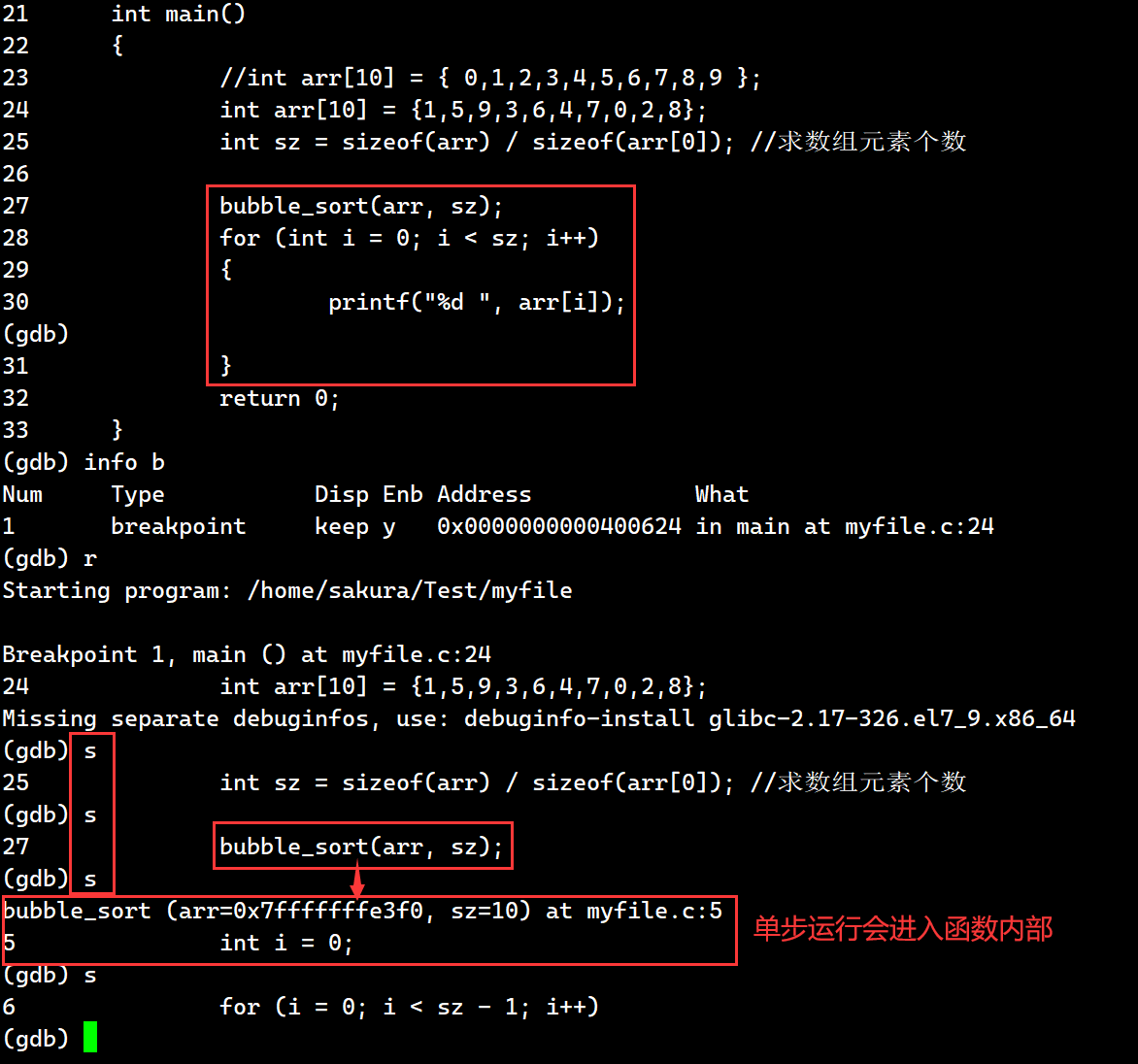
目录
- Introduction 导言
- 赛题背景
- 任务描述
- 数据探索分析
- 核心思路
- 数据预处理
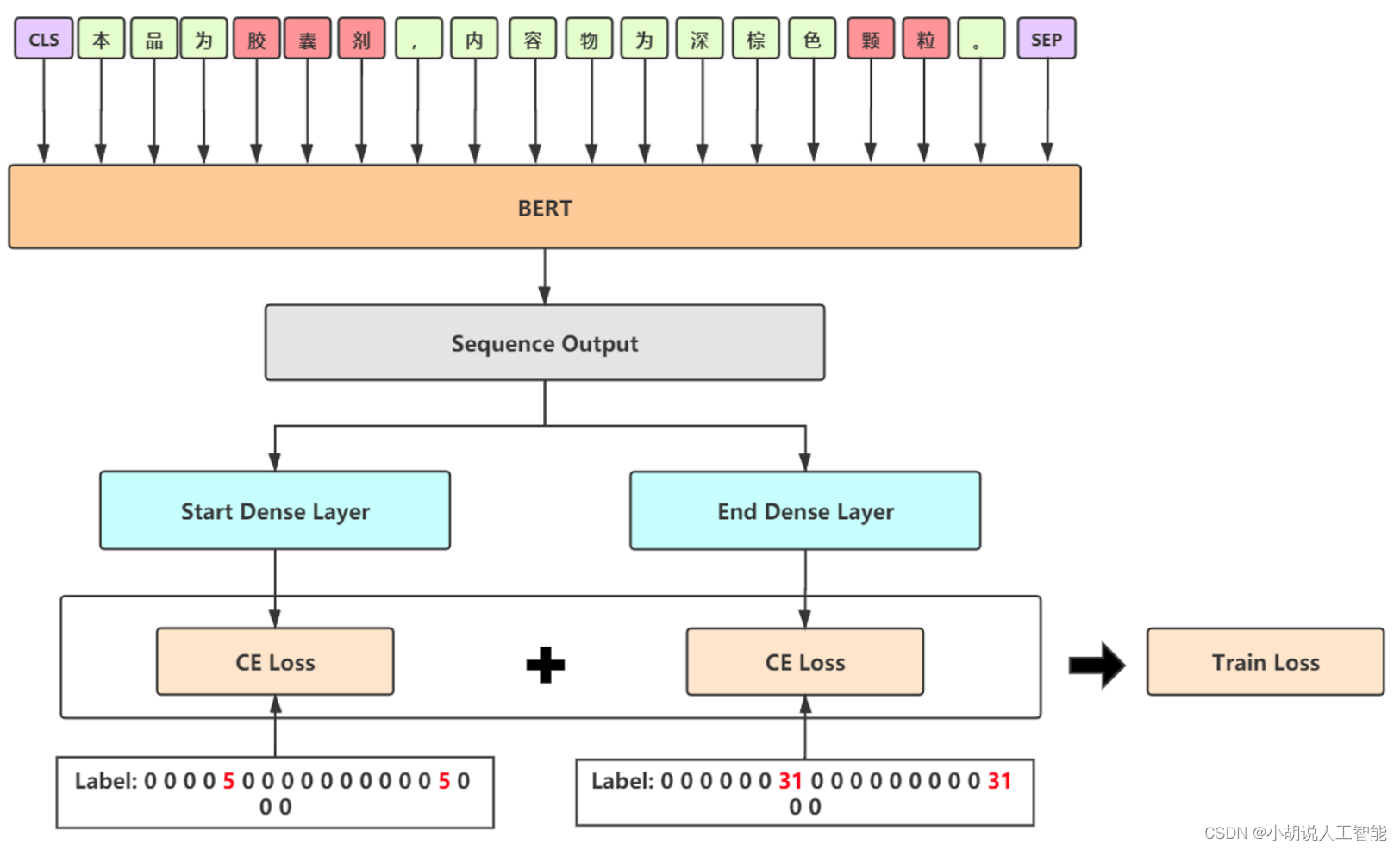
- Baseline: BERT-CRF
- 优化1:对抗训练
- 优化2:混合精度训练(FP16)
- 优化3:多模型融合
- 优化4:半监督学习
- 其他无明显提升的尝试方案
- 最终线上成绩72.90%,复赛Rank 1,决赛Rank 1
- 参考资料
- 其它资料下载
Introduction 导言
人工智能对中医药领域的传承和创新发展起到了重要的加速作用。其中,中医药文本信息的抽取是构建中医药知识图谱的核心组成部分,为上层应用如临床辅助诊疗系统(CDSS)的构建奠定了基础。
在本次NER挑战中,我们的目标是从中药药品说明书中提取关键信息,包括药品、药物成分、疾病、症状、证候等13类实体,并构建中医药药品的知识库。
