在过去的数年里,我们见证了机器学习和计算机科学领域的很多变化。人工智能应用也愈趋广泛,正在加速融入人们的日常生活之中。机器学习作为技术核心,也在持续地发展进化,在更多领域发挥出越来越重要的作用。**机器学习会有哪些新的演进趋势和发展方向?**我们又该如何提前布局,紧跟这一热门技术的前沿变化?
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
《机器学习洞察》系列文章将基于机器学习的发展现状,逐一解读和分析目前机器学习在实践落地中颇具潜力的四个演进趋势,包括多模态机器学习、分布式训练、无服务器推理,以及 JAX 这一新崛起的深度学习框架。
什么是多模态数据机器学习
人们听到的声音、看到的食物、闻到的味道,这些都属于模态信息,而我们生活在多模态信息相互交融的环境之中。
为了使人工智能可以更好地理解世界,人们需要赋予人工智能学习理解和推理多模态信息的能力。多模态数据机器学习就是指通过建立模型,使机器从多模态中学习各种模态信息,并且实现各个模态的信息交流和转换的过程。
多模态应用范围广泛,既涵盖包括人工智能音箱、电商的商品推荐系统、图像识别等生活化场景,还可以应用于一些工业领域,包括导航和自动驾驶、生理病变研究、环境监测和天气预报等等,也可以支持未来元宇宙场景下虚拟人和人类之间沟通等等。
多模态学习领域的演进
随着多模态数据机器学习的热度越来越高,有关于多模态数据机器学习的研究也迎来许多创新性的突破,特别是以下三个重要进展:
-
ZSL:Zero-Shot Learning(University of Tübingen, 2009)
Learning to detect unseen object classes by between-class attribute transfer | IEEE Conference Publication | IEEE Xplore
-
CLIP:基于对比文本-图像对的预训练(OpenAI, 2021)
https://arxiv.org/abs/2103.00020?trk=cndc-detail
-
ZESREC:基于 Zero-Shot 的推荐系统(Amazon, 2021)
Zero shot recommender systems - Amazon Science
Zero-Shot Learning (ZSL)
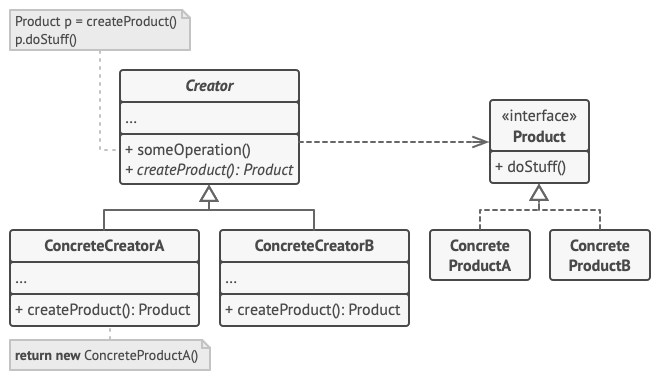
通过训练集图片学习出一些属性,将这些属性相结合得到融合特征之后,匹配与训练集图片不重合的测试集图片,来判断其类别,这一过程就是 Zero-Shot Learning (ZSL),即用见过的图片特征去判断没见过的图片类别。
让我们先以人类的一般推理过程来做个类比:
假设小明和爸爸一起到动物园游玩。首先看到了马,于是爸爸告诉小明,马就是这个形状的;之后,又看到了老虎,爸爸又告诉小明:“看,这种身上有条纹的动物就是老虎。”;最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”
