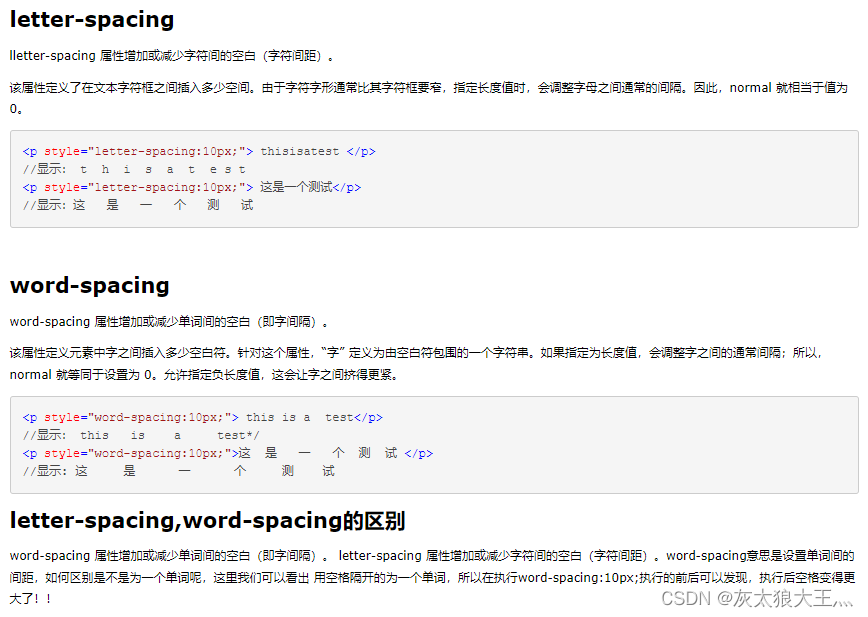
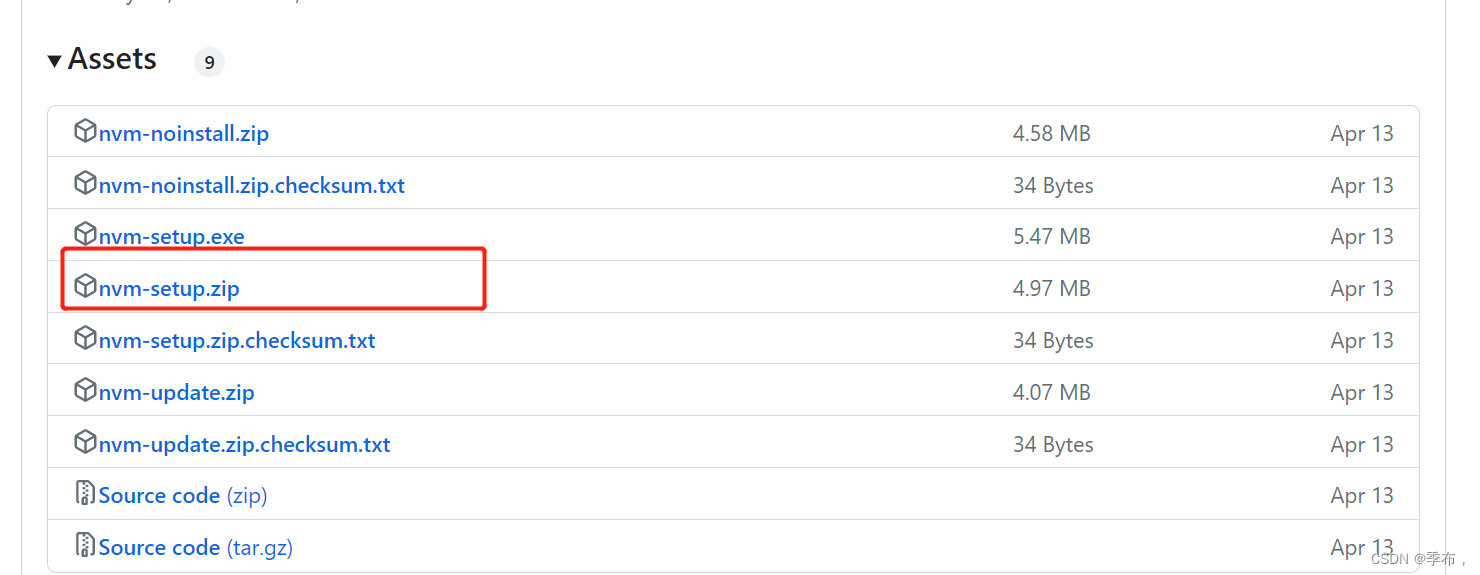
1. Nerf
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
2020年8月3日
(0)总结
NeRF工作的过程可以分成两部分:三维重建和渲染。(1)三维重建部分本质上是一个2D到3D的建模过程,利用3D点的位置(x,y,z)及方位视角(θ,φ)作为输入,通过多层感知机(MLP)建模该点对应的颜色color(c)及体素密度volume density(σ),形成了3D场景的”隐式表示“(2)渲染部分本质上是一个3D到2D的建模过程,渲染部分利用重建部分得到的3D点的颜色及不透明度沿着光线进行整合得到最终的2D图像像素值。在训练的时候,利用渲染部分得到的2D图像,通过与Ground Truth做L2损失函数(L2 Loss)进行网络优化
(1)摘要
我们提出了一种方法,通过使用稀疏的输入视图集优化底层连续体积场景函数,实现合成复杂场景的新颖视图的最先进的结果。我们的算法使用全连接(非卷积)深度网络表示场景,其输入是单个连续 5D 坐标(空间位置 (x; y; z) 和观察方向 (θ; φ)),其输出是体积密度以及该空间位置处与视图相关的发射辐射率。我们通过查询沿相机光线的 5D 坐标来合成视图,并使用经典的体积渲染技术将输出颜色和密度投影到图像中。由于体积渲染本质上是可微分的,因此优化表示所需的唯一输入是一组具有已知相机姿势的图像。我们描述了如何有效地优化神经辐射场,以渲染具有复杂几何和外观的场景的逼真新颖视图,并展示了优于神经渲染和视图合成先前工作的结果。查看合成结果最好以视频形式观看,因此我们敦促读者观看我们的补充视频以获得令人信服的比较。
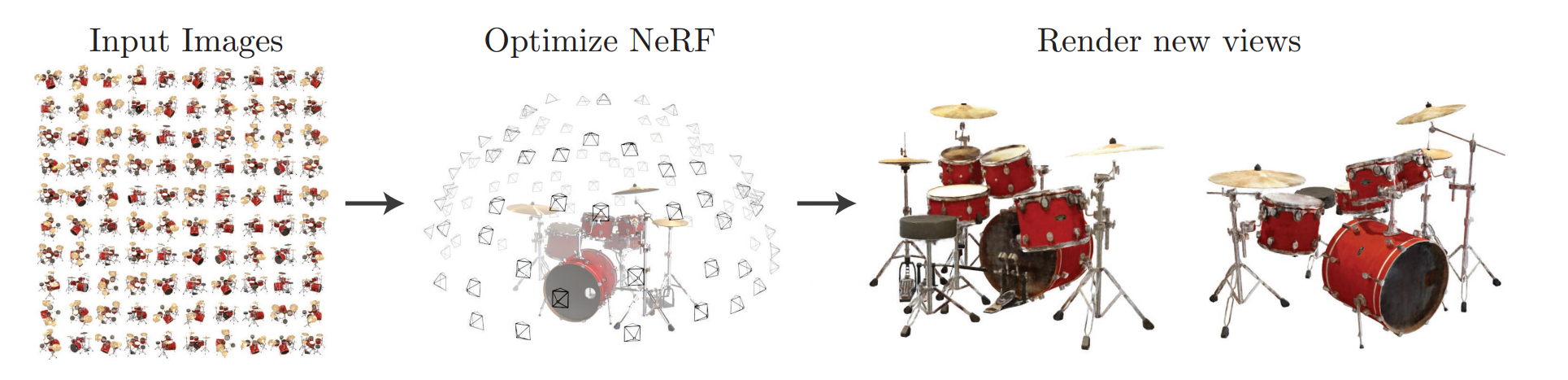
**图 1:**我们提出了一种方法,可以优化一组输入图像中场景的连续 5D 神经辐射场表示(任何连续位置处的体积密度和与视图相关的颜色)。我们使用体积渲染技术沿着光线累积该场景表示的样本,以从任何视点渲染场景。在这里,我们可视化了在周围半球上随机捕获的合成鼓场景的 100 个输入视图,并展示了根据优化的 NeRF 表示渲染的两个新颖视图。
(2)引言
在这项工作中,我们通过直接优化连续 5D 场景表示的参数,以一种新的方式解决长期存在的视图合成问题,以最大限度地减少渲染一组捕获图像的错误。