通过应用自然语言处理和深度学习技术,我们可以对中药药品说明书进行语义分析和实体抽取。通过训练模型,我们可以识别和提取药品名称、药物成分、相关疾病、症状、证候等重要信息,并将其存储到中医药药品知识库中。
构建中医药药品知识库对于推动中医药的研究和临床实践具有重要意义。这个知识库可以为中医药研究人员和临床医生提供方便快捷的参考信息,帮助他们深入了解中药的特性、功效和应用范围。同时,该知识库也为中医药领域的智能化应用提供了数据基础,如CDSS系统的构建和其他医疗决策支持系统。
本次开源的项目是天池中药说明书实体识别挑战冠军方案Cinese-DeepNER-Pytorch。
赛题背景
任务描述
人工智能在中医药领域的传承创新发展中发挥了重要作用,其中,中医药文本的信息抽取是构建中医药知识图谱的核心组成部分。这对于构建上层应用,例如临床辅助诊疗系统(CDSS)等提供了基础。本次命名实体识别(NER)挑战的目标是从中药药品说明书中提取关键信息,包括药品、药物成分、疾病、症状、证候等13类实体,以构建中医药药品知识库。
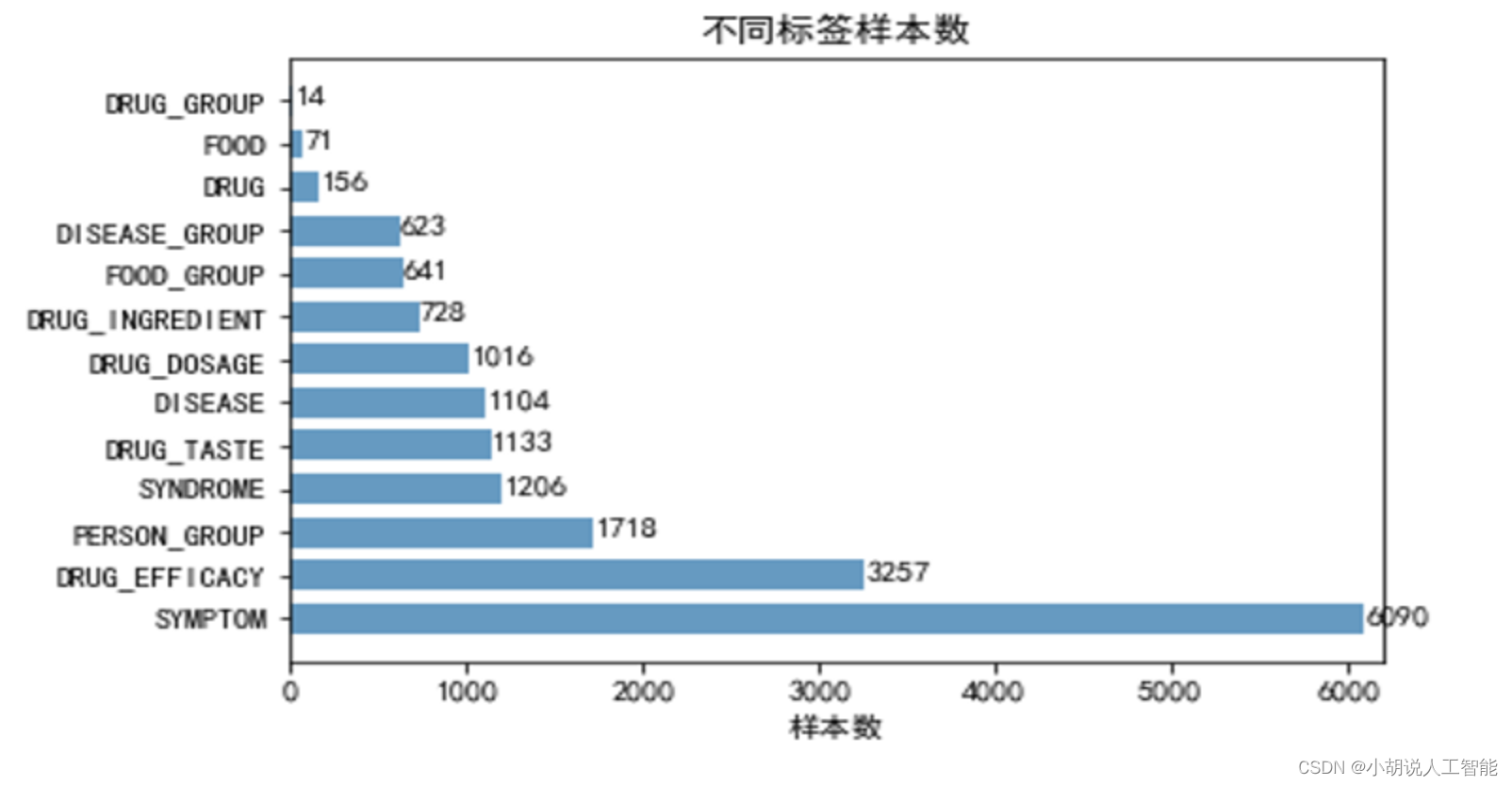
数据探索分析
本次竞赛训练数据有三个特点:
- 大部分中药药品说明书是以长文本的形式呈现的。
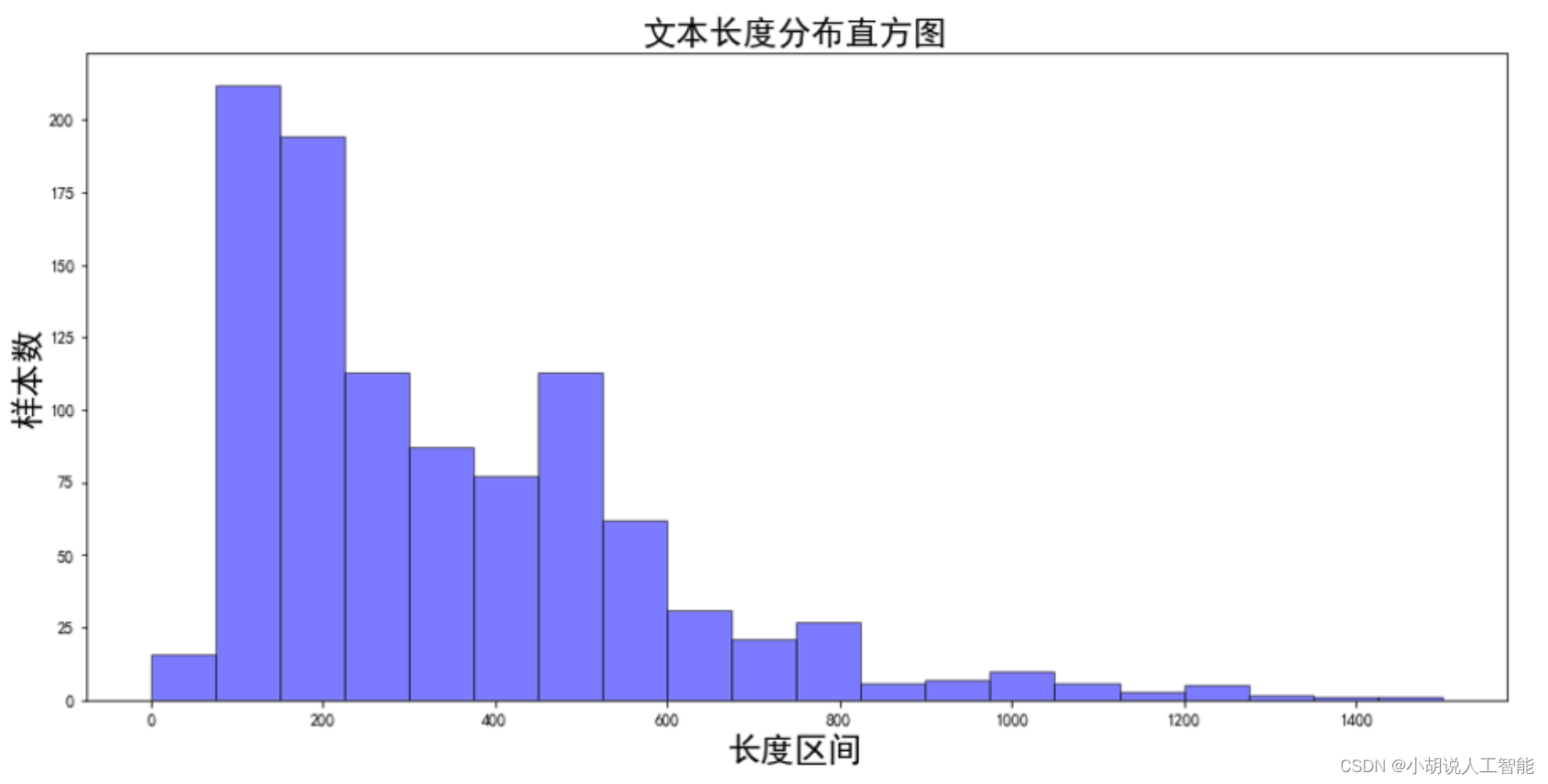
- 在医疗场景下,我们常常面临标注样本不足的挑战
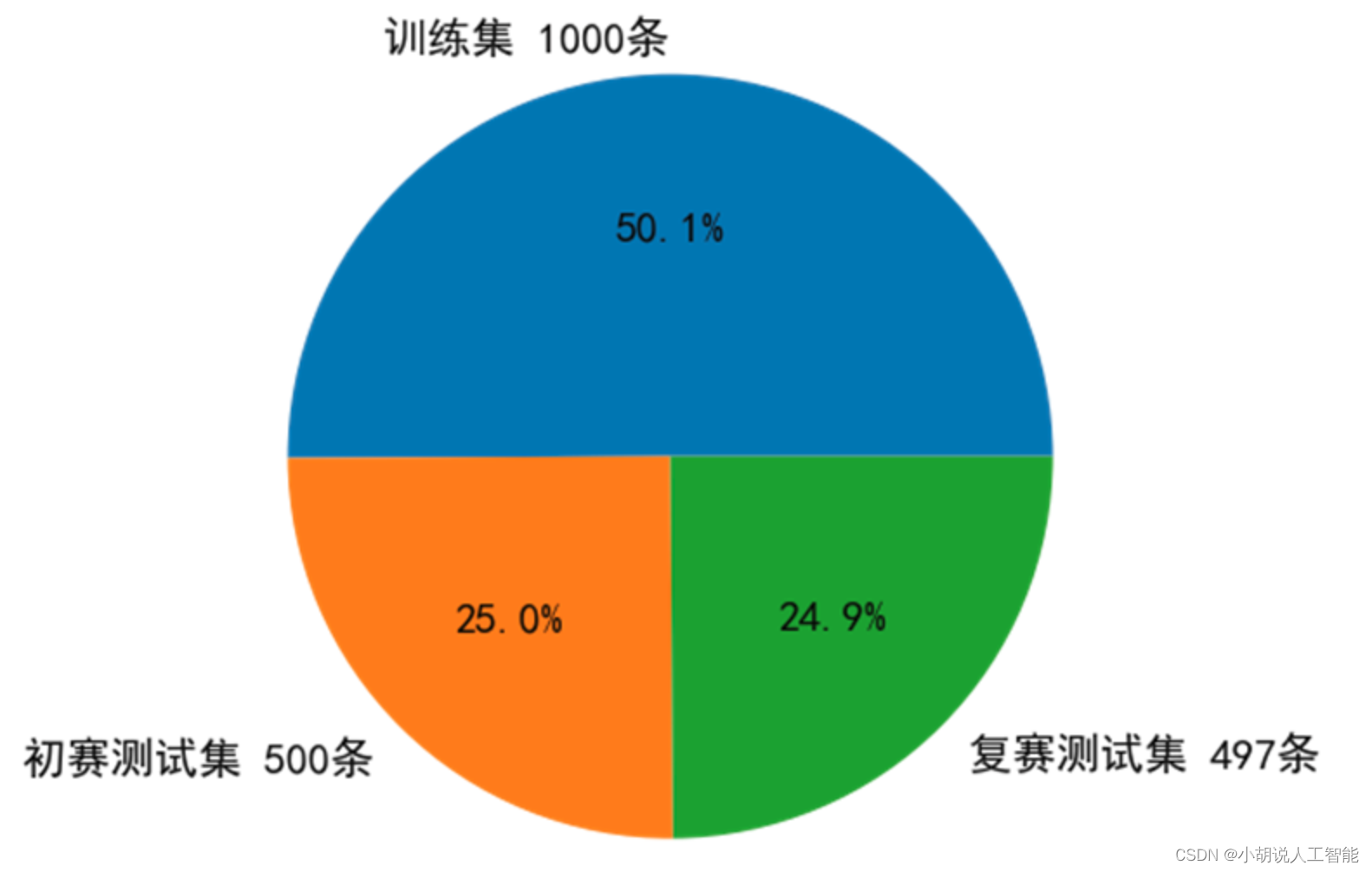
- 在医疗领域,标签的分布通常呈现不平衡状态。
核心思路
数据预处理
首先,对于说明书文本,我们需要进行预清洗和长文本切分的处理。预清洗阶段的目标是过滤掉无效字符,确保文本的准确性和可用性。针对长文本问题,我们采用了两级文本切分策略。通过将长文本分割成较短的句子,可以更好地处理和理解文本内容。
然而,由于切分后的句子可能过短,我们需要将短文本进行归并,以确保归并后的文本长度不超过预设的最大长度。这样可以保持文本的连贯性和完整性。
此外,我们还可以利用全部标注数据构建实体知识库,作为领域的先验词典。这样的知识库可以提供有关实体的信息和上下文,为后续的实体抽取任务提供有力支持和参考。
