期刊语义网络和主路径分析
- 文本挖掘的研究趋势:期刊语义网络和主路径分析(2020年)
- 1. 简介
- 2. 理论背景
- 2.1 文本挖掘
- 2.2 网络分析
- 2.3. 主路径分析
- 2.4. 文献分析
- 3. 文本挖掘研究的分析和分类
- 3.1. 分析范围
- 3.2. 文本挖掘研究的学术领域
- 4. 选定期刊的语义网络分析
- 4.1 使用Gephi进行网络分析
- 4.2 使用VOSviewer进行关键词网络分析
- 5. 文本挖掘研究的主路径分析
- 6. 结论
文本挖掘的研究趋势:期刊语义网络和主路径分析(2020年)
1. 简介
文本挖掘是从文本形式的数据中提取有意义信息的技术。文本挖掘的目标范围从学术文献到社交网站,关于新闻的帖子和评论,客户的声音,语音到文本(STT)数据,等等。
文本挖掘也被积极地用于分析各种研究领域的研究趋势,如信息系统、技术管理、教育、图书馆和信息科学、心理学、社会学等。然而,尽管文本挖掘已经被广泛应用于各个研究领域,但是对于文本挖掘本身的研究趋势还没有足够的研究。因此,当研究者需要找到具有学术重要性和对文本挖掘有贡献的论文时,他们主要依赖于论文所发表期刊的声誉和被引用的数量。
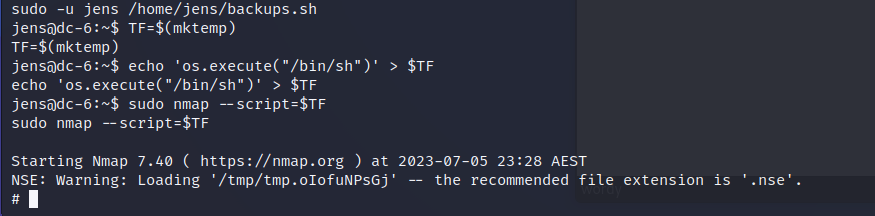
本研究的目的是明确哪些论文有重要的学术贡献,当前文本挖掘研究的主要研究路径是什么,并预测文本挖掘未来的研究趋势 。为了回答这些问题,我们分析了国际学术引文数据库Scopus和Web of Science中存储的1856篇关于文本挖掘的论文。为了发现当前文本挖掘的发展趋势,本文将语义网络分析和主路径分析作为文本挖掘的方法。
2. 理论背景
2.1 文本挖掘
文本挖掘可以分析大量非结构化数据,而传统的数据分类和分析无法处理这些数据,因此文本挖掘作为一种分析技术已被广泛应用于许多学术研究中。
2.2 网络分析
网络分析,通常被称为“关键词网络分析”或“语义网络分析”,通过将出现在文本中的词与词连接起来,建立网络来解释现象,形成一幅关系图。网络分析描述的是来自未分类数据而不是完全分类数据的结构化结果。换句话说,从关系的角度来看,不是一个独立的对象,而是帮助人们更清楚地理解一种情况或现象的对象之间的关系。网络由与关键字和指示它们之间关系的线或链接对应的节点组成。
在本研究中,我们使用Gephi 0.9.2和VOSviewer 1.6.9作为网络分析软件。确定节点中心性的方法,比如度中心性,用来衡量有多少节点是直接连接的,亲密度中心性,根据每个节点与网络中所有其他节点的亲密度来评分,中间度中心性用来度量一个节点在其他节点之间最短路径上的次数。本研究基于特征向量中心性对网络节点进行可视化,以确定节点的相对重要性。
2.3. 主路径分析
主径分析确立了论文引文关系的重要路径。这是一种通过可视化机构间引文的使用,揭示学术、幕后关系和知识拓宽路径的技术。在本研究中,主要的路径是基于搜索路径计数(SPC)推导出来的。SPC是一篇论文被引用的路径中,从源到末端的链接的总次数。我们使用四种类型的主路径分析;本地主路径转发、反向主路径、全局主路径、关键路由主路径分析。前向本地主路径和后向本地主路径分析在每个接触点选择并连接到最大SPC的链路。全局主路径分析选择spc之和最大的路径,关键路由主路径分析选择链路最大最先的路径,并将重要路径前后结合。key-route主路径搜索解决了丢失一些路由的问题,并且包含了所有重要的连接。我们使用软件Pajek 64-5.07a作为主路径分析工具。
2.4. 文献分析
已经有一些学术领域的研究趋势,如信息科学(Lee, Kim, & Kim, 2010),教育(Hung, 2012),机器学习(Sharma, Kumar, & Chand, 2018),生物医学(Zhai等人,2015),商业智能(Moro, Carneiro, Cortez, & Rita, 2015)和医疗信息学(Kim, Delen, 2015)。2018年)对同行评议论文进行定量分析。所有这些研究都是基于文本挖掘技术,通过对期刊数据库中的论文进行分析来揭示研究趋势。基于文本挖掘的研究趋势分析不仅针对特定研究领域,也针对跨学科研究。Calero-Medina和Noyons(2008)通过文本挖掘分析了所有以“吸收能力”为关键词的研究,揭示了哪些学术领域使用了吸收能力的概念。在本研究中,我们收集并分析了论文标题或作者关键词中包含“文本挖掘”或“文本分析”的论文,以确定文本挖掘应用的学术领域的类型和趋势、主要研究课题和与文本挖掘研究相关的关键论文。如前所述,尽管文本挖掘被广泛应用于各个研究领域,但很少有学者研究文本挖掘本身的研究趋势。本研究显然是第一个全面分析文本挖掘研究趋势的研究。
3. 文本挖掘研究的分析和分类
3.1. 分析范围
本研究使用的数据来源为Web of Science和Scopus。Moro et al.(2015)利用“银行”、“商业智能”等关键词进行搜索,研究商业智能在银行领域的研究趋势。如果作者主观地判断一篇论文是否是关于“商业智能在银行”的研究,结果的可靠性就会降低。本研究通过文本挖掘技术,收集所有在论文标题或作者关键词中包含“文本挖掘”或“文本分析”等词的论文,选取相关期刊,目标是近40年来Scopus收录的所有英文期刊。
当文献标题中同时包含“text”和“mining”,或者同时包含“text”和“analysis”时,我们认为它们符合本研究的标准。我们还决定分析自1980年以来发表的、到2019年12月底收到1次以上引用的论文。我们将所选期刊分为:(1)20世纪80年代和90年代,文本挖掘很少使用;(2) 2000年代,互联网和数字文学的传播;(3) 2010年代,文本挖掘在各个领域的扩展,智能手机和社交网络服务开始流行。
本分析的目的是确定文本挖掘研究的特点和影响的最新研究趋势,并预测主路径分析在文本挖掘研究中的未来。
3.2. 文本挖掘研究的学术领域
附录1、2、3给出了基于Web of Science数据对标题中包含“text”、“mining”或“text”、“analysis”的论文的分类。文本挖掘研究在20世纪80年代和90年代(1980-1999)共发表45篇论文,在21世纪前10年(2000-2009)共发表105篇论文,在21世纪前10年(2010-2019)共发表171篇论文。也就是说,与文本挖掘相关的论文被广泛应用于各种学术研究中,并且数量趋势越来越多。
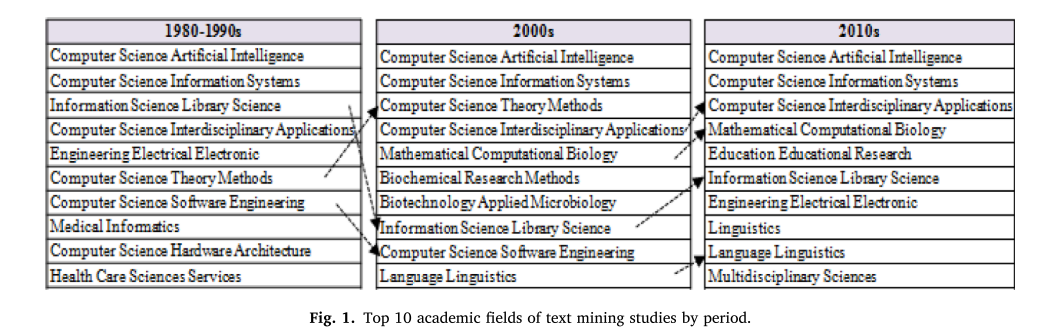
图1显示,1980年至2019年,计算机科学类人工智能和计算机科学信息系统稳居前10名,情报学图书馆学从1980年的第3名小幅下降至2010年的第6名。工程类——电气电子类——从上世纪80年代和90年代的第五位降至2010年代的第七位。计算机科学领域的软件工程从上世纪80年代的第7位下降到2000年代的第9位,到2010年代再次下降到第13位。相反,在20世纪80年代和90年代分别排在第8、9、10位的医学信息学、计算机科学硬件结构、保健科学服务等学科进入21世纪后,被挤出了前10名之外。
4. 选定期刊的语义网络分析
4.1 使用Gephi进行网络分析
我们基于作者在摘要中创建的关键词进行了语义网络分析。使用Python软件从Scopus中提取每篇论文的关键词,并推导出同一摘要中同时出现的关键词之间的网络。在数据提取和分析过程中,阈值即表示关键词对同时出现的频率,1980 - 1999年为2,2000 - 2009年为4,2010 - 2019年为7。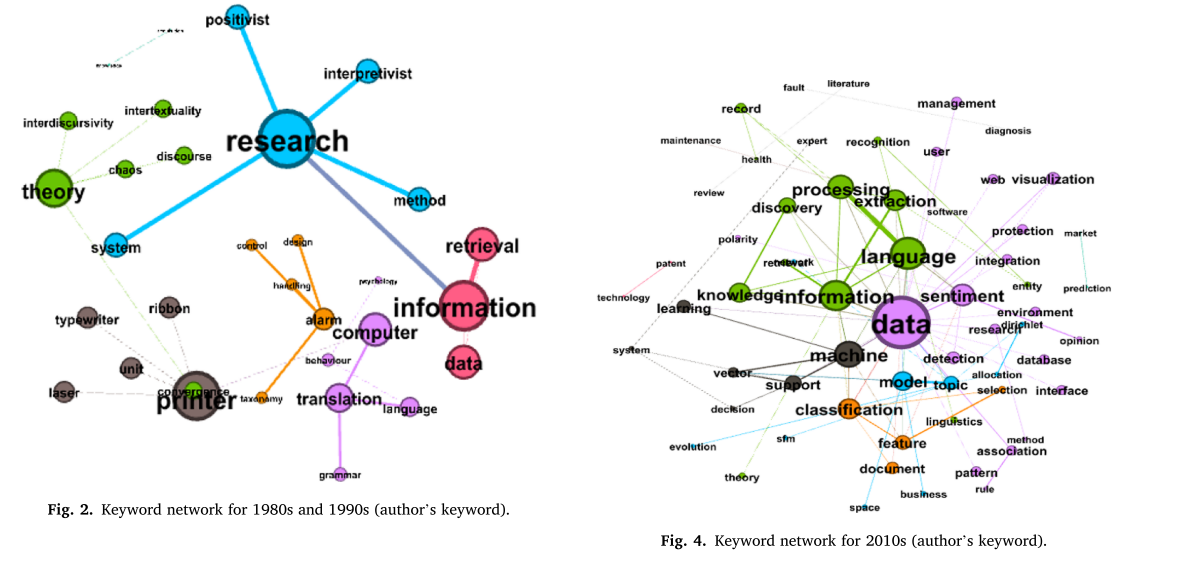
 得到每篇论文关键词之间的网络数据如图2-4所示。这些是由Gephi 0.9.2可视化的。节点的大小表示特征值中心性的值,节点的唯一颜色表示模块性的差异。
得到每篇论文关键词之间的网络数据如图2-4所示。这些是由Gephi 0.9.2可视化的。节点的大小表示特征值中心性的值,节点的唯一颜色表示模块性的差异。
通过对关键词网络的分析发现,随着研究范围的扩大,对文本挖掘的研究也越来越多,关键词间网络也逐渐变得更加复杂。然而,当研究的数量较少时,如在20世纪80年代和90年代,可能来自任何论文的词,如“研究”、“信息”和“理论”被突出作为主要关键词,这使得很难推断出任何具体的含义。文本挖掘是对语素、单词、句子、段落、语料库和文档的研究。从这个意义上说,作者在论文摘要中提出的关键词并不是一个句子的形式,而是一组无结构的词。由于作者选择的关键词的网络分析结果在某些方面是有限的,所以有必要在段落层面分析数据,而不是非结构化的词集。因此,我们根据每篇论文的摘要,额外进行了关键词网络分析。此外,为了排除大多数文章中出现频率高的单词,我们使用了Python的**“stop word”**函数。
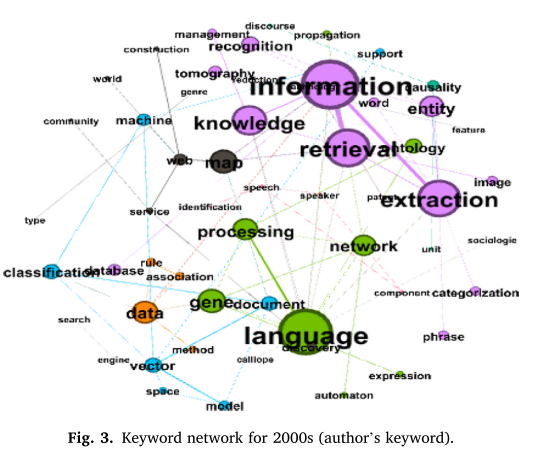
我们分析了1856篇论文的摘要文本,并使用Python提取同一摘要中同时出现的关键词对的频率,并通过Gephi将其可视化。每个时间段推导的关键词网络如图5-7所示。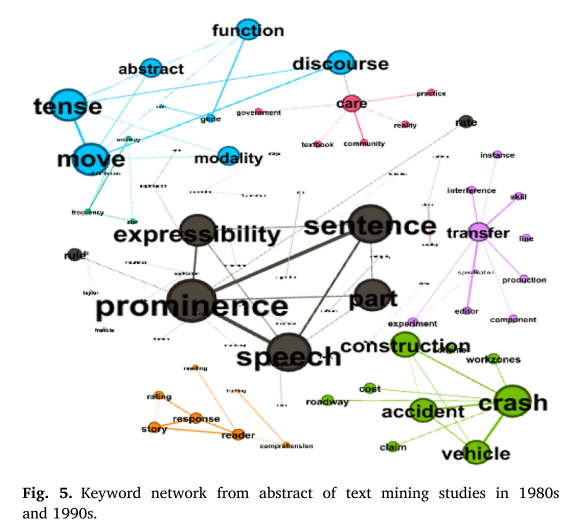
将分析的目标从作者的关键词扩展到摘要的文本,关键词之间的可视化链接提供了对论文内容的有意义的见解。此外,三个时间段的关键字对的实际数量显著增加,阈值为20。该分析中节点的大小也是基于特征值中心性的,节点的颜色根据模块性准则而变化。20世纪80年代和90年代的关键词包含了对话或句子的内容和语气,如“句子”、“时态”、“言语”等。与此相反,“基因”等生物学和遗传学关键词在21世纪前10年尤为突出;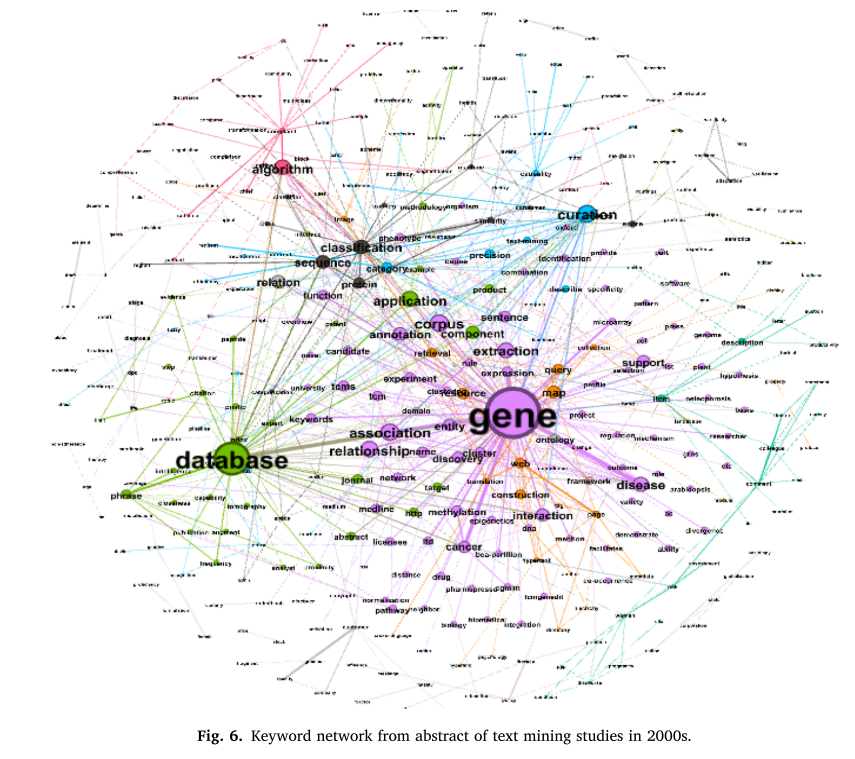 “健康”、“癌症”、“患者”等医学和健康相关的关键词在21世纪前10年主要出现
“健康”、“癌症”、“患者”等医学和健康相关的关键词在21世纪前10年主要出现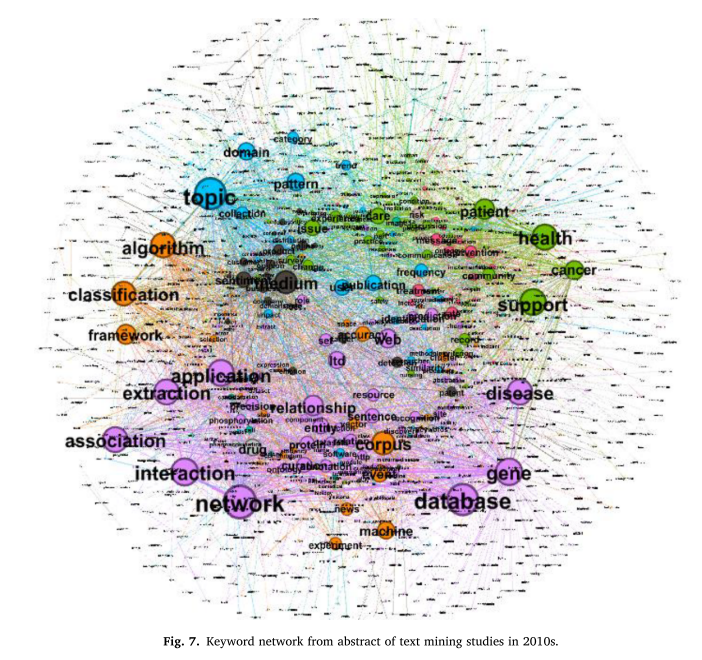
4.2 使用VOSviewer进行关键词网络分析
选择了一个网络分析软件VOSviewer来进行节点的同步映射和聚类,以及可以直观地识别关键区域的密度可视化。在VOSviewer中,两个单词之间的相似度与它们同时出现的次数成正比,相似度高的单词被放在一起。我们指定一个项目的最小总链接强度为1。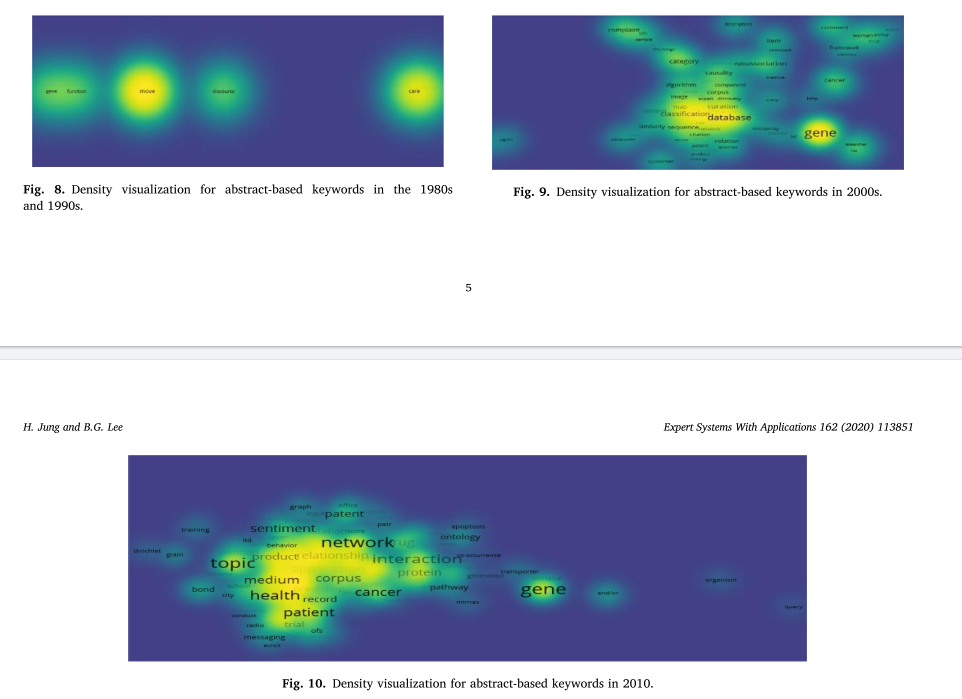
在图8-10中,我们展示了通过VOSviewer实现的关键词密度可视化,但与通过Gephi实现的网络可视化相比,没有发现具体的区别结果。然而,VOSviewer的叠加可视化功能显示了每年的关键字趋势,它可以识别额外的影响和研究趋势的特征。覆盖可视化将1980年至2019年期间在文本挖掘研究中一起出现的词对可视化。将同时出现次数最少(2次以上)的关键字可视化,得到如图11-13所示的分析结果。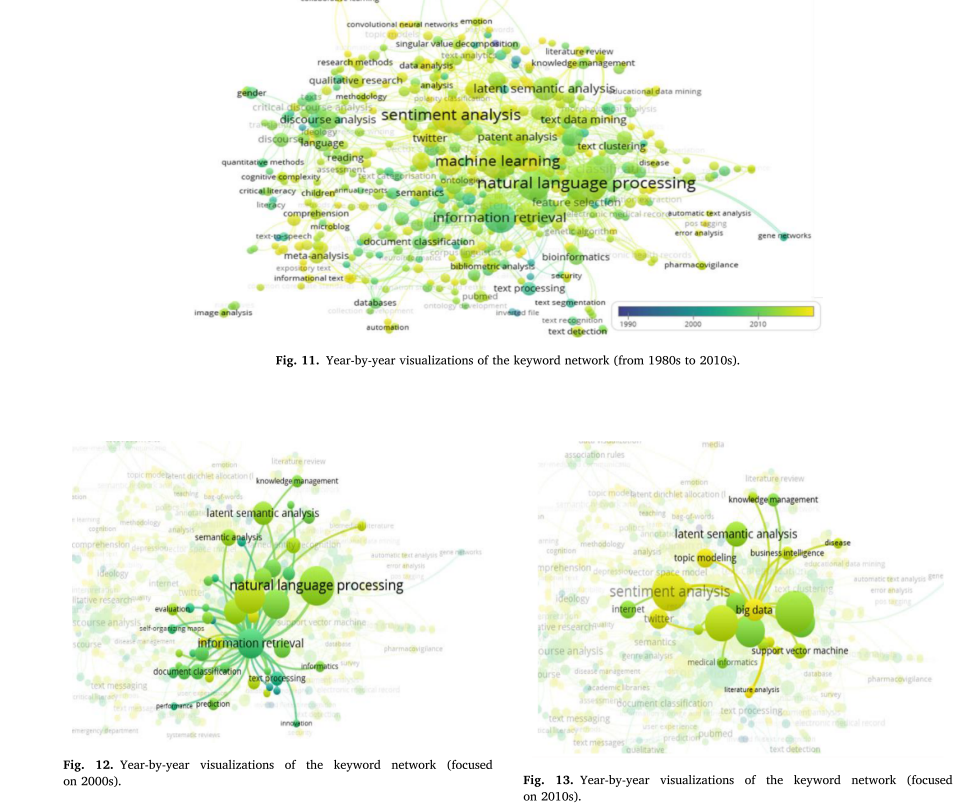
在图11-13中,节点的颜色表示研究的年龄。节点越接近黄色,它出现的时间越近。另一方面,节点越接近蓝色,它就越老,这意味着接近1980年。图11是对我们所针对的所有论文进行分析后的结果。图12和图13也是分别强调2000年和2010年的可视化图。在2000年代,如图12所示,网络围绕“信息检索”、“自然语言处理”和“文档分类”形成。图13突出了2010年代比较近期的论文的关键词,强调了“大数据”、“推特”、“话题建模”、“情绪分析”等最新的研究趋势。
5. 文本挖掘研究的主路径分析
我们对两个引文数据库进行了主径路分析。主路径分析的目标研究集与前面网络分析中使用的研究集相同。用于主路径分析的软件为VOSviewer、Gephi和Pajek。首先,我们使用VOS - viewer和Gephi构建文本挖掘研究之间的引文网络关系,并使用Pajek计算SPC并可视化主要路径。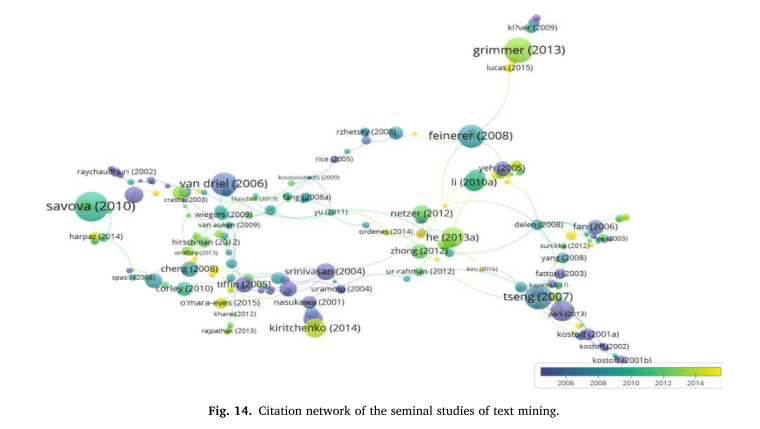 由于论文的出版年份显示在可视化结果中,我们通过分离时间段和合并时间段来实现主路径分析(图14)。
由于论文的出版年份显示在可视化结果中,我们通过分离时间段和合并时间段来实现主路径分析(图14)。
本研究采用四种主要路径分析及可视化方法;正向本地主路径、反向本地主路径、关键路由本地主路径和标准全局主路径。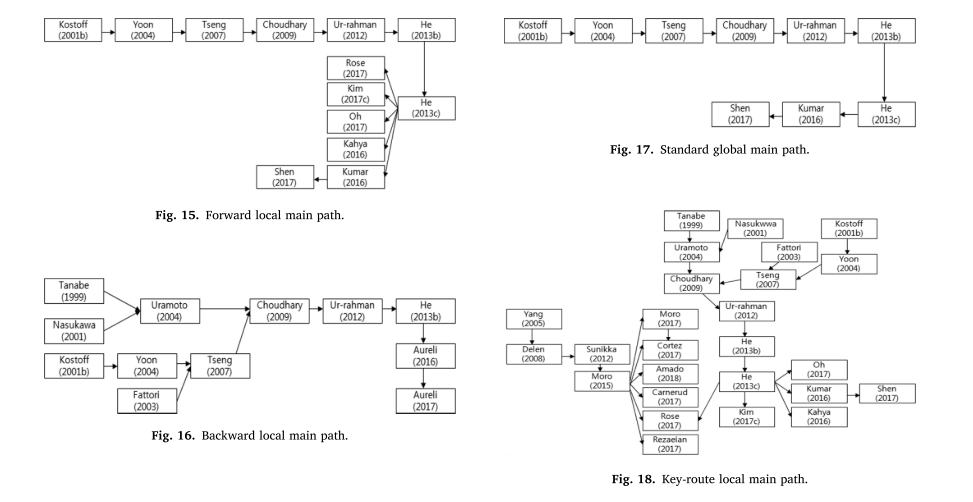 主路径分析的最终结果如图15-18所示。通过分析,可以确定引文路径上的重要论文,并找到每年发表与文本挖掘相关论文的学术领域。
主路径分析的最终结果如图15-18所示。通过分析,可以确定引文路径上的重要论文,并找到每年发表与文本挖掘相关论文的学术领域。
此外,还可以确立发展的秩序和方向的主要路线。
在图15中,前向局部主路径分析,“社交媒体竞争分析与文本挖掘”(He, Zha, & Li, 2013),发表在国际信息管理杂志上的一篇关于社交媒体与文本挖掘的研究,接着是一篇关于建筑学的论文,“支持绿色建筑设计的文本挖掘技术与案例推理集成系统”(沈航雁,Ya, & Zhang, 2017)。
在图16中,与正向局部主路径不同,从Tanabe(1999)和Nasukawa(2001)开始的路径被显示为一个额外的主路径。
图18显示了关键路线局部主路径分析,该分析最小化了某些路线的遗漏,表明He等人(2013)影响了各个学术领域。此外,Moro、Cortez和Rita(2015)使用了潜在Dirichlet allocation (LDA)技术来分析与银行业商业智能系统相关的文献,在各个学术领域都得到了引用。
特别是,“使用数据库到mography和文献计量学的文本挖掘:综述”(Kostoff, Toothman, Eberhart, & Humenik, 2001)是一个使用文本挖掘的学术文献数据库的研究,本文处于所有四个主要路径分析结果的早期阶段。两篇关于专利分析的研究论文“基于文本挖掘的技术网络:高技术趋势分析工具”(Yoon & Park, 2004)和“专利分析的文本挖掘技术”(Tseng, Lin, & Lin, 2007)也出现在所有四个主要路径分析结果中。比较主路径分析的结果,文本挖掘的sig - ificant研究产生于21世纪初的文献信息领域(Kostoff et al., 2001),但后来出现在与技术管理、专利和信息系统相关的许多研究中。
近年来,文本挖掘的研究范围已扩大到对社交媒体等社会现象的分析。在这条主要道路上的其他开创性研究可以在社会生态学和建筑学中找到。我们还证明,He等人(2013)和Moro等人(2015)撰写的重要论文对知识的广泛传播做出了贡献,并在每个领域发挥了重要作用。在上述的每一个主路径分析中,出现两次以上的论文按发表年份的顺序显示在表1中。
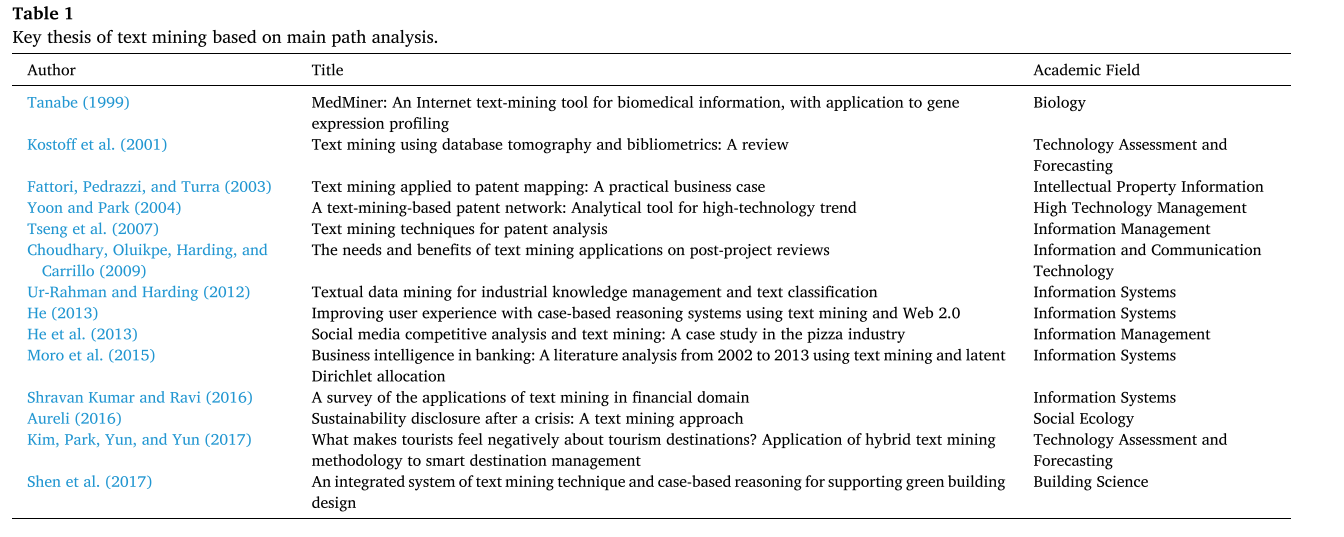
这些结果表明,这些论文是文本挖掘研究的主要路径上的重要研究。在大多数情况下,这些论文所发表的学术期刊都与信息系统或信息管理、技术管理或技术管理相关。结果表明,在文本挖掘领域有重要贡献的论文已经在过去很少与文本挖掘相关的领域发表。这一效应对应于论文所写领域的整体扩展。结果还表明,大多数重要的论文将文本挖掘作为研究工具,而不是专注于文本挖掘本身,这一趋势最近有所增加。
6. 结论
我们分析了不同时期的文本挖掘研究,并从同行评议文献数据库、Web of Science数据库和Scopus数据库中获得了研究动态。结果表明,使用文本挖掘的学术领域数量显著增加,并明确指出了哪些研究领域的文本挖掘正在积极应用。此外,我们从文本挖掘论文的摘要中提取同时出现的关键词来分析网络路径,并基于特征向量中心性确定每个时间段的主要关键词。我们的研究结果表明,在20世纪80年代和90年代,与谈话和语音相关的关键词如“话语”和“演讲”,在21世纪的头十年,生物医学相关的关键词如“基因”,医学相关的关键词如“癌症”,以及与先进分析技术相关的关键词如“主题”和“算法”,在21世纪10年代都很突出。此外,我们具体展示了每年关键词的变化,表明大数据、社交媒体分析、情绪分析(“大数据”、“推特”、“情绪分析”)的研究正在成为最新的研究趋势。根据论文摘要关键词分析的结果,我们可以预期,未来与文本挖掘相关的论文发表的学术领域将稳步扩大,新的分析技术也将不断发展。
我们还考察了1856项文本挖掘研究中的引文网络的主要路径,并提出了一些证据,表明有影响力的作者和对文本挖掘领域的知识和发展有重要贡献的论文。总结四种主要路径分析的结果,对文本挖掘学术发展做出贡献的论文产生于直到21世纪初的信息科学文献和2010年代的信息系统与技术管理文献。此外,最近关于文本挖掘的重要研究已经在社会生态学和建筑学领域发表,我们观察到文本挖掘在各个学术领域的广泛应用。我们也强调哪些研究已经对各个学术领域产生了广泛的影响。近年来,文本挖掘越来越多地作为一种研究手段而不是研究的目的。在国际学术文献数据库的基础上,对研究之间的引文和被引数据进行了提取和预处理。本研究的贡献在于揭示了1980年至今文本挖掘的研究趋势,并通过分析语义网络和这些网络中的主要路径得出了这些趋势的含义。本研究的一个延伸是分析文本挖掘的研究趋势,比较“文本挖掘作为一种研究手段”和“文本挖掘作为一种研究主题”。