然后爸爸给小明安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小明有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后小明根据爸爸的提示,在动物园里找到了斑马。
上述例子中包含了一个人类的推理过程,就是利用过去的知识(马,老虎,熊猫的描述),在脑海中推理出新对象(斑马)的具体形态,从而能对新对象进行辨认。
例如下图中,从训练集图片 (Seen Classes Data) 中学习出一些属性 (比如 horselike、stripe 和 black&white),然后将这些属性相结合得到融合特征,融合特征刚好和测试集的斑马特征相匹配,最终得到预测结果为斑马:

图片来源:论文《Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer( University of Tübingen, 2009)》
Zero-Shot Learning 包含了一个推理的过程,就是如何利用过去的知识,在脑海中推理出新的对象的具体形态,从而对新对象进行辨认。
如今通过深度学习和监督学习虽然在很多任务上都可以给出令人惊叹的结果,但是这种学习方式也存在以下弊端:
- 需要足够多的样本数据,给样本打标签的工作量巨大
- 分类结果依赖训练样本,无法推理识别新类别
这显然难以满足人类对于人工智能的终极想象。而 Zero-Shot Learning 就是希望能够模拟人类通过推理识别新类别的能力,使得计算机具有识别新事物的能力,进而实现真正的智能。
CLIP:基于对比文本-图像对的预训练
2021 年之前,在自然语言处理 (Natural Language Processing, NLP) 领域有很多预训练方法都获得了成功。例如,GPT-3 175B 从网上搜集了近 5 亿 tokens 进行预训练,在很多下游任务上实现 SOTA (State-of-the-Art) 性能和 Zero-Shot Learning。这说明从海量互联网数据 (web-scale) 中学习,是可以超过高质量的人工标注 NLP 数据集的。
但是在计算机视觉 (Computer Vision, CV) 领域的预训练模型还是主要基于人工标注的 ImageNet 数据进行训练。由于人工标注的工作量巨大,许多科学家们开始设想,如何构建更为高效、便捷的方式用于训练视觉表征模型呢?
在 2021 年发表的论文《Learning Transferable Visual Models From Natural Language Supervision》中隆重推出了 CLIP (Contrastive Language-Image Pre-training) 模型,并且详细地介绍了如何通过自然语言处理监督信号,训练可迁移的视觉模型。