我们将静态场景表示为连续的 5D 函数,该函数输出空间中每个点 (x; y; z) 处每个方向 (θ; φ) 发射的辐射亮度,以及每个点的密度,其作用类似于如何控制变化的微分不透明度穿过 (x; y; z) 的光线会积累大量辐射。我们的方法优化了没有任何卷积层(通常称为多层感知器或 MLP)的深度全连接神经网络,通过从单个 5D 坐标 (x; y; z; θ; φ) 回归到单个 5D 坐标来表示该函数体积密度和与视图相关的 RGB 颜色。从特定视点渲染神经辐射场 (NeRF),我们:1) 使相机光线穿过场景以生成一组采样的 3D 点,2) 使用这些点及其相应的 2D 观看方向作为神经网络的输入来生成一组颜色和密度的输出,以及 3) 使用经典的体积渲染技术将这些颜色和密度累积成 2D 图像。因为这个过程自然是可微的,所以我们可以使用梯度下降来优化这个模型,通过最小化每个观察到的图像和从我们的表示呈现的相应视图之间的误差。跨多个视图最小化此错误可以鼓励网络通过向包含真实底层场景内容的位置分配高体积密度和准确的颜色来预测场景的连贯模型。图 2 直观地展示了整个管道。
我们发现,优化复杂场景的神经辐射场表示的基本实现并不能收敛到足够高分辨率的表示,并且在每条相机光线所需的样本数量方面效率低下。我们通过使用位置编码来转换输入 5D 坐标来解决这些问题,使 MLP 能够表示更高频率的函数,并且我们提出了一种分层采样过程来减少充分采样这种高频场景表示所需的查询数量。
我们的方法继承了体积表示的优点:两者都可以表示复杂的现实世界几何形状和外观,并且非常适合使用投影图像进行基于梯度的优化。至关重要的是,我们的方法克服了以高分辨率建模复杂场景时离散体素网格的高昂存储成本。总而言之,我们的技术贡献是:
(1) 一种将具有复杂几何形状和材料的连续场景表示为 5D 神经辐射场的方法,参数化为基本 MLP 网络。
(2)基于经典体积渲染技术的可微渲染程序,我们用它来优化标准 RGB 图像的这些表示。这包括分层采样策略,将 MLP 的容量分配给具有可见场景内容的空间。
(3)用于将每个输入 5D 坐标映射到更高维度空间的位置编码,这使我们能够成功优化神经辐射场以表示高频场景内容。
我们证明,我们得到的神经辐射场方法在数量和质量上都优于最先进的视图合成方法,包括将神经 3D 表示适合场景的工作以及训练深度卷积网络来预测采样体积表示的工作。据我们所知,本文提出了第一个连续神经场景表示,能够从自然环境中捕获的 RGB 图像中渲染真实物体和场景的高分辨率真实感新颖视图。
(3)相关工作
