LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,以便在不同的应用程序中使用。
今天我们来学习DeepLearning.AI的在线课程:LangChain for LLM Application Development的第四门课:Q&A over Documents,也就是对文档进行问答。根据Langchain官方文档的说明,针对文档的问答包括五个步骤:
- 创建文档加载器Loder
- 创建索引(index)
- 从该索引创建一个检索器(retriever)
- 创建问答链(chain)
- 对文档进行提问
创建文档加载器Loder
在对文档进行问答之前,我们需要做一些基础性工作,比如设置openai的api key,以及langchain所需要的一些关于文档文档的基础库,下面我们导入本地环境配置文件.env, 在.env文件中我们存放了opai的api key
import os
import pandas as pd
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import DocArrayInMemorySearch
from IPython.display import display, Markdown
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file今天我们需要实验的对象是一个csv文件,我们要对这个csv文档的内容进行问答,下面我们先导入该csv文件:
df=pd.read_csv("OutdoorClothingCatalog_1000.csv")
df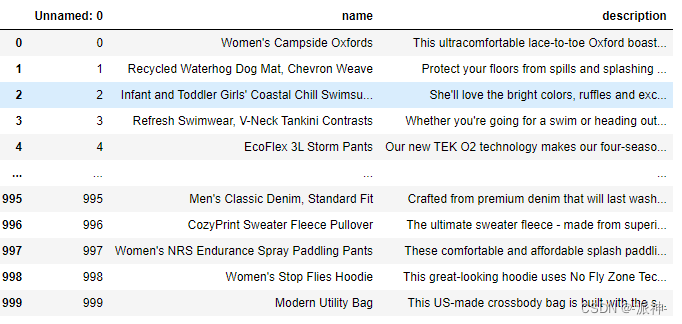
该文档主要包含2列,name和description,其中name表示商品的名称,description表示该商品的说明信息,下面我们查看一下其中的某个商品信息:
print(df[10:11].name.values[0])
print()
print(df[10:11].description.values[0])
下面我们将该商品的信息翻译成中文,这样便于大家理解:

要实现对文档内容的问答,我们首先需要创建一个文档的加载器Loader,这里因为是csv文件,所以我们需要创建一个CSVLoader:
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
创建索引(index)
创建了文档加载器loder以后,我们需要创建一个用于检索文档内容的索引器,这里我们需要指定指定一个向量数据库,我们使用DocArrayInMemorySearch作为向量数据库,DocArrayInMemorySearch是由Docarray提供的文档索引,它将会整个文档以向量的形式存储在内存中,对于小型数据集来说使用DocArrayInMemorySearch会非常方便,接下来我们还要指定一个数据源loder:
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])这里我们需要说明的是当加载文档后将执行三个主要步骤:
- 将文档分割成块
- 为每个文档创建embeddings
- 将文档和embeddings存储到向量数据库中
接下来我们可以直接使用索引来进行简单的对文档进行问答:
#问题: 请以 Markdown 形式在表格中列出您所有具有防晒功能的衬衫,并总结每一件衬衫。
query ="Please list all your shirts with sun protection \
in a table in markdown and summarize each one."