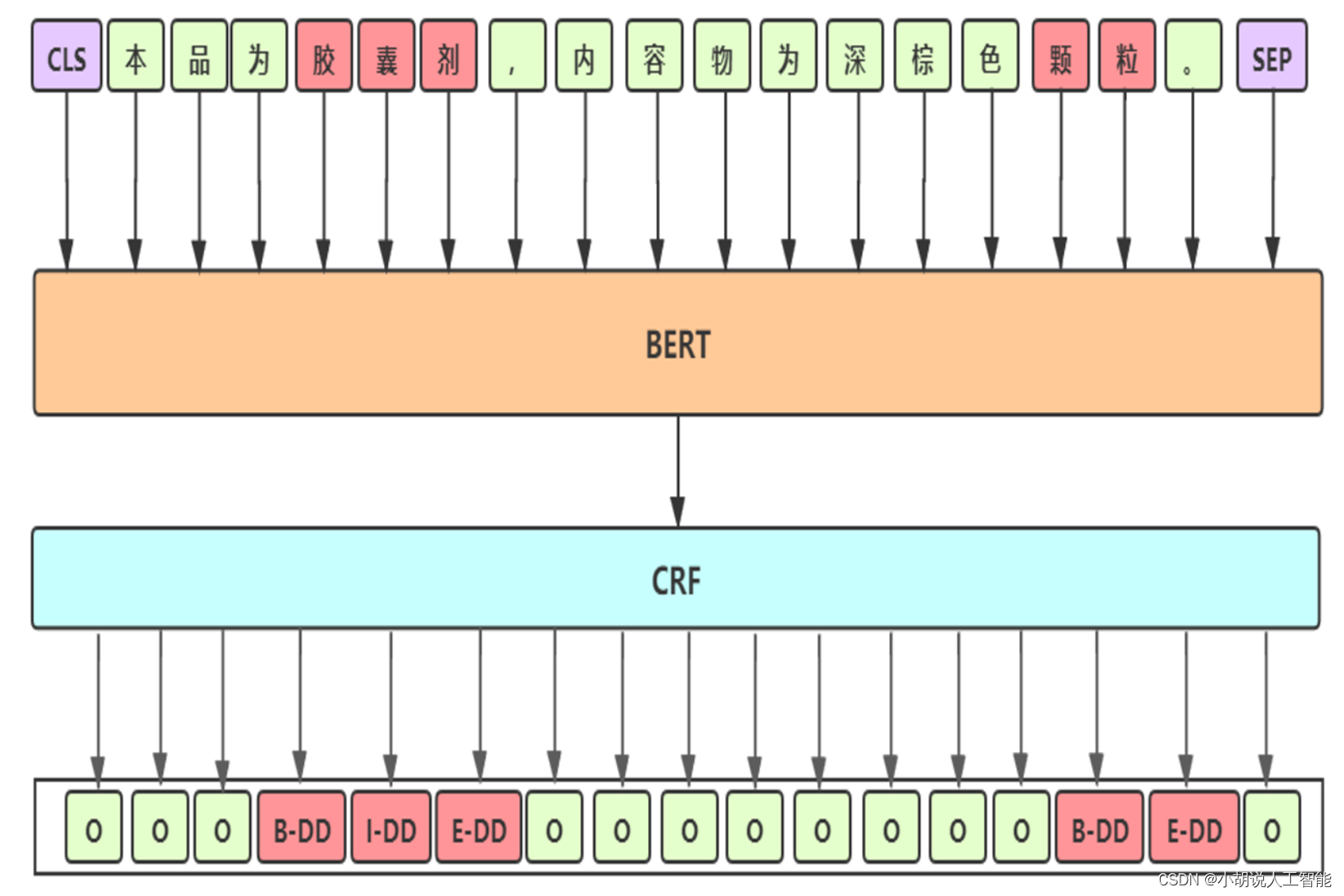
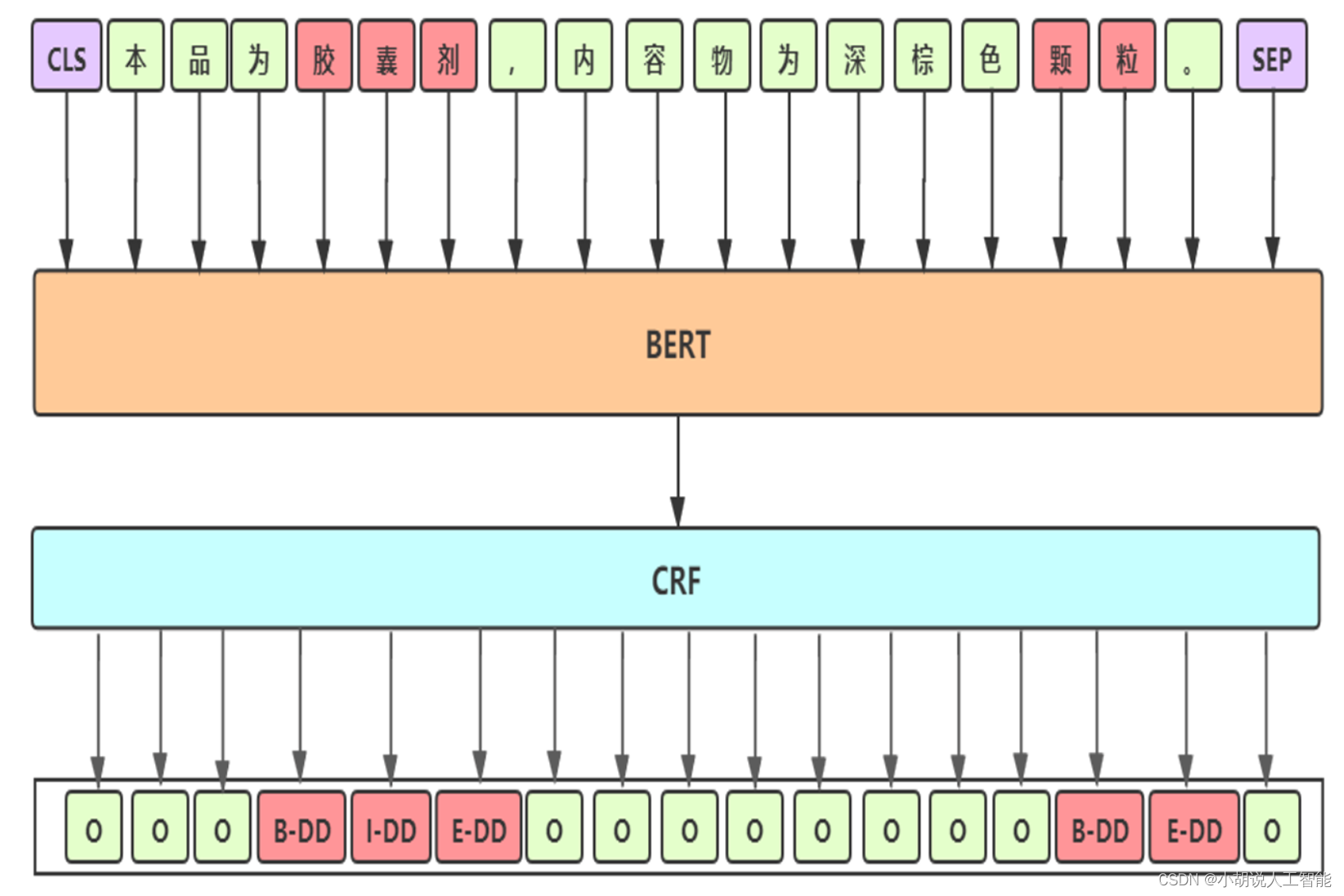
Baseline: BERT-CRF
-
Baseline 细节
- 预训练模型:选用
UER-large-24 layer[1],UER在RoBerta-wwm框架下采用大规模优质中文语料继续训练,CLUE 任务中单模第一 - 差分学习率:BERT层学习率
2e-5;其他层学习率2e-3 - 参数初始化:模型其他模块与BERT采用相同的初始化方式
- 滑动参数平均:加权平均最后几个epoch模型的权重,得到更加平滑和表现更优的模型
- 预训练模型:选用
-
Baseline bad-case分析
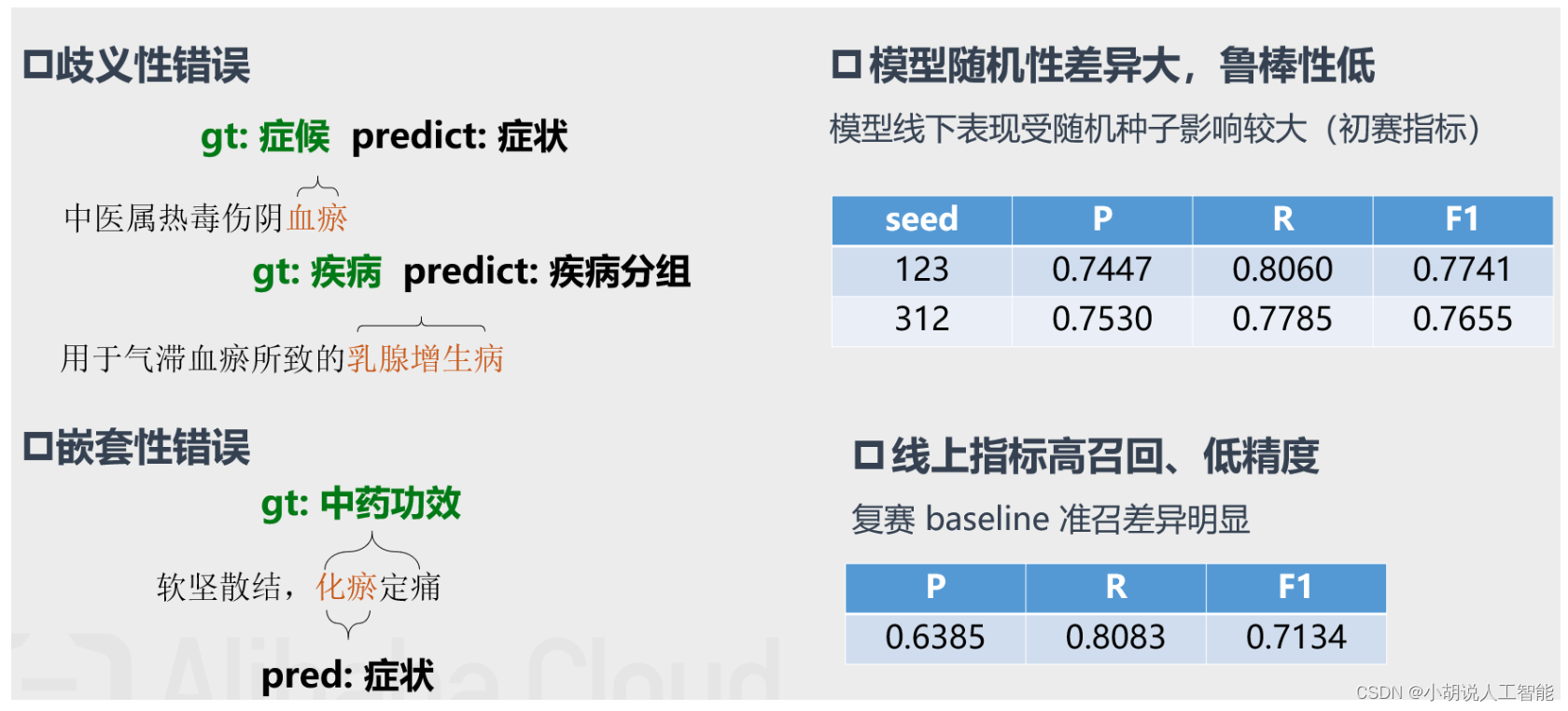
优化1:对抗训练
- 动机:采用对抗训练缓解模型鲁棒性差的问题,提升模型泛化能力
- 对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,提升模型鲁棒性和泛化能力
- Fast Gradient Method (FGM):对embedding层在梯度方向添加扰动
- Projected Gradient Descent (PGD) [2]:迭代扰动,每次扰动被投影到规定范围内
优化2:混合精度训练(FP16)
- 动机:对抗训练降低了计算效率,使用混合精度训练优化训练耗时
- 混合精度训练
- 在内存中用FP16做存储和乘法来加速
- 用FP32做累加避免舍入误差
- 损失放大
- 反向传播前扩大2^k倍loss,防止loss下溢出
- 反向传播后将权重梯度还原
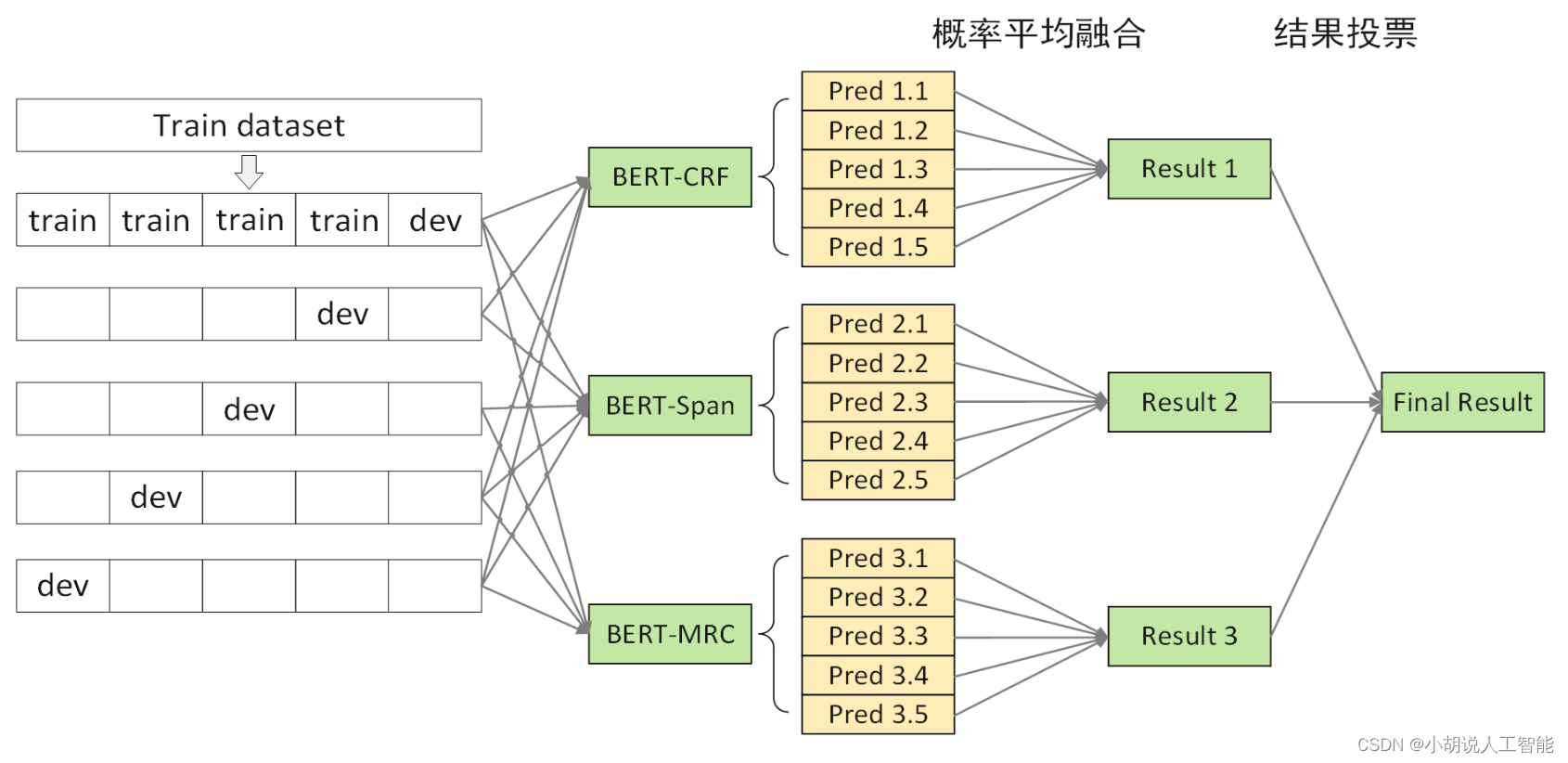
优化3:多模型融合
-
动机:baseline 错误集中于歧义性错误,采用多级医学命名实体识别系统以消除歧义性
-
方法:差异化多级模型融合系统
- 模型框架差异化:BERT-CRF & BERT-SPAN & BERT-MRC
- 训练数据差异化:更换随机种子、更换句子切分长度(256、512)
- 多级模型融合策略
-
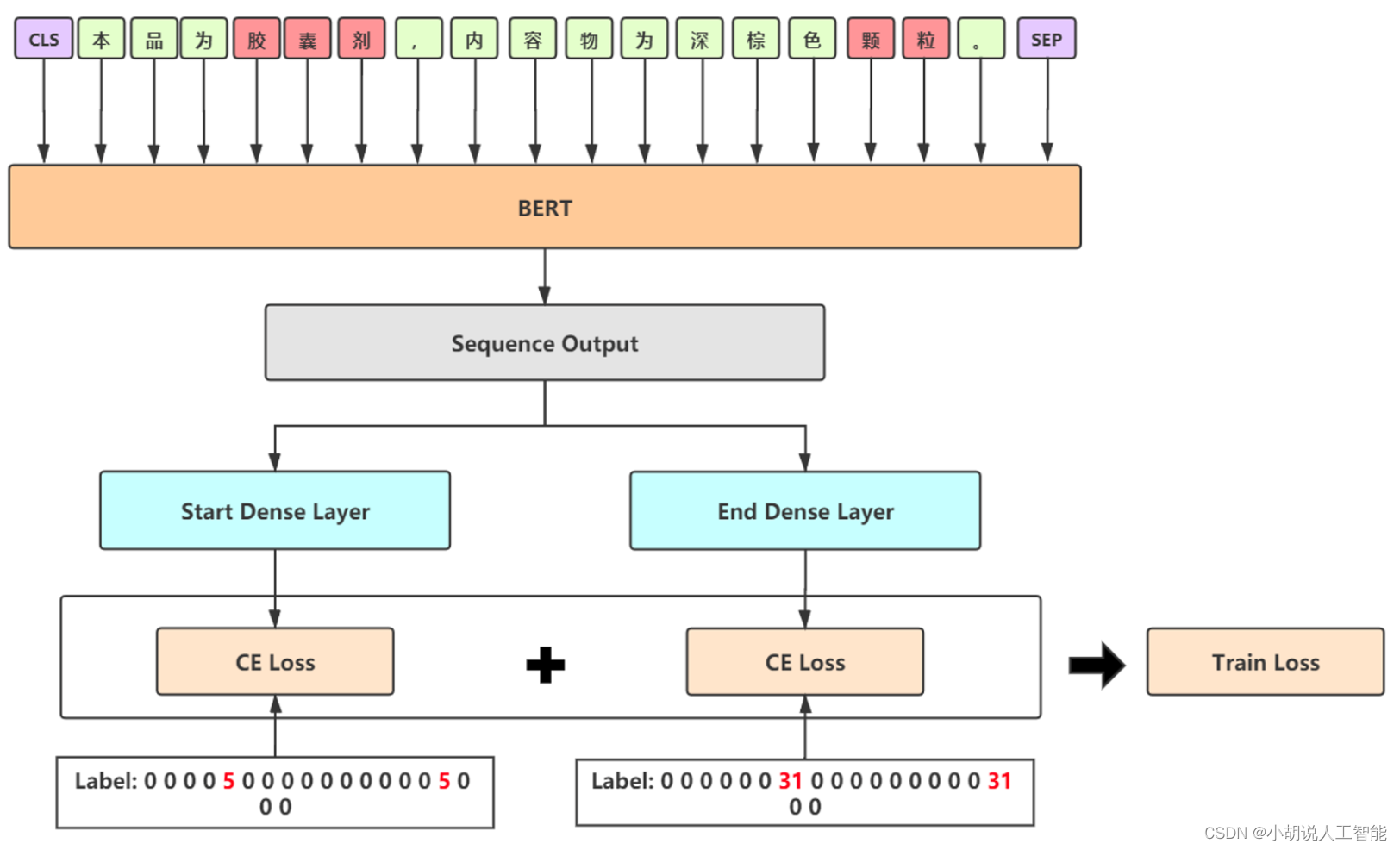
融合模型1——BERT-SPAN
- 采用SPAN指针的形式替代CRF模块,加快训练速度
- 以半指针-半标注的结构预测实体的起始位置,同时标注过程中给出实体类别
- 采用严格解码形式,重叠实体选取logits最大的一个,保证准确率
- 使用label smooth缓解过拟合问题
- 融合模型2——BERT-MRC
- 基于阅读理解的方式处理NER任务
- query:实体类型的描述来作为query
- doc:分句后的原始文本作为doc
- 针对每一种类型构造一个样本,训练时有大量负样本,可以随机选取30%加入训练,其余丢弃,保证效率
- 预测时对每一类都需构造一次样本,对解码输出不做限制,保证召回率
- 使用label smooth缓解过拟合问题
- MRC在本次数据集上精度表现不佳,且训练和推理效率较低,仅作为提升召回率的方案,提供代码仅供学习,不推荐日常使用