计算机视觉领域最近一个有前途的方向是在 MLP 的权重中对对象和场景进行编码,该权重直接从 3D 空间位置映射到形状的隐式表示,例如该位置处的符号距离 [6]。然而,到目前为止,这些方法无法以与使用离散表示(例如三角形网格或体素网格)表示场景的技术相同的保真度来再现具有复杂几何形状的现实场景。在本节中,我们回顾这两条工作,并将它们与我们的方法进行对比,该方法增强了神经场景表示的能力,以产生渲染复杂现实场景的最先进的结果。
使用 MLP 从低维坐标映射到颜色的类似方法也已用于表示其他图形函数,例如图像 [44]、纹理材料 [12,31,36,37] 和间接照明值 [38] 。
略
(4-1)模型结构:神经辐射场场景表示
我们将连续场景表示为 5D 向量值函数,其输入是 3D 位置 x = (x; y; z) 和 2D 观看方向 (θ; φ),其输出是发射颜色 c = (r; g ;b) 和体积密度 σ。在实践中,我们将方向表示为 3D 笛卡尔单位向量 d。我们用 MLP 网络 Fθ 来近似这个连续的 5D 场景表示: ( x , d ) → ( c , σ ) (\mathbf{x}, \mathbf{d}) \rightarrow(\mathbf{c}, \sigma) (x,d)→(c,σ) 并优化其权重 θ,以从每个输入 5D 坐标映射到其相应的体积密度和定向发射颜色。
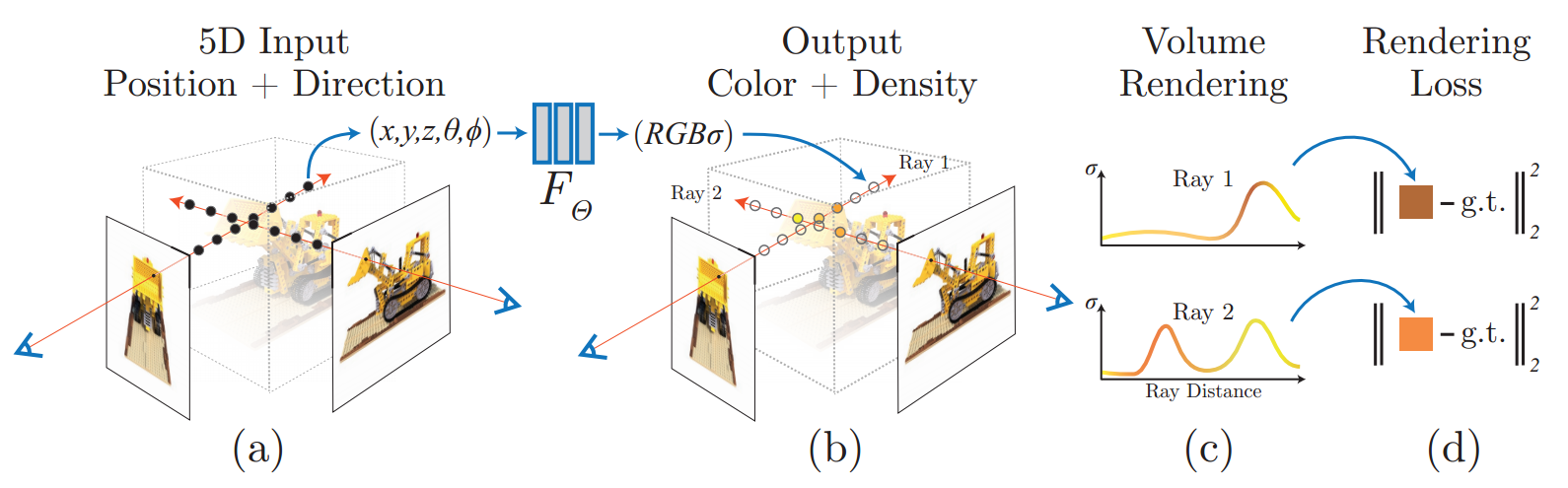
图 2:我们的神经辐射场场景表示和可微渲染过程的概述。我们通过沿相机光线采样 5D 坐标(位置和观察方向)来合成图像 (a),将这些位置输入 MLP 以生成颜色和体积密度 (b),并使用体积渲染技术将这些值合成为图像 ( C)。该渲染函数是可微分的,因此我们可以通过最小化合成图像和地面真实观察图像之间的残差来优化场景表示(d)。
我们通过限制网络将体积密度 σ 预测为仅位置 x 的函数,同时允许将 RGB 颜色 c 预测为位置和观察方向的函数,从而鼓励表示实现多视图一致。为了实现这一点,MLP Fθ 首先使用 8 个全连接层(使用 ReLU 激活和每层 256 个通道)处理输入 3D 坐标 x,并输出 σ 和 256 维特征向量。然后,该特征向量与相机光线的观看方向连接,并传递到一个额外的全连接层(使用 ReLU 激活和 128 个通道),该层输出与视图相关的 RGB 颜色。
请参阅图 3,了解我们的方法如何使用输入观看方向来表示非朗伯效应的示例。如图 4 所示,在没有视图依赖性(仅 x 作为输入)的情况下训练的模型难以表示镜面反射。
(4-2)模型结构:具有辐射场的体渲染
我们的 5D 神经辐射场将场景表示为空间中任意点的体积密度和定向发射辐射度。我们使用经典体积渲染 [16] 的原理来渲染穿过场景的任何光线的颜色。体积密度 σ(x) 可以解释为射线终止于位置 x 处的无穷小粒子的微分概率。具有近边界和远边界 tn 和 tf 的相机光线 r(t) = o + td 的预期颜色 C® 为:
C
(
r
)
=
∫
t
n
t
f
T
(
t
)
σ
(
r
(
t
)
)
c
(
r
(
t
)
,
d
)
d
t
,
where
T
(
t
)
=
exp
(
−
∫
t
n
t
σ
(
r
(
s
)
)
d
s
)
C(\mathbf{r})=\int_{t_{n}}^{t_{f}} T(t) \sigma(\mathbf{r}(t)) \mathbf{c}(\mathbf{r}(t), \mathbf{d}) d t, \text { where } T(t)=\exp \left(-\int_{t_{n}}^{t} \sigma(\mathbf{r}(s)) d s\right)
C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dt, where T(t)=exp(−∫tntσ(r(s))ds)
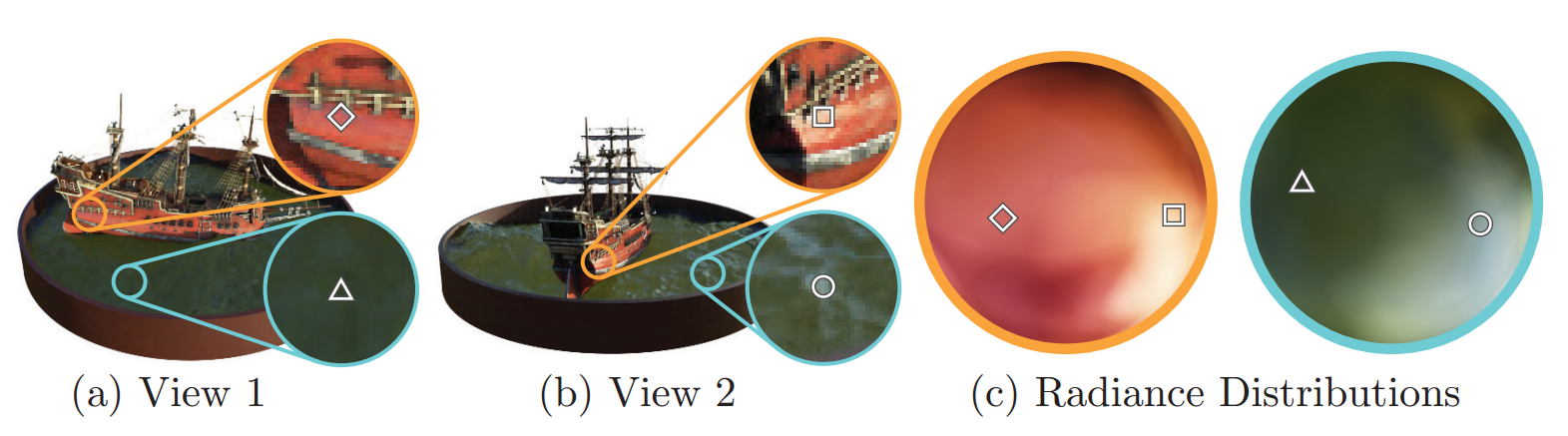
图 3:与视图相关的发射辐射的可视化。我们的神经辐射场表示将 RGB 颜色输出为空间位置 x 和观察方向 d 的 5D 函数。在这里,我们可视化船舶场景的神经表示中两个空间位置的示例方向颜色分布。在 (a) 和 (b) 中,我们展示了来自两个不同相机位置的两个固定 3D 点的外观:一个位于船侧(橙色插图),一个位于水面(蓝色插图)。我们的方法预测这两个 3D 点的镜面反射外观的变化,并且在 © 中我们展示了这种行为如何在整个观察方向半球上持续推广。
函数 T(t) 表示光线从 tn 到 t 的累积透射率,即光线从 tn 传播到 t 而不撞击任何其他粒子的概率。从我们的连续神经辐射场渲染视图需要估计通过所需虚拟相机的每个像素追踪的相机光线的积分 C®。
我们使用求积法对这个连续积分进行数值估计。确定性求积通常用于渲染离散体素网格,它会有效地限制我们表示的分辨率,因为 MLP 只能在一组固定的离散位置进行查询。相反,我们使用分层抽样方法来划分 [tn; tf ] 放入 N 个均匀间隔的 bin 中,然后从每个 bin 内均匀随机抽取一个样本:
t
i
∼
U
[
t
n
+
i
−
1
N
(
t
f
−
t
n
)
,
t
n
+
i
N
(
t
f
−
t
n
)
]
t_{i} \sim \mathcal{U}\left[t_{n}+\frac{i-1}{N}\left(t_{f}-t_{n}\right), t_{n}+\frac{i}{N}\left(t_{f}-t_{n}\right)\right]
ti∼U[tn+Ni−1(tf−tn),tn+Ni(tf−tn)]
尽管我们使用一组离散样本来估计积分,但分层采样使我们能够表示连续的场景表示,因为它会导致在优化过程中在连续位置评估 MLP。我们使用这些样本通过 Max [26] 的体积渲染评论中讨论的求积规则来估计 C®:
C
^
(
r
)
=
∑
i
=
1
N
T
i
(
1
−
exp
(
−
σ
i
δ
i
)
)
c
i
,
where
T
i
=
exp
(
−
∑
j
=
1
i
−
1
σ
j
δ
j
)
\hat{C}(\mathbf{r})=\sum_{i=1}^{N} T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) \mathbf{c}_{i}, \text { where } T_{i}=\exp \left(-\sum_{j=1}^{i-1} \sigma_{j} \delta_{j}\right)
C^(r)=i=1∑NTi(1−exp(−σiδi))ci, where Ti=exp(−j=1∑i−1σjδj)
其中
δ
i
=
t
i
+
1
−
t
i
\delta_{i}=t_{i+1}-t_{i}
δi=ti+1−ti 是相邻样本之间的距离。这个用于从
(
c
i
,
σ
i
)
\left(\mathbf{c}_{i}, \sigma_{i}\right)
(ci,σi) 值集合计算
C
^
(
r
)
\hat{C}(\mathbf{r})
C^(r) 的函数是微可微的,并且可简化为具有 alpha 值
α
i
=
1
−
exp
(
−
σ
i
δ
i
)
\alpha_{i}=1-\exp \left(-\sigma_{i} \delta_{i}\right)
αi=1−exp(−σiδi) 的传统 alpha 合成。

图 4:在这里,我们直观地看到了我们的完整模型如何从表示视点相关的发射辐射率以及通过高频位置编码传递输入坐标中受益。消除视图依赖性可防止模型在推土机履带上重新创建镜面反射。删除位置编码会大大降低模型表示高频几何和纹理的能力,导致外观过于平滑。
(4-3)模型结构:优化神经辐射场