#通过索引进行查询
response = index.query(query)
#在jupyter notebook中展示查询结果
display(Markdown(response))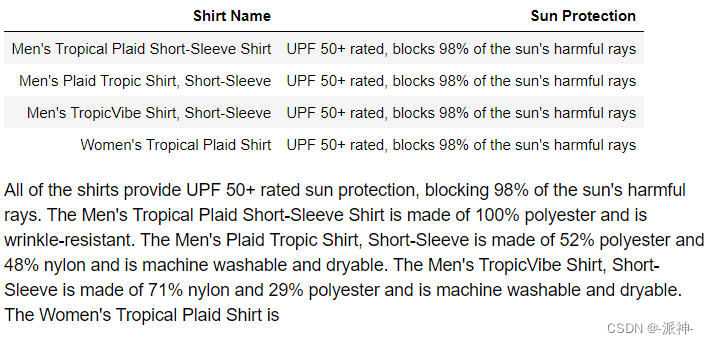
这里我们提出的问题是:“请以 Markdown 形式在表格中列出您所有具有防晒功能的衬衫,并对每一件衬衫进行总结。”,从上面llm返回的结果中我们可以看到,llm找到了4件具有防嗮功能的衬衫,并且它对每一件衬衫都进行了总结,最后还加了一个最终的总结,如果我们没有对格式有特殊要求的话,这样的回答基本符合我们的要求。
Embeddings
前面我们使用的是DocArrayInMemorySearch组件在内存中向量化存储数据,所以它只适合该小型数据集向量化存储,由于大型语言模型一次只能检索几千个单词,所以当遇到较大规模的文档时DocArrayInMemorySearch就不再适用了。对于大型文档,我们需要使用词嵌入(word Embedding)技术,所谓word Embedding是一种将文本转换成数字的技术,因为计算机只认识数字,对于文本信息计算机是无法理解的,让要计算机能理解文本信息,我们将需要将文本信息转换成一组计算机可以理解的数字,这组数字称为向量,两个含义相近的词,他们所在的向量空间中的位置可能会比较接近,而两个含义不同的词,他们在向量空间中的距离可能就比较遥远,请看下面的例子:
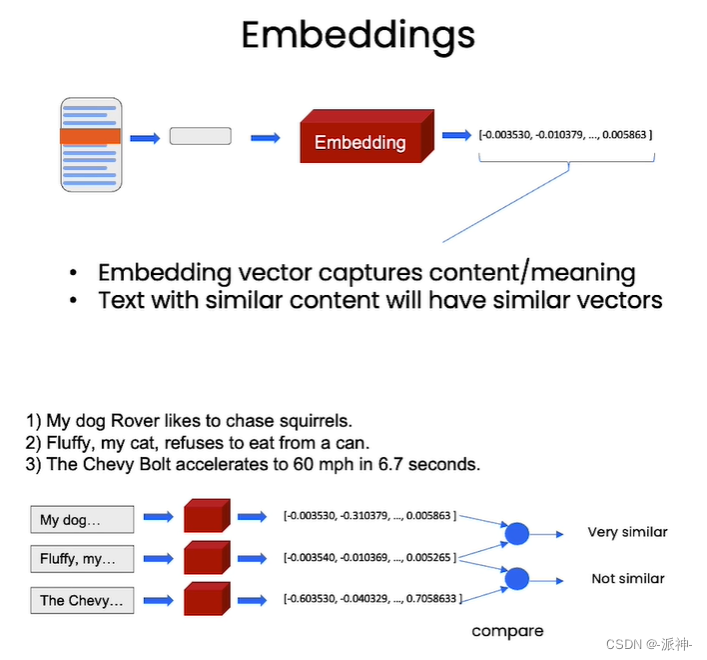
在上面的这个例子中的三句话:
- My dog Rover likes to chase squirrels.(我的狗Rover喜欢追松鼠。)
- Fluffy, my cat, refuses to eat from a can.(我的猫蓬松拒绝吃罐头食品。)
- The Chevy Bolt accelerates to 60 mph in 6.7 seconds.(雪佛兰 Bolt 在 6.7 秒内加速至 60 英里/小时。)
中第一句和第二句都是描述动物的,第三句是描述汽车的,所以第一句和第二句经过Embedding以后生成的两组向量,这两组向量在向量空间中的位置会比较接近,我们称这种情况为两个向量具有相似性,也就是说第一句话和第二句话有相似性(因为他们都在描述动物),第三句话与前两句话不相似。
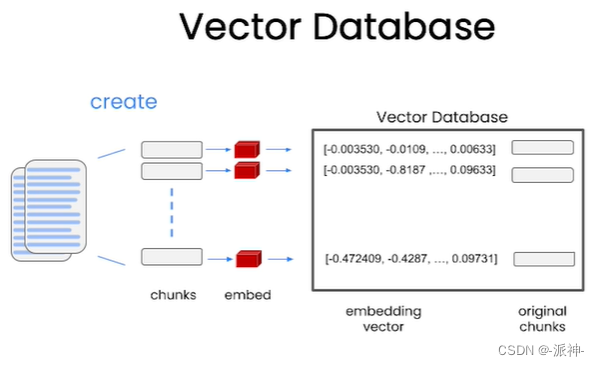
向量数据库
前面我们解释了小规模文档检索和Embedding基本原理,那么对于大规模文档文档该如果处理呢?对于大规模文档,首先需要将文档进行切片分割操作,把文档切分成一个个块(chunks),然后对每个块做embedding,最后再把由embedding生成的所有向量存储在向量数据库中,如下图所示:
向文档提出问题
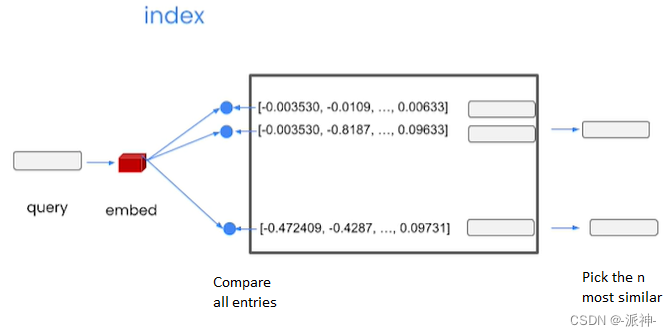
当我们完成了大规模文档的向量数据库存储以后,接下来在用户提问时,系统会将用户的问题进行Embedding操作并生成一组向量,接着将该组向量与向量数据库中的所有向量进行比较,找出前n个最相似的向量并将其转换成对应的文本信息,如下图所示:
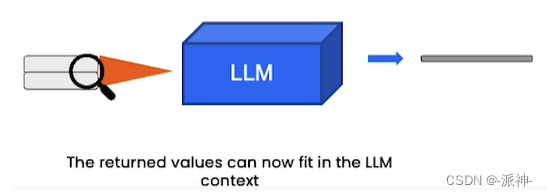
这些与用户问题最相似的文本信息最后会喂给大型语言模型(LLM),并由LLM生成最终的回复信息,如下图所示:
接下来我们就来对之前的数据集做Embedding,然后我们再生成一个问答chain来实现对文档的问答:
#1.加载文档,并进行文档切割
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
docs = loader.load()
#2.创建embeddings
embeddings = OpenAIEmbeddings()
#3.创建向量数据库
db = DocArrayInMemorySearch.from_documents(
docs,
embeddings
)
#4.创建检索器
retriever = db.as_retriever()
#5.创建RetrievalQA
qa_stuff = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature = 0.0),
chain_type="stuff",
retriever=retriever,
verbose=True
)这里需要说明的是由于我们的数据集是一个1000行的csv文件,所以我们使用DocArrayInMemorySearch作为向量数量数据库,因为它比较擅长处理小规模的数据集,然后我们创建了一个检索器retriever,最后我们创建了一个RetrievalQA的chain,该chain包含三个主要的参数,其中llm参数被设置为openai的llm,默认为"gpt-3.5-turbo", retriever参数设置设置为前面我们由DocArrayInMemorySearch创建的retriever,最后一个重要的参数为chain_type,该参数包含了四个可选值:stuff,map_reduce,refine,map_rerank 其中:
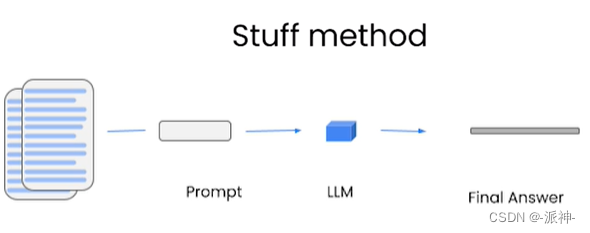
stuff:这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果docume很 多的话,势必会报超出最大 token 限制的错。
map_reduce: 这个方式会先将每个 document 通过llm 进行总结,最后将所有 document 总结出的结果再进行一次总结。
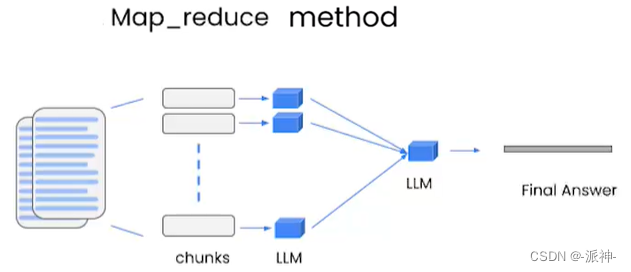