论文中是怎样处理 NLP 的监督信号呢?
在论文中主要介绍了以下三个部分:
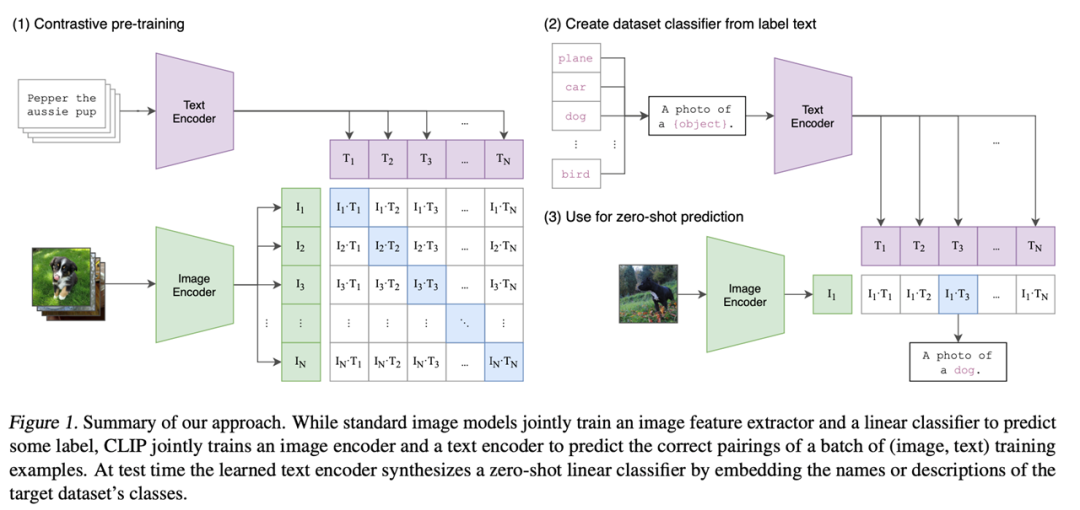
图片来自论文
第一部分:对比的预训练。
在训练的过程中,通过两个编码器:文字编码器和图片编码器,完成模型输入的配对,形成 N 组图片和文本的特征。上图矩阵中蓝色对角线上的特征组作为正样本,其他白色特征组作为负样本, CLIP 会基于这些特征进行对比学习,完全不需要手工标注。
需要注意的是,这种无监督的对比学习需要大量的数据训练。在论文中的数据集中有 4 亿组文字图片的配对,保证了输出结果的质量。
第二部分:用 CLIP 实现 Zero-Shot 分类。
在下游任务中,CLIP 避免使用特殊的分类头,以实现完全不需要进行微调的数据集迁移。论文中设计了一个很巧妙的方法 ,Prompt Template,利用自然语言将分类任务巧妙的移植到现有的训练方法中。
第三部分:Zero-Shot 推理。
通过将样本图片输入到图像编码器中得到图像的特征,然后拿这个图像的特征去和所有的文本特征计算相似度,选择相似度最大的文本特征对应的句子来完成分类任务,最后形成结果图片。
通过验算,我们能够看到基于 CLIP 训练出来的模型效果非常理想:

图片来自论文
这个实验经过 ImageNet 数据集的重新筛选,制作了几个变种的版本。
在 ImageNet 数据集上训练出来的 ResNet 101 模型准确率是 76.2%,用 CLIP 训练出来的 VIT-Large 模型准确率同样是 76.2%。然而当我们换成其它数据集,严格按照 1000 类的分类头再次训练,得出的模型准确率却下降得很快。特别是使用上图中最后两行样本(素描画或者对抗性样本)时,准确度仅为 25.2% 和 2.7%,基本属于随机猜测,迁移效果惨不忍睹。对比使用 CLIP 训练出来的模型,准确率基本在线。
这从侧面说明了:因为和自然语言处理的结合,所以导致 CLIP 学出来的这个视觉特征,和我们用语言所描述的某个物体,已经产生了强烈的联系。
代码示例:在 Amazon SageMaker 运行 CLIP 模型
这个示例展示了如何下载和运行 CLIP 模型,计算任意图像和文本输入之间的相似性,以及执行 ZSL 图像分类。
- 下载和运行 CLIP 模型,输入之后可得到我们需要的模型;
import clip
clip.available_models()model, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
图片来源:ImageNet 数据集
- 计算相似度:通过对特征进行归一化并计算每对的点积,来计算余弦相似度。
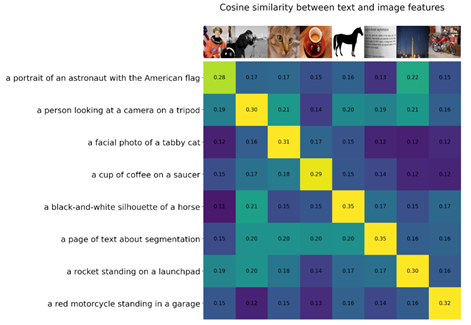
图片来源:CIFAR100 数据集
- ZSL 图像分类:使用余弦相似度(乘以 100)作为 softmax 运算的对数对图像进行分类。