- 基于阅读理解的方式处理NER任务
- 多级融合策略
- CRF/SPAN/MRC 5折交叉验证得到的模型进行第一级概率融合,将 logits 平均后解码实体
- CRF/SPAN/MRC 概率融合后的模型进行第二级投票融合,获取最终结果
优化4:半监督学习
- 动机:为了缓解医疗场景下的标注语料稀缺的问题, 我们使用半监督学习(伪标签)充分利用未标注的500条初赛测试集
- 策略:动态伪标签
- 首先使用原始标注数据训练一个基准模型M
- 使用基准模型M对初赛测试集进行预测得到伪标签
- 将伪标签加入训练集,赋予伪标签一个动态可学习权重(图中alpha),加入真实标签数据中共同训练得到模型M’
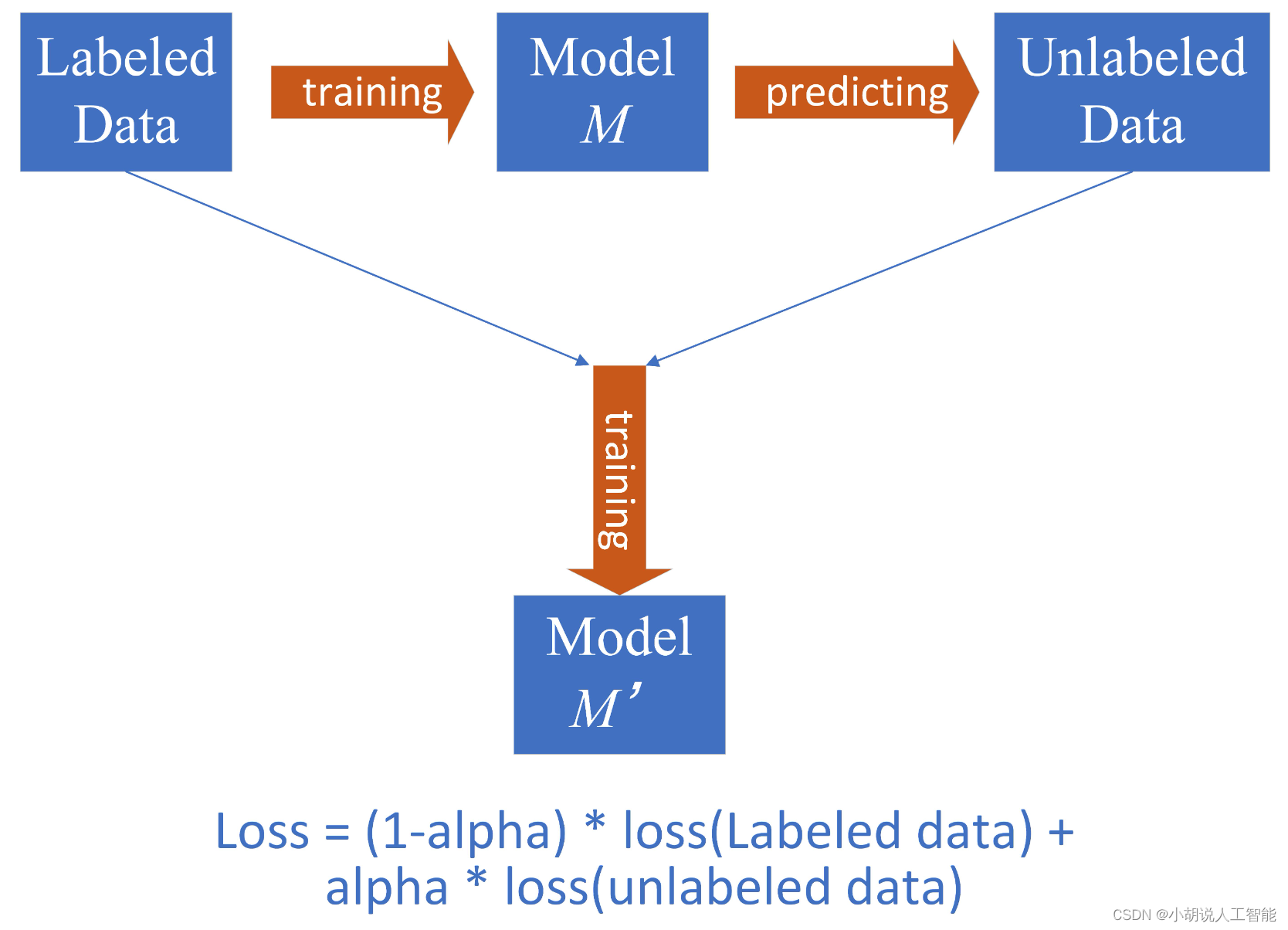
- tips:使用多模融合的基准模型减少伪标签的噪音;权重也可以固定,选取需多尝试哪个效果好,本质上是降低伪标签的loss权重,是缓解伪标签噪音的一种方法。
其他无明显提升的尝试方案
- 取BERT后四层动态加权输出,无明显提升
- BERT 输出后加上BiLSTM / IDCNN 模块,过拟合严重,训练速度大大降低
- 数据增强,对同类实体词进行随机替换,以扩充训练数据
- BERT-SPAN / MRC 模型采用focal loss / dice loss 等缓解标签不平衡
- 利用构造的领域词典修正模型输出
最终线上成绩72.90%,复赛Rank 1,决赛Rank 1
参考资料
[1] Zhao et al., UER: An Open-Source Toolkit for Pre-training Models, EMNLP-IJCNLP, 2019.
[2] Madry et al., Towards Deep Learning Models Resistant to Adversarial Attacks, ICLR, 2018.
[3] 天池中药说明书实体识别挑战冠军方案开源
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。