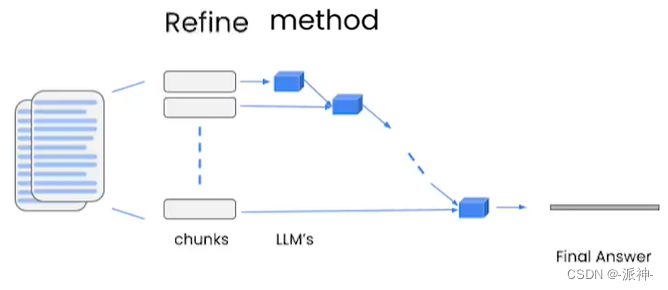
refine:这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个 document 一起发给 llm 模型再进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。
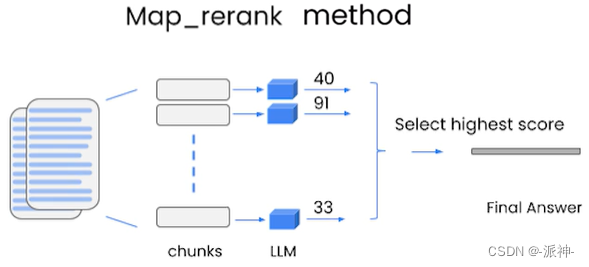
map_rerank: 这种方式会通过llm对每个文档进行一次总结,然后得到一个分数,最后选择一个分数最高的总结作为最终回复。
下面我们调用qa_stuff来实现对文档的问题,我们的问题还是与之前用index来进行文档问答的问题一样:"Please list all your shirts with sun protection in a table in markdown and summarize each one." 即,“请以 Markdown 形式在表格中列出您所有具有防晒功能的衬衫,并每一件衬衫进行总结。”
query = "Please list all your shirts with sun protection in a table \
in markdown and summarize each one."
response = qa_stuff.run(query)
display(Markdown(response)) 这里我们看到,通过qa_stuff返回的结果与之前用index来提问时返回的结果非常接近,llm找到同样的四件具有防嗮功能的衬衫,并在最后对每一件衬衫进行了总结,这也符合我们的要求。
这里我们看到,通过qa_stuff返回的结果与之前用index来提问时返回的结果非常接近,llm找到同样的四件具有防嗮功能的衬衫,并在最后对每一件衬衫进行了总结,这也符合我们的要求。
Index 与 RetrievalQA
之前我们用index.query()这个方法只用一行代码也实现了上述的文档问答的功能,也许有读者会问,既然index.query()可以只用一行代码就完成了文档问答功能又何必要舍近求远搞一个RetrievalQA这样的对象来实现,并且增加很多繁琐的步骤(有5个步骤)来实现同样的效果呢?Langchain框架的作者Harrison Chase在课件视频中是这么解释的,通过index来进行文档问答,只需一行代码,但是这其中其实隐藏了很多的实现细节,如果我们使用的是RetrievalQA对象来实现文档问答功能,那么我们就可以了解其中的细节比如Embeddings,向量数据库等内容,反正各有各的好处吧。
参考资料
DocArrayInMemorySearch | 🦜️🔗 Langchain
Retrievers | 🦜️🔗 Langchain