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)这里展示了执行 ZSL 图像分类的最终结果:在一个模型从未见过的图像集(这里以 CIFAR100 图像集为例)上,CLIP ViT-B/32 模型针对 CIFAR100 图像集分类标签的匹配结果。
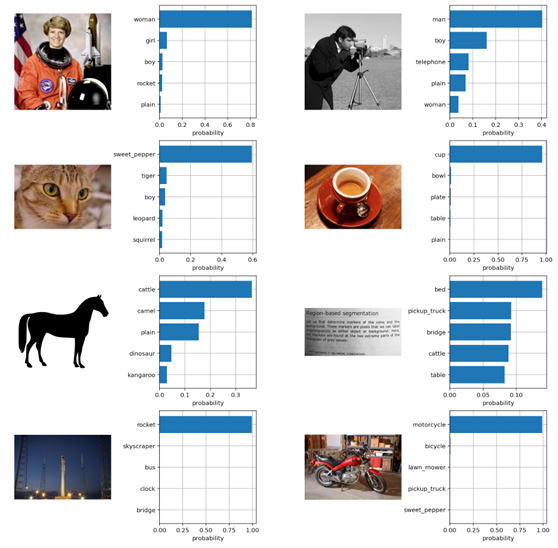
图片来源:CIFAR100 数据集
整个过程无需在下游做微调,不用在数据集上训练,直接在基准上评估。
关于 CLIP 论文的完整代码请参考: GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
ZESREC:基于 Zero-Shot 的推荐系统
除此之外,在多模态数据机器学习中,除了 CLIP 以外,我们也有一些其他的探索,例如亚马逊云科技的 AI Labs。
在论文 《Zero-Shot Recommender Systems》中分享了基本思路,即使用 BERT 训练的商品详情描述信息替代商品 id embedding 作为产品输入,上层连接 mlp 转为300 dim,然后连接 hmn 学习序列特征。
对于未出现的商品和用户进行推荐,它很好地解决了推荐的冷启动问题,甚至在跨数据集的 Zero-Shot 也有很好的表现,适用于新零售的全渠道 (Omni-Channel),并扩展增加输入的维度,例如视频和商品图等。
架构案例:多模态数据的模型训练
在下图中介绍了多模态数据管道在生命科学领域的参考部署架构。
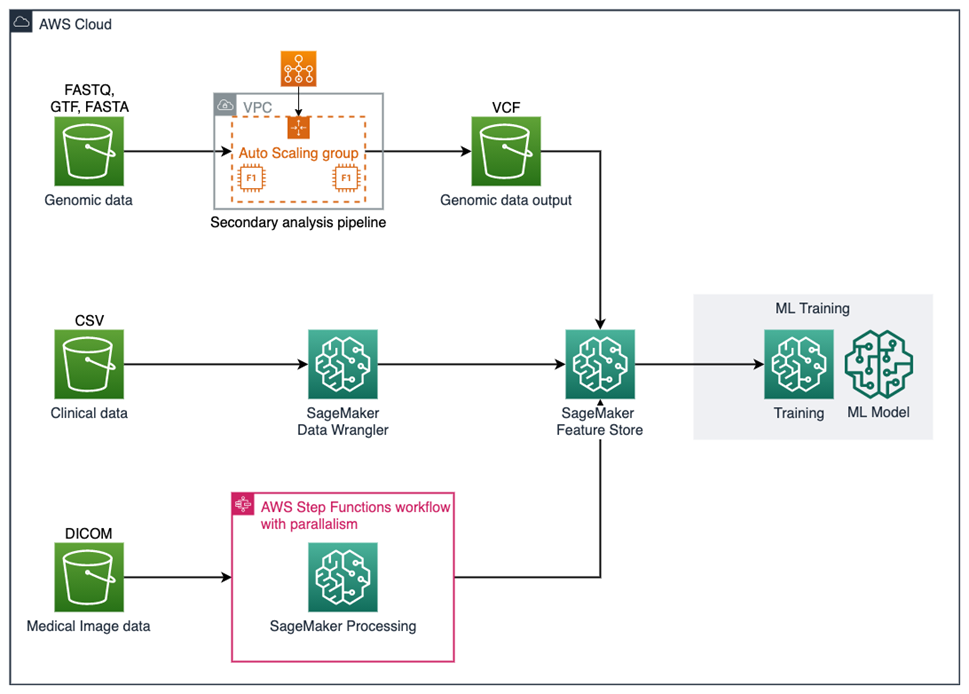
图片来源:官方博客《在 Amazon SageMaker 上使用多模态健康数据训练机器学习模型》
该架构将处理来自基因组数据、临床数据和医学成像数据,并将每种模式的处理功能加载到 Amazon SageMaker Feature Store 中。
这个案例展示了如何汇集来自不同模式的特征,并训练一个预测模型,该模型的性能优于在一种或两种数据模式上训练的模型。
我们会在后续文章中继续介绍有关分布式训练、无服务器推理,以及 JAX 框架的演进趋势,请持续关注 Build On Cloud 微信公众号。
随着机器学习的重要程度不断突显,以及相关技术研究的不断丰富,相信在未来围绕机器学习的技术将会逐渐完善,并以此赋能、推动人工智能等技术领域迎来更广阔的发展空间,造福人类。

作者黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
文章来源:https://dev.amazoncloud.cn/column/article/63e32a58e5e05b6ff897ca0c?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN