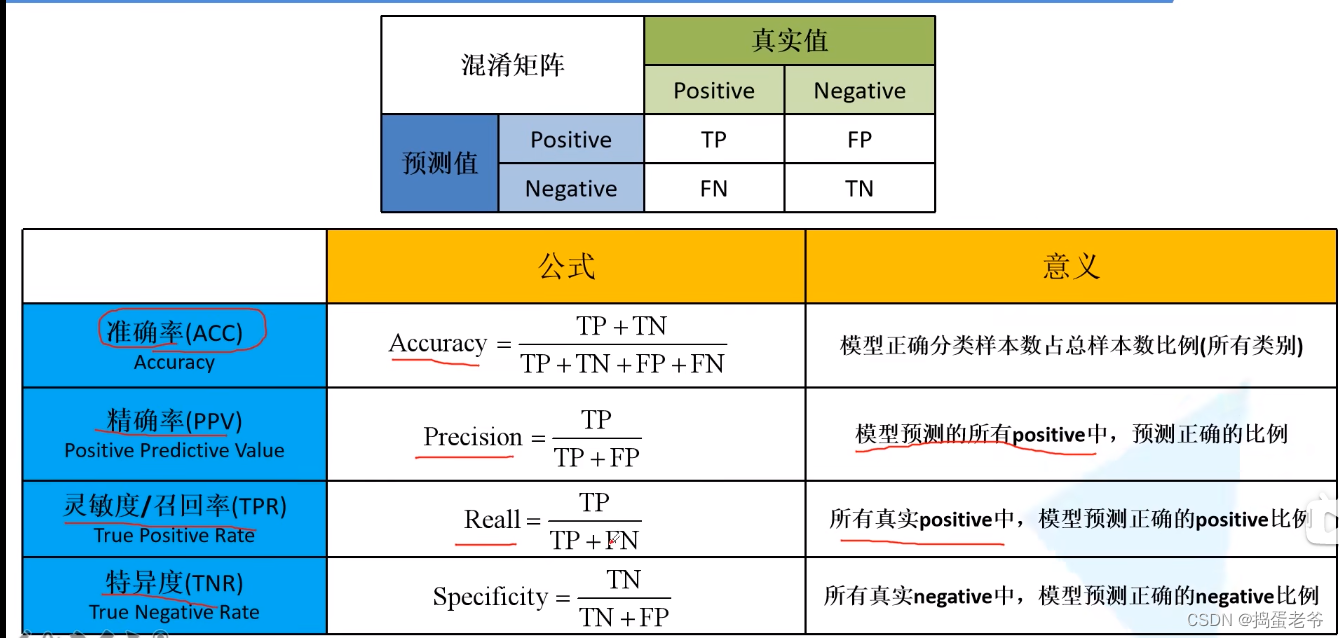
3.混淆矩阵
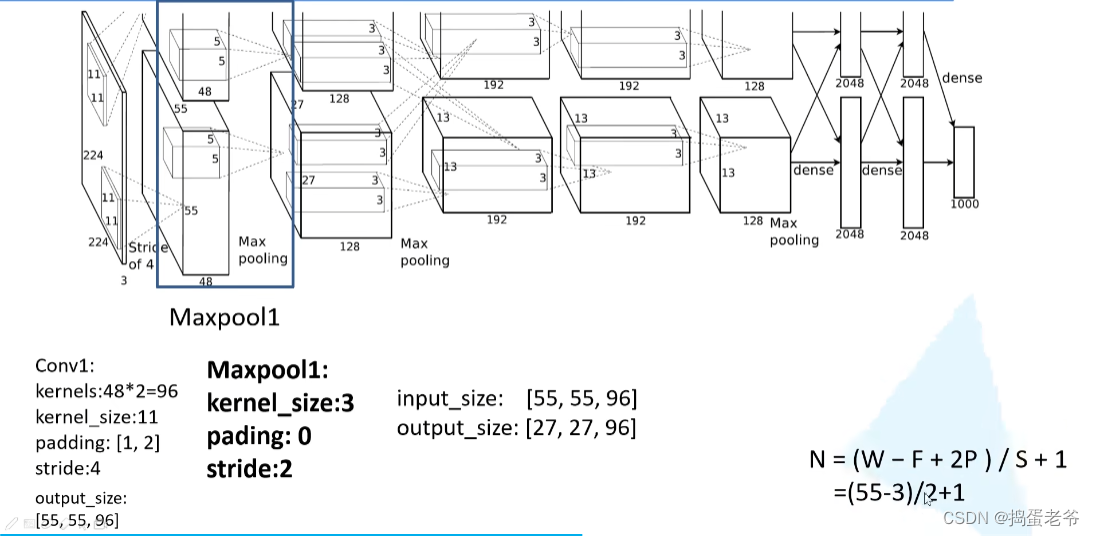
AlexNet进入卷积神经网络爆发时代
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self,num_classes=1000,init_weights=False):
super(AlexNet, self).__init__()
self.features=nn.Sequential(
nn.Conv2d(3,48,kernel_size=11,stride=4,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,padding=2),
nn.Conv2d(48,128,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,padding=2),
nn.Conv2d(128, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, padding=2)
)
