文章目录
- 一、RabbitMQ集群概述
- 1、为什么要使用RabbitMQ集群
- 2、RabbitMQ如何支持集群
- 3、RabbitMQ的节点类型
- 二、普通集群
- 1、什么是普通集群
- 2、Docker搭建普通集群模式
- (1)安装docker
- (2)安装RabbitMQ
- (3)检验集群
- (4)设置用户
- (5)删除集群节点(node2 和 node3 机器分别执行,这里不需要操作)
- (6)访问控制台
- 三、镜像队列
- 四、Haproxy+Keepalive 实现高可用集群
- 五、Federation的使用
- 六、Shovel的使用
- 参考资料
一、RabbitMQ集群概述
1、为什么要使用RabbitMQ集群
集群主要用于实现高可用与负载均衡。
高可用:如果集群中的某些MQ服务器不可用,客户端还可以连接到其他MQ服务器,不至于影响业务。
负载均衡:在高并发的场景下,单台MQ服务器能处理的消息有限,可以分发给多台MQ服务器,减少消息延迟。
2、RabbitMQ如何支持集群
应用做集群,需要面对数据同步和通信的问题。因为Erlang天生具备分布式的特性,所以RabbitMQ天然支持集群,不需要通过引入ZK来实现数据同步。
RabbitMQ通过.erlang.cookie(默认路径:/var/lib/rabbitmq/)来验证身份,需要在所有节点上保持一致。
服务的端口是5672,UI的端口是15672,集群的端口是25672。
集群通过25672端口两两通信,需要开放防火墙的端口。
需要注意的事,RabbitMQ集群无法搭建在广域网上,除非使用federation或者shovel等插件(没有必要这么做)。
3、RabbitMQ的节点类型
RabbitMQ的集群有两种节点类型,一种是磁盘节点(Disc Node),一种是内存节点(RAM Mode)。
磁盘节点:将元数据(包括队列名字属性、交换机的类型名字属性、绑定、vhost)放在磁盘中。未指定类型的情况下,默认为磁盘节点。

集群中至少需要一个磁盘节点用来持久化元数据,否则全部内存节点崩溃时,就无从同步元数据。
内存节点:将元数据存储在内存中。内存节点会将磁盘节点的地址存放在磁盘(不然重启后就没办法同步数据了)。如果是持久化的消息,会同时存放在内存和磁盘。
我们一般把应用连接到内存节点(读写快),磁盘节点用来备份。
二、普通集群
1、什么是普通集群
普通集群模式下,不同的节点之间只会相互同步元数据(交换机、队列、绑定关系、vhost的定义),而不会同步消息。
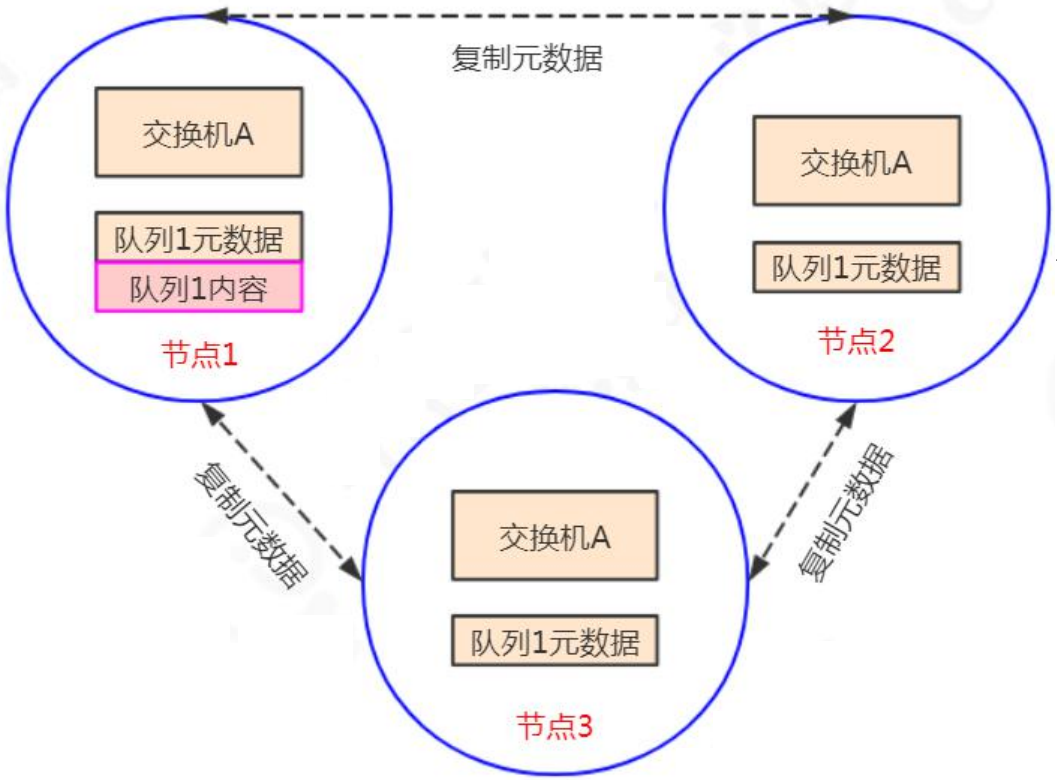
比如,队列1的消息只存储在节点1上。节点2和节点3同步了队列1的定义,但是没有同步消息。
假如生产者连接的是节点3,要将消息通过交换机A路由到队列1,最终消息还是会转发到节点1上存储,因为队列1的内容只在节点1上。
同理,如果消费者连接的是节点2,要从队列1上拉取消息,消息会从节点1转发到节点2,其他节点起到一个路由的作用,类似于指针。
普通集群模式就会有一个问题,如果节点1挂了,队列1的所有数据全部就丢失了。为什么不直接把消息在所有节点上复制一份?主要是出于存储和同步数据的网络开销的考虑,如果所有节点都存储相同的数据,就无法达到线性地增加性能和存储容量的目的(堆机器)。
这也是一个分片存储的思想。当然,如果需要保证队列的高可用,就不能用普通集群模式了,因为节点失效将导致相关队列不可用,这就需要镜像队列模式了。
2、Docker搭建普通集群模式
(1)安装docker
centos7安装与卸载docker-简单而详细无坑
(2)安装RabbitMQ
# 1)拉取RabbitMQ镜像(带managment)
docker pull rabbitmq:3.7.17-management
# 2)创建docker网络(让容器可以和主机通信)
docker network create rabbitmqnet
# 3)创建三个容器,端口分别是 5673 5674 5675 ,管理端口是 15673 15674 15675
docker run -d \
--name=rabbitmq1 \
-p 5673:5672 \
-p 15673:15672 \
-e RABBITMQ_NODENAME=rabbitmq1 \
-e RABBITMQ_ERLANG_COOKIE='GUPAOEDUFORBETTERYOU' \
-h rabbitmq1 \
--net=rabbitmqnet \
rabbitmq:3.7.17-management
docker run -d \
--name=rabbitmq2 \
-p 5674:5672 \
-p 15674:15672 \
-e RABBITMQ_NODENAME=rabbitmq1 \
-e RABBITMQ_ERLANG_COOKIE='GUPAOEDUFORBETTERYOU' \
-h rabbitmq2 \
--net=rabbitmqnet \
rabbitmq:3.7.17-management
docker run -d \
--name=rabbitmq3 \
-p 5675:5672 \
-p 15675:15672 \
-e RABBITMQ_NODENAME=rabbitmq1 \
-e RABBITMQ_ERLANG_COOKIE='GUPAOEDUFORBETTERYOU' \
-h rabbitmq3 \
--net=rabbitmqnet \
rabbitmq:3.7.17-management
# 4)后两个节点作为内存节点加入集群
docker exec -it rabbitmq2 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbitmq1@rabbitmq1
rabbitmqctl start_app
docker exec -it rabbitmq3 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbitmq1@rabbitmq1
rabbitmqctl start_app
(3)检验集群
# 集群状态
root@rabbitmq3:/# rabbitmqctl cluster_status
Cluster status of node rabbitmq1@rabbitmq3 ...
[{nodes,[{disc,[rabbitmq1@rabbitmq1]},
{ram,[rabbitmq1@rabbitmq3,rabbitmq1@rabbitmq2]}]},
{running_nodes,[rabbitmq1@rabbitmq2,rabbitmq1@rabbitmq1,rabbitmq1@rabbitmq3]},
{cluster_name,<<"rabbitmq1@rabbitmq3">>},
{partitions,[]},
{alarms,[{rabbitmq1@rabbitmq2,[]},
{rabbitmq1@rabbitmq1,[]},
{rabbitmq1@rabbitmq3,[]}]}]
(4)设置用户
# 创建账号
rabbitmqctl add_user admin admin
# 设置用户角色
rabbitmqctl set_user_tags admin administrator
# 设置用户权限
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"
(5)删除集群节点(node2 和 node3 机器分别执行,这里不需要操作)
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl cluster_status
rabbitmqctl forget_cluster_node rabbit@rabbitmq2 #(node1 机器上执行)
(6)访问控制台
http://192.168.8.146:15673/
admin/admin

我们在1节点新建交换机和队列,发现2节点和3节点会将交换机和队列同步过去。
往1节点发送一条消息,消费任意节点也能消费掉。
三、镜像队列
镜像队列模式下,消息内容会在镜像节点间同步,可用性更高。不过也有一定的副作用,系统性能会降低,节点过多的情况下同步的代价比较大。
集群模式可以通过UI或CLI或者HTTP操作。
命令方式:
rabbitmqctl set_policy ha-all "^ha." "{""ha-mode"":""all""}"
HTTP方式:
PUT /api/policies/%2f/ha-all {"pattern":"^ha.","definition":{"ha-mode":"all"}}
UI方式:
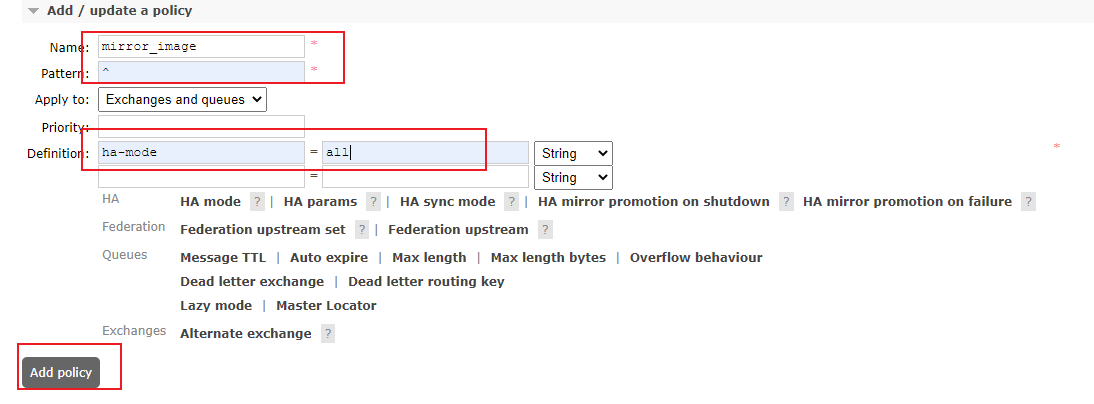
四、Haproxy+Keepalive 实现高可用集群
未完待续
五、Federation的使用
未完待续
六、Shovel的使用
未完待续
参考资料
https://gper.club/articles/7e7e7f7ff3g5bgc5g6c








![[C语言][小游戏][猜拳游戏]](https://img-blog.csdnimg.cn/8d9cebd0b7e6408ba0e5ddd973a8cfcb.jpeg)
