目录
- Introduction 导言
- 环境
- 搭建环境
- Github地址
- 项目目录说明
- 使用步骤
- 下载预训练模型
- 更改部分代码
- 模型训练
- 参数设置
- BERT-CRF模型训练
- BERT-SPAN模型训练
- BERT-MRC模型训练
- 运行训练
- 预测复赛 test 文件 (上述模型训练完成后)
- 参考资料
- 其它资料下载
Introduction 导言
人工智能对中医药领域的传承和创新发展起到了重要的加速作用。其中,中医药文本信息的抽取是构建中医药知识图谱的核心组成部分,为上层应用如临床辅助诊疗系统(CDSS)的构建奠定了基础。
在本次NER挑战中,我们的目标是从中药药品说明书中提取关键信息,包括药品、药物成分、疾病、症状、证候等13类实体,并构建中医药药品的知识库。
通过应用自然语言处理和深度学习技术,我们可以对中药药品说明书进行语义分析和实体抽取。通过训练模型,我们可以识别和提取药品名称、药物成分、相关疾病、症状、证候等重要信息,并将其存储到中医药药品知识库中。
构建中医药药品知识库对于推动中医药的研究和临床实践具有重要意义。这个知识库可以为中医药研究人员和临床医生提供方便快捷的参考信息,帮助他们深入了解中药的特性、功效和应用范围。同时,该知识库也为中医药领域的智能化应用提供了数据基础,如CDSS系统的构建和其他医疗决策支持系统。
本次开源的项目是天池中药说明书实体识别挑战冠军方案Cinese-DeepNER-Pytorch,本博客主要是部署运行该算法的不同模型。
关于本项目的方案及模型原理说明详见另外一篇博客:
天池大赛中药说明书实体识别挑战冠军方案开源(一)方案及模型原理说明
环境
python3.7
pytorch==1.6.0 +
transformers==2.10.0
pytorch-crf==0.7.2
搭建环境
搭建环境,建议搭建pytorch-GPU版本,具体搭建过程,可参考我另外一篇博客:
NLP实战:Pytorch实现6大经典深度学习中文短文本分类-bert+ERNIE+bert_CNN+bert_RNN+bert_RCNN+bert_DPCNN
另外还需要在安装环境下,分别使用下面命令安装相关库:
pip install transformers==2.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pytorch-crf==0.7.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
Github地址
使用下面github地址,下载到本地。
天池中药说明书实体识别挑战冠军方案
项目目录说明
下载到本地后,可以看到以下目录:
DeepNER
│
├── data # 数据文件夹
│ ├── mid_data # 存放一些中间数据
│ │ ├── crf_ent2id.json # crf 模型的 schema
│ │ └── span_ent2id.json # span 模型的 schema
│ │ └── mrc_ent2id.json # mrc 模型的 schema
│
│ ├── raw_data # 转换后的数据
│ │ ├── dev.json # 转换后的验证集
│ │ ├── test.json # 转换后的初赛测试集
│ │ ├── pseudo.json # 转换后的半监督数据
│ │ ├── stack.json # 转换后的全体数据
│ └── └── train.json # 转换后的训练集
│
├── out # 存放训练好的模型
│ ├── ...
│ └── ...
│
├── src
│ ├── preprocess
│ │ ├── convert_raw_data.py # 处理转换原始数据
│ │ └── processor.py # 转换数据为 Bert 模型的输入
│ ├── utils
│ │ ├── attack_train_utils.py # 对抗训练 FGM / PGD
│ │ ├── dataset_utils.py # torch Dataset
│ │ ├── evaluator.py # 模型评估
│ │ ├── functions_utils.py # 跨文件调用的一些 functions
│ │ ├── model_utils.py # Span & CRF & MRC model (pytorch)
│ │ ├── options.py # 命令行参数
│ | └── trainer.py # 训练器
|
├── competition_predict.py # 复赛数据推理并提交
├── README.md # ...