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier=nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*6*6,2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self,x):
x=self.features(x)
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
if __name__ == '__main__':
a=torch.rand(32,3,224,224)
net=AlexNet(10,False)
b=net(a)
pass
VGG
- 提出堆叠33的卷积核代替55(2个) 、7*7(3个)减少计算的同时获得相同的视野
- 感受野计算公式理解
- 如果上一层的感受野是1,那么下一层的感受野就是核心大小
- 如果上一层的感受野大于1,那么1的部分是核心大小,其他部分是步距大小
- 结构

- 感受野计算公式理解
GoogleNet
- 首次出现拼接结果的并行结构(之前的都是串行)

- inception结构
- 输入的宽高相同在C出拼接
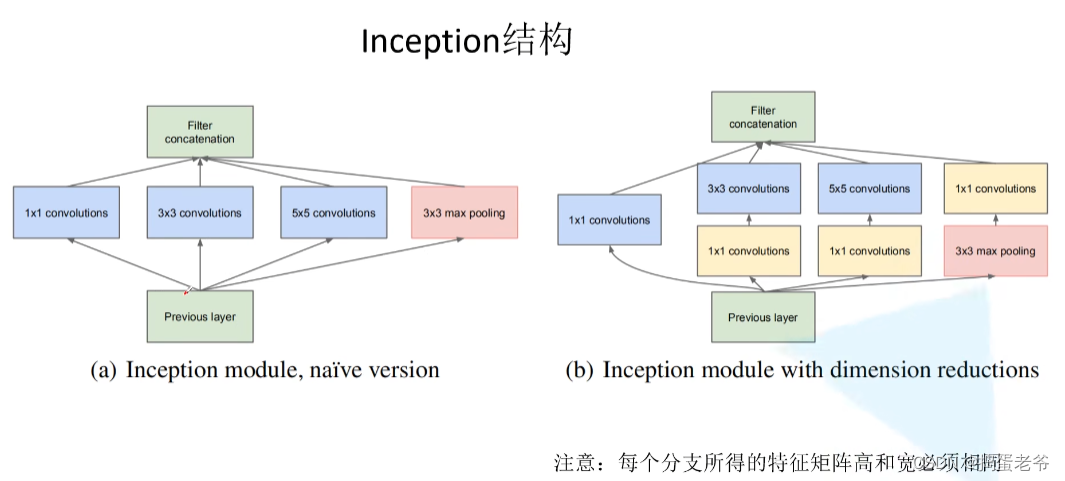
- 输入的宽高相同在C出拼接
- 1*1的卷积核降维
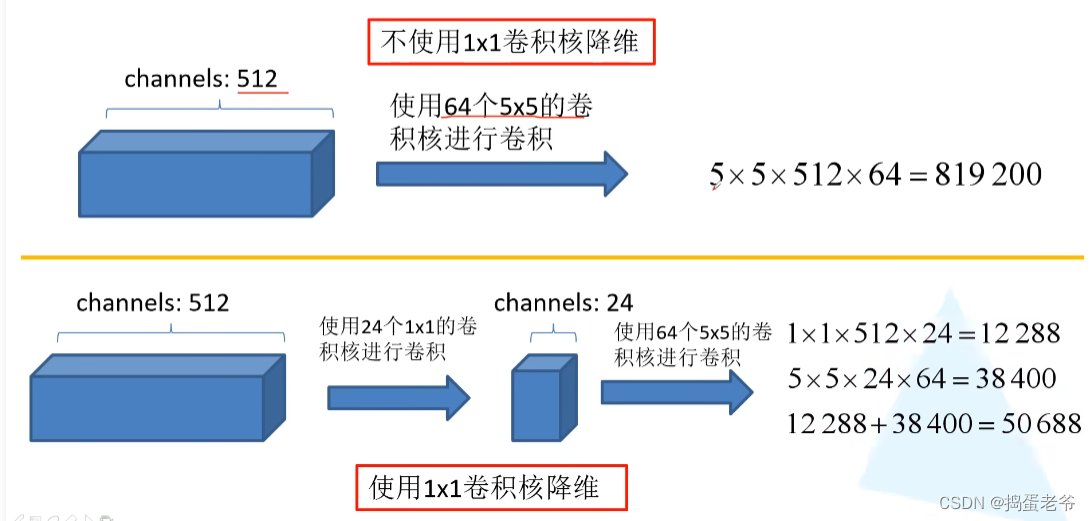
- 网络详解
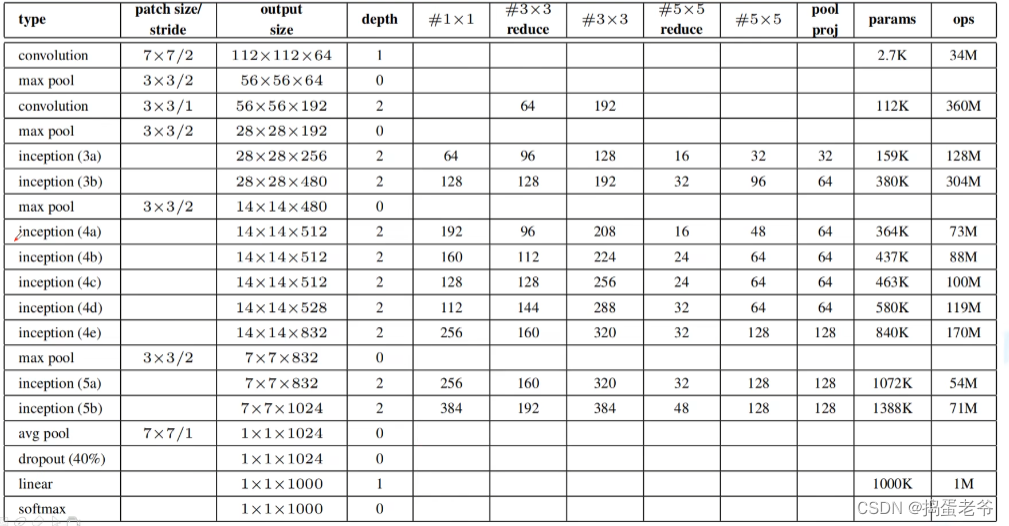
ResNet
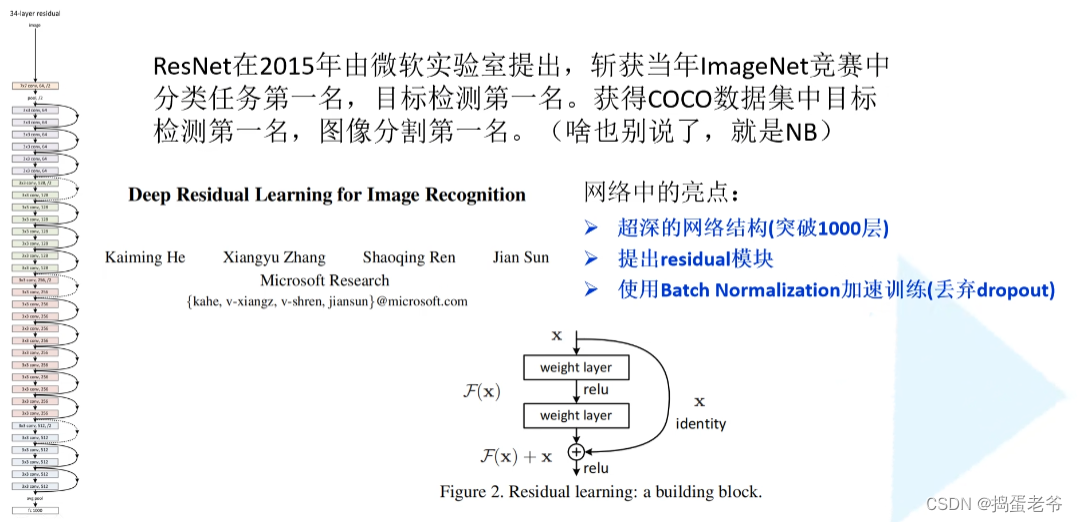
- 创新解决梯度消失 and 爆炸
- 退化问题(残差)
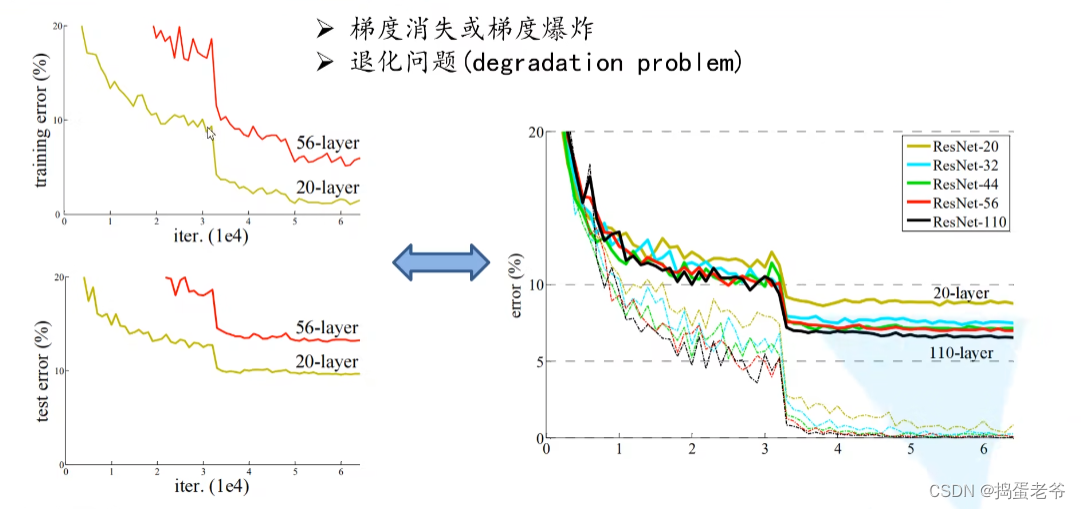
- 残差结构要求chw都一样,值相加,从而爆炸梯度大于1
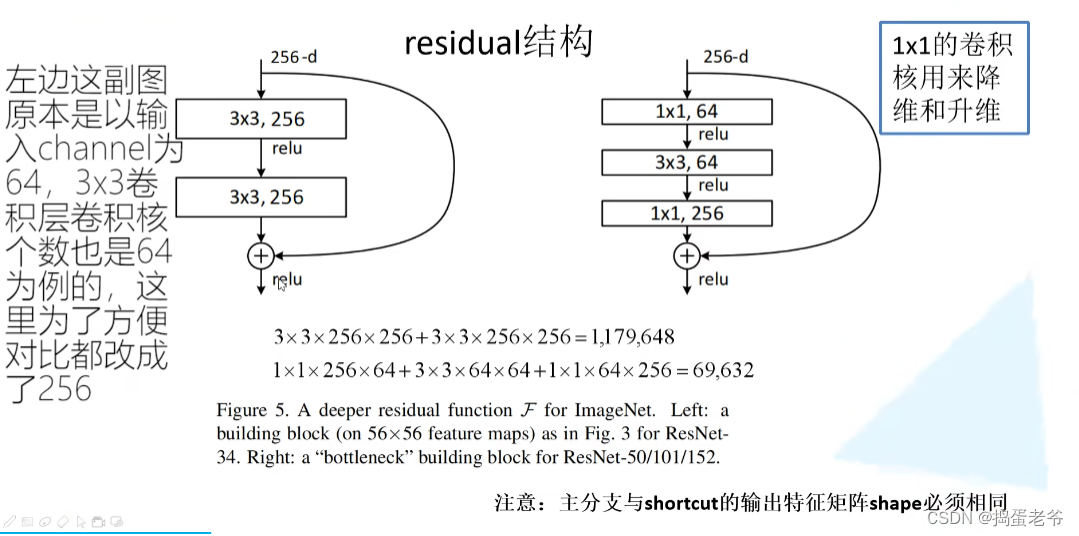
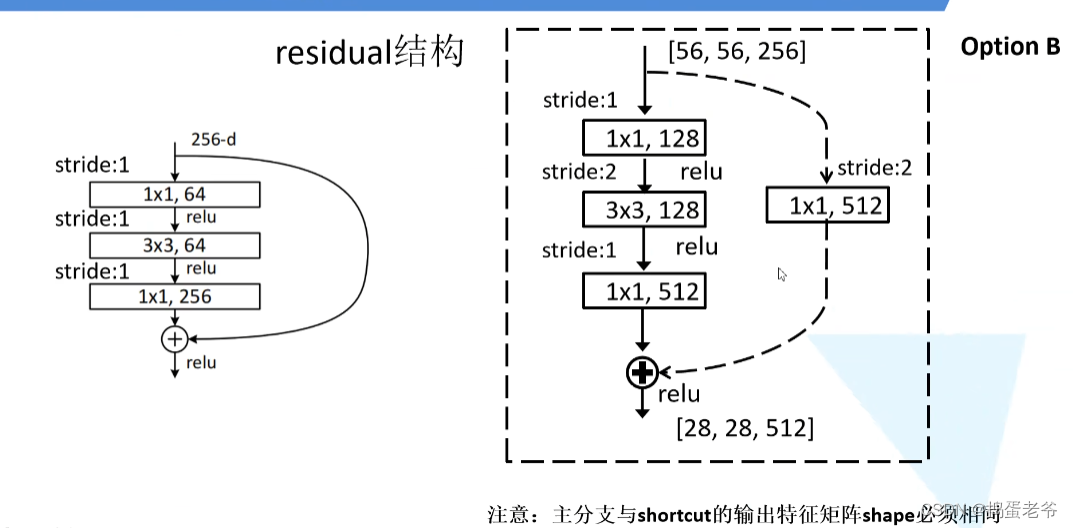
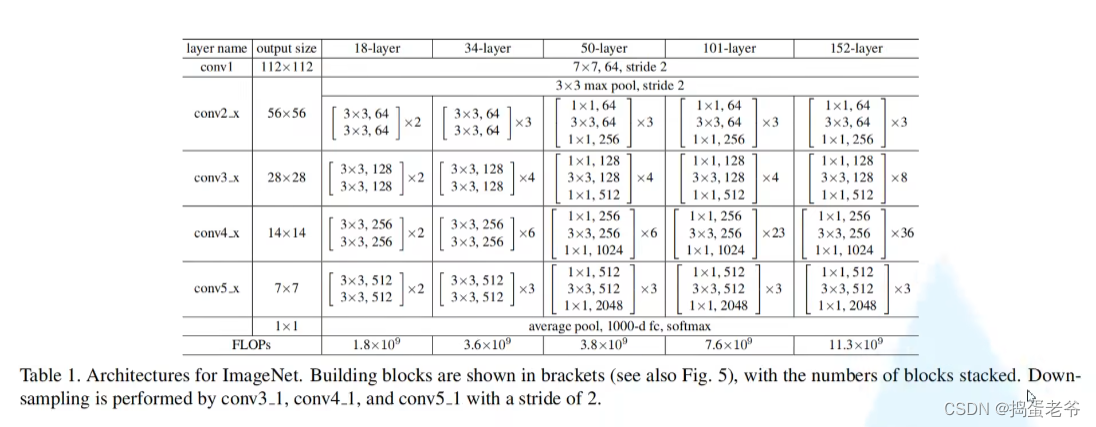
- BN层,两个参数调整的分别是方差和均值,不调整就是均值为0方差为1
-
https://blog.csdn.net/qq_37541097/article/details/104434557

-
(1)训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
-
(2)batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
-
(3)建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,即使使用了偏置bias求出的结果也是一样的
-
- 迁移学习

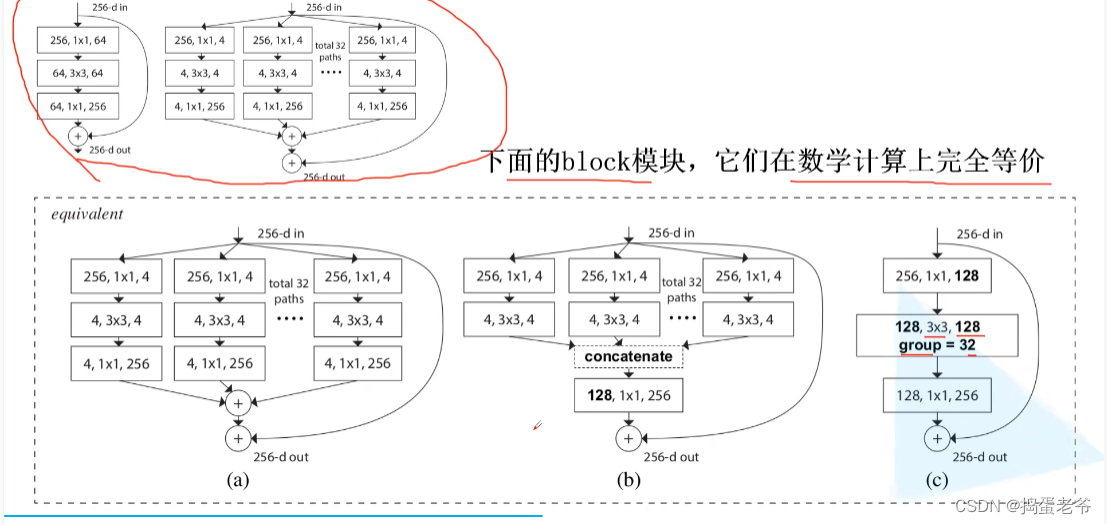
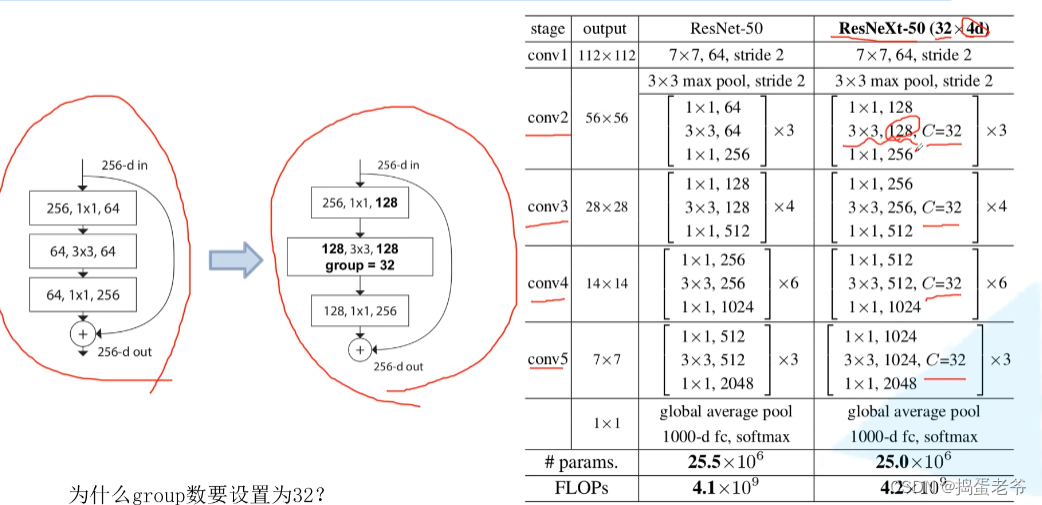
ResNeXt
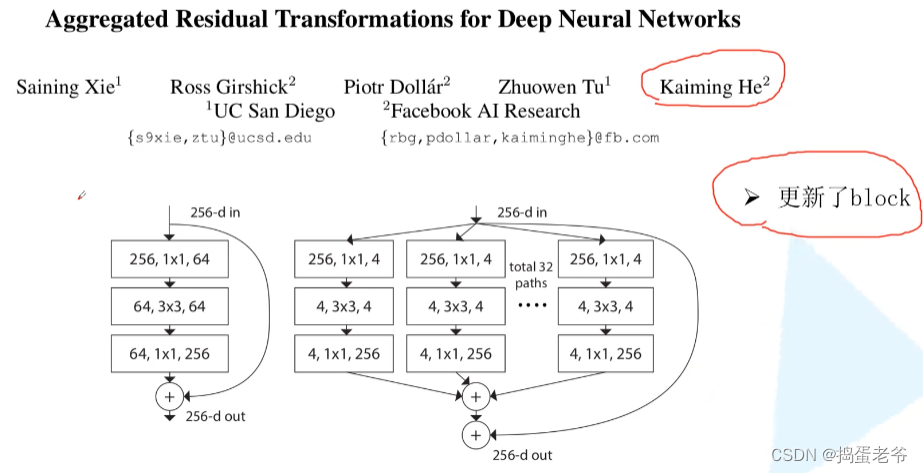
- 组卷积
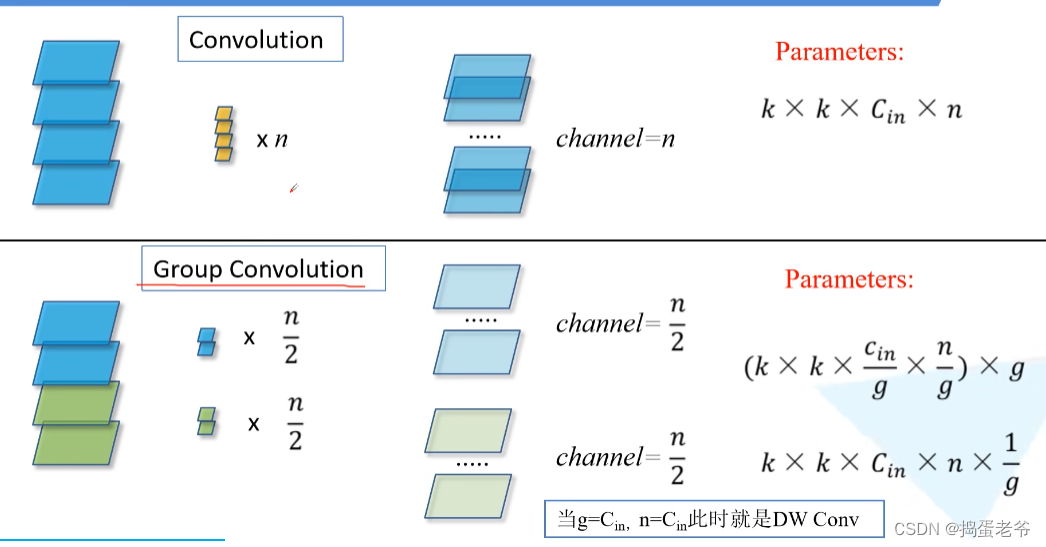
- 等价替换
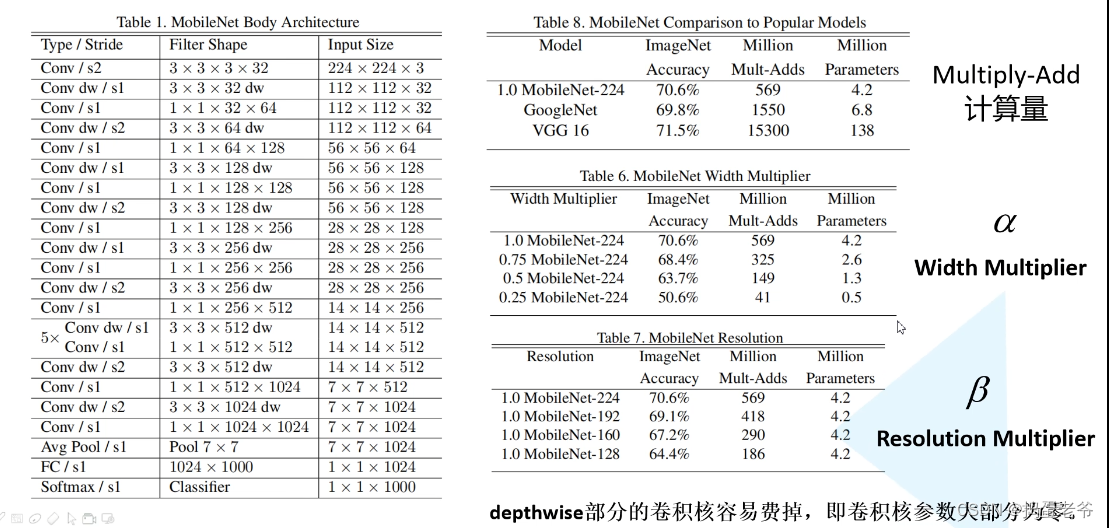
MobileNetV1
- DW卷积
- 减少参数
- 缺点:训练完后很多参数失效(为0),在V2中改进

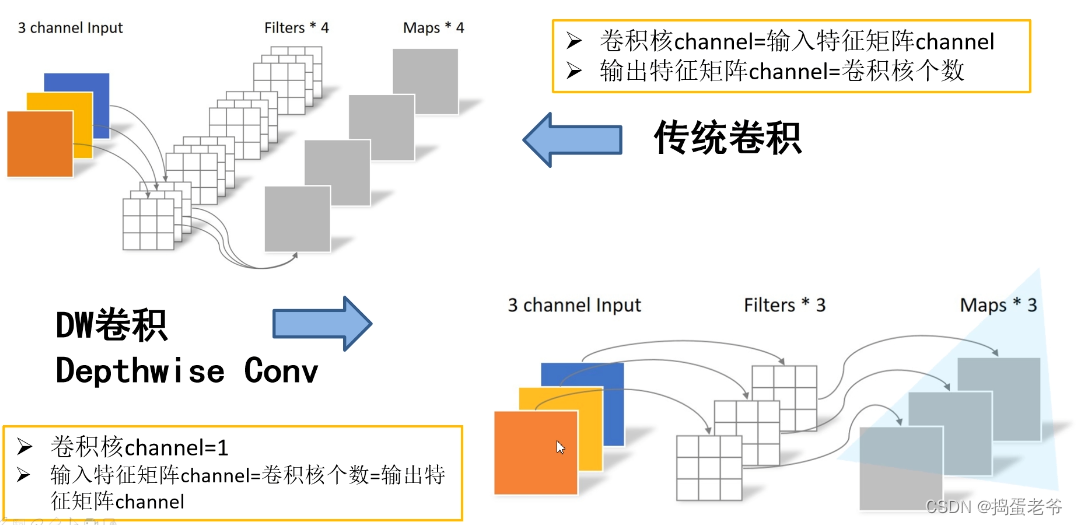
- PW卷积
- 注意计算量和参数量不一样
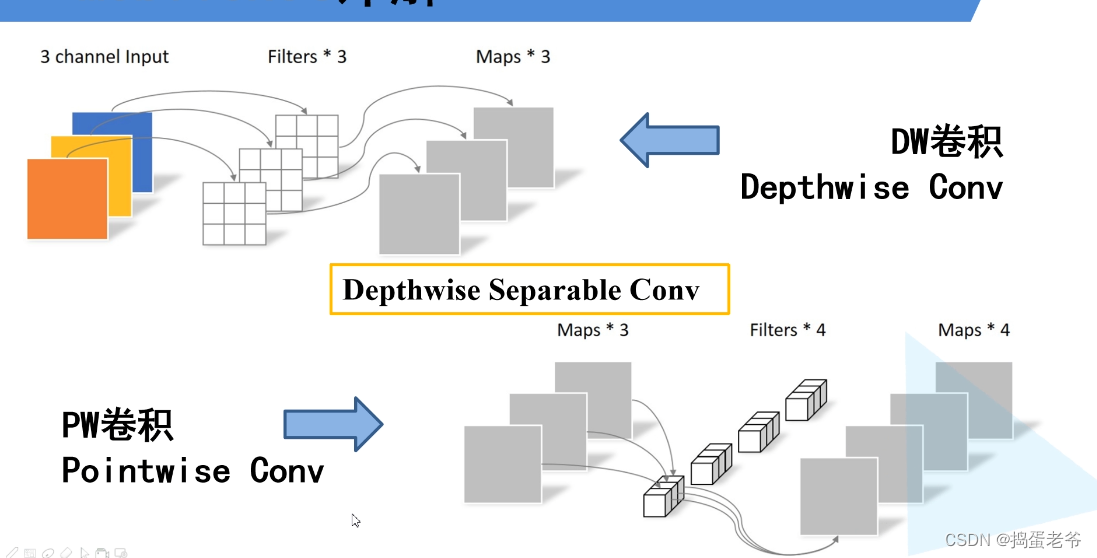
- 注意计算量和参数量不一样
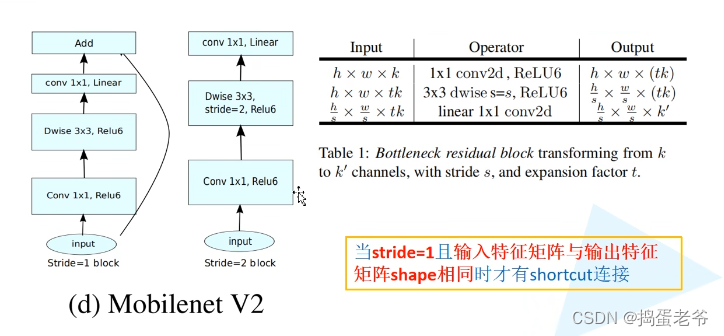
MobileNetV2

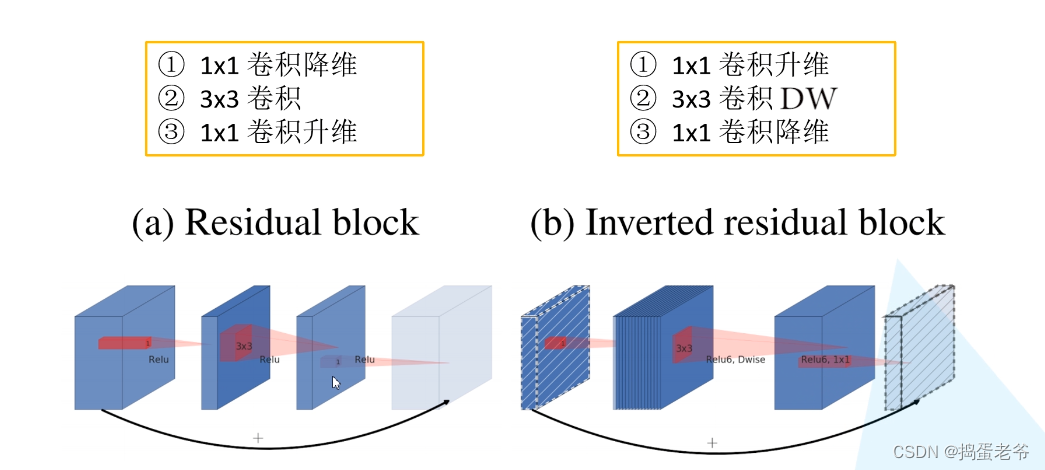
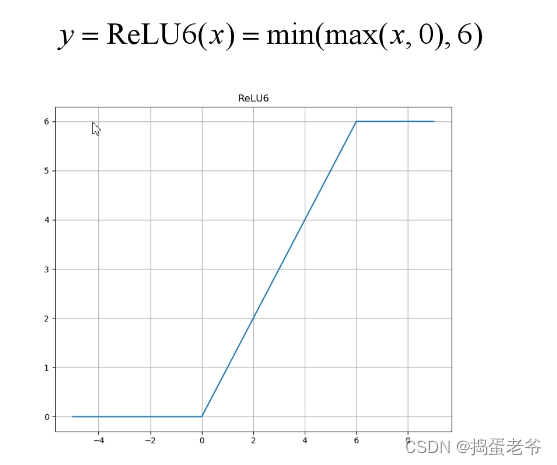
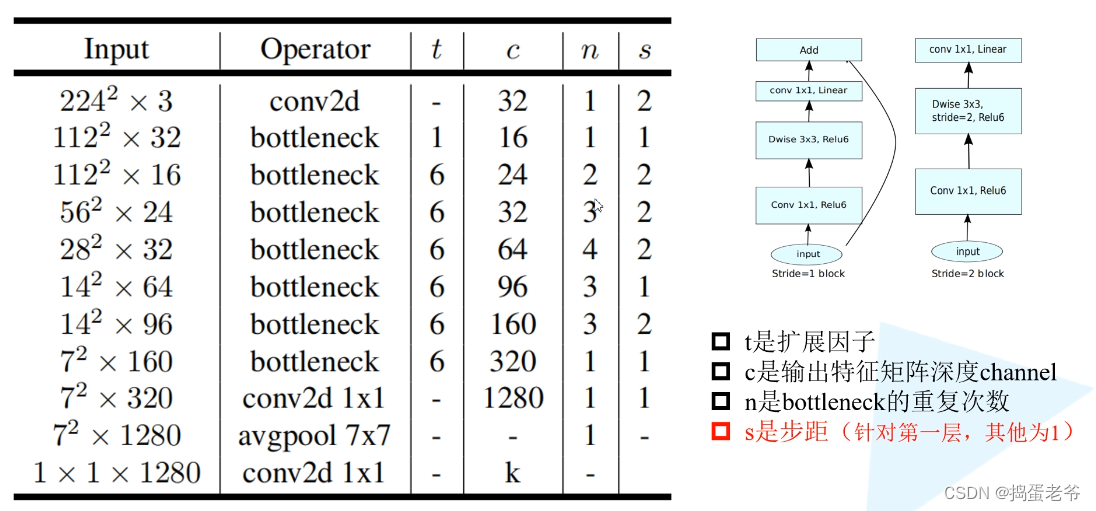
- 搭建网络倒残差结构
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel#1保证大小相等,保证通道相等
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
MobileNetv3
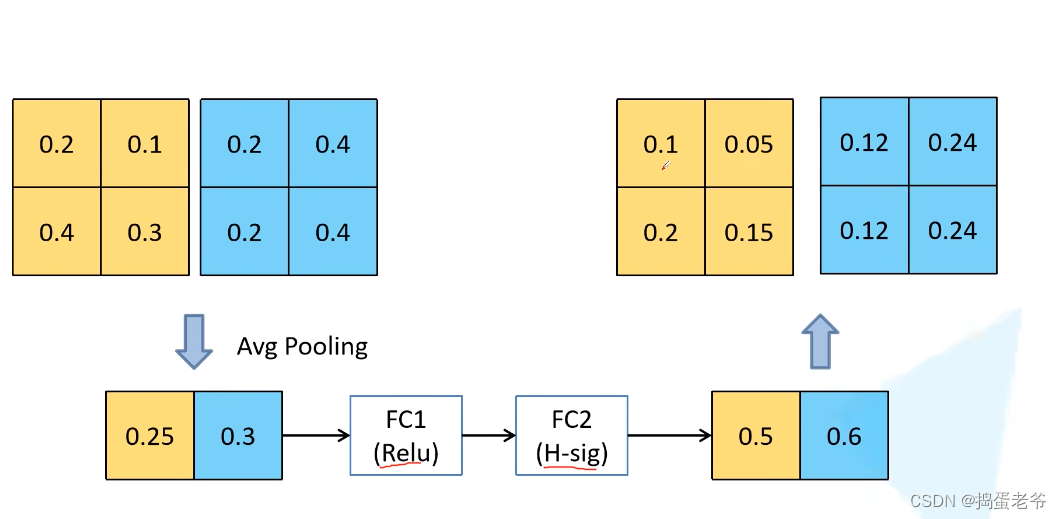
- 通道注意力
- QKV原理:https://www.bilibili.com/video/BV1nL4y1j7hA/?spm_id_from=333.337.search-card.all.click&vd_source=ce61818c8667e3f2de36a179a3c6e3af
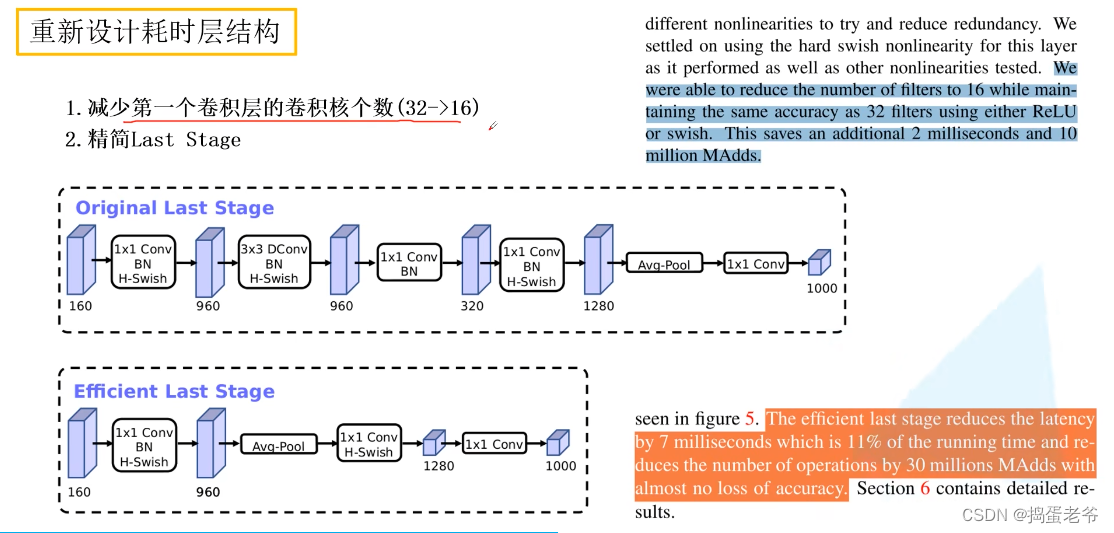
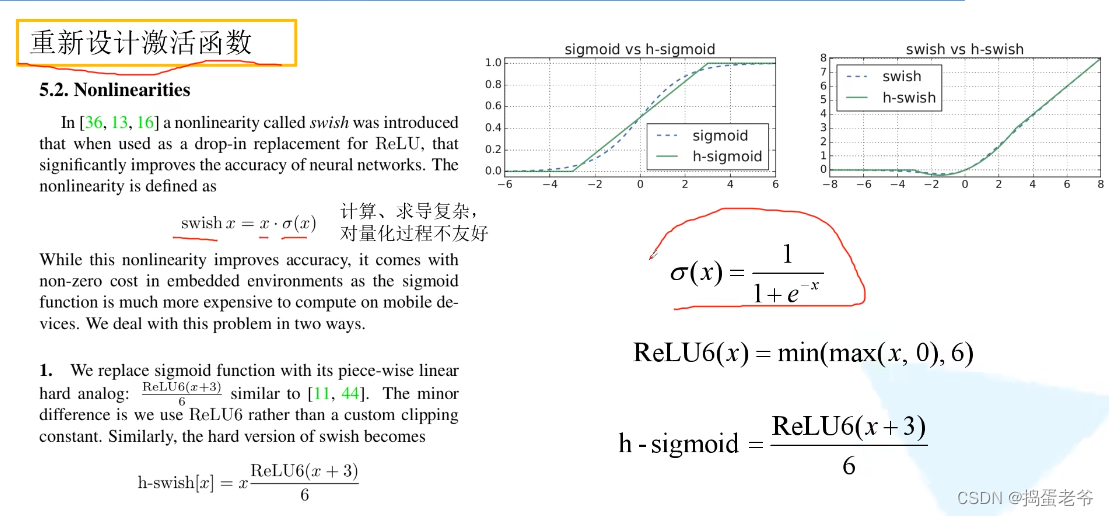
- QKV原理:https://www.bilibili.com/video/BV1nL4y1j7hA/?spm_id_from=333.337.search-card.all.click&vd_source=ce61818c8667e3f2de36a179a3c6e3af
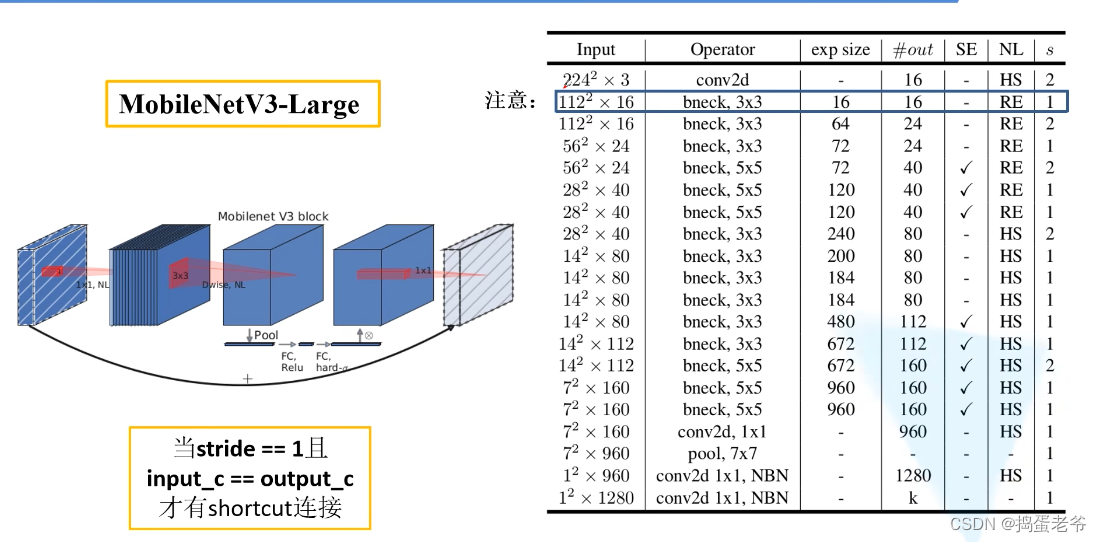
- 结构
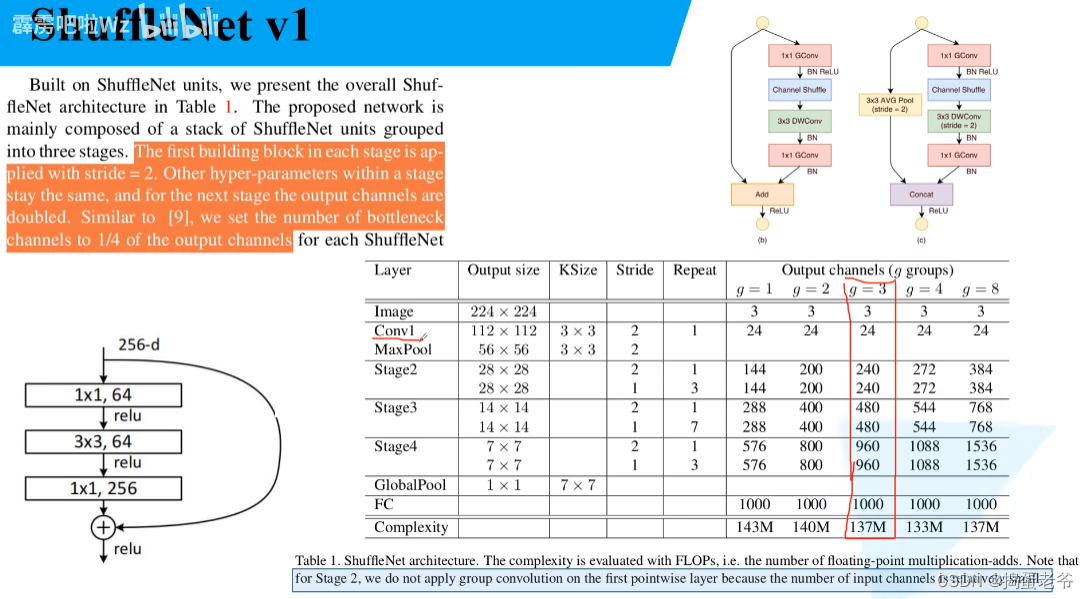
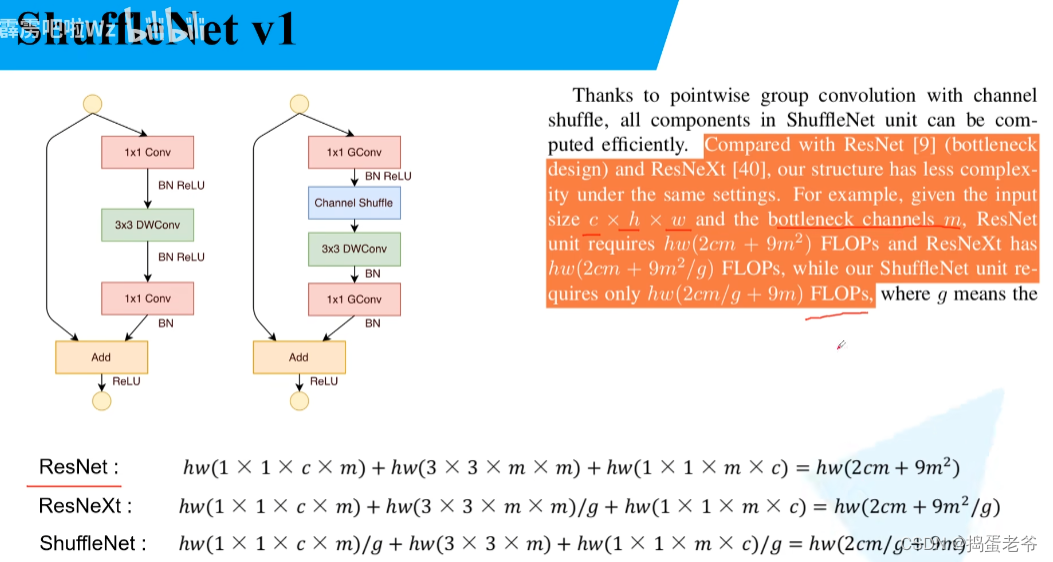
ShuffleNet v1
- 解决组卷积每组信息隔离不能互通的问题
- 将pw卷积改成group卷积减少计算量
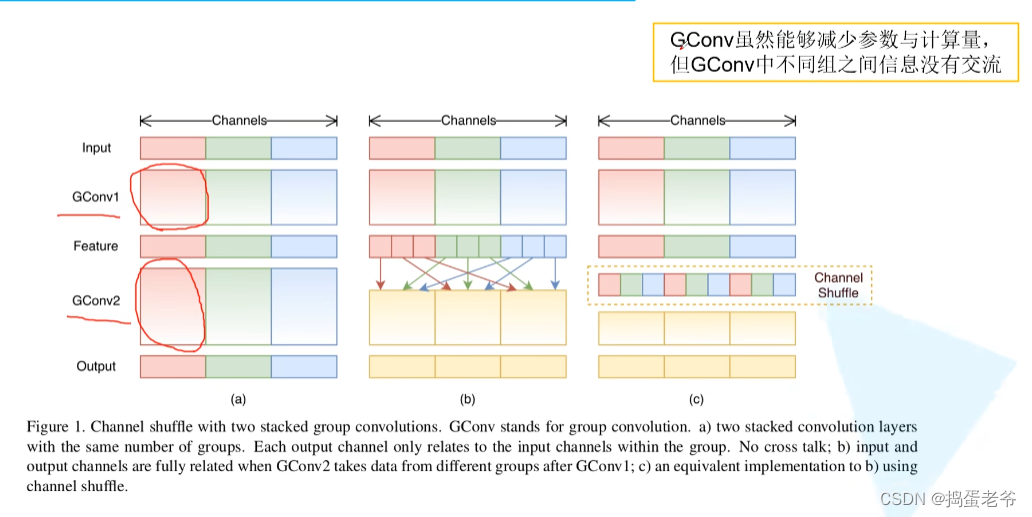

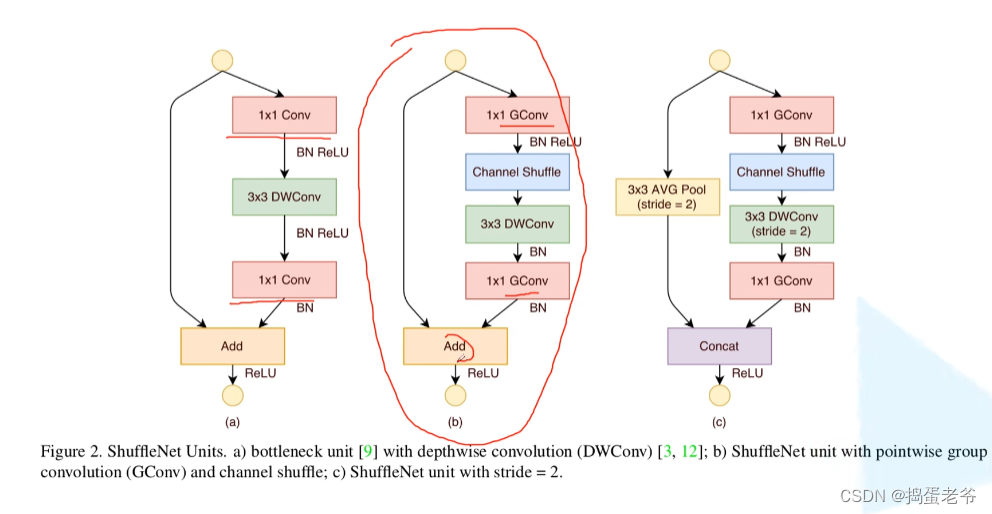
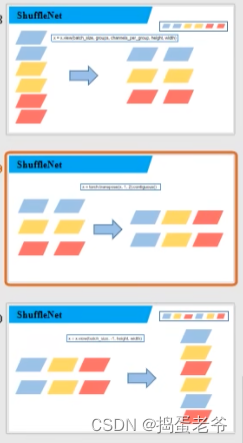
- shuffle的过程
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
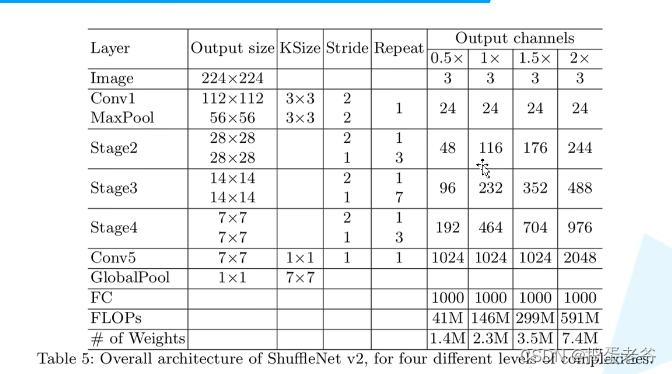
ShuffleNet v2
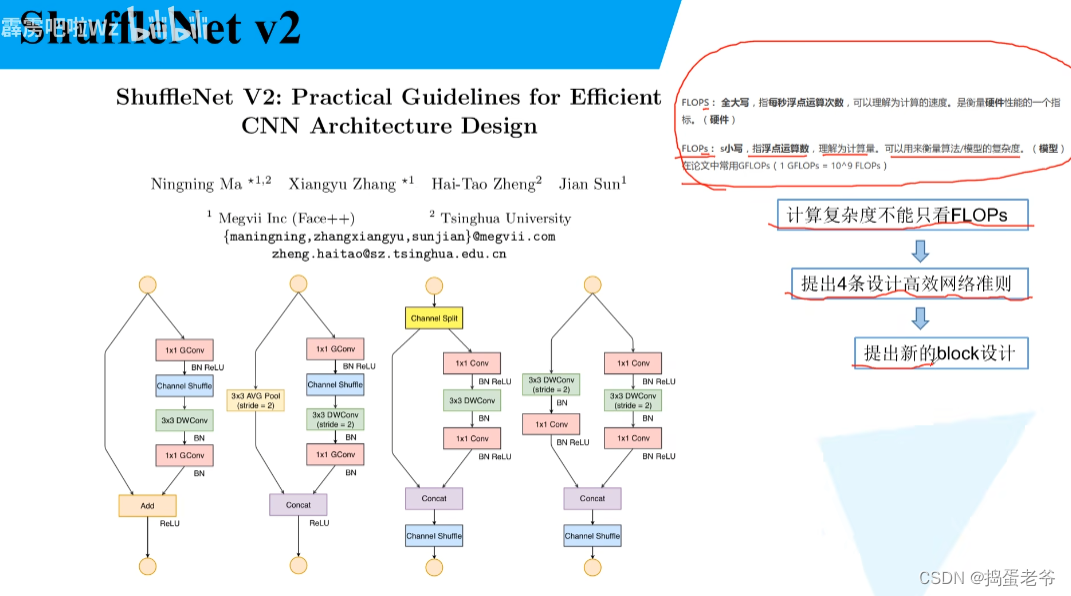

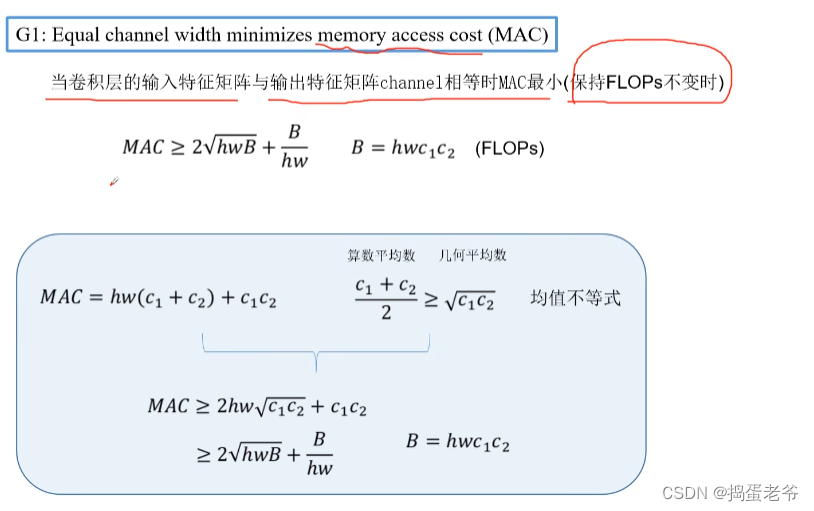
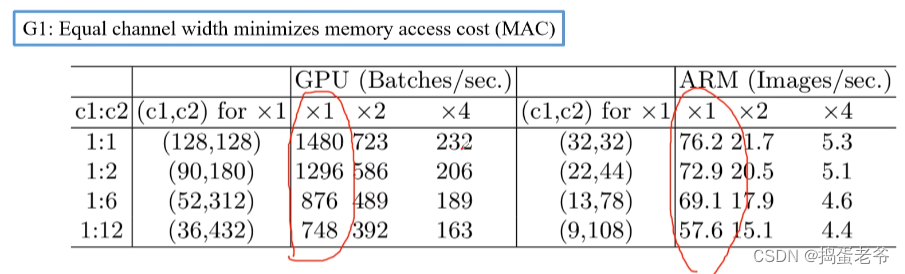
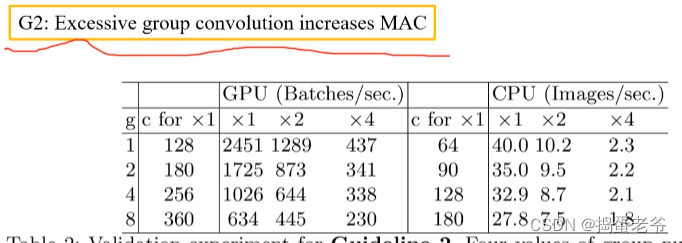
- 设计高效的网络

- 针对1*1的pw卷积

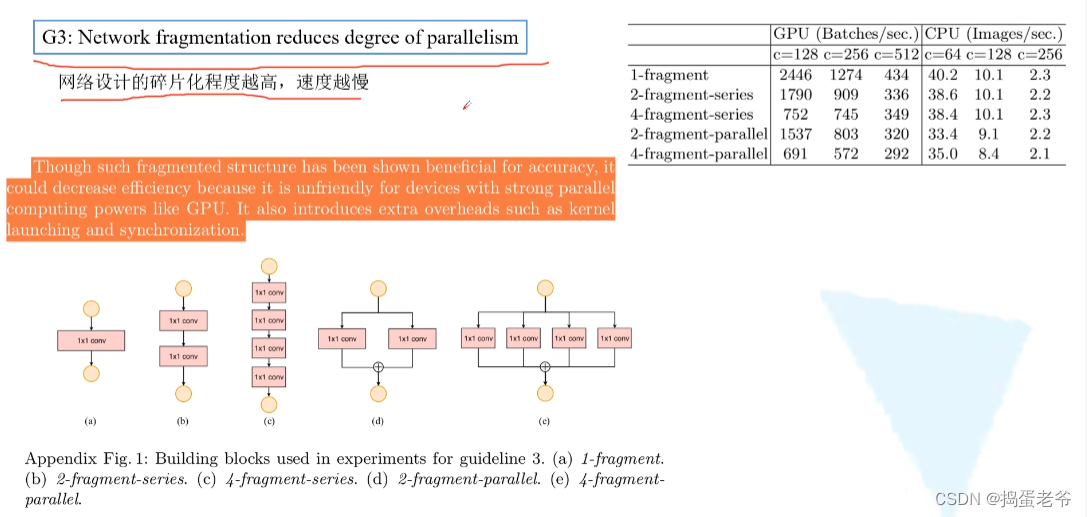

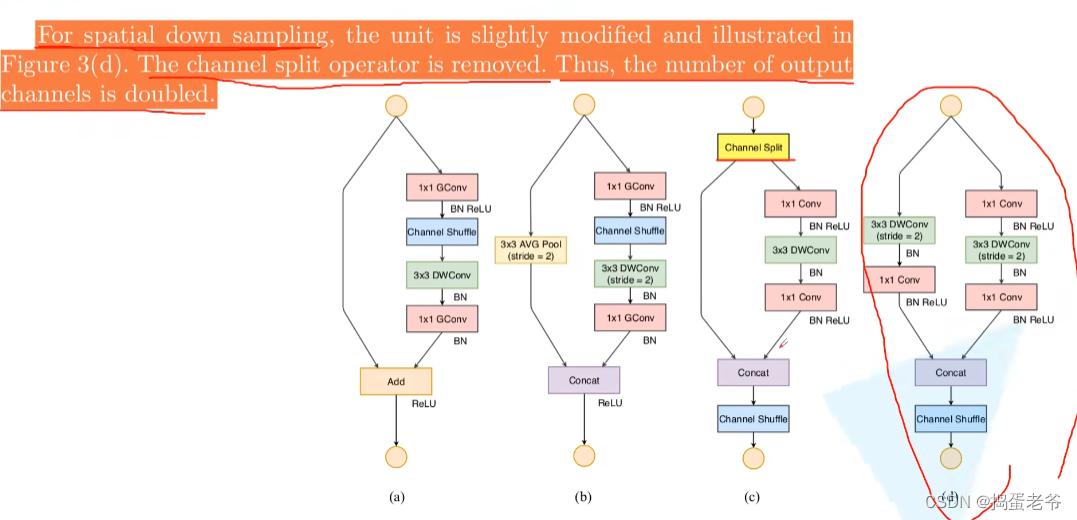
- 结构
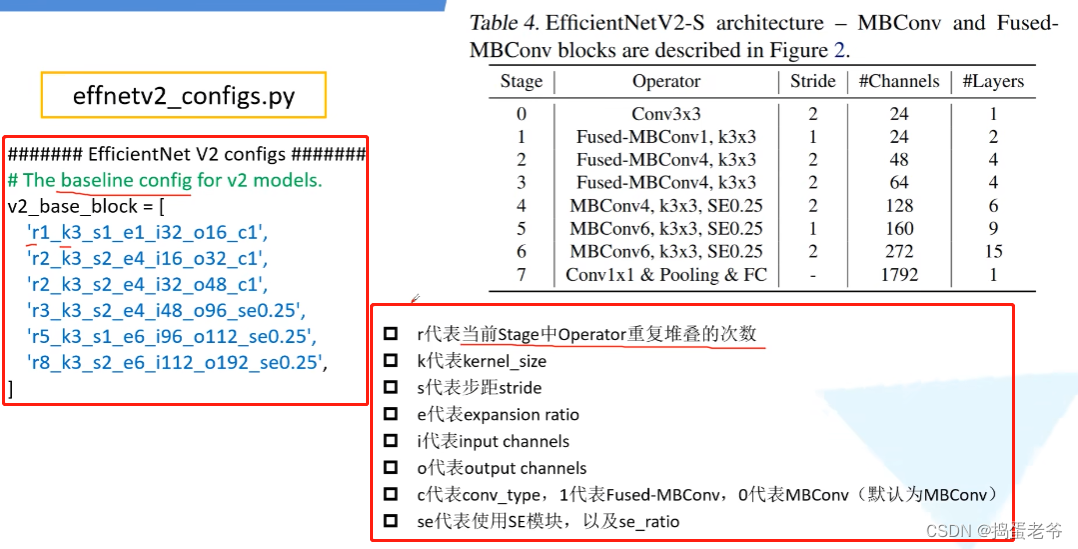
EfficientNet V1
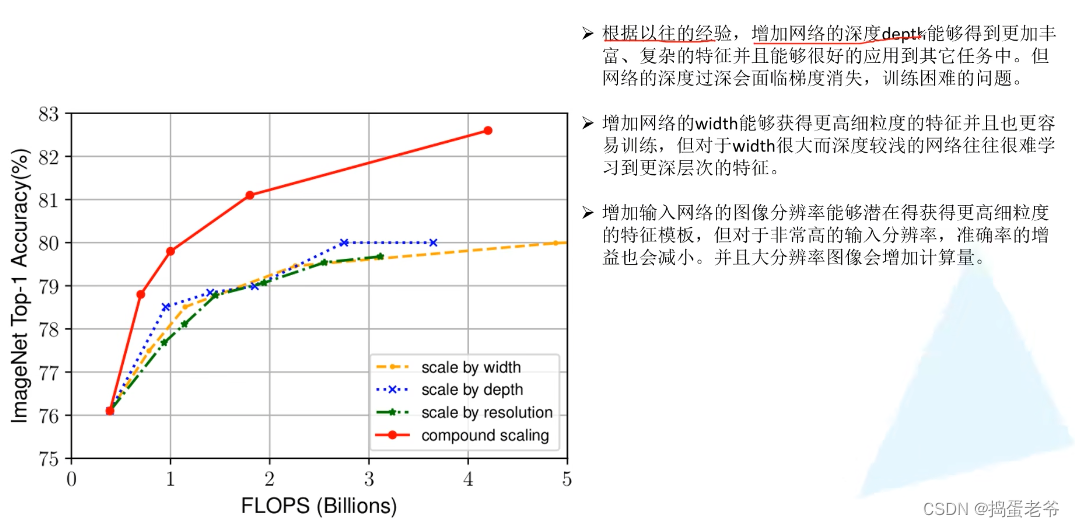
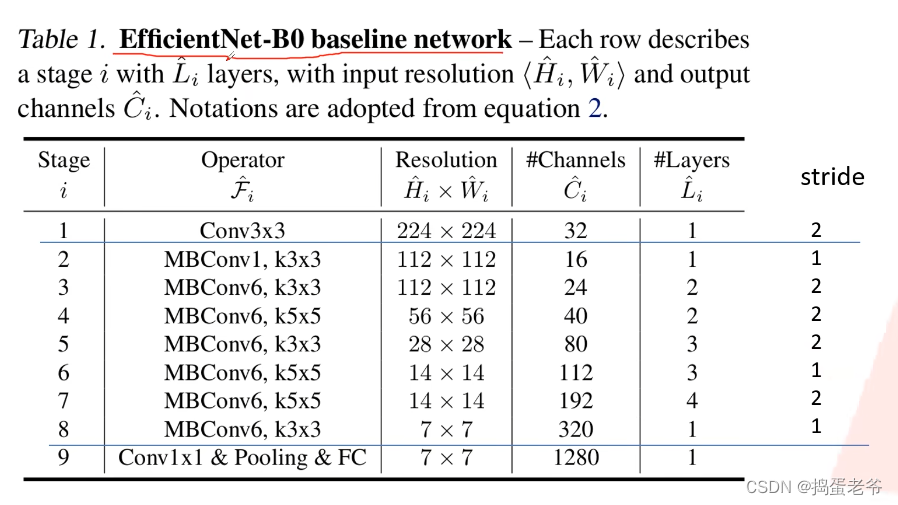
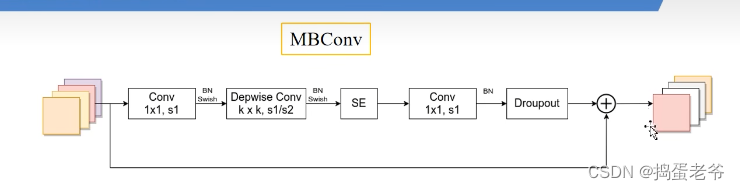
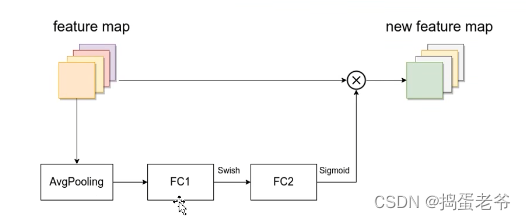
- 不同的网络输入图片的尺寸是不一样的
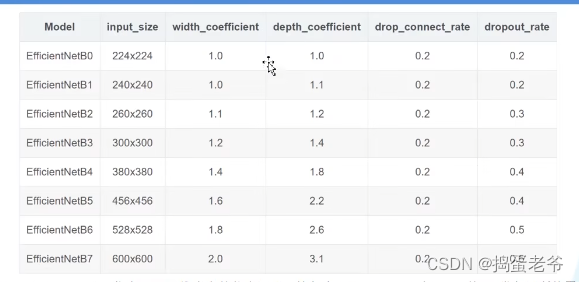
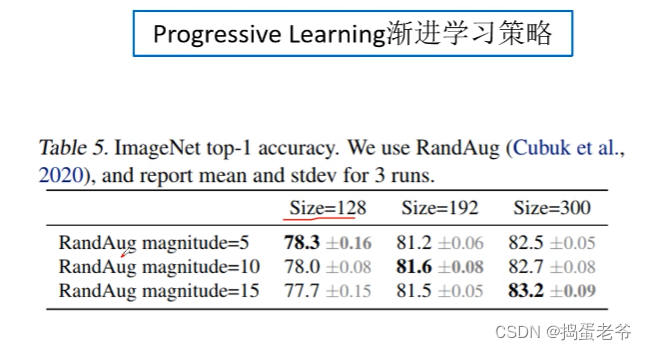
EfficientNet V2
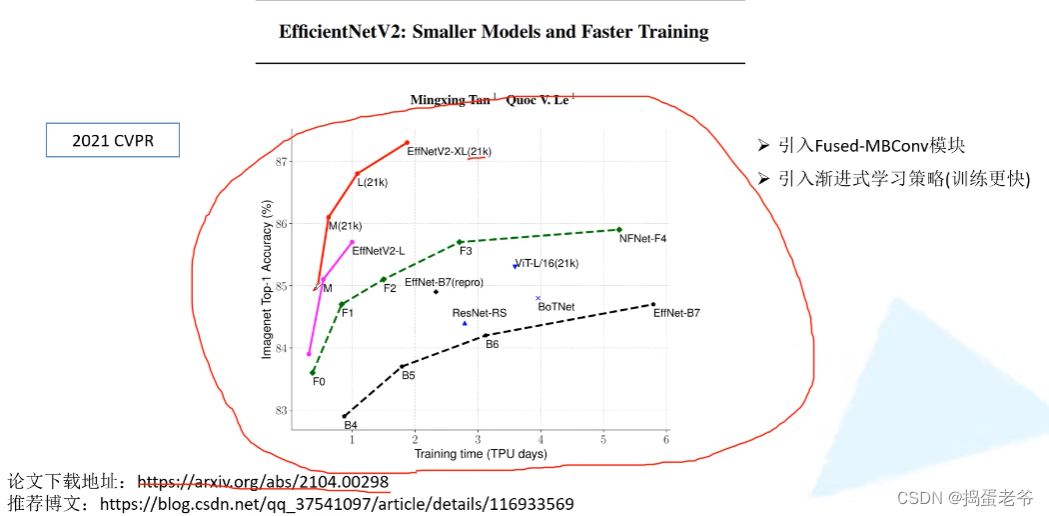

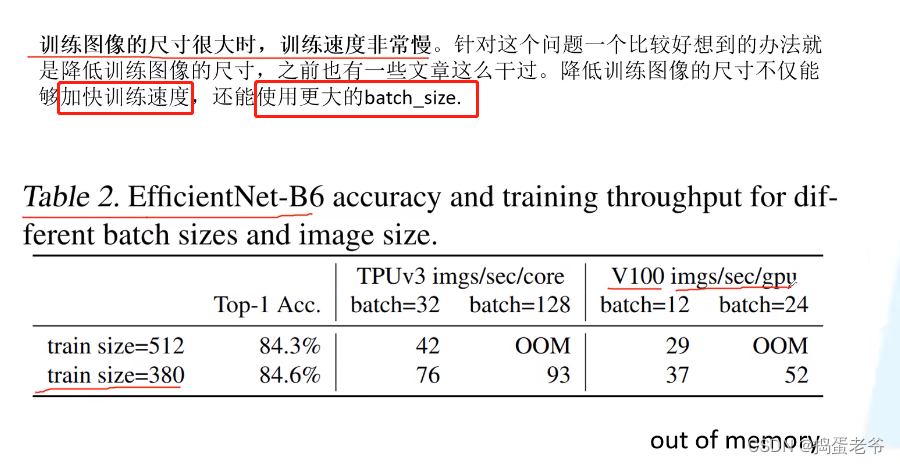

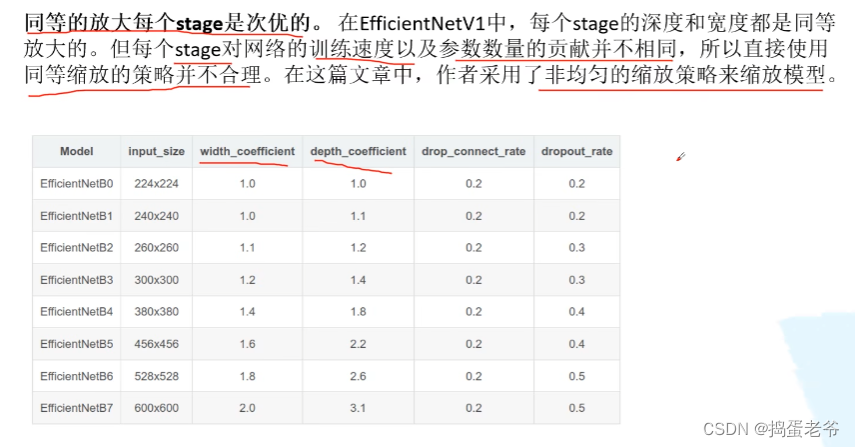
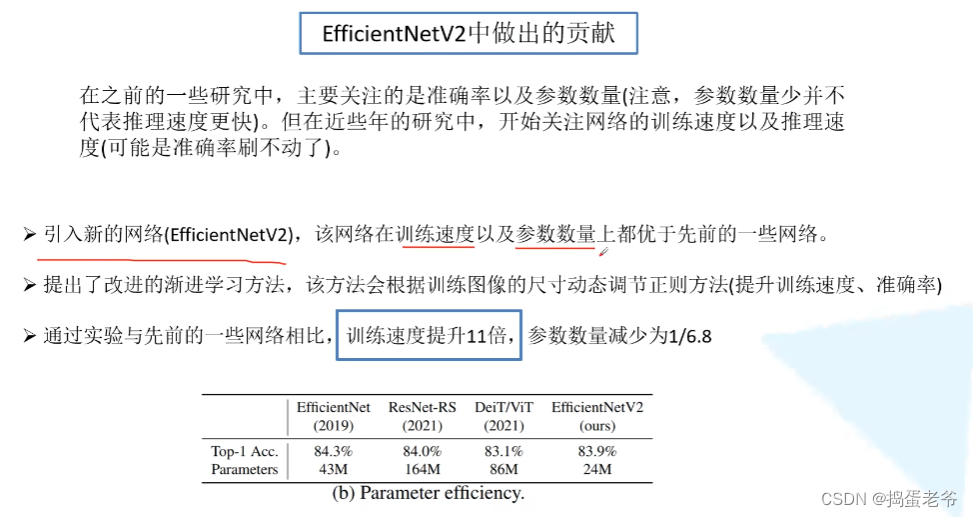
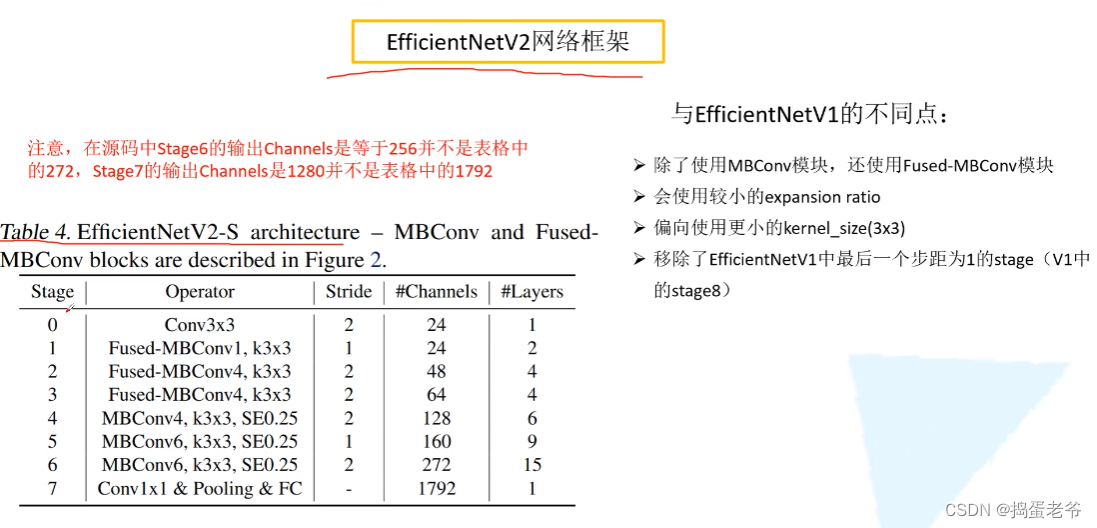
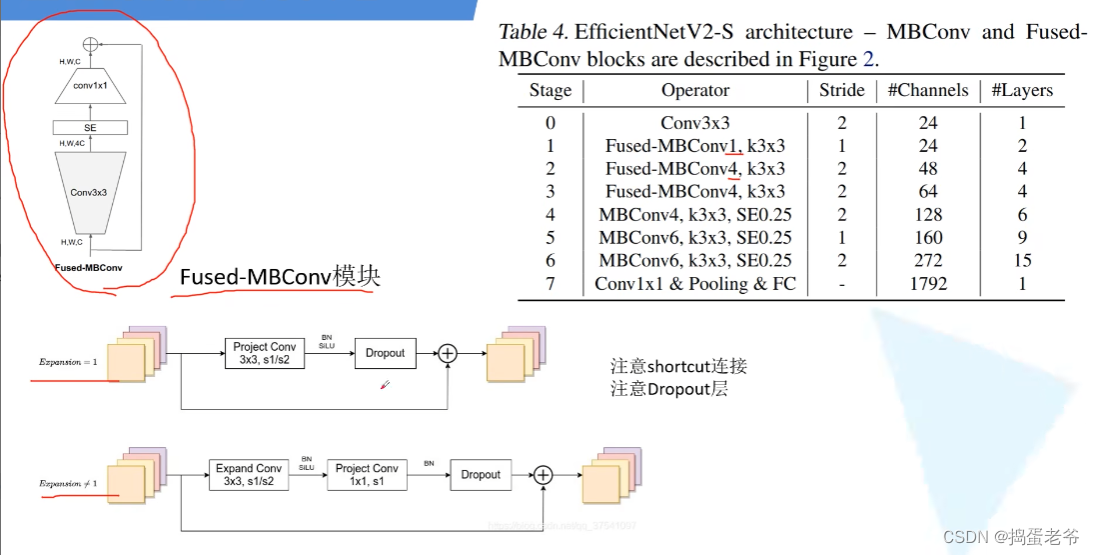
- Dropout:https://www.bilibili.com/video/BV1Fb4112722/?spm_id_from=333.337.search-card.all.click&vd_source=6bcccf10adf3fa505b41acbe0da77a56
- 训练的时候以p的概率丢弃输入x,所以输入的期望是px,输出是wpx。
- 推理的时候为了和训练呼应,又不能使得推理是一个可以变化的值,那么把p放在w上,输出是pwx
- 输入层丢弃少一点0.9,隐藏层0.5左右
- 原理:因为不确定每次神经元的个数,所以只能学习非常稳定内容,使得单个神经元变得很强大,不好学习误差信息