在上一节中,我们描述了将场景建模为神经辐射场并根据该表示渲染新视图所需的核心组件。然而,我们发现这些组件不足以实现最先进的质量,如第 6.4 节所示)。我们引入了两项改进来能够表示高分辨率的复杂场景。第一个是输入坐标的位置编码,帮助 MLP 表示高频函数;第二个是分层采样过程,使我们能够有效地对这种高频表示进行采样。
(4-3-1)位置编码
尽管神经网络是通用函数逼近器[14],但我们发现让网络 Fθ 直接在 xyzθφ 输入坐标上运行会导致渲染在表示颜色和几何的高频变化方面表现不佳。这与 Rahaman 等人最近的工作[35]一致,该工作表明深度网络偏向于学习低频函数。他们还表明,在将输入传递到网络之前使用高频函数将输入映射到更高维度的空间可以更好地拟合包含高频变化的数据。
我们在神经场景表示的背景下利用这些发现,并表明将 Fθ 重新表述为两个函数
F
Θ
=
F
Θ
′
∘
γ
F_{\Theta}=F_{\Theta}^{\prime} \circ \gamma
FΘ=FΘ′∘γ (一个已学习,一个未学习)的组合,可显着提高性能(见图 4 和表 2)。这里γ是从
R
\mathbb{R}
R 到更高维空间
R
2
L
\mathbb{R}^{2L}
R2L 的映射,并且
F
Θ
′
F_{\Theta}^{\prime}
FΘ′ 仍然是简单的常规MLP。形式上,我们使用的编码函数是:
γ
(
p
)
=
(
sin
(
2
0
π
p
)
,
cos
(
2
0
π
p
)
,
⋯
,
sin
(
2
L
−
1
π
p
)
,
cos
(
2
L
−
1
π
p
)
)
\gamma(p)=\left(\sin \left(2^{0} \pi p\right), \cos \left(2^{0} \pi p\right), \cdots, \sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right)
γ(p)=(sin(20πp),cos(20πp),⋯,sin(2L−1πp),cos(2L−1πp))
该函数 γ(·) 分别应用于 x 中的三个坐标值中的每一个(它们被归一化为 [−1; 1])以及笛卡尔观察方向单位向量 d 的三个分量(通过构造,它们位于在[−1; 1]中)。在我们的实验中,我们将
γ
(
x
)
\gamma(x)
γ(x) 设置为 L = 10,将
γ
(
d
)
\gamma(d)
γ(d) 设置为 L = 4。