├── convert_test_data.py # 将复赛 test 转化成 json 格式
├── run.sh # 运行脚本
└── main.py # main 函数 (主要用于训练/评估)
使用步骤
下载预训练模型
首先下载
-
哈工大预训练模型 :https://github.com/ymcui/Chinese-BERT-wwm
百度云下载链接:
链接:https://pan.baidu.com/s/1axdkovbzGaszl8bXIn4sPw
提取码:jjba(注意:需人工将 vocab.txt 中两个 [unused] 转换成 [INV] 和 [BLANK])
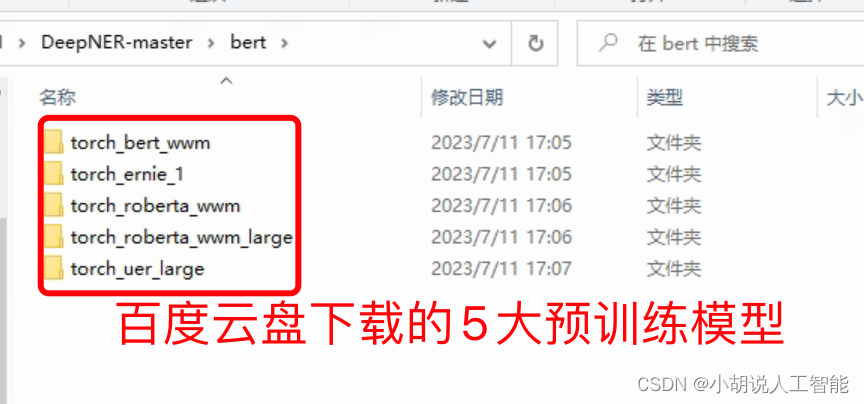
tips: 推荐使用 uer、roberta-wwm、robert-wwm-large
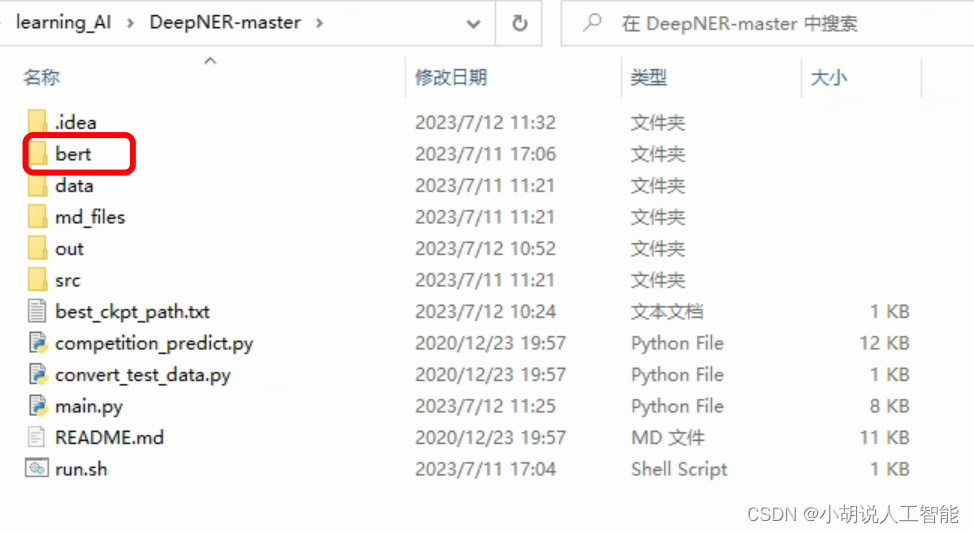
注:run.sh脚本中指定的 BERT_DIR 指BERT所在文件夹,需要把上面百度云下载的 BERT 文件夹放到该指定文件夹中
如:export BERT_DIR=“./bert/torch_$BERT_TYPE”
就表示直接放到DeepNER目录下的bert文件夹即可。注意github中的export BERT_DIR="../bert/torch_$BERT_TYPE"是默认放在DeepNER上层目录下。
博主最后放的目录如下图:
更改部分代码
-
如果你使用的系统为Linux系统,可以不做任何更改。
-
如果你使用的系统为Windows系统,需要对部分地址的分割方式进行更改。否则会出现相关报错,如下:
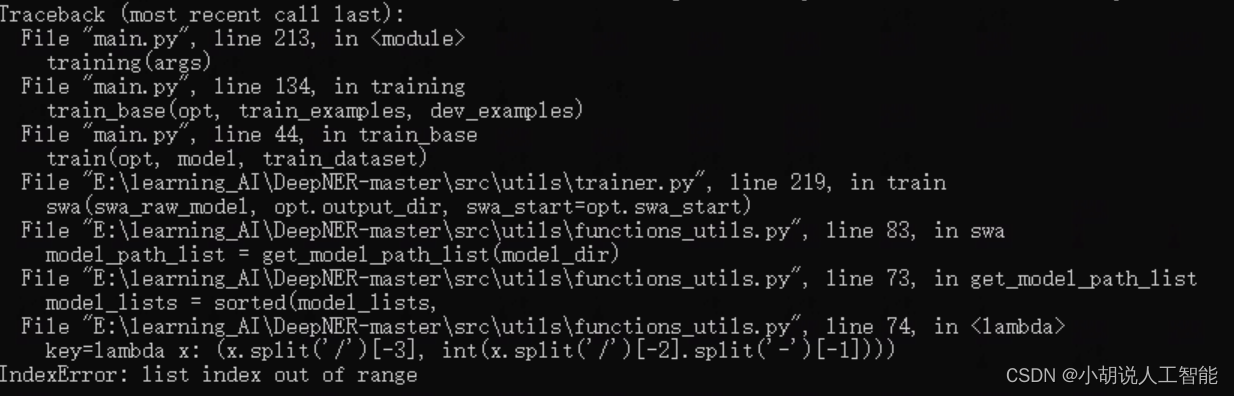
具体Windows系统下需要修改的代码(核心就是把路径分割中的/ 改为\\)如下:
1)/src/utils/function_utils.py 中的get_model_path_list函数,具体修改如下:
def get_model_path_list(base_dir):
"""
从文件夹中获取 model.pt 的路径
"""
model_lists = []
base_dir = os.path.abspath(base_dir) #生成绝对路径
# print(base_dir)
for root, dirs, files in os.walk(base_dir):
for _file in files:
if 'model.pt' == _file:
model_lists.append(os.path.join(root, _file))
model_lists = sorted(model_lists,
key=lambda x: (x.split('\\')[-3], int(x.split('\\')[-2].split('-')[-1])))
return model_lists
2)main.py 第69行,具体修改如下:
model_path = os.path.abspath(model_path) #生成绝对路径
tmp_step = model_path.split('\\')[-2].split('-')[-1]
3)main.py 第106行,具体修改如下:
del_dir_list = [os.path.join(opt.output_dir, path.split('\\')[-2])
for path in model_path_list if path != max_f1_path]
模型训练
参数设置
BERT-CRF模型训练
task_type='crf'
mode='train' or 'stack' train:单模训练与验证 ; stack:5折训练与验证
swa_start: swa 模型权重平均开始的 epoch
attack_train: 'pgd' / 'fgm' / '' 对抗训练 fgm 训练速度慢一倍, pgd 慢两倍,pgd 本次数据集效果明显
BERT-SPAN模型训练
task_type='span'
mode:同上
attack_train: 同上
loss_type: 'ce':交叉熵; 'ls_ce':label_smooth; 'focal': focal loss
BERT-MRC模型训练
task_type='mrc'
mode:同上
attack_train: 同上
loss_type: 同上
运行训练
1)Linux系统:直接打开终端,进入上面搭建好的环境,到DeepNER目录下,运行下面命令即可开始训练了。
按照上面参数设置说明:
- 如果你需要训练BERT-CRF,可以参考下面,修改
run.sh文件
#!/usr/bin/env bash
export MID_DATA_DIR="./data/mid_data"
export RAW_DATA_DIR="./data/raw_data"
export OUTPUT_DIR="./out"
export GPU_IDS="0"
export BERT_TYPE="roberta_wwm" # roberta_wwm / roberta_wwm_large / uer_large
export BERT_DIR="./bert/torch_$BERT_TYPE"
export MODE="train"
export TASK_TYPE="crf"
python main.py \
--gpu_ids=$GPU_IDS \
--output_dir=$OUTPUT_DIR \
--mid_data_dir=$MID_DATA_DIR \
--mode=$MODE \
--task_type=$TASK_TYPE \
--raw_data_dir=$RAW_DATA_DIR \
--bert_dir=$BERT_DIR \
--bert_type=$BERT_TYPE \
--train_epochs=10 \
--swa_start=5 \
--attack_train="" \
--train_batch_size=24 \
--dropout_prob=0.1 \
--max_seq_len=512 \
--lr=2e-5 \
--other_lr=2e-3 \
--seed=123 \
--weight_decay=0.01 \
--loss_type='ls_ce' \
--eval_model \
#--use_fp16
- 如果你需要训练BERT-SPAN,可以参考下面,修改
run.sh文件
#!/usr/bin/env bash
export MID_DATA_DIR="./data/mid_data"
export RAW_DATA_DIR="./data/raw_data"
export OUTPUT_DIR="./out"
export GPU_IDS="0"
export BERT_TYPE="roberta_wwm" # roberta_wwm / roberta_wwm_large / uer_large
export BERT_DIR="./bert/torch_$BERT_TYPE"
export MODE="train"
export TASK_TYPE="span"
python main.py \
--gpu_ids=$GPU_IDS \
--output_dir=$OUTPUT_DIR \
--mid_data_dir=$MID_DATA_DIR \
--mode=$MODE \
--task_type=$TASK_TYPE \
--raw_data_dir=$RAW_DATA_DIR \
--bert_dir=$BERT_DIR \
--bert_type=$BERT_TYPE \
--train_epochs=10 \
--swa_start=5 \
--attack_train="" \
--train_batch_size=24 \
--dropout_prob=0.1 \
--max_seq_len=512 \
--lr=2e-5 \
--other_lr=2e-3 \
--seed=123 \
--weight_decay=0.01 \
--loss_type='ls_ce' \
--eval_model \
#--use_fp16
- 如果你需要训练BERT-MRC,可以参考下面,修改
run.sh文件
#!/usr/bin/env bash
export MID_DATA_DIR="./data/mid_data"
export RAW_DATA_DIR="./data/raw_data"
export OUTPUT_DIR="./out"
export GPU_IDS="0"
export BERT_TYPE="roberta_wwm" # roberta_wwm / roberta_wwm_large / uer_large
export BERT_DIR="./bert/torch_$BERT_TYPE"
export MODE="train"
export TASK_TYPE="mrc"
python main.py \
--gpu_ids=$GPU_IDS \
--output_dir=$OUTPUT_DIR \
--mid_data_dir=$MID_DATA_DIR \
--mode=$MODE \
--task_type=$TASK_TYPE \
--raw_data_dir=$RAW_DATA_DIR \
--bert_dir=$BERT_DIR \
--bert_type=$BERT_TYPE \
--train_epochs=10 \
--swa_start=5 \
--attack_train="" \
--train_batch_size=24 \
--dropout_prob=0.1 \
--max_seq_len=512 \
--lr=2e-5 \
--other_lr=2e-3 \
--seed=123 \
--weight_decay=0.01 \
--loss_type='ls_ce' \
--eval_model \
#--use_fp16
bash run.sh
2)Windows系统:直接打开终端,进入上面搭建好的环境,到DeepNER目录下,运行下面命令即可开始训练了。
- 训练BERT-CRF
python main.py --gpu_ids="0" --output_dir="./out" --mid_data_dir="./data/mid_data" --mode="train" --task_type="crf" --raw_data_dir="./data/raw_data" --bert_dir="./bert/torch_roberta_wwm" --bert_type="roberta_wwm" --train_epochs=10 --swa_start=5 --attack_train="" --train_batch_size=12 --dropout_prob=0.1 --max_seq_len=512 --lr=2e-5 --other_lr=2e-3 --seed=123 --weight_decay=0.01 --loss_type='ls_ce' --eval_model
- 训练BERT-SPAN
python main.py --gpu_ids="0" --output_dir="./out" --mid_data_dir="./data/mid_data" --mode="train" --task_type="span" --raw_data_dir="./data/raw_data" --bert_dir="./bert/torch_roberta_wwm" --bert_type="roberta_wwm" --train_epochs=10 --swa_start=5 --attack_train="" --train_batch_size=12 --dropout_prob=0.1 --max_seq_len=512 --lr=2e-5 --other_lr=2e-3 --seed=123 --weight_decay=0.01 --loss_type='ls_ce' --eval_model
- 训练BERT-MRC
python main.py --gpu_ids="0" --output_dir="./out" --mid_data_dir="./data/mid_data" --mode="train" --task_type="mrc" --raw_data_dir="./data/raw_data" --bert_dir="./bert/torch_roberta_wwm" --bert_type="roberta_wwm" --train_epochs=10 --swa_start=5 --attack_train="" --train_batch_size=12 --dropout_prob=0.1 --max_seq_len=512 --lr=2e-5 --other_lr=2e-3 --seed=123 --weight_decay=0.01 --loss_type='ls_ce' --eval_model
注:小伙伴们也可以分别调整如max_seq_len为512或者256,使用不同的lr(学习率)、不同的loss_type(‘ce’:交叉熵; ‘ls_ce’:label_smooth; ‘focal’: focal loss),不同的swa_start(swa模型权重平均开始的epoch),不同的attack_train( ‘pgd’ 或 ‘fgm’ 在对抗训练 fgm 训练速度慢一倍, pgd 慢两倍,pgd 本次数据集效果明显)。对比训练结果。
3)运行问题说明:
当遇到下面提示,说明你的GPU显存不够(博主显存是16G,显示不够),建议将train_batch_size由24调整为12 或者 6再尝试即可。

4)训练结果演示:
BERT-CRF模型:
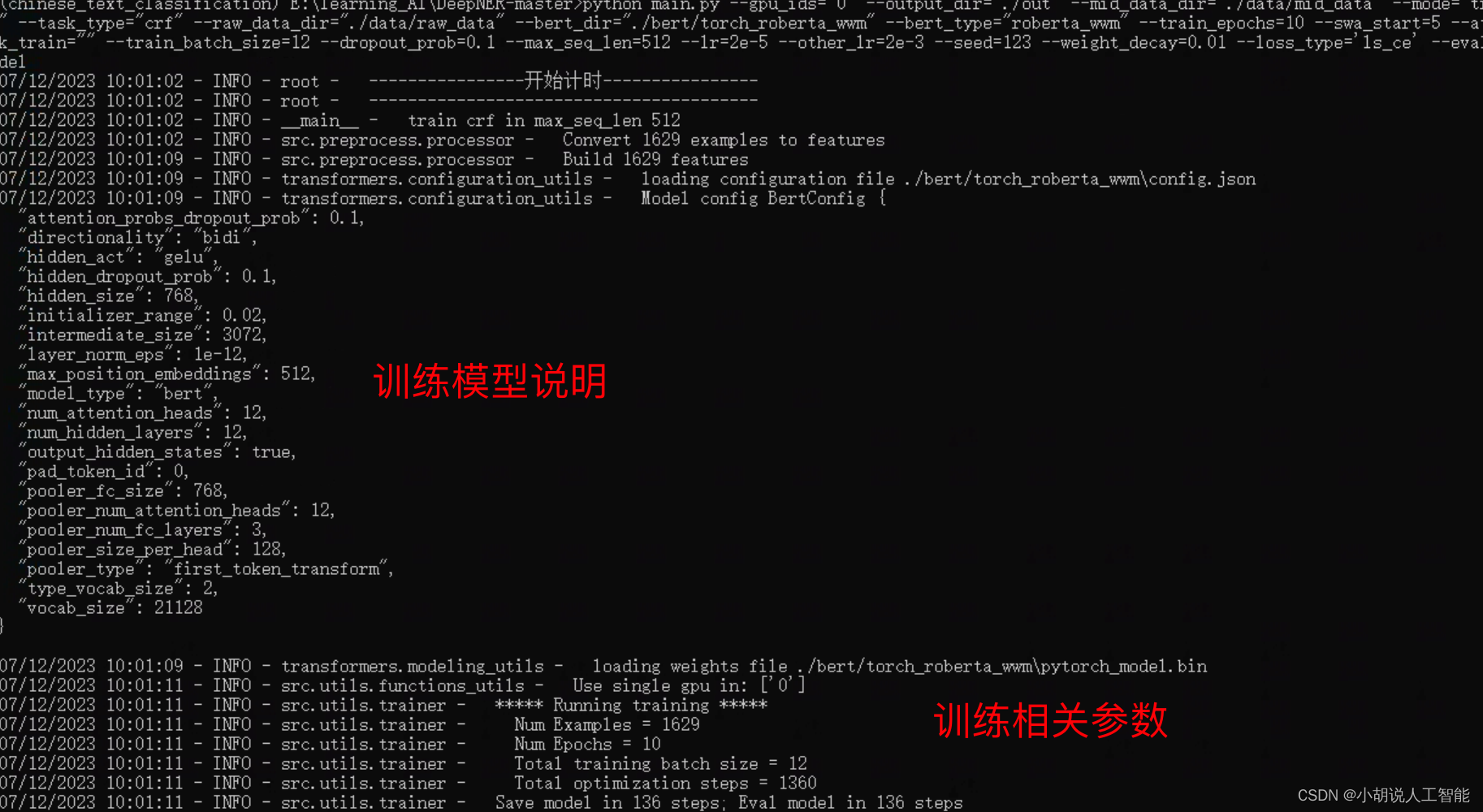
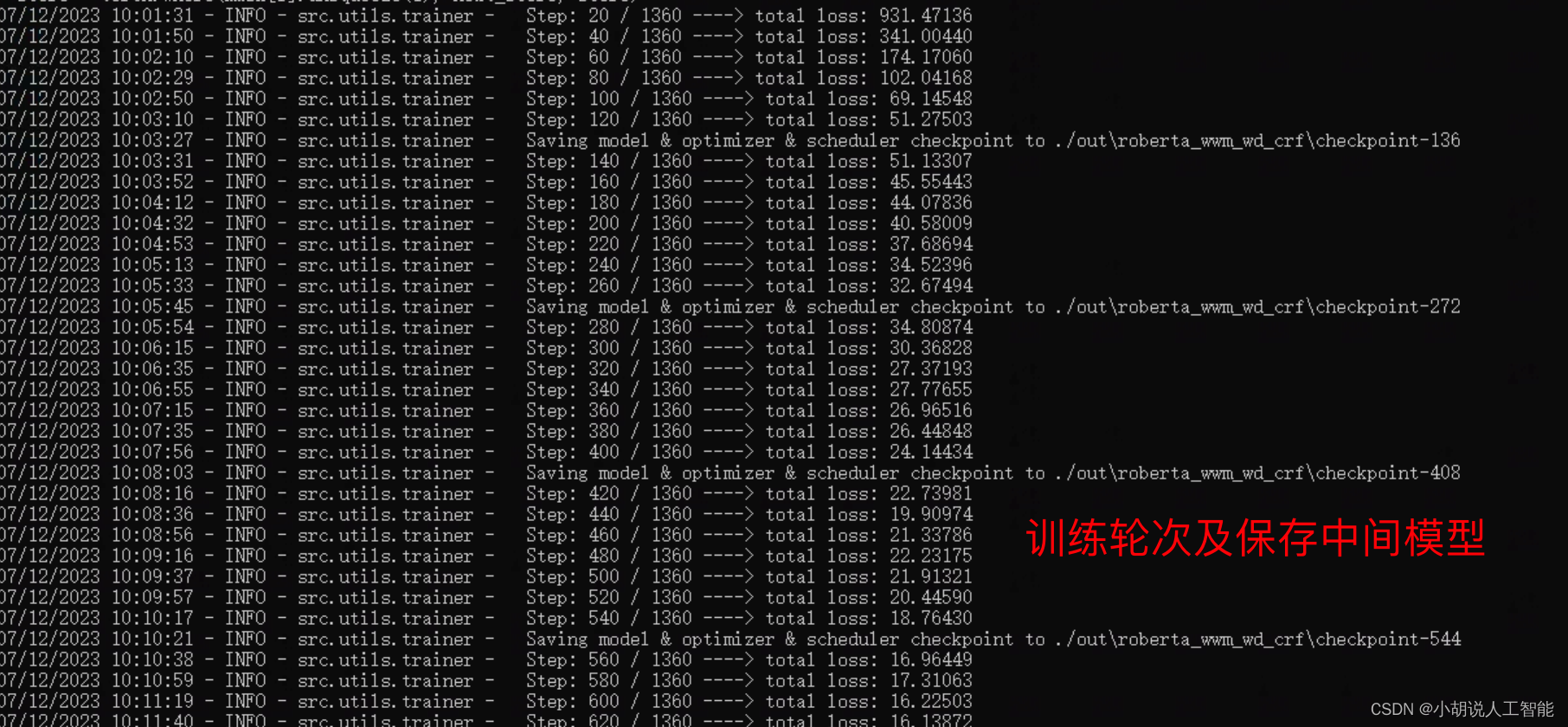

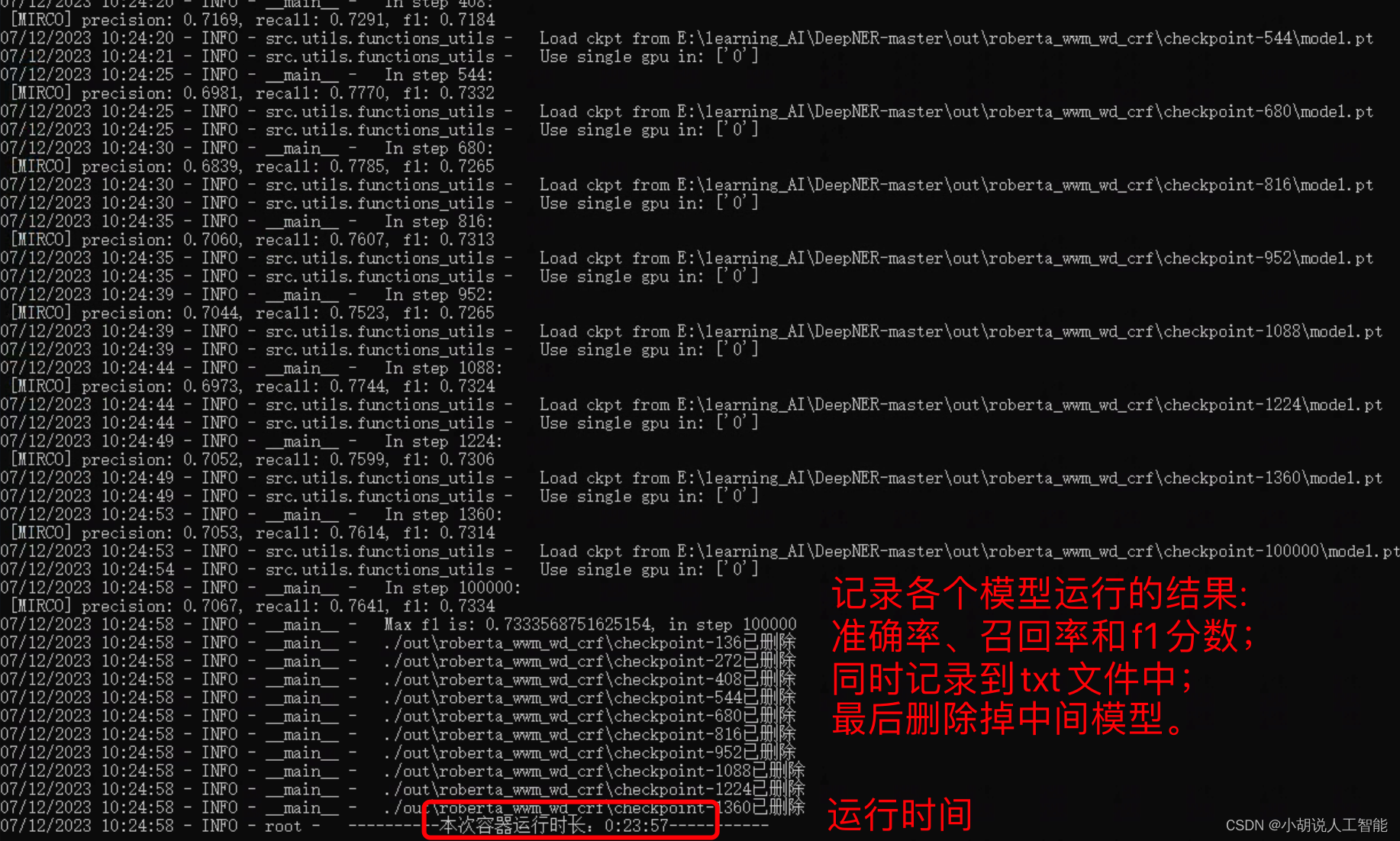
从上面几张图,可以看出,整个训练大概运行了23分57秒;BERT-CRF模型训练到最后的准确率约为70.67%,召回率为76.41%,f1分数为0.7334。
BERT-SPAN模型:
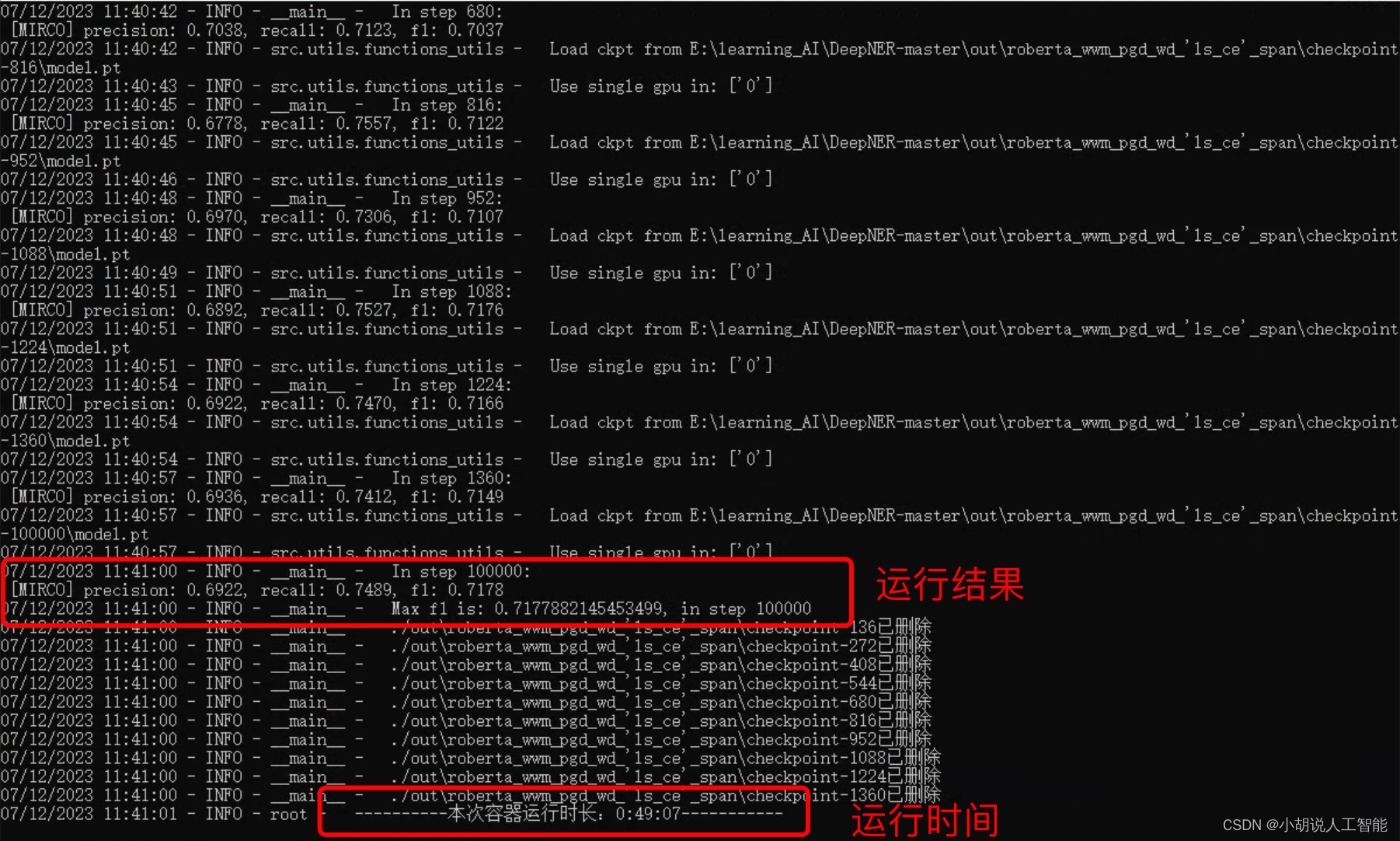
训练结果如下图,可以看出,整个训练大概运行了49分07秒;BERT-SPAN模型训练到最后的准确率约为69.22%,召回率为74.89%,f1分数为0.7178。
预测复赛 test 文件 (上述模型训练完成后)
注:暂无数据运行,等待官方数据开源后可运行
# convert_test_data
python convert_test_data.py
# predict
python competition_predict.py
参考资料
天池中药说明书实体识别挑战冠军方案开源
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。