流行的 Transformer 架构 [47] 中使用了类似的映射,称为位置编码。然而,Transformers 将其用于不同的目标,即提供序列中令牌的离散位置作为不包含任何顺序概念的架构的输入。相反,我们使用这些函数将连续输入坐标映射到更高维度的空间,以使我们的 MLP 能够更轻松地逼近更高频率的函数。针对从投影建模 3D 蛋白质结构的相关问题的同时工作 [51] 也利用了类似的输入坐标映射。
(4-3-2)分层体积采样
我们沿着每条相机射线在 N 个查询点处密集评估神经辐射场网络的渲染策略效率很低:对渲染图像没有贡献的自由空间和遮挡区域仍然被重复采样。我们从体积渲染的早期工作中汲取灵感[20],并提出了一种分层表示,通过根据最终渲染的预期效果按比例分配样本来提高渲染效率。
我们不只是使用单个网络来表示场景,而是同时优化两个网络:一个“coarse”和一个“fine”。我们首先使用分层采样对一组 Nc 位置进行采样,并按照方程 2 和 3 中所述评估这些位置处的“粗”网络。给定此“粗”网络的输出,然后我们生成更明智的点采样沿着每条射线,样本偏向体积的相关部分。为此,我们首先重写等式中粗网络
C
^
c
(
r
)
\hat{C}_{c}(\mathbf{r})
C^c(r)的 alpha 合成颜色。公式 3 作为沿射线的所有采样颜色 ci 的加权和:
C
^
c
(
r
)
=
∑
i
=
1
N
c
w
i
c
i
,
w
i
=
T
i
(
1
−
exp
(
−
σ
i
δ
i
)
)
\hat{C}_{c}(\mathbf{r})=\sum_{i=1}^{N_{c}} w_{i} c_{i}, \quad w_{i}=T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right)
C^c(r)=i=1∑Ncwici,wi=Ti(1−exp(−σiδi))
将这些权重标准化为
w
^
i
=
w
i
/
∑
j
=
1
N
c
w
j
\hat{w}_{i}=w_{i} / \sum_{j=1}^{N_{c}} w_{j}
w^i=wi/∑j=1Ncwj 会产生沿射线的分段常数 PDF。我们使用逆变换采样从该分布中采样第二组 Nf 位置,在第一组和第二组样本的并集处评估我们的“fine”网络,并使用 公式3 计算光线
C
^
f
(
r
)
\hat{C}_{f}(\mathbf{r})
C^f(r) 的最终渲染颜色. 但使用所有 Nc+Nf 样本。此过程将更多样本分配给我们期望包含可见内容的区域。这解决了与重要性采样类似的目标,但我们使用采样值作为整个积分域的非均匀离散化,而不是将每个样本视为整个积分的独立概率估计。
(4-3-3)实施细节
我们为每个场景优化单独的神经连续体积表示网络。这仅需要捕获的场景 RGB 图像、相应的相机姿态和内在参数以及场景边界的数据集(我们使用地面实况相机姿态、内在参数和合成数据的边界,并使用 COLMAP 结构从运动包[39]估计真实数据的这些参数)。在每次优化迭代中,我们从数据集中的所有像素集中随机采样一批相机光线,然后遵循第 2 节中描述的分层采样。 5.2 从粗网络查询 Nc 样本,从精细网络查询 Nc + Nf 样本。然后我们使用第 2 节中描述的体积渲染过程。 4 渲染两组样本中每条光线的颜色。我们的损失只是粗略渲染和精细渲染的渲染像素颜色和真实像素颜色之间的总平方误差:
L
=
∑
r
∈
R
[
∥
C
^
c
(
r
)
−
C
(
r
)
∥
2
2
+
∥
C
^
f
(
r
)
−
C
(
r
)
∥
2
2
]
\mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}\left[\left\|\hat{C}_{c}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}+\left\|\hat{C}_{f}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}\right]
L=r∈R∑[
C^c(r)−C(r)
22+
C^f(r)−C(r)
22]
其中 R 是每个批次中的光线集合,C®、
C
^
c
(
r
)
\hat{C}_{c}(\mathbf{r})
C^c(r)和
C
^
f
(
r
)
\hat{C}_{f}(\mathbf{r})
C^f(r)分别是光线 r 的地面实况、粗略体积预测和精细体积预测 RGB 颜色。请注意,即使最终渲染来自
C
^
f
(
r
)
\hat{C}_{f}(\mathbf{r})
C^f(r),我们也最小化
C
^
c
(
r
)
\hat{C}_{c}(\mathbf{r})
C^c(r) 的损失,以便粗网络的权重分布可以用于在精细网络中分配样本。
在我们的实验中,我们使用 4096 条射线的批量大小,每条射线在粗体积中的 Nc = 64 个坐标和精细体积中的 Nf = 128 个附加坐标处采样。我们使用 Adam 优化器 [18],其学习率从 5 × 10−4 开始,并在优化过程中以指数方式衰减到 5 × 10−5(其他 Adam 超参数保留默认值 β1 = 0:9, β2 = 0:999, 且 = 10−7 )。单个场景的优化通常需要大约 100-300k 次迭代才能在单个 NVIDIA V100 GPU 上收敛(大约 1-